

Bellman, Dynamic Programming, and Edit Distance | Gödel's Lost Letter and P=NP
source link: https://rjlipton.wordpress.com/2009/03/22/bellman-dynamic-programming-and-edit-distance/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Bellman, Dynamic Programming, and Edit Distance
Approaches to the exact edit distance problem

Richard Bellman created the method of dynamic programming in 1953. He was honored with many awards for this and other seminal work, during his lifetime. We probably all know dynamic programming, use it often to design algorithms, and perhaps take it for granted. But, it is one of the great discoveries that changed the theory and practice of computation. One of the surprises–at least to me–is given its wide range of application, it often yields the fastest known algorithm. See our friends at Wikipedia for a nice list of examples of dynamic programming in action.
I never had the honor of meeting Bellman, but he wrote a terrific short autobiographical piece that contained many interesting stories. (I cannot locate it anymore: if you can please let me know.) One story that I recall was how, when he was at The Rand Corporation, he often made extra money playing poker with his doctor friends in the evenings. He usually won, which convinced them that he was using “deep mathematics” against them–perhaps probability theory. Bellman said the truth was much simpler: during the day the doctors were stressed making life and death decisions, at night when they played poker they “let go”. During the day Bellman could just look out at the Pacific Ocean from his office and think about problems. At night he played tight simple poker, and he cleaned up.
One other story from this piece made a long-lasting impression on me. When he was famous he would often be invited to places to give talks, like many scientists. However, he always insisted that he must be picked up at the airport by a driver of a white limo. I understand the driver part, I understand the limo part, but insisting on the color was a very nice touch.
The Edit Distance Problem
The edit distance problem (EDP) is given two strings

determine their edit distance. That is what are the fewest operations that are needed to transform string 

This distance is sometimes called the Levenshtein distance, named after Vladimir Levenshtein, who defined it in 1965. The notation of edit distance arises in a multlude of places and contexts, I believe that the notion has been repeatedly discovered. It also has many generalizations where more complex operations are allowed.
People really care about EDP. There are very good heuristic algorithms that are used, for example, in the biological community to solve EDP. One is called BLAST. It is implemented in many languages and runs on everything, there are even special purpose hardware devices that run BLAST. Clearly, there is need for solutions to EDP. Unlike theory algorithms, BLAST has no provable error bounds; unlike theory algorithms, BLAST seems, in practice, to be good enough for the scientists who use it. However, I have no doubt that they would prefer to get the optimal answer–however, the cost of getting the optimal answer cannot be too great.
Upper and Lower Bounds
The dynamic programming algorithm for EDP has been discovered and rediscovered many times. I believe that Robert Wagner and Mike Fischer did it first, but I will not try to be the perfect historian. Their algorithm runs in time 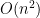
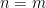

There are papers that prove a lower bound of 
Actually, as I recall, there was a bit of an inversion here: there was a better upper bound paper that gave an algorithm for EDP that took time 
The Four Russian Method was first, I believe, used to compute boolean matrix products faster than cubic time. The method has been used since then to solve many other problems. If you do not know the method, take a look at the following link.
Still here. Okay, here is an overview of the method: it is based on trading space for time. A typical Four Russian Method algorithm operates in two phases. In the first phase, it examines the input and cleverly pre-computes values to a large number of subproblems, and stores these values in a look-up table. In the second phase, it uses the pre-computed values from the table to make macro steps during the rest of the computation. The result is usually a reduction in time by a logarithmic factor, while the space becomes as large as the time. The method is not generally practical; however, it is a useful method to know.
Bit Complexity
Actually there is a logarithmic factor that is hidden in the quadratic dynamic programming algorithm for EDP, since the algorithm must use 

Theorem 1 There is an algorithm for EDP that uses
bit operations and
space.
Proof: The key idea is to use only a constant number of bits rather than

I will explain this in more detail in a future post. Truth in blogging: Lopresti was once a graduate student of mine, and I worked with him on this result.
Approximation and EDP
Legend has it that when faced with unravelling the famous Gordian Knot, Alexander the Great simply cut the knot with his sword. We do this all the time in theory: when faced by a “knotty” problem we often change the problem. The edit distance problem is any not different: years ago the problem of exact distance was changed to approximate edit distance. The goal is to get a fast algorithm that finds the distance to within a small relative error. For example, in the STOC 2009 conference there will be a paper “Approximating Edit Distance in Near-Linear Time” by Alexandr Andoni and Krzysztof Onak. They show that there is an algorithm (AO) that in time 

This is a huge improvement over the previous work. I will not go into any details today, see their paper for the full proofs.
This is very pretty work. I have started to look at their paper and believe that it has many interesting ideas, they may even help solve other problems. My issue is that we still are no closer to solving the edit distance problem. The AO algorithm still makes too large relative error to be practical–what exactly is the factor for reasonable size 
On the other hand, I am intrigued with their breakthrough. I think that it may be possible to use their new algorithm as a basis of an exact algorithm. The key idea I have in mine is to try to use their algorithm combined with some kind of “amplification trick.”
Amplification
Papers on approximations to the EDP use “relative” error, so let’s take a look at additive error. Suppose that 
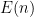


There is a simple amplification trick:
Theorem 1 Suppose there is an algorithm
for the EDP that runs in time
and has additive error
. Then, there is an algorithm
for the EDP that runs in time
and has an additive error of
.
I assume that this is well known, but in case not, here is a sketch of the proof. Suppose that 



The claim is that provided 

It should be clear that

since one way to change 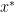
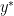

The opposite inequality follows since any matching of the first 

and therefore,

Divide by 


I conjecture that there is a general construction that can replace 



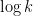
If such an amplification were possible, then we could do the following, for example: if there is an algorithm that runs in near linear time, i.e. time 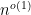

I have started thinking about the AO algorithm and how to combine it with different amplification methods. Perhaps this could lead, finally, to a fast exact algorithm for EDP. Perhaps. In any event such amplification methods seem potentially useful.
Open Problems
Thus, the main open problem is clear: find an EDP algorithm that runs in 
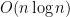
There are other, perhaps, more approachable open problems. In real applications the inputs are not worst case, nor are they random. For instance, the BLAST program assumes implicitly a kind of randomness to the inputs. Are there reasonable models of the kinds of inputs that are actually encountered? And for such a model can we get provable fast algorithms for EDP?
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK