

GPU高性能编程CUDA实战-读书简记
source link: http://lanbing510.info/2017/11/09/Cuda-By-Example.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

GPU高性能编程CUDA实战对于没有接触过GPU编程的人是非常不错的一本入门书,脉络清晰,例子由浅入深。下文是一些笔记,代码占了很大部分(代码很好的解释了用法),方便用到的时候查阅复习。
第1篇 CUDA C简介
本篇主要对CUDA C编程进行了简介,介绍了如何查询支持CUDA的设备的信息。
代码Enum GPU主要涉及到了设备属性的查询。
第2篇 CUDA C并行编程
本篇主要介绍了如何使用CUDA C编写并行代码。
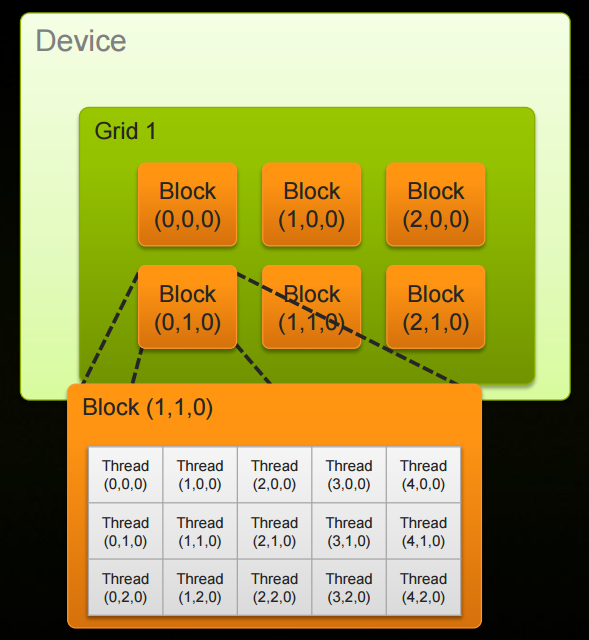
代码Add Loop Long实现了使用GPU计算向量加法。其中核函数add<<<128,1>>>中第一个参数表示设备在执行核函数时是用的并行线程块的数量。其中blockIdx代表线程块的索引。将add核函数声明为__global__函数,从而可从主机上调用并在设备上运行。
代码Julia使用GPU实现了生成Julia集的算法。其中__device__声明的函数,表示将在GPU而不是主机上运行,只能从其他__device__函数或者重__global__函数中调用它们。
第3篇 线程协作
本篇主要介绍CUDA中的线程、不同线程间的通信机制、并行执行线程的同步机制。
代码Add Loop Long Blocks中,核函数add<<<128,128>>>第一个参数表示使用128个线程块,第二个参数表示每个线程块中创建128个线程数量。在add核函数中,blockDim是一个常数,保存的是线程块中每一维的线程数量;gridDim保存了一个类似的值,即在线程格中每一维的线程块数量。gridDim是二维的,blockDim实际上是三维的。
代码Ripple使用GPU实现了波纹效果。代码中使用了二维的线程块和线程数组。
代码Dot实现了矢量的点积运算。展示了共享内存的使用。编写代码时,将CUDA C的关键字__share__添加到变量声明中,将会使这个变量驻留在共享内存中,这样线程块中的每个线程都共享这块内存,但线程却无法看到也不能修改其他线程块的变量副本。程序中,共享内存缓存中的偏移就等于线程索引,线程块索引与这个偏移无关,因为每个线程块都拥有该共享内存的私有副本。
同时还要注意到对线程块中的线程进行同步:__syncthreads()。这个函数调用将确保线程块中的每个线程都执行完__syncthreads()前面的语句后,才会执行下一条语句。还需注意,如果将__synctheads()调用移入到if()线程块中,那么任何cacheIndex大于或等于i的线程都永远不能执行__syncthreads()。这将使处理器挂起。
第4篇 常量内存与事件
本篇将介绍如何在CUDA C中使用常量内存、常量内存的特性及如何使用CUDA事件来测量应用程序的性能。
代码Ray展示了如何使用常量内存。常量内存的声明方法与共享内存类似,在变量前加上__constant__修饰符即可。__constant__将把变量的访问限制为只读。在某些情况中,用常量内存来替换全局内存能有效减少内存宽带。其可以节约内存带宽主要有两个原因:1 对常量内存的单次操作可以广播到其他邻近线程,这将节约15次读取操作;2 常量内存的数据将缓存起来,因此对相同地址的连续读操作将不会产生额外的内存通信量。
邻近这个词的含义是什么?首先解释线程束(Wrap)的概念。线程束可以看出是一组线程通过交织而形成的一个整体。在CUDA架构中,线程束是一个包含32个线程的ihe,这个线程集合被编织在一起,并且步调一致(Lockstep)的形式执行。在程序中的每一行,线程束中的每个线程都将在不同的数据上执行相同的指令。
当处理常量内存时,NVIDIA硬件将把单次内存读取操作广播到每个半线程束。如果在半线程束中的每个线程都从常量内存的相同地址上读取数据,那么GPU只会产生一次请求并在随后将数据广播到每个线程。只有当16个线程每次都只需要相同的读取求情时,才值得将这个读取操作广播到16个线程。然而,如果半线程束中所有16个线程需要访问常量内存中不同的数据,那么这个16个读取操作将被串行化,从而需要16倍的时间发出请求。但如果从全局内存中读取,这些请求会同时发出。这种情况中,从常量内存读取就慢雨从全局内存中读取。
代码Ray同时展示了如何使用CUDA事件进行计时。
第5篇 纹理内存
本篇主要介绍纹理内存。和常量内存一样,纹理内存是另一种类型的只读内存,在特定的访问模式中,纹理内存同样能够提升性能并减少内存流量。纹理缓存是专门为那些在内存访问模式中存在大量空间局部性的图形应用程序而设计的。
代码Heat2D对热传导进行了简单的模拟,展示了二维纹理内存的使用。使用纹理内存时,首先需要对数据声明为texture类型的引用:texture<类型, 维度> variable,然后需要通过cudaBindTexture()将这些变量绑定到内存缓冲区来告诉CUDA:1 我们希望将指定的缓冲区作为纹理来使用;2 我们希望将纹理引用作为纹理的名字。
第6篇 图形交互操作
本篇主要介绍了CUDA C应用程序与OpenGL和DirectX这两种实时渲染API的交互操作。略。
第7篇 原子性
本篇主要介绍了原子操作性、为什么需要使用它们及如何在CUDA C核函数中执行带有原子操作的运算。
代码Hist GPU Shmem Atomics展示了原子操作性代码的编写,实现了GPU直方图统计。代码中使用atomicAdd实现原子加法操作,通过使用两阶段算法,降低了全局内存的访问竞争程度。
通过一些性能实验,发现当线程块数量为GPU中处理器数量的2倍时(不同于CUDA核心数,1080Ti处理器数为28,每个处理器128个CUDA核,总共3584个CUDA核心),将达到最优性能。
本篇主要介绍使用流实现任务并行来加速应用程序。
页锁定主机内存称为固定内存或不可分页内存,操作系统不会对这块内存分页并交换到磁盘上,可确保该内存始终驻留在物理内存中,但使用固定内存时,会失去虚拟内存的所有功能。使用cudaHostAlloc()函数实现分配页锁定的主机内存。
CUDA流在加速应用程序方面起着重要的作用。CUDA流表示一个GPU操作队列,并且该队列中的操作将以指定的顺序执行。
代码Basic Double Stream Correct展示了流的使用。其做的第一件事是选择一个支持设备重叠(Device Overlap)功能的设备。支持设备重叠功能的GPU能够在执行一个CUDA C核函数的同时,在设备和主机间执行复制操作。其中还使用了cudaStreamSynchronize(stream)实现GPU等待流。同时需要注意代码中将操作放入流的顺序,其影响着CUDA驱动程序调度这些操作以及执行的方式。
第9篇 多GPU系统上的CUDA C
本篇主要介绍如何在同一个应用程序中使用多个GPU、如何分配和使用零拷贝内存、如何分配和使用可移动的固定内存。
代码Portable展示了多个GPU的使用,同时涉及到了零拷贝内存、合并式写入内存、可移动的固定内存。
零拷贝内存是指可以在CUDA C核函数中直接访问的主机内存,不需要复制到GPU。在分配内存时加上cudaHostAllocMapped标志即可,该标志告诉陨石时将从GPU访问这块内存。
WriteCombined标志表示,运行时应该将内存分配为“合并式写入”内存。可以显著提升GPU读取内存的性能。然后,当CPU也要读取这块内存时,合并式写入会显得很低效。
调用cudaHostAlloc()将返回这块内存在CPU上的指针,需调用cudaHostGetDevicePointer()来获得这块内存在GPU上的有效指针。
通过cudaSetDeviceFlags()可实现在运行时置入能分配零拷贝内存的状态,通过传递标志cudaDeviceMapHost来表示我们希望设备映射主机内存。
当输入内存和输出内存都只能使用一次时,那么在独立GPU上使用零拷贝内存将带来性能提升。但由于GPU不会缓存零拷贝内存的内容,如果多次读取内存,那么最终将得不偿失,还不如一开始就将数据复制到GPU。
如果某个线程分配了固定内存,那么这些内存只是对于分配它们的线程来说是页锁定的,对于其他线程似乎是可分页的。对于这个问题的补救方案是:将固定内存分配为可移动的。这意味着在主机线程之间移动这块内存,并且每个线程都将其视为固定内存。要达到这个目标需要使用cudaHostAlloc()来分配内存,并且在调用时使用标志cudaHostAllocPortable。
编写多GPU代码中还有一点需要注意:一旦某个线程上设置了这个设备,那么将不能再次调用cudaSetDevice(),即便传递的是相同的设备标志符号。
第10篇 附录
本篇主要附上了几个有助于理解CUDA C编程中一些概念的截图及上文代码的几个附属头文件。

几个头文件
book.h cpu_bitmap.h cpu.anim.h
[1] GPU高性能编程CUDA实战
[2] CUDA By Example,书及源码
[3] CUDA C/C++ Basics,Cyril Zeller, NVIDIA Corporation
Recommend
-
24
C++11加入了多线程编程的支持,目前讲C++并发编程最好的书籍是《C++ Concurrency In Action》,因为中文版的翻译被黑出了翔,直接读的英文原版。因为书中讲的比较深,加上英语理解的难度,读了两遍才懵懵懂懂的读懂了一些。多线程编程相对于...
-
15
编程珠玑-读书简记 2016年04月11日 之前看过一遍编程珠玑,非常不错的书,觉得很有必要再看一遍整理一下。网上找到一篇整理的非常不错的
-
10
C++编程思想反反复复读过三遍,每次都有不一样的理解和收获,下面是一些备忘记录。 第一章 对象导言第二章 对象的创建与使用1 如果两个加引号的字符数组相邻,并且它们之间没有标点,编译器会将其组成...
-
13
GPU高性能编程CUDA实战(二) Original...
-
4
Linux命令行与Shell脚本编程大全是一本不可多得的好书,值得多次精读并非常适合作手头工具书。下面是多次阅读的一些摘录整理,方便定期回顾查阅。 第一部分 Linux命令行第一章 初始Linux Shell1 Linux...
-
35
GPU 编程 | 你了解 CUDA,了解 GPU 吗? 1年前 ⋅...
-
3
搭建CUDA 环境(GPU) 2017年6月12日 | 字数 4494 | ...
-
6
近日,摩尔线程在北京发布多款软硬件新品,包括新一代GPU“春晓”、面向个人电脑的消费级显...
-
6
NVIDIA CUDA2023春训营(一)GPU 与 CUDA 简介 2023-02-06...
-
10
合集 - 《CUDA编程:基础与实践》读书笔记(1)1.《CUDA编程:基础与实践》读书笔记(1):CUDA编程基础08-08
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK