

一种稀疏矩阵的实现方法
source link: https://blog.csdn.net/tkokof1/article/details/82895970
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
本文简单描述了一种稀疏矩阵的实现方式,并与一般矩阵的实现方式做了性能和空间上的对比
矩阵一般以二维数组的方式实现,代码来看大概是这个样子:
// C#
public class Matrix
{
// methods
// elements
ElementType[,] m_elementBuffer;
}
实现方式简单直观,但是对于稀疏矩阵而言,空间上的浪费比较严重,所以可以考虑以不同的方式来存储稀疏矩阵的各个元素.
一种可能的实现方式是将元素的数值和位置一起抽象为单独的类型:
// C#
public struct ElementData
{
uint row, col;
ElementType val;
};
但是如何存储上述的 ElementData 仍然存在问题,简单使用列表存储会导致元素访问速度由之前的O(1)变为O(m)(m为稀疏矩阵中的非0元素个数),使用字典存储应该是一种优化方案,但是同样存在元素节点负载较大的问题.
定性的讨论往往没有结果,不如定量的来分析一下结果.
这里尝试使用字典存储方式实现一下稀疏矩阵,考虑到需要提供字典键,我们可以将元素的位置信息通过一一映射的方式转换为键值(这里采用简单的拼接方式,细节见源码),同样是因为一一映射的缘故,通过键值我们也可以获得元素的位置信息,基于此,字典中只需存储元素的数值即可,无需再存储元素的位置信息,可以节省一部分内存消耗.
本以为相关实现应该比较简单,但整个过程却颇多意外,这里简单记下~
C#的泛型限制
由于矩阵的元素类型不定,使用泛型实现应该是比较合理的选择,代码大概如此:
// C#
public class Matrix<T>
{
public uint Row { get; private set; }
public uint Col { get; private set; }
public Matrix(uint row, uint col)
{
Row = row;
Col = col;
m_elementBuffer = new T[Row, Col];
}
public T this[uint row, uint col]
{
get
{
return m_elementBuffer[row, col];
}
set
{
m_elementBuffer[row, col] = value;
}
}
public static Matrix<T> operator +(Matrix<T> left, Matrix<T> right)
{
var result = new Matrix<T>(left.Row, left.Col);
for (uint row = 0; row < left.Row; ++row)
{
for (uint col = 0; col < left.Col; ++col)
{
result[row, col] = left[row, col] + right[row, col];
}
}
return result;
}
// more methods here
T[,] m_elementBuffer;
}
但是编译时却提示: 运算符 “+” 无法应用于 “T” 和 “T” 类型的操作数(代码 result[row, col] = left[row, col] + right[row, col]),目前C#支持的泛型约束也不支持四则运算类型的constraints,这导致需要一些workaround的方式来让上面的代码通过编译,自己参照这篇文章的思路也尝试实现了一下(代码),但是依然觉得逻辑偏于复杂了.
C#中类型的内存占用
由于需要比较内存占用,我需要获取类型的内存大小,但C#中目前没有直接获取某一类型的内存占用的方法,诸如sizeof,serialize等方式都比较受限,简单尝试了一下 GC.GetTotalMemory(true),发现结果也不准确,后面便没有再深入了解了.
鉴于上面的原因,最终还是选择使用C++实现了相关的程序代码,获取内存占用的方法采用了重载全局 new 操作符的方式:
// C++
void* operator new(std::size_t count)
{
mem_record::add_mem(count);
return malloc(count);
}
比起之前C#的实现,C++的实现就显的"底层"很多,需要考虑不少额外的代码细节,当然,程序的自由度也更高了.
实现过程中自然也有不少意外,其中一个觉得挺有意思:
C/C++ 中多维数组的动态申请
C/C++ 中动态申请一维数组对于大部分朋友来说应该是轻车熟路:
// C++
T* array = new T[array_size];
不想自己管理内存的朋友可能还会使用 std::vector<T> 之类的容器.
但是对于多维数组,似乎动态申请的方式就没有这么直观了:
// C++
int** array = new int*[row];
for (int i = 0; i < row; ++i)
{
array[i] = new int[col];
}
概念上其实就是"数组的数组",同样的,如果使用容器,你就需要 std::vector<std::vector<T>> 这样的定义.
但如果考虑到数据缓存,代码复杂度等因素,个人还是建议将多维数组展平为一维数组,并提供多维方式的访问接口:
// C++
// create array
T* array = new T[row * col];
memset(array, T(), row * col * sizeof(T));
// get array
array[i * col + j];
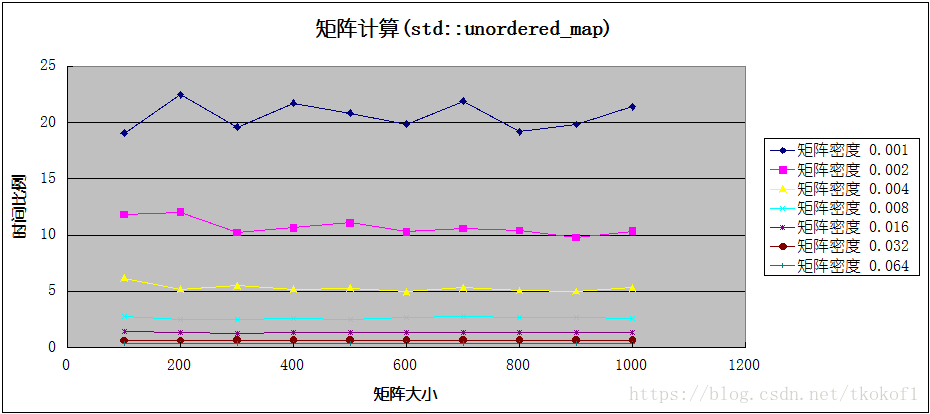
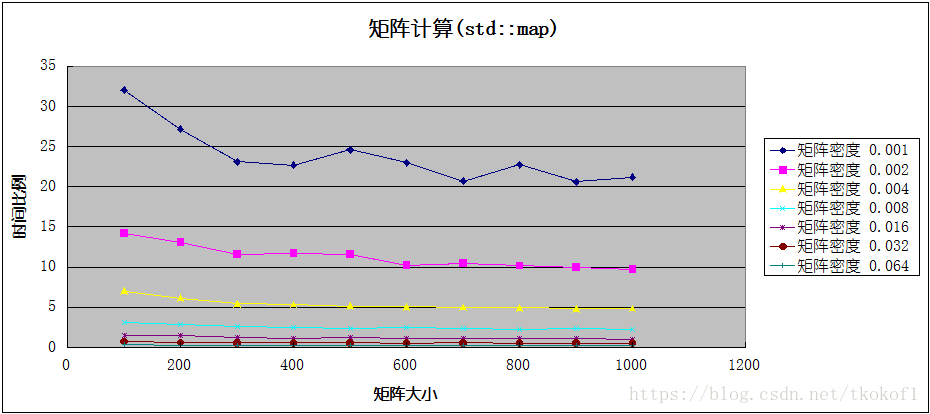
代码分别使用了 std::map 和 std::unordered_map 作为底层容器实现了稀疏矩阵,并与基于数组实现的普通矩阵进行了程序效率和空间使用上的对比,下图中的横坐标是矩阵的大小,纵坐标是数据比值(普通矩阵的对应数值/稀疏矩阵的对应数值),各条折线代表不同的矩阵密度(矩阵非0元素个数/矩阵所有元素个数).
这是矩阵运算效率(执行加法)的比较结果:
这是矩阵内存空间占用的比较结果:
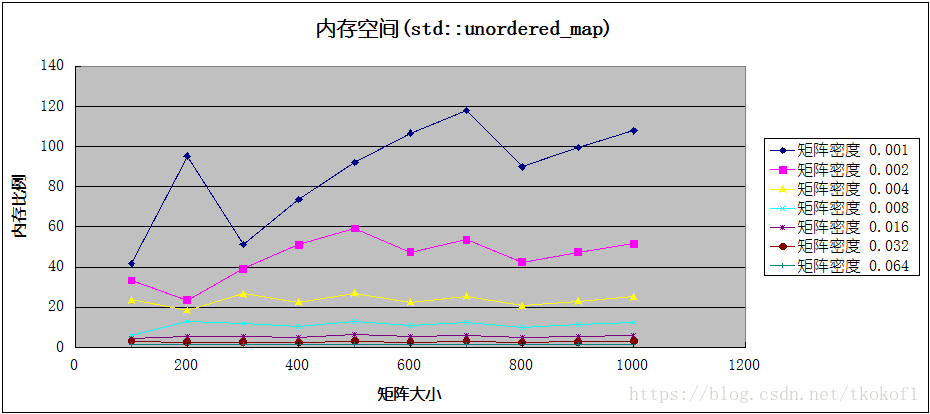
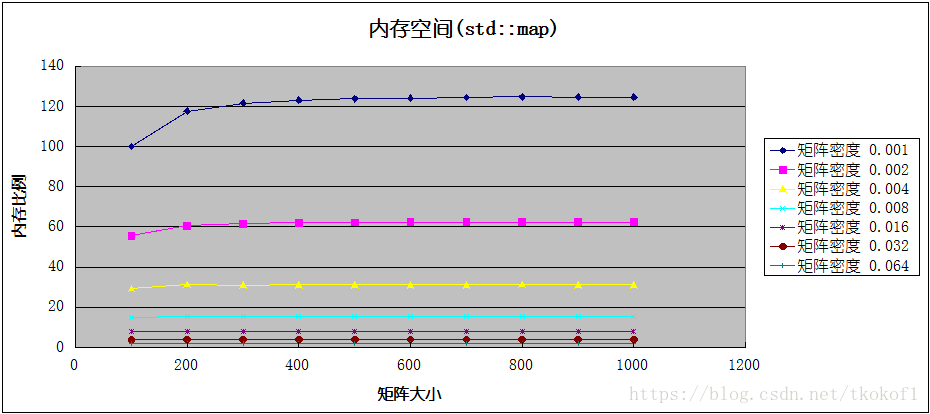
当矩阵密度较小时(<=0.016),稀疏矩阵在运算效率和内存占用上都优于普通矩阵,在密度极小时(<=0.002),稀疏矩阵在这两方面的优势是普通矩阵的数十倍(甚至上百倍),但随着矩阵密度的增加(>0.016),稀疏矩阵的运算效率便开始低于普通矩阵,并且内存占用的优势也变的不再明显,甚至高于普通矩阵.考虑到矩阵的临界密度较低(0.016,意味着10x10的矩阵只有1-2个非0元素),所以实际开发中不建议使用稀疏矩阵的实现方式,除非你能确定处理的矩阵密度大部分都小于临界值.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK