

广度优先遍历搜索的最通俗介绍,如何实现广度优先搜索算法?广度优先遍历搜索可用于哪...
source link: https://blog.popkx.com/basic-introduction-of-Breadth-First-Search-Algorithm-how-to-implement-Breadth-First-Search-Algorithm-where-i-can-use-it/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
图遍历搜索算法是一种非常迷人的算法,它是一种将抽象枯燥的逻辑与较为直观的“图”相结合的算法。本文将讨论图遍历搜索算法背后的逻辑,并且通过简单的实例来理解广度优先搜索算法的工作原理。
图遍历搜索算法简介
按照最浅显的解释,访问(visiting)和探索(exploring)图并且进行处理的过程就称为“图遍历”,在这个过程中,关键在于要 visiting 和 exploring 图中的每个顶点和边,还要争取所有的顶点只被搜索一次。
图遍历搜索算法有广度优先搜索、深度优先搜索等,挑战在于针对具体的问题,选择使用最适合的图遍历技术,若要做到这一点,需要“知己知彼”,本文将较为详细的讨论广度优先搜索算法(Breadth-First Search Algorithm)。
什么是广度优先搜索算法?
首先,广度优先搜索算法属于图遍历算法,因此前文讨论图遍历算法的特点,广度优先搜索算法都有。在该算法中,我们可以任意选择一个随机的初始节点(称作源节点或者根节点),并且以 visiting 和 exploring 所有节点及其子节点的方式开始遍历图。
所谓的图,可以是我们构建的数据结构,只不过为了更加直观,常常把该数据结构以“图”的形式展现,稍后将看到实例。
在我们进一步深入讨论广度优先搜索之前,先对 visiting 和 exploring 做个更加直观的解释,请看下图:
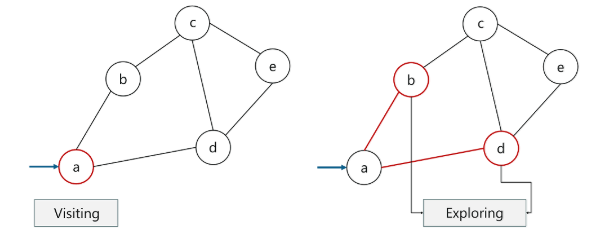
- visiting 节点:即访问或者选择一个节点
- exploring 节点:是指探索与被选中节点相邻的节点(子节点)
广度优先搜索算法实例
广度优先搜索算法遵循一种简单的、基于层次的方法来解决问题。考虑下面的二叉树(这种数据结构显然可以看作一张图),现在目标是使用广度优先搜索算法遍历该二叉树,也即遍历图。
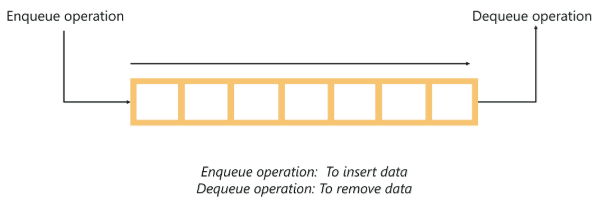
不过在开始之前,我们先了解一下“队列”这种数据结构,稍后在广度优先搜索算法中使用。请看下图,队列是一种遵循“先进先出”的抽象数据结构,最先被插入的数据最先被访问,它在两端都是开放的,一端用于插入数据(enqueue),另一端用于取出数据(dequeue),这一点倒是很像人类日常生活中的“排队”。
现在,我们来看下使用广度优先搜索遍历图涉及的步骤:
- 定义一个空队列
- 选择一个起始节点(visiting),并将其插入到队列中
- 从队列中取出之前插入的节点,并且把它的子节点(exploring)插入到队列中
- 打印/输出取出的节点
以前面的二叉树为例,上述 4 个步骤的过程可以具体为下图:
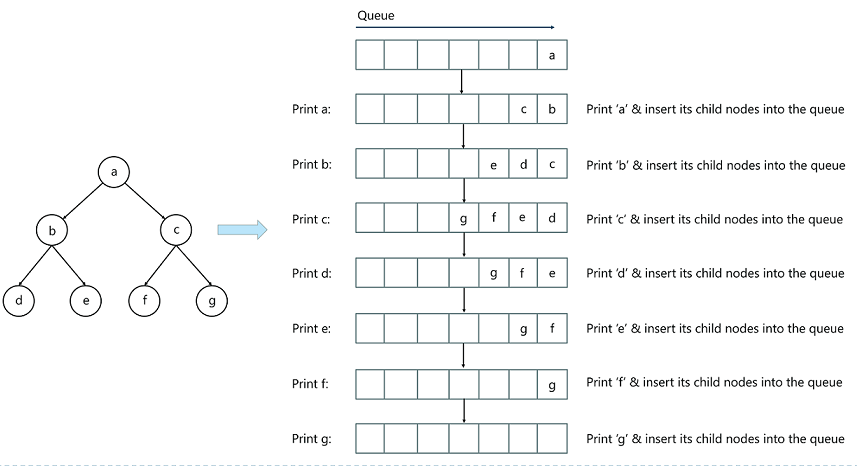
- 指定 a 为根节点,并将其插入到队列中
- 从队列取出 a,并且把 a 的子节点 b 和 c 插入队列
- 打印 a 节点
- 队列中仍然有节点,因为 b 是先被插入的节点,所以我们先取出 b,并把它的子节点 d 和 e 插入队列
- 重复上述步骤,一直到队列为空
注意,不应将已经 visiting 过的节点再添加到队列中。
现在让我们看看广度优先搜索算法的伪代码。
广度优先搜索算法的伪代码
Input: 把 s 作为源节点
BFS (G, s)
令 Q 为队列.
Q.enqueue( s )
标记 s 已被访问过
while ( Q is not empty)
v = Q.dequeue( )
for 所有v的子节点 w in 图 G
if w 没有被访问过
Q.enqueue( w )
标记 w 已被访问过我们稍稍解释下上述伪代码,其实无非就是以下几个步骤:
- (G, s)是输入,其中 G 是所谓的图,s 是选定的根节点
- 创建队列 Q,并把 s 节点初始化为它的根节点
- 标记 s 的所有子节点
- 从队列中取出 s 并且访问它的所有子节点
- 处理 v 的所有子节点
- 存储 Q 中的 w (子节点),并访问它的子节点
- 重复上述步骤,直到 Q 为空
广度优先搜索算法的应用
广度优先搜索算法是搜索引擎使用的主要算法之一,算法从源页面开始遍历,并跟踪与该页面相关联的所有链接,显然,此时每个网页都可以视作图形中的一个节点。
GPS 导航系统
广度优先搜索算法是使用 GPS 系统查找相邻位置的最佳算法之一。
求无权图的最短路径&最小生成树
对于未加权图,计算最短路径非常简单,因为最短路径的思想是选择一条边数最少的路径。广度优先搜索可以通过从源节点开始遍历最少数量的节点来实现这一点。类似地,对于生成树,我们也可以使用广度优先搜索(或深度优先搜索)方法来查找生成树。
网络利用各种数据包进行通信,这些数据包遵循我们设定的遍历方法到达不同的网络节点,最常用的遍历方法之一就是广度优先搜索算法。
p2p 技术
广度优先搜索方法可以作为一种遍历方法来查找 p2p 网络中的所有相邻节点,例如,BitTorrent 便是使用广度优先搜索算法进行点对点通信的。
广度优先搜索算法实例问题
下面这个比较有趣的问题来自于 leetcode:
你有一个用于表示一片土地的整数矩阵land,该矩阵中每个点的值代表对应地点的海拔高度。若值为0则表示水域。由垂直、水平或对角连接的水域为池塘。池塘的大小是指相连接的水域的个数。编写一个方法来计算矩阵中所有池塘的大小,返回值需要从小到大排序。
比如,输入
[
[0,2,1,0],
[0,1,0,1],
[1,1,0,1],
[0,1,0,1]
]可以得到输出:
[1, 2, 4]接下来我们将基于广度优先搜索算法,使用C++语言编写程序解决这个问题。
广度优先搜索算法实例解答
如前文所讨论的,图搜索算法本身并不难,难的是针对具体的问题选择恰当的算法。就本例而言,我们已经选定广度优先搜索算法,该如何实现呢?读者应把注意力放在“搜索”一词上,既然是搜索算法,搜索什么呢?
输入邮箱或者手机号码,付款后可永久阅读隐藏的内容,请勿未经本站许可,擅自分享付费内容。
如果您已购买本页内容,输入购买时的手机号码或者邮箱,点击支付,即可查看内容。
电子商品,一经购买,不支持退款,特殊原因,请联系客服。 付费可读
$ g++ bfs.cpp -std=c++11 -g
$ ./a.out
start...
1
2
4
finished.与预期一致。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK