

Maximizing Deep Learning Inference Performance on Intel Architecture in VMware v...
source link: https://blogs.vmware.com/performance/2020/12/max-dl-inference-performance-vmware-vsphere-intel-arch-openvino.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Maximizing Deep Learning Inference Performance on Intel Architecture in VMware vSphere with Intel Distribution of OpenVINO Toolkit
By Lan Vu (VMware), Anton Lokhmotov (dividiti), Ramesh Radhakrishnan (Dell), Padma Apparao (Intel), Uday Kurkure, Juan Garcia-Rovetta, and Hari Sivaraman (VMware)
In collaboration with Dell, Intel, and dividiti, we’ve recently submitted benchmarking results on the VMware vSphere® 7.0 platform with Dell® PowerEdge® servers powered by 2nd Generation Intel® Xeon® Scalable Processors to the MLPerf™ Inference v0.7 round. In this blog, we summarize these results and provide some best practices on deploying and scaling machine learning/deep learning inference workloads on the vSphere platform. We also show that CPU-based inference on vSphere has a very small virtualization overhead compared to the performance of the same task running on similar, non-virtualized servers. Specifically, some of our experiments with the MLPerf benchmark give even better inference throughput on vSphere compared to bare metal due to the oversubscription of CPU cores.
Accelerating Deep Learning Inference Workloads on Intel Architecture
The growing computation demand in machine learning (ML), especially deep learning (DL), requires special hardware support to accelerate ML/DL workloads. The ML workloads that leverage CPU for computation can take advantage of the Intel Advanced Vector Extensions 512 (AVX-512) with Intel Deep Learning Boost (Intel DL Boost) in the 2nd Generation Intel® Xeon® Scalable processors to enhance their performance. Intel DL Boost contains the Vector Neural Network Instructions (VNNI) that accelerate convolutional neural networks (CNNs) by multiplying two 8-bit (or 16-bit) integer variables and accumulating the result in a 32-bit integer variable. This significantly improves the throughput of deep learning workloads.
VNNI instructions are supported in vSphere 7.0. In our previous blog post and white paper, we have shown that doing inference on 2nd Generation Intel® Xeon® Scalable Processors with VNNI and the INT8 quantization helped increase inference throughput by 3.49x compared to the same task on 1st Generation Intel® Xeon® Scalable processors using FP32. The overhead when comparing with bare metal is also minimal.
We used OpenVINO™ to optimize the ML inference model and maximize the performance of a ML task on Intel architecture. This toolkit extends computer vision and non-vision workloads across Intel hardware, maximizing performance. One of the core components of the OpenVINO™ toolkit is the Model Optimizer. It converts a trained neural network from its source framework such as Caffe*, TensorFlow*, MXNet*, Kaldi*, and ONNX* to an open-source, nGraph-compatible Intermediate Representation (IR) by performing optimizations that remove excess layers and group operations into simpler, faster graphs.
MLPerf Inference Performance in vSphere with Intel DL Boost Technology and Intel Distribution of OpenVINO Toolkit
Experimental Setup
Note: All tests were conducted by VMware and dividiti in partnership with Dell.
In our experiments, we ran two scenarios defined by the MLPerf community: Offline and Server. The scenarios defined how the load was generated and how the performance was measured. The ResNet50 benchmark for image classification in MLPerf Inference v0.7 suite was run on a Dell PowerEdge R640 server with two Intel® Xeon® Gold 6248R chips. The benchmark was optimized for the 2nd Generation Intel® Xeon® Scalable processors in our test systems using the Intel® Distribution of OpenVINO™ toolkit 2020. The experiments were performed both on vSphere and bare metal for comparison.
The configuration of the test system is presented in table 1. In the vSphere case, the MLPerf benchmark was run inside a VM with 96 vCPUs, 192GB memory, 100GB virtual disk, with an Ubuntu guest operating system.
Systems Bare Metal (Native) vSphere 7.0 (Virtualized) Server Type Dell PowerEdge R640 Dell PowerEdge R640 Processor 2 x Intel® Xeon® Gold 6248R CPU @ 3.00GHz, 24C/48T, 35.75MB cache 2 x Intel® Xeon® Gold 6248R CPU @ 3.00GHz, 24C/48T, 35.75MB cache Physical Cores 48 48 Logical Cores 96 96 Hyper-Threading Enabled Enabled Memory Size 192GB 192GB Storage 200GB SATA 21TB vSAN storage OpenVINO™ toolkit v. 2020 v. 2020 Operating Systems Ubuntu 18.04.5 LTS; kernel 4.15.0-117-generic Guest OS: Ubuntu 18.04.4 LTS, Linux 4.15.0-117-generic Hypervisor None VMware vSphere 7.0Table 1. Server configurations
MLPerf Offline Scenario Performance Overview and Results
Detailed results for both bare metal and vSphere results on the 6248R server can be found at the MLperf site:
For the offline scenario, ResNet50 inferencing was performed with a single query to process at least 24,576 image samples. This offline scenario simulated ML applications that perform inference in batches and there was no critical requirement on inference latency. Hence, the main performance metric is inference throughput measured in samples per second.

We present the inference throughput of ResNet50 in figure 1, in which vSphere delivers a performance of 2,403 images per second and has a 2.7% overhead when compared to the bare metal throughput that is 2,468 images per second. To obtain the low overhead inference, a number of optimizations were applied; these are detailed in the Optimizing Deployment section later in this article.
MLPerf Server Scenario Performance
For the server scenario, the load generator creates a series of inference queries, each requesting the inference for a single image. This mimics ML applications where the inference requests come in real time. In this case, we consider both throughput and latency. This benchmarking scenario requires that the 99th percentile latency of inference requests must not exceed 15 milliseconds (ms) for the results to be considered valid. Hence, an orchestrated tuning of the inference load, the system configuration, and OpenVINO™ framework must be done to realize the optimal throughput while still meeting the 99th percentile latency threshold of 15ms. We present the inference throughput and latency of ResNet50 for this benchmarking mode in figures 2 and 3, respectively.
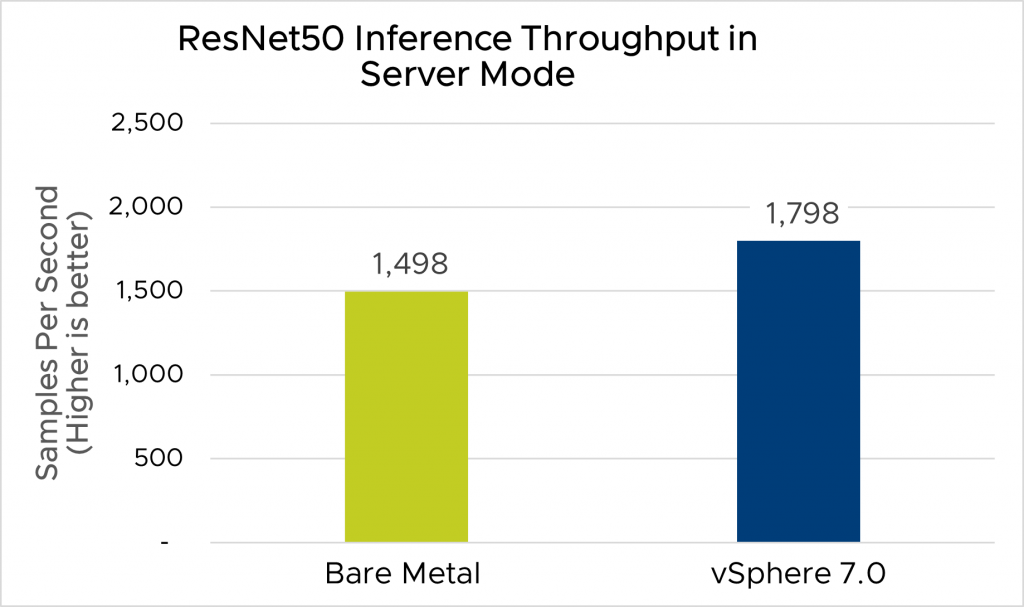

As observed in the results, the highest inference throughput that we can obtain while meeting the latency requirement is 1,798 images per second, which is 20% higher than the max throughput obtained in the bare metal test in figure 2. This can be explained by a number of optimizations that we applied; we discuss those in the next section.
For the inference latency, both bare metal and vSphere results give similar 99th percentile latencies of ~15ms. For 95th percentile latencies, the overhead of ResNet50 is 8.8% compared to the bare metal results as shown in figure 3. The overhead of latency in the Server mode of MLPerf can be reduced further by reducing the target throughput configuration of the MLPerf benchmark. In this case, the maximum throughput obtained was lower than 1,798. In our experiments, we set the benchmarking configuration to maximize the inference throughput as seen in figure 2.
Optimizing Deployment of Machine Learning Workloads in vSphere
To obtain the best performance results, several optimizations and deployment configurations were applied.
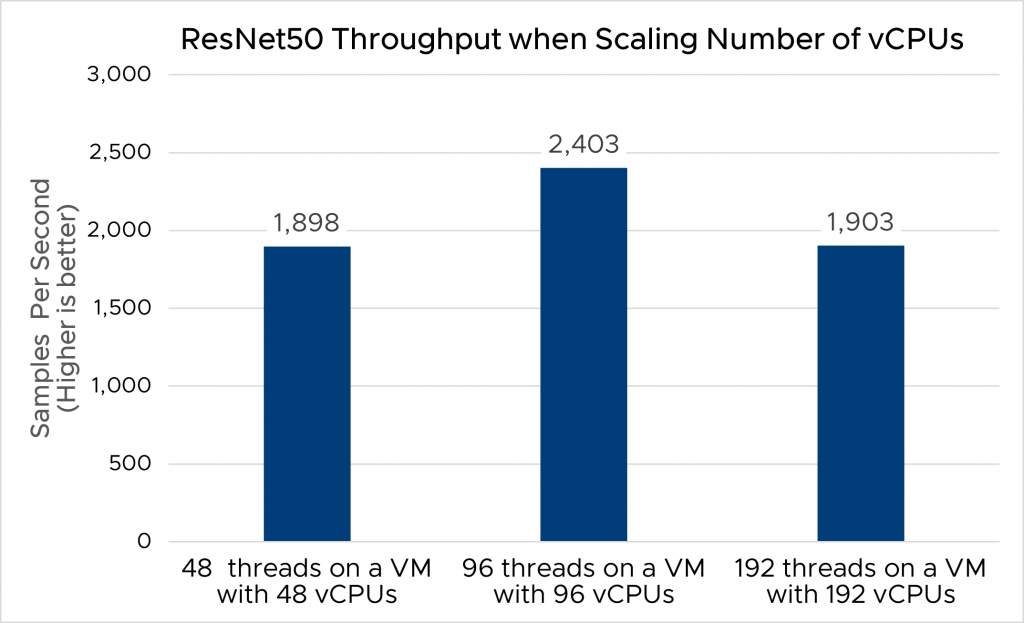
First, the best performance was achieved when we enabled and used the Hyper-Threading feature in both the physical server and vSphere host. Given our test servers with 48 physical CPUs, enabling hyperthreading gave us a total of 96 logical CPUs. Figure 4 shows the throughput of the ResNet50 workload running on VMs with different numbers of vCPUs and with different numbers of concurrent threads with the Intel® Distribution of OpenVINO™ toolkit. Among those, a workload that used all logical CPUs which ran inference with 96 threads on a 96-vCPU VM achieved 26.6% better throughput compared to the case of using more than the available logical CPUs.
Second, another deployment configuration that helped improve inference throughput was the number of VMs. Unlike the deployment on bare metal, ML workloads in vSphere were deployed inside VMs whose configurations like vCPU and memory could be dynamically adjusted on the real loads of ML applications. Hence, when the load of a certain ML application was low, we had multiple VMs on the same server, where each VM hosted a separate ML application. Figures 5 and 6 show how the inference throughput of ResNet50 concurrently run on different numbers of VMs per server and with different VM configurations, which are shown in table 2. As we can see, the deployment of multiple, smaller VMs shows slightly better inference throughput compared to the deployment of one big VM. When you have multiple VMs running ML workloads on the same server, and you want each VM using a separate NUMA socket, you can set the NUMA affinity for each VM. This ensures each VM uses only the CPUs of the NUMA node to which it is assigned. See “Associate Virtual Machines with Specified NUMA Nodes” for details.

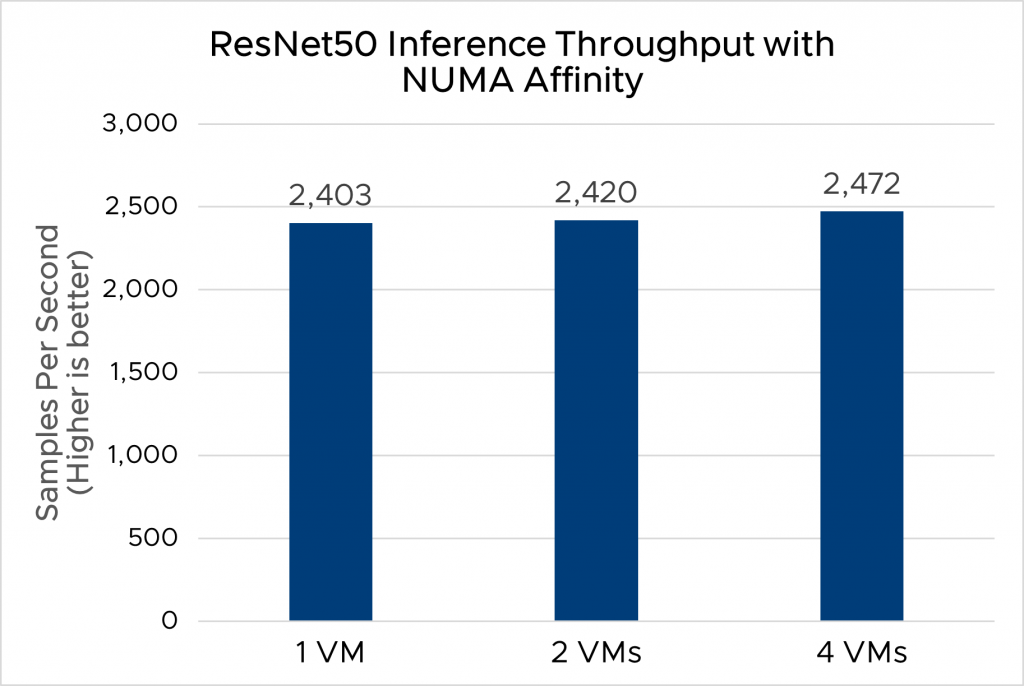
Note: Benchmark results in figures 1, 2, and 3 have been submitted to the MLperf committee, while the performance data in figures 4, 5, and 6 have been collected to highlight the benefits of scaling cores, VMs, and NUMA affinity.
Number of vCPUs per VM Memory Size per VM With NUMA affinity Without NUMA affinity 1 VM 96 192GB Not set Not set 2 VMs 48 96GB 1 VM on NUMA node 01 VM on NUMA node 1 Not set 4 VMs 24 48GB 2 VMs on
NUMA node 0
2 VMs on NUMA node 1 Not set
Table 2. VM Configurations
Takeaways
We presented some performance results of MLPerf Inference v0.7 on a vSphere platform that used Intel® Xeon® Scalable processors for inference—test results show low overhead of ML workloads on vSphere.
One of our experiments achieved 20% better inference throughput compared to bare metal results, mainly due to the vSphere support of oversubscription (aka over-commitment) of logical cores. vSphere allows for large oversubscriptions of hardware resources to enable multiple workloads to be run simultaneously and still provide quality of service and meet service-level agreements. This is a unique feature of vSphere performance that we take advantage of in our benchmarking; vSphere oversubscription can also be applied in real-world scenarios for ML/DL workloads.
We also discussed deployment configurations that we applied to optimize the performance of vSphere for the ResNet50 benchmark workload in MLPerf.
Intel and OpenVINO are trademarks of Intel Corporation or its subsidiaries.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK