

C语言深度剖析-读书简记
source link: http://lanbing510.info/2016/04/24/C-Language-Understanding.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
最近再次温习C语言深度剖析,对C语言的一些易错的和重要的知识点做了以下整理。
第一章 关键字
一 register
1 关键字请求编译器尽可能将变量存在CPU内部的寄存器内中,避免存入聂功通过寻址访问来提高效率。
2 变量类型必须是CPU寄存器可以接受的类型,即必须是一个单个的值,其长度小于或者等于整型的长度。
3 不能用&来获取register变量的地址(因为是存在了寄存器而不是内存中)。
二 static
1 修饰变量,变量存在内存的静态区。当修饰全局变量时,表示变量只能在被定义的文件中使用,其他文件即时使用extern也不能使用。修饰局部变量时,表示只能在函数里使用。跳出函数后值并不销毁。
2 修饰函数,不表示存储方式是静态的,而是针对函数作用域,表示作用域仅局限于本文件。在C++中,static有第3个作用:类中的静态数据成员,可以实现多个对象间的数据共享。静态数据成员需要相应的静态成员函数访问。
三 sizeof
1 sizeof是关键字而不是函数。在计算变量所占空间大小时括号可以省略,而计算类型大小时不可以省略。
2 sizeof是在编译时求值(在C99中,计算柔性数组所占空间大小是其是运行时求值)。sizeof操作符里面不要有其他运算,否则不会达到预期的目的。
四 signed和unsigned关键字
先看一段程序,考虑其输出结果。
int main()
{
signed char a[1000];
int i;
for(i=0;i<1000;i++)
{
a[i]=-1-i;
}
printf("%d",strlen(a));
return 0;
}输出为255。答对了吗?答对了可以跳过下面的分析。
首先介绍一下计算机信息表示的几个易混淆的概念:原码、反码、补码。原码是符号位加上真值的绝对值,即第一位表示符号,其余表示值;反码规定,正数的反码是本身,负数的反码是在其原码的基础上,符号位不变,其余位各个取反。补码是计算机系统中数值的表示方法,正数的补码与原码一致,即也与反码一致,负数的补码是其反码加1.用补码可以将符号位和其他位统一处理,减法按加法处理。两个用补码表示的数相加时,如果最高位(符号位)有进位,则进位被舍弃。
下面来介绍有符号数和无符号数之间的转换。在C语言中,对有符号数和无符号数之间的强制转换,保持不变的是位模式。由此可以把有符号数和无符号数之间的变换,看成有符号数的补码表示和无符号数之间的转换。
下图是补码到无符号数之间的转换示意图:
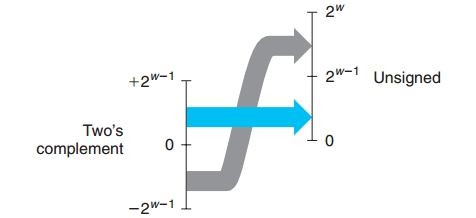
用公式表示即为:
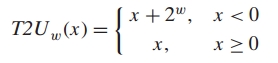
下图是无符号数到补码之间的转换示意图:
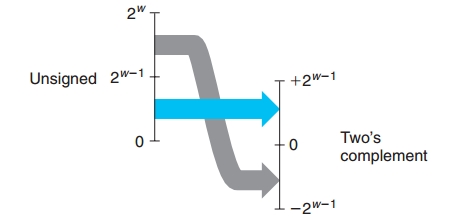
用公式表示即为:
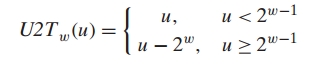
回归到题目,strlen函数是计算字符串长度的,遇到'\0'即认为字符串的结束(长度值不包括最后的'\0')。则题目可转换为计算从a[0]到a[n]之间的长度,其中n为第一个a[n]位模式为0的位置。-1,-2..到多少的位模式会为0?根据补码到无符号数之间的转换公式,可以得到-256的位模式为0。则长度为255。
另外,无符号数的表示范围为0−2w,有符号数为−2w−1−2w−1−1。w为类型的bit数。可以看到,有符号数的正数表示范围比负数少1,是因为-0和+0,人为规定+0视为0,-0视为−2w−1。
五 if和else的组合
1 bool变量与“零值”比较,写成if(flag)或if(!flag)最好。
2 float与“零值”进行比较,使用if(val>=-EPSINON&&val<=EPSINON),EPSIONO为定义好的精度。
3 说到浮点数,还要注意不要在很大的浮点数和很小的浮点数之间进行运算,如:
#include <stdio.h>
int main()
{
double i = 1000000000.00;
double j = 0.00000000001;
printf("%.15f",i+j);
return 0;
}输出:1000000000.000000000000000,会有截断。为什么?涉及到浮点数在计算机里的表示。
float:1bit(符号位) 8bits(指数位) 23bits(尾数位)
double:1bit(符号位) 11bits(指数位) 52bits(尾数位)
精度由尾数的位数决定。比如,对于float,log10223=6.923689900271567,则其精度最多有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字;对于double类似,精度为15~16位。题目中,i+j的有效位数为21位,超过了double的最高有效位数,则会产生截断。
4 指针变量与“零值”比较,使用if(NULL==p)和if(NULL!=p)。
六 switch和case
1 分支比较多的话使用switch和case会提高效率。
2 每个case后不要忘了break。
3 case后面只能是整型或字符型的常量或常量表达式(不可以是字符串)。
七 const
1 在ANSI C标准中(不适用于C++),const精确来说应该是只读变量而不是常量,其值在编译时不能被使用,编译器在编译时不知道其存储的内容。所以case后也不可以跟const修饰的只读变量。
2 修饰指针
const int *p; //常量指针,p可变,p指向的对象不可变
int const *p; //常量指针,p可变,p指向的对象不可变
int *const p; //常指针,p不可变,指向的对象可以变
const int* const p;//指针p和其指向的内容都不可以变记忆方法:忽略类型名,看const离谁近就修饰谁。
八 volatile
1 修饰的变量表示可以被某些编译器未知的因素更改,不然操作系统、硬件或者其他线程。 2 volatile int i=10,volatile告诉编译器,i是随时可能发生更改的,每次使用时必须从内存中取出i的值。保证对特殊地址的稳定访问。
九 struct关键字
1 空结构体大小为1字节。
2 柔性数组。C99中,结构中的最后一个元素允许是未知大小的数组,即柔性数组成员,但其前必须有至少一个其他成员。sizeof返回的结构大小不包括柔性数组的内存。
十 union关键字
1 union中的所有数据成员共用一个空间,同一时间只能存储一个数据成员,所有的成员有相同的起始地址。
2 union默认属性为public,大小为最大程度的数据成员的空间。
3 利用union来确定当前系统的存储模式(大小端)。
首先看什么是大小端模式,大端模式表示字数据的高字节存储在低地址,而字数据的低字节存储在高地址;小短模式表示字数据的高字节存储在高地址,而字数据的低字节存储在低地址。 比如,一个存在地址0x100处的int型的变量x的16进制表示为0x01234567,则其大小端的表示为:
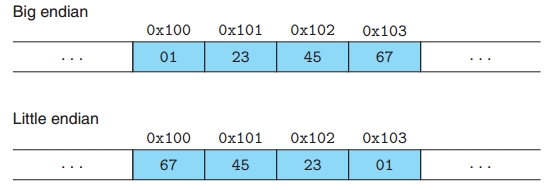
则利用union可以很快的写出检测大小端模式的程序:
int check_system()
{
union check
{
int i;
char ch;
}c;
c.i=1;
return (c.ch==1);//ture为小端模式,false为大端模式。
}留一个问题,在x86系统下,以下程序的输出值为多少
#include <stdio.h>
int main(void)
{
int a[5] = {1,2,3,4,5};
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf("%x,%x\n",ptr1[-1],*ptr2);
return 0;
}正确答案是5,2000000。为什么?详细分析可转到后文中的第四章。
十一 enum关键字
1 一般的定义方法如下:
enum enum_type_name
{
ENUM_CONST_1,
ENUM_CONST_2,
...
ENUM_CONST_n
} enum_variable_name;
enum_type_name为数据类型名,enum_variable_name为enum_type_name类型的一个变量。ENUM_CONST_*如果不赋值,会从被赋值的那个常量开始加1,默认的第一个常量值为0.
2 枚举在编译时确定值,define在预编译确定。
十二 typedef
1 用于给一个已经存在的数据类型取一个别名。看例子:
typedef struct student
{
//Code
}Stu_st,*Stu_pst;以上代码表示给struct student{}取了个别名叫Stu_st,给struct student{}* 取了个别名叫Stu_pst。
第二章 符号
一 注释符号
1 编译器处理注释时不是简单的剔除,而是用空格取代。
2 "/"和"*"之间如果没有空格,都会被当做注释的开始。可以y=x/ *p或者y=x/(*p),但不可以y=x/*p。
3 C语言里反斜杠"\"表示断行,编译器会将反斜杠剔除掉,跟在反斜杠后面的字符自动接续到前一行。但要注意,反斜杠之后不能有空格,反斜杠的下一行也不能有空格。
二 位运算符
1 按位异或可以实现不用第三个临时变量来交换两个变量的值:a^=b;b^=a;a^=b;但不推荐这样做,不易读。
2 如果位操作符"~"和"<<"应用于基本类型无符号字符型或无符号短整型的操作数,结果会立即转换成操作数的基本类型。
uint8_t port = 0x5aU;
unit8_t result_8;
unit16_t result_16;
result_8 = (~port) >> 4; //不能得到期待的0xa5
result_8 = ((uint8_t)(~port))>>4; //正确的写法
result_16=((uint16_t)(~(uint16_t)port))>>4; //正确的写法3 位运算符不能用于基本类型是有符号数的操作数上。
4 一元减运算符不能用在基本类型为无符号的表达式上。将一元减运算符用在unsigned int 或 unsigned long 的表达式上会分别产生类型为 unsigned int 或 unsigned long的结果,是无意义的操作。
unsigned int a = 12;
unsigned int b = -a;
int c=-a; // U2T
cout<<a<<endl; //12
cout<<b<<endl; //4294967284,及-12+2^32
cout<<c<<endl; //-12
cout<<(b==c)<<endl; //15 左移,右移运算符。左移时,高位丢弃,地位补0;右移时,低位丢弃,符号位随同移动(一般正数补0,负数补什么取决于编译系统的规定)。左移和右移的位数不能大于和等于数据长度,不能小于0(取决于编译器支持与否);
三 ++和--操作符
1 后缀的++,--是在本计算单位计算结束后再自加或自减。
int i=1;
int k=(i++)+(i++)+(i++); //3 2 贪心法则。C语言有这样一个规则:每一个符号应该包含尽可能多的字符。
int a = 3, b = 1;
int c=a+++b;
cout<<a<<" "<<b<<" "<<c<<endl; // 4 1 4四 除法运算符
1 假定q=a/b,r=a%b,先假定b>0,则由整数除法和余数操作应具备的相知有:
- q*b+r==a。
- 如果改变a的正负号,希望q的正负号随着改变,但q的绝对值不变。
- 当b>0,希望保证r>=0且r<b。
但上述三条不能同时成立(如-3/2),C语言或其他语言在实现整数除法截断运算时,必须放弃其中一条,大多编程语言了最后一条。
2 由上述规定,有2/(-2)=-1, 2%(-2)=0, 3/(-2)=-1, 3%(-2)=1, (-3)/2=-1, (-3)%2=-1。
五 运算符的优先级
1 运算符的优先级顺序如下。
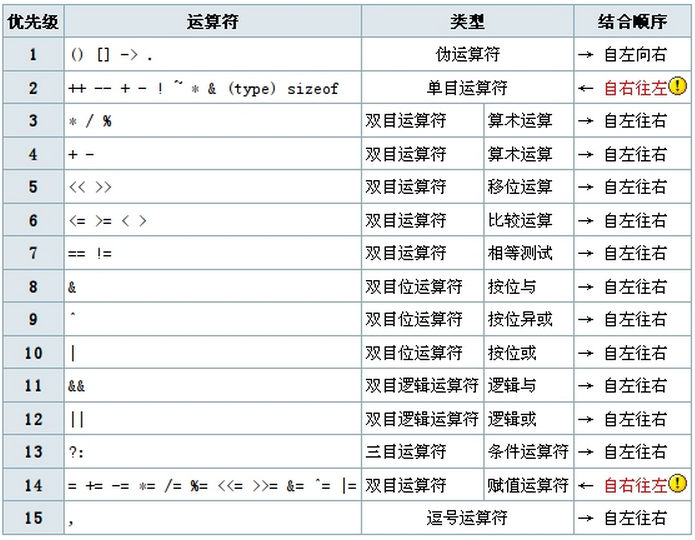
记忆技巧:
① 伪运算符的优先级最高,单目运算符优先级总是高于双目;
② 对于双目运算符而言,算术运算>位运算>逻辑运算;
③ 自右向左结合的运算符只有单目运算符和赋值运算符。
2 一些容易出错的优先级问题,见下表。
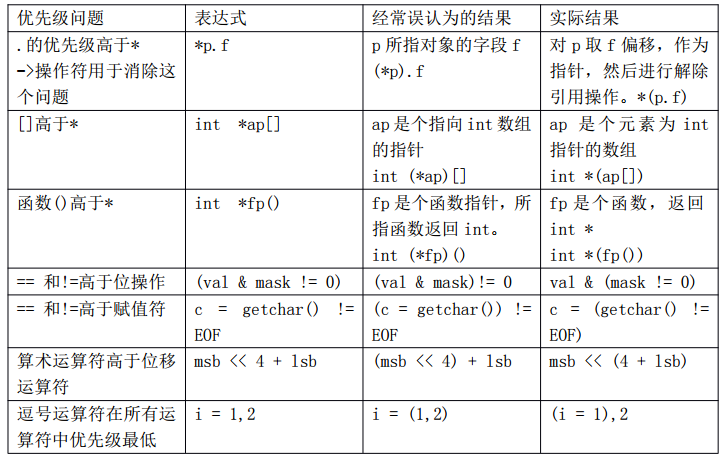
第三章 预处理
1 注释先与预处理指令被处理,所以不可以用define宏定义注释符号。
2 C的宏只能扩展为用大括号括起来的初始化、常量、小括号括起来的表达式、类型限定符、存储类标识符或do-while-zero。
3 在定义函数宏时,每个参数实例都应该以小括号括起来,除非他们做为#(字符串化操作符)或##(粘合剂)的操作数。
4 注意宏定义中的空格。
#define SUM (x) (x)+(x) //错误
#define SUM(x) (x)+(x) //正确写法二 一些其他预处理
1 遇到#error后会生成一个编译错误提示消息并停止编译,#error error-message。
2 #pragma comment,将一个诸世纪路放入一个对象文件或可执行文件中。
#pragma comment(lib,"user32.lib") //将user32.lib库放入到本工程3 #pragma pack,用于内存对齐。
首先介绍下什么是内存对齐,看一个例子:
struct TestStruct
{
char c1;
short s;
char c2;
int i;
};求上述结构体所占字节数。由于内存对齐的存在,使得答案不是8(1 11 1 1111)而是12(1x 11 1xxx 1111),1代表使用内存,x代表空内存。
什么时候会产生内存对齐?一个字(2个字节)或者双字(4个字节)跨越了4字节边界,或者1个四字(8个字节)跨越了8字节边界,被认为是未对齐的,从而需要两次总线来访问内存。一个字起始地址是奇数但是没有跨越字边界被认为是对齐的。缺省条件下编译器会将结构、栈中的成员函数进行内存对齐。
接下来来看下#pragma pack的使用方法。使用它可以改变编译器默认的内存对齐方式。
#pragma pack(n) //告诉编译器按n字节对齐
#pragma pack() //取消自定义字节对齐方式
#pragma pack(push) //保存当前对齐方式到packing stack
#pragma pack(push,n) //等效于#pragma pack(push);#pragma pack(n);
#pragma pack(pop) //packing stack出栈,并将对齐方式设置为出栈的对齐方式看一个例子
#pragma pack(8)
struct TestStruct1
{
char a;
long b; //假定所用编译器long为4字节
};
struct TestStruct2
{
char c;
TestStruct1 d;
long long e; //假定所用编译器long为8字节
};
#pragma pack()求sizeof(TestStruct1)和sizeof(TestStruct2)。直接放上答案:8,24。具体内存布局为:TestStruct1(1xxx(a) 1111(b)),TestStruct2(1xxx(c) 1xxx(d.a) 1111(d.b) xxxx 11111111(e))。为什么?
① 每个成员按照其类型的对齐参数(通常是其大小)和指定对齐参数(上例中n=8)中较小的一个对齐,并且结构的长度必须为所用过的所有对齐参数的整数倍,不够就补空;
② 复杂类型(如结构体)的默认对齐方式是它最长的成员的对齐方式;
③ 对齐后的长度必须是成员中最大的对齐参数的整数倍。
第四章 指针和数组
1 int *p=NULL 和 int *p; *p=NULL的区别。前者是表示把p的值设置为0x00000000,后者是把*p的值设置为0x00000000(即p指向的地址设为0x00000000)。
2 将数值存储到指定的内存地址。比如往内存地址0x12ff7c上存储一个整型数0x100。
int *p = (int *)0x12ff7c;
*p = 0x100;
//或者这样写
*(int *)0x12ff7c = 0x100;数组和指针
1 &a和a的区别。看一个例子:
int a[5]={1,2,3,4,5};
int *ptr=(int *)(&a +1);
printf("%d, %d",*(a+1),*(ptr-1))分析:&a+1表示区取数组a的首地址,该地址的值加上sizeof(a)的值,即:&a+5*sizeof(int); *(a+1),虽然a和&a的值是一样的,但a表示数组首元素的首地址,(a+1)的地址为&a[0]+1*sizeof(int),即a[1]的地址。所以上例中输出为2,5。用类似的分析,第一章第九小结中留的问题应该可以解决了吧?
2 不可以定义为数组,声明为指针。例如,文件1中定义char a[100]; 文件2中声明 extern char *a;这样的话, 编译文件2是编译器会认为a是一个指针变量,占四字节。会取a[0]~a[4]四个字节去寻址。
3 不可以定义为指针声明为数组。例如文件1中定义 char *p="abcdefg"; 文件2中声明 extern char p[]; 这样编译文件2是编译器会认为p是一个数组,会把直接读p的地址,并不会通过p间接寻到"abcdefg"的实际地址。
指针数组和数组指针
看下例,指出哪个是数组指针,哪个是指针数组:
int *p1[10];
int (*p2)[10];分析:[]的优先级高于*,p1表示指针数组(存放指针的数组);p2表示数组指针(指向一个包含10个int类型数据的数组)。
多维数组和多级指针
1 看例题,计算打印的结果:
int a[3][2]={(0,1),(2,3),(4,5)};
int *p;
p=a[0];
printf("%d",p[0]);答案是1,答对了吗?分析:注意初始化的时候错把大括号用成了小括号,赋值相当于了a[3][2]={1,3,5}。初始化注意写法。
2 看一个面试经常遇到的例子:
int a[5][5];
int *(p)[4];
p=a;问:&p[4][2]-&a[4][2]的值。问题不难,答案是-4,答错的可以结合下面内存布局图仔细理解下。
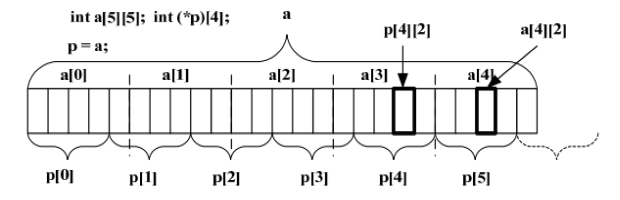
数组参数和指针参数
1 一级指针参数无法把指针变量本身传递给一个函数,可以用return或者二级指针参数来实现。看例子:
void GetMemory(char* p, int num)
{
p=(char *)malloc(num*sizeof(char));
}
char *str=NULL
GetMomory(str,10); //str本身并没有改变,还是指向NULL通过return实现:
char* GetMemory(char* p, int num)
{
p=(char *)malloc(num*sizeof(char));
return p;
}通过二级指针:
void GetMemory(char** p, int num)
{
*p=(char *)malloc(num*sizeof(char));
}
char *str=NULL;
GetMemory(&str,10); //OK1 一个函数指针长的样子: char* (*fun)(char* p1, char* p2)。
2 *(int *)&p是个什么鬼。看例子:
void Function()
{
printf("Call Function! \n");
}
int main()
{
void (*p)();
*(int*)&p=(int)Function;
*(p)();
return 0;
}分析:p是一个函数指针变量,*(int*)&p=(int)Function表示将函数Function的入口地址赋值给指针变量p。
3 函数指针数组,长这个样子:char* (*pf[3])(char *p)。使用时可以直接 pf[0]=fun;或者 pf[0]=&fun;
4 函数指针数组指针。读完后是不是想抓狂。其实没那么复杂,就是一个指针,指针指向一个数组,数组里存放的是指向函数的指针而已。 大概面貌:char* (*(*pf)[3])(char* p)。结合下面的例子会更好的理解。
char* fun1(char* p)
{
printf("%s\n",p);
return p;
}
char* fun2(char* p)
{
printf("%s\n",p);
return p;
}
char* fun3(char* p)
{
printf("%s\n",p);
return p;
}
int main()
{
char* (*a[3])(char* p); //函数指针数组
char* (*(*pf)[3])(char* p); //函数指针数组指针
pf=&a;
a[0]=fun1;
a[1]=fun2;
a[2]=fun3;
pf[0][0]("fun1"); //也可以用(*pf)[0]("fun1");
pf[0][1]("fun2"); //也可以用(*pf)[1]("fun2");
pf[0][2]("fun3"); //也可以用(*pf)[2]("fun3");
return 0;
}第五章 内存泄露
没涉及到多少易错点和重点。记得定义指针变量的同时最好初始化为NULL,用完后也置为NULL;访问提防越界;记得给结构体里的指针分配内存;分配的内存记得释放。
第六章 函数
没有什么需要特别注意的。
第七章 文件结构
1 需要对外公开的常量放在头文件中,不需要的放在源文件。
2 不要在头文件中定义对象或函数体。
第八章 关于面试的秘密
态度是一种习惯,习惯决定一切。
C语言最难的部分是设计到指针的部分,还有很多易错的细节问题。本文中的整理的内容都弄明白后,你可以在简历上自信的写上能熟练掌握和运用C语言了。结合原书会更好的理解,文章意在作知识点回顾和速查之用。
[1] C语言深度剖析. 第2版. 陈正冲
[2] 深入理解计算机系统.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK