

中科院自动化所陈玉博:事件抽取与金融事件图谱构建
source link: https://zhuanlan.zhihu.com/p/45583498
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
中科院自动化所陈玉博:事件抽取与金融事件图谱构建
2018年9月16日,第27期智能金融沙龙于杭州成功举办,文因互联 CEO 鲍捷、中科院自动化所陈玉博、文因互联华东地区商务总监朱衡利分享了知识图谱技术发展以及实际落地案例。
以下为陈玉博老师演讲《事件抽取与金融事件图谱构建》内容节选。
陈玉博:大家好,我是中国科学院自动化所的陈玉博,很高兴能和大家分享事件抽取和金融事件图谱构建方向的一些探索。
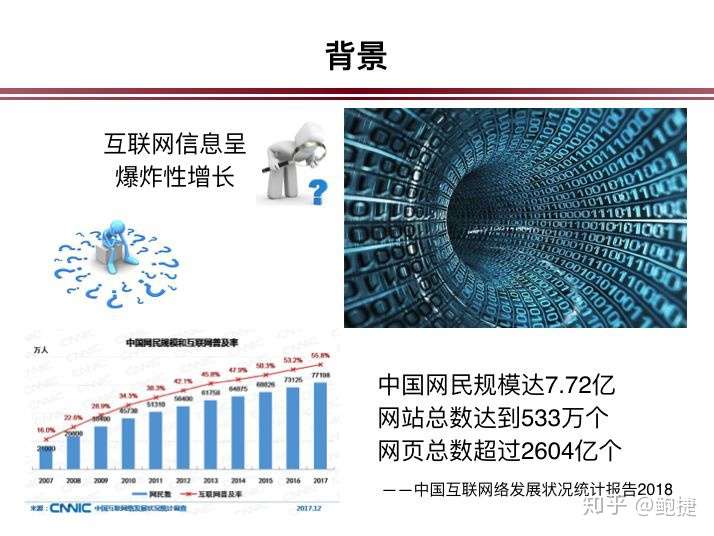
现在互联网信息呈爆炸性增长,据中国互联网中心2018年发布的数据显示,截止到2017年12月,网民规模达到了7.72亿,网页总数也超过了2600亿。如何快速地去获取海量信息当中所需要的知识,尤为重要。
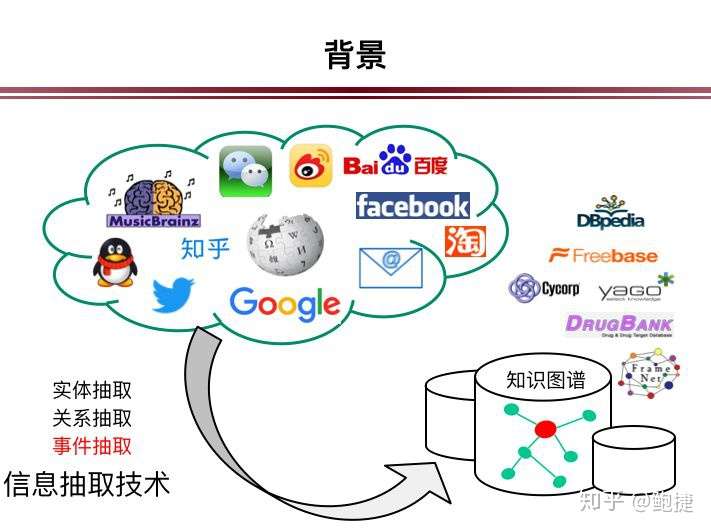
随着需求的产生,信息抽取技术也获得了进一步发展。
如鲍捷博士刚才提到,通过语义注释,可以把非结构化的文本转变成结构化的文本,构建大规模的知识图谱,就能把很多计算机不理解的东西,变成计算机所理解的东西,进而辅助我们的工作。
信息抽取技术包括实体抽取、关系抽取和事件抽取三个重要部分,今天我主要分享事件抽取。
维特根斯坦在《逻辑哲学论》当中就说“世界是所有事实,而不是事物的总和”,其实就是说事实在现实世界当中的表现就是一个一个的事件。一个事件会涉及到多个事物,而事物其实就是刚才鲍捷博士所说的实体,有可能是人、机构,或者是各种物件。
其实很多行为学家还有认知学家认为,我们是以事件为单位去认知和体验世界的。
比如我们一说到地震,就会有可能想到震中、时间、地点,当然也会想到它的一些子事件,比如抗震救援,但是也不能一刀切,实体和关系在我们脑海当中也是存在的。
我们可以把实体和事件看作两类,实体是一种静态的,而事件偏动态。在金融领域,这两个方向应该都关注。

构建一个事件图谱能丰富现有的以实体为核心的知识图谱。除此之外,它能支撑很多信息检索,比如说问地震遇难人数,它能给一个具体的数。另外还可以对一个企业或者是一支股票进行很多事件的监控。
事件图谱构建关键:事件抽取以及事件关系抽取
如何定义一个事件呢? 事件起源于认知科学,常常在哲学、语言学、计算机科学等领域被广泛讨论。但遗憾的是目前对事件还没有统一的定义,在不同领域,针对不同的应用,不同的人对事件有不同的描述。
在知识图谱领域,事件是发生在某个特定的时间点或时间段、某个特定的地域范围内,由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变
基于定义,我们在建模的时候就有几点需要注意。
首先就是不同动作或者状态的改变是不同类型的事件,就比如说奥巴马上任和奥巴马离任这都是两个类型的事件。
同一类型的事件中不同的元素代表了不同的事件,比如奥巴马上任和特朗普上任,这是两个事件。
同一个类型的事件中不同粒度的元素代表不同粒度的事件。事件之间其实有很多关系,其中子事件就是一个比较有代表性的,同样是战争类型的事件,持续的时间或者元素的粒度不一样,就有二战、抗日战争和淞沪会战之分,它们是不同粒度的事件。
构建一个事件图谱有两项关键技术,第一是事件抽取,第二是事件关系抽取。
事件抽取分两个步骤:第一步就是事件的发现和抽取,第二个是事件元素的抽取。事件发现是你要让计算机知道读完这一句话,是哪一个词触发了这个类型的事件并且判断它触发什么类型。
然后是事件元素抽取,就是说你要让计算机判断出参与这个事件所有的元素是什么,并且它们在这个事件当中扮演一个什么角色,比如说美团和大众点评合并这样一个事件,其实它描述的就是一个公司合并事件。美团和大众点评在这里就是两个参与者了,10月8日就是合并事件发生的时间,这是我们希望计算机能自动从文本当中提取出来的。
另外一个就是事件关系抽取,事件关系给大家介绍四类:共指,时序,因果和子事件。
共指。比如说一个事件你会有不同的新闻来源,去描述它不同的侧面,如果识别出这些不同的描述,描述的都是同一个事件,就能判断这是共指关系,这样你就能从各个角度全方位地去认识这个事件,并且追踪这个事件。
因果。有了因果关系以后,就可以做很多风控或者是预测。比如日本大地震导致了海啸,最后导致了核泄露。类似这样的因果关系能对风控和预测有参考价值。
时序。你只要把一个事件结构化,就有时间信息,时序就比较清晰了。
还有一个就是子事件。
事件图谱在金融领域的应用
了解了事件的建模、事件图谱的关键技术之后,接下来给大家讲讲我们在金融领域做的尝试——篇章级金融事件抽取。主要解决的问题是如何从金融公告当中抽取出结构化的事件信息,比如说抽取出冻结、质押、增减持等公告。
先说说两大挑战,一个是篇章级的抽取,一个是标注数据的缺失。
学术界的研究和真实场景的应用之间存在一些区别。学术界做的大多数是国际上公开定义的任务,给你一个句子,你抽取它触发了什么类型的事件,更多体现出实验的思维,控制变量。但是真实场景要求你从公告或者是一个研报这样篇章级别的文件中去抽取一个结构化的事件,通常由多个句子描述一个事件,一个事件的多个元素分布在不同的句子中,不确定性加大,难度加大。
另外一个问题,现有的事件抽取系统性能都依赖于人工标注数据,现在没有一份公开做这个任务的语料,人工标注数据耗时费力,成本高昂,金融领域缺乏大规模高质量的标注数据。没有这样的语料很难去做这件事情,所以我们也是在原来所有工作的基础之上,做了一些改进,在金融领域做了一个简单的尝试。
针对这两个挑战,我们做了两个任务,第一个就是自动生成标注数据,利用现有的一些结构化的事件信息,然后去公开文档当中自动生成标注数据。
有了数据以后,我们还要做一个篇章级的抽取。
先做一个句子级的抽取,采用一个序列标注的模型,双向LSTM+CRF。但很多情况下一个事件是由篇章当中的不同句子去描述的,你需要从不同的句子当中抽取出来对应的元素,去构成一个这样的一个完整事件,那么你就要从多句话当中,识别出来哪个是主句,这个是用一个 CNN 分类的模型去做的,模型中不仅考虑了文本特征,还同时考虑了对于那个句子分析的结果。找到主句以后,这一个主句有可能描述得不全面,你又从它上下文档中,把对应的角色给补齐。
我们针对冻结、回购、增减持,还有质押这四个事件类型做了一个简单的实验,在我们比较擅长的句子级事件领域,平均做到了大概 F 值 90% 左右,但是如鲍老师所说,其实这个 90%多的性能的系统到实际应用,还需要大量的工程和工业界的努力。
我们开发了一个demo系统,可以对全篇公告进行分析,首先针对每个句子进行分析,分析结果示如demo页面1。
分析完以后,找到主句,然后再上下文补齐,例如图片中的例子中整篇公告描述的是一个冻结的事件,但是主句子只描述了4个角色,而完整的冻结事件至少要提取6个角色,主句中缺乏的是起始和结束时间,这两个元素需要从别的句子当中补齐,最终结果如demo页面2所示。
简单总结一下,其实事件知识在知识图谱以及很多智能应用当中都是不可缺少的。在金融领域,比如企业信息监控、风险信用控制和智能投顾等方面都能发挥积极作用。
在通用领域的事件抽取其实是很难的,难在大规模、高质量的训练数据的缺失,还有鲁棒特征的提取。相比较而言,在限定领域,尤其是金融领域的事件抽取,是有可能取得不错的效果的,在限定领域,它的文本类型受限,语言表述的规律性也比较强,而且它是知识密集型的。目前在金融领域的实践中已经证明能够替代部分人工,提取的精确度能随着样本量的增加以及算法的优化而不断提高,可用性程度会进一步扩大,事件抽取以及事件图谱的构建在金融领域的影响力也必将不断增强。
拓展阅读:
如果你还不熟悉文因互联:文因互联是位于北京的智能金融创业公司。技术团队来自MIT、RPI、IBM、Samsung等知名大学和公司,深耕人工智能十余年,是知识图谱领域的领军团队。我们用人工智能技术解决交易所、银行、券商等面临的投资研究、自动化监管、投资顾问等问题。经过两轮融资,财务健康,目前市场拓展顺利,也建立了良好的行业口碑。
以下招聘岗位职责描述仅供参考,请不要让它们限制住你的想象和勇气。
前端工程师
【岗位职责】
1. 负责与产品需求和设计团队、开发架构团队密切配合,完成前端框架设计和技术实现方案
2. 负责按照各类需求文档和设计文档,完成前端代码开发
3. 负责创建用户友好、符合标准的跨浏览器应用
4. 遵循并参与项目开发规范和开发流程
【优先考虑】
1. 精通 HTML5、CSS3、ES6 等 Web 前端开发技术
2. 熟悉 JavaScript 面向对象编程、函数式编程及其相关设计模式
3. 熟悉 React /Vue技术栈,了解 Redux/Vuex 或基于它们二次开发的状态管理框架
4. 熟悉 webpack、Babel、npm/Yarn 等现代前端开发工具
NLP工程师
【岗位职责】
1. 信息抽取、文本摘要、自动问答等方面的研发以及语言资源/知识库维护
2. 金融知识图谱构建
3. 客户项目开发
【优先考虑】
1. 有自然语言处理经验,熟悉分词、实体识别等NLP基本模块(知道基本原理,并且使用过某个相关库)
2. 有Python项目开发经验,熟悉collections标准库下的数据结构
3. 可以完全在linux下工作
4. 有git开发项目经验,并能描述自己的workflow
5. 良好的沟通能力,一定的学习能力
【加分项】
1. 遵循良好的代码风格(如Google Style或PEP8)。
2. 有全周期项目开发经验加分。有开源项目、个人微博、博客证明自己者优先
3. 熟悉机器学习、深度学习,有使用深度学习在NLP中的应用经验,熟悉至少一种开源库,如tensorflow。
【岗位职责】
1. 完成年度商务指标和相应营销工作
2. 完成所在区域金融客户的跟踪推进工作。包括拜访区域内各主要银行、券商等金融机构、发展维护渠道合作伙伴关系
3. 组织协调公司资源,完成与客户签约相关的招投标、谈判、签约、收款及售后客户关系工作
4.维护本地金融客户日常关系,收集反馈客户对公司产品和服务等方面的意见
【优先考虑】
1. 统招本科及以上学历,特别优秀者可放宽,专业、工作经验不限。
2. 喜欢与客户交流沟通,能适度出差
3. 具有良好的自我学习能力与团队合作精神,有强烈责任感。
4.对金融、银行、证券等业务熟悉的优先,有计算机专业背景的优先。
数据标注实习生
【岗位职责】
1. 使用标注工具,针对文本数据进行归类、整理、标注。
2. 学习标注规则,及时反馈标注质量及进度。
3. (如有编程能力)协助编写数据清理和处理代码。
【优先考虑】
1. 本科或硕士在校生优先,专业不限。
2. 对数据敏感,细致踏实;有较强的沟通能力。
3. 每周出勤时间不少于3天,最好能连续实习两个月。
【加分项】(非必须项):
1. 有一定的编程能力,熟悉 Python。
2. 有数据标注和校验经验。
3. 有语言学、自然语言处理或金融、财会背景。
是人才我们都不想错过,欢迎你过来一起聊聊。公司博客是 http://blog.memect.cn/ 主页是 http://memect.cn/
简历投递地址:[email protected] 等着你来!
加入智能金融交流群
添加微信群小助手微信号 wenyinai42,附上姓名、所属机构、部门及职位,审核后小助手会邀请您入群。文因商务合作请另联系微信号:wenyinba
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK