

Apple M1 foreshadows Rise of RISC-V
source link: https://erik-engheim.medium.com/apple-m1-foreshadows-risc-v-dd63a62b2562
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Apple M1 foreshadows Rise of RISC-V
The M1 is the beginning of a paradigm shift, which will benefit RISC-V microprocessors, but not the way you think.


By now it is pretty clear that Apple’s M1 chip is a big deal. And the implications for the rest of the industry is gradually becoming clearer. In this story I want to talk about a connection to RISC-V microprocessors which may not be obvious to most readers.
Let me me give you some background first: Why Is Apple’s M1 Chip So Fast?
In that story I talked about two factors driving M1 performance. One was the use of massive number of decoders and Out-of-Order Execution (OoOE). Don’t worry it that sounds like technological gobbledegook to you.
This story will be all about the other part: Heterogenous computing. Apple is aggressively pursued a strategy of adding specialized hardware units, I will refer to as coprocessors throughout this article:
- GPU (Graphical Processing Unit) for graphics and many other tasks with a lot of data parallelism (do the same operation on many elements at the same time).
- Neural Engine. Specialized hardware for doing machine learning.
- Digital Signal processing hardware for image processing.
- Video encoding in hardware.
Instead of adding a lot more general purpose processors to their solution, Apple has started adding a lot more coprocessors to their solution. You could also use the term accelerator.
This isn’t an entirely new trend, my good old Amiga 1000 from 1985 had coprocessors to speed up audio and graphics. Modern GPUs are essentially coprocessors. Google’s Tensor Processing Units are a form of coprocessors used for machine learning.

What is a Coprocessor?
Unlike a CPU, a coprocessor cannot live alone. You cannot make a computer by just sticking a coprocessor into it. Coprocessor as special purpose processors which do a particular task really well.
One of the earliest examples of a coprocessors was the Intel 8087 floating point unit (FPU). The humble Intel 8086 microprocessor could perform integer arithmetic but not floating point arithmetic. What is the difference?

Integers are whole numbers like this: 43, -5, 92, 4.
These are fairly easy to work with for computers. You could probably wire together a solution to add integer numbers with some simple chips yourself.
The problem starts when you want decimals. Say you want to add or multiply numbers such as 4.25, 84.7 or 3.1415.
These are examples of floating point numbers. If the number of digits after the point was fixed, we would call it fixed point numbers. Money is often treated this way. You usually have two decimals after the point.
You can however emulate floating point arithmetic with integers, it is just slower. That is akin to how early microprocessors could not multiply integers either. They could only add and subtract. However one could still perform multiplication. You just had to emulate it will multiple additions. For instance 3 × 4 is simply 4 + 4 + 4.
It is not important to understand the code example below, but it may help you understand how multiplication can be performed by a CPU only by using addition, subtraction and branching (jumping in code).
loadi r3, 0 ; Load 0 into register r3
multiply:
add r3, r1 ; r3 ← r3 + r1
dec r2 ; r2 ← r2 - 1
bgt r2, multiply ; goto multiply if r2 > 0
If you do want to understand microprocessors and assembly code, read my beginner friendly intro: How Does a Modern Microprocessor Work?
In short, you can always achieve more complex math operations by repeating simpler ones.
What all coprocessor do is similar to this. There is always a way for the CPU to do the same task as the coprocessor. However this will usually require repetition of multiple simpler operations. The reasons we got GPUs early on, was that repeating the same calculations on millions of polygons or pixels was really time consuming for a CPU.
How Data is Transmitted to and from Coprocessors
Let us look at the diagram below to get a better sense of how a coprocessor work together with the microprocessor (CPU), or general purpose processor, if you will.
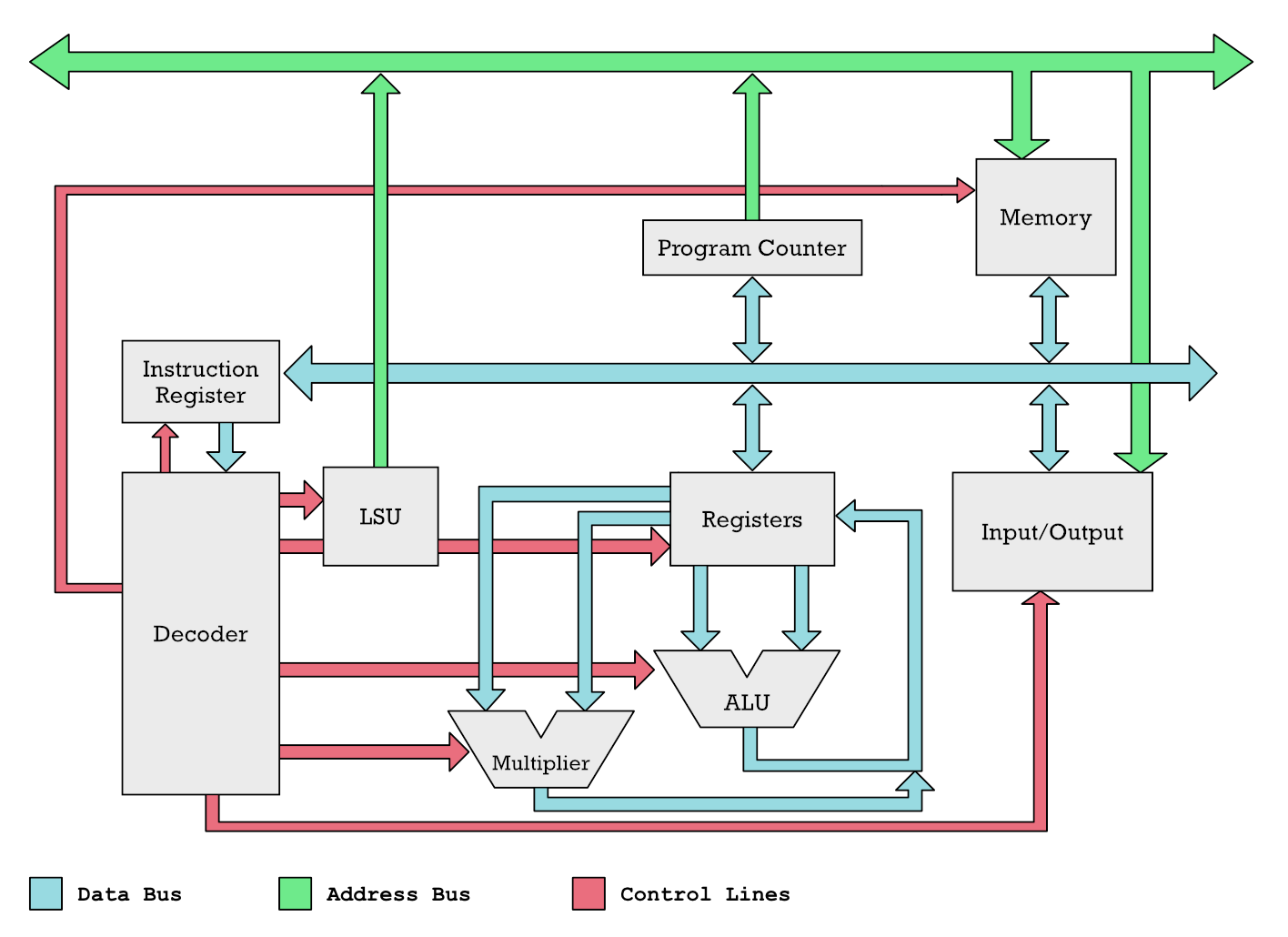
We can think of green and light blue busses as pipes. Numbers are pushed through these pipes to reach different functional units of the CPU (drawn as gray boxes). The inputs and outputs of these boxes are connected to these pipes. You can think of the inputs and outputs of each box as having valves. The red control lines are used to open and close these valves. Thus the Decoder, in charge of the red lines, can open valves on two gray boxes to make numbers flow between them.
This lets us explain how data is fetched from memory. To perform operations on numbers we need them in registers. The Decoder uses the control lines to open the valves between the gray Memory box and the Registers box. This is how it specifically happens:
- The Decoder opens a valve on Load Store Unit (LSU) which causes a memory address to flow out on the green address bus.
- Another valve is opened on the Memory box, so it can receive the address. It gets delivered by the green pipe (address bus). All other valves are closed so e.g. Input/Output cannot receive the address.
- The memory cell with the given address is selected. Its content flows out onto the blue data bus, because the Decoder has opened the valve to the data bus.
- The data in the memory cell could flow anywhere, but the Decoder has only opened the input valve to the Registers.
Things like mouse, keyboard, the screen, GPU, FPU, Neural Engine and other coprocessors are equal to the Input/Output box. We access them just like memory locations. Hard drives, mouse, keyboard, network cards, GPU, DMA (direct memory access) and coprocessors all have memory addresses mapped to them.
Hardware is accessed just like memory locations by specifying addresses.
What exactly do I mean by that? Well let me just make up some addresses. If you processor attempts to read from memory address 84 that may mean the x-coordinate of your computer mouse. While say 85 means the y-coordinate. So to get a mouse coordinates you would do something like this in assembly code:
load r1, 84 ; get x-coordinate
loar r2, 85 ; get y-coordinate
For a DMA controller there might might be address 110, 111 and 113 which as special meaning. Here is an unrealistic made up assembly code program using this to interact with the DMA controller:
loadi r1, 1024 ; set register r to source address
loadi r2, 50 ; bytes to copy
loadi r3, 2048 ; destination address
store r1, 110 ; tell DMA controller start address
store r2, 111 ; tell DMA to copy 50 bytes
store r3, 113 ; tell DMA where to copy 50 bytes to
Everything works in this manner. You read and write to special memory addresses. Of course a regular software developers never sees this. This stuff is done by device drivers. The programs you use only see virtual memory addresses where this is invisible. But the drivers will have these addresses mapped into its virtual memory addresses.

I am not going to say too much about virtual memory. Essentially we got real addresses. The addresses on the green bus will get translated from virtual addresses to real physical addresses. When I began programming in C/C++ in DOS, there was no such thing. I could just set a C pointer to point straight to a memory address of the video memory and start writing straight to it to change the picture.
char *video_buffer = 0xB8000; // set pointer to CGA video buffer
video_buffer[3] = 42; // change color of 4th pixel
Coprocessors work the same way as this. The Neural Engine, GPU, Secure Enclave and so on will have addresses you communicate with. What is important to know about these as well as something like the DMA controller is that they can work asynchronously.
That means the CPU can can arrange a whole bunch of instructions for the Neural Engine or GPU which it understands and write these into a buffer in memory. Afterwards it informs the Neural Engine or GPU coprocessor about location of these instructions, by talking to their IO addresses.
You don’t want the CPU to sit there and idle waiting for the coprocessor to chew through all the instructions and data. You don’t want to do that with the DMA either. That is why usually you can provide some kind of interrupt.
How does an Interrupt Work?
Various cards you stick into your PC, whether they are graphics cards or network cards will have assigned some interrupt line. It is kind of like a line that goes straight to your CPU. When this line get activated, the CPU drops everything it is holding to deal with your interrupt.
Or more specifically. It stores in memory its current location and the values of its registers, so it can return to whatever it was doing later.
Next it looks up in a so called interrupt table what to do. The table has an address of a program you want to run when that interrupt is triggered.
As a programmer you don’t see this stuff. To you it will appear more like callback functions which you register for certain events. Drivers typically handle this at the lower level.
Why am I telling you all these nerdy details? Because it helps develop an intuition about what is going on when you use coprocessors. Otherwise it is unclear what communicating with a coprocessor actually entails.
Using interrupts allow lots of things to happen in parallel. An application may fetch an image from the network card, while the CPU is interrupted by the computer mouse. The mouse has been moved and we need the new coordinates. The CPU can read these and send them to the GPU, so it can redraw the mouse cursor in the new location. When the GPU is drawing the mouse cursor the CPU could begin processing the image retrieved from the network.
Likewise with these interrupts we can send complex machine learning tasks to the M1 Neural Engine to say identify a face on the WebCam. Simultaneously the rest of the computer is responsive because the Neural Engine is chewing through the image data in parallel to everything else the CPU is doing.

The Rise of RISC-V
Back in 2010 at UC Berkley the Parallel Computing Laboratory saw the development towards heavier use of coprocessors. They saw how the end of Moore’s Law meant that you could no longer easily squeeze more performance out of general purpose CPU cores. You needed specialized hardware: Coprocessors.
Let us reflect momentarily on why that is. We know that the clock frequency cannot easily be increased. We are stuck on close to 3–5 GHz. Go higher and Watt consumption and heat generation goes through the roof.
However we are able to add a lot more transistors. We simply cannot make the transistors work faster. Thus we need to do more work in parallel. One way to do that is by adding lots of general purpose cores. We could add lots of decoders and do Out-of-Order Execution (OoOE) as I have discussed before: Why Is Apple’s M1 Chip So Fast?
You can keep playing that game and eventually you have 128 general cores like the Ampere Altra Max ARM processor. But is that really the best use of our silicon? For servers and cloud services lots of cores work well. But for desktop computing this has limited utility.
Instead of spending all that silicon on more CPU cores, perhaps we can add more coprocessors instead?
Think about it this way: You got a transistor budget. In the early days, maybe you had a budget of 20 000 transistors and you figured you could make a CPU with 15 000 transistors. That is close to reality in the early 80s. Now this CPU could do maybe 100 different tasks. Say making a specialized coprocessor to one fo these tasks cost you 1000 transistors. If you made a coprocessor for every task you would get to 100 000 transistors. That would blow your budget.
Thus in early designs you need to focus on general purpose computing. But today, we can stuff chips with so many transistors, we hardly know what to do with them.
Thus designing coprocessors has become a big thing. A lot of research goes into making all sorts of new coprocessors. However these tend to contain pretty dumb accelerators which needed to be babied. Unlike a CPU they cannot read instructions which tells them all the steps to do. They don’t generally know how to access memory and organize anything.
Thus the common solution to this is to have a simple CPU as a sort of controller. So the whole coprocessor is some specialized accelerator circuit controlled by a simple CPU, which configures the accelerator to do its job. Usually this is highly specialized. For instance, something like a Neural Engine or Tensor Processing Unit deal with very large registers that can hold matrices (rows and columns of numbers).
This is exactly what RISC-V got designed for. It has a bare minimum instruction-set of about 40–50 instructions which lets it do all the typical CPU stuff. It may sound like a lot, but keep in mind that an x86 CPU has over 1500 instructions.
Instead of having a large fixed instruction-set, RISC-V is designed around the idea of extensions. Every coprocessor will be different. It will thus contain a RISC-V processor to manage things which implements the core instruction-set as well as an extension instruction-set tailor made for what that co-processor needs to do.
Okay, now maybe you start to see the contours of what I am getting at. Apple’s M1 is really going to push the industry as whole towards this coprocessor dominated future. And to make these coprocessors, RISC-V will be an important part of the puzzle.
But why? Can’t everybody making a coprocessor just invent their own instruction-set? After all that is what I think Apple has done. Or possibly they use ARM. I have no idea. If somebody knows, please drop me a line.
What is the Benefit of Sticking with RISC-V for Coprocessors?
Making chips have become a complicated and costly affair. Building up tools to verify your chip. Run tests programs, diagnosis and a host of other things requires a lot of effort.
This is part of the value of going with ARM today. They have a large ecosystem of tools to help verify your design and test it.
Going for custom proprietary instruction-sets is thus not a good idea. However with RISC-V there is a standard which multiple companies can make tools for. Suddenly there is an eco-system and multiple companies can share the burden.
But why not just use ARM which is already there? You see ARM is made as a general purpose CPU. It has a large fixed instruction-set. After pressure from customers and RISC-V competition ARM has relented and in 2019 opened its instruction-set for extensions.
Still the problem is that it wasn’t made for this from the onset. The whole ARM toolchain is going to assume you got the whole large ARM instruction set implemented. That is fine for the main CPU of a Mac or an iPhone.
But for a coprocessor you don’t want or need this large instruction-set. You want an eco-system of tools that have been built around the idea of a minimal fixed base instruction-set with extensions.
Why is that such a benefit? Nvidia’s use of RISC-V offers some insight. On their big GPUs they need some kind of general purpose CPU to be used as a controller. However the amount of silicon they can set aside for this, and the amount of heath it is allowed to produce is minimal. Keep in mind that lots of things are competing for space.
Because RISC-V has such a small and simple instruction-set it beat all the competition, including ARM. Nvidia found they could make smaller chips by going for RISC-V than for anybody else. They also reduced watt usage to a minimum.
Thus with the extension mechanism you can limit yourself to adding only the instructions crucial for the job you need done. A controller for a GPU likely needs other extensions than a controller on an encryption coprocessor e.g.
ARM Will be the New x86
Thus ironically we may see a future where Macs and PCs are powered by ARM processors. But where all the custom hardware around them, all their coprocessors will be dominated by RISC-V. As coprocessor get more popular more silicon in your System-on-a-Chip (SoC) may be running RISC-V than ARM.
Read more: RISC-V: Did Apple Make the Wrong Choice?
When I wrote the story above, I had not actually fully grasped what RISC-V was all about. I though the future would be about ARM or RISC-V. Instead it will likely be ARM and RISC-V.
General purpose ARM processors will be at the center with an army of RISC-V powered coprocessors accelerating every possible task from graphics, encryption, video encoding, machine learning, signal processing to processing network packages.
Prof. David Patterson and his team at UC Berkeley saw this future coming and that is why RISC-V is so well tailored to meet this new world.
We are seeing such a massive uptake and buzz around RISC-V in all sorts of specialized hardware and micro-controllers that I think a lot of the areas dominated by ARM today will go RISC-V.

Imagine something like Raspberry Pi. Now it runs ARM. But future RISC-V variants could offer a host of variants tailored for different needs. There could be machine learning microcontrollers. Another can be image processing oriented. A third could be for encryption. Basically you could pick your own a little micro-controller with its own little flavor. You may be able to run Linux on it and do all the same tasks, except the performance profile will be different.
RISC-V microcontrollers with special machine learning instructions will train neural networks faster than the RISC-V microcontroller with instructions for video encoding.
Nvidia has already ventured down that path with their Jetson Nano, shown below. It is a Raspberry Pi sized microcontroller with specialized hardware for machine learning, so you can do object detection, speech recognition and other machine learning tasks.

Share Your Thoughts
Let me know what you think. There is a lot going on here which is hard to guess. We see e.g. now there are claims of RISC-V CPUs which really beats ARM on watt and performance. This also makes you wonder if there is indeed a chance that RISC-V becomes the central CPU of computers.
I must admit it has not been obvious to me why RISC-V would outperform ARM. By their own admission, RISC-V is a fairly conservative design. They don’t use much instructions which have not already been used in some other older design.
However there seems to be a major gain from pairing everything down to a minimum. It makes it possible to make exceptionally small and simple implementations or RISC-V CPUs. This again makes it possible to reduce Watt usage and increase clock frequency.
Hence the last word on RISC-V and ARM is not yet said.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK