

如何有效的进行公司名称匹配
source link: https://cdc.tencent.com/2020/08/30/%e5%a6%82%e4%bd%95%e6%9c%89%e6%95%88%e7%9a%84%e8%bf%9b%e8%a1%8c%e5%85%ac%e5%8f%b8%e5%90%8d%e7%a7%b0%e5%8c%b9%e9%85%8d/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

1. 背景及主要问题
项目需要把两个独立的系统通过公司名称的匹配来实现数据打通,其中一个系统的公司数有40万+,另一个系统中需要匹配的公司数3600+,如果直接通过SQL LIKE形式的方式来关联两个系统,发现只有1100多家公司名称可以匹配,如果剩余2500家左右的公司需要纯人工方式手动匹配,不仅工作量大而且效率低。
通过分析bad case发现公司名称难匹配的主要问题有以下两点:
1.1 公司简称形式多样
公司简称往往是人们根据习惯约定而成的,没有标准的形式。比如【深圳市腾讯计算机系统有限公司】的简称是【腾讯】,这种用公司全称的某一部分作为简称很容易通过字符串包含的方式来匹配。但是很多公司的简称是其它形式,比如【中国银行股份有限公司】的简称是【中行】,【中国石油化工有限公司】的简称是【中石化】,这种取公司全称中不同部分拼接而来的简称很难直接通过字符串模糊匹配取得较好的效果。另外有些公司的简称可能存在多种,比如【中国东方航空有限公司】有人简称【东航】,也有人简称【东方航空】。
总之,各式各样的简称形式导致字符串匹配时很难正确识别。传统的解决办法通常是维护一个公司全称和简称的 Mapping 关系作为常识库,但如果仅仅依靠常识库来解决,由于公司数量众多而且随时间而变化,维护和更新常识库就会成为一个很大的问题。
1.2 简称字数少时错误率高
比如【深圳市阅文教育咨询有限公司】的简称是【阅文】,但是当拿【阅文】去系统做LIKE形式的匹配时会发现总共有35家带有【阅文】子串的公司全称,部分如下:
- 北京大阅文化传播有限公司
- 成都悦阅文化传播有限公司
- 杭州怡阅文化传媒有限公司
- 北京鼎阅文学信息技术有限公司
- 深圳华阅文化传媒有限公司
- 上海亲阅文化科技发展有限公司
这些匹配的公司全称往往所包含的匹配子串在语义上是割裂的,但是直接的包含匹配无法进行语义上的分割,导致匹配的错误率随着简称字数的减少而升高。
2. 方案设计
基于以上问题,在处理公司名称匹配时将工作主要分为了两大部分:数据清洗和模糊匹配。数据清洗主要通过分词将公司全称拆解并对可能的简称形式进行组合;模糊匹配主要是基于最短编辑距离算法计算猜测的简称和需要匹配的简称的匹配分数,然后通过筛选最高匹配分数来找到最佳的匹配结果。
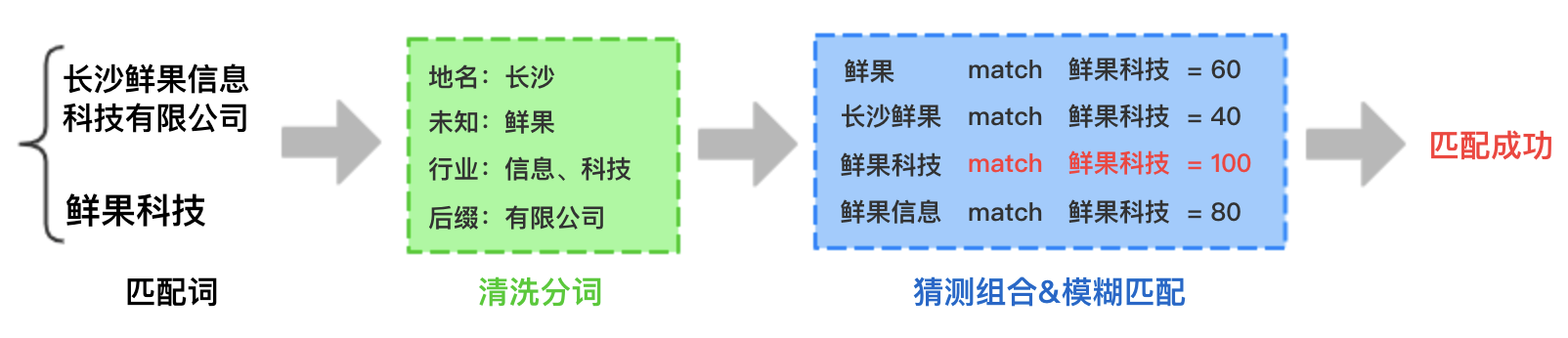
以下为各部分工作的详细介绍:
2.1 形式化表示公司全称
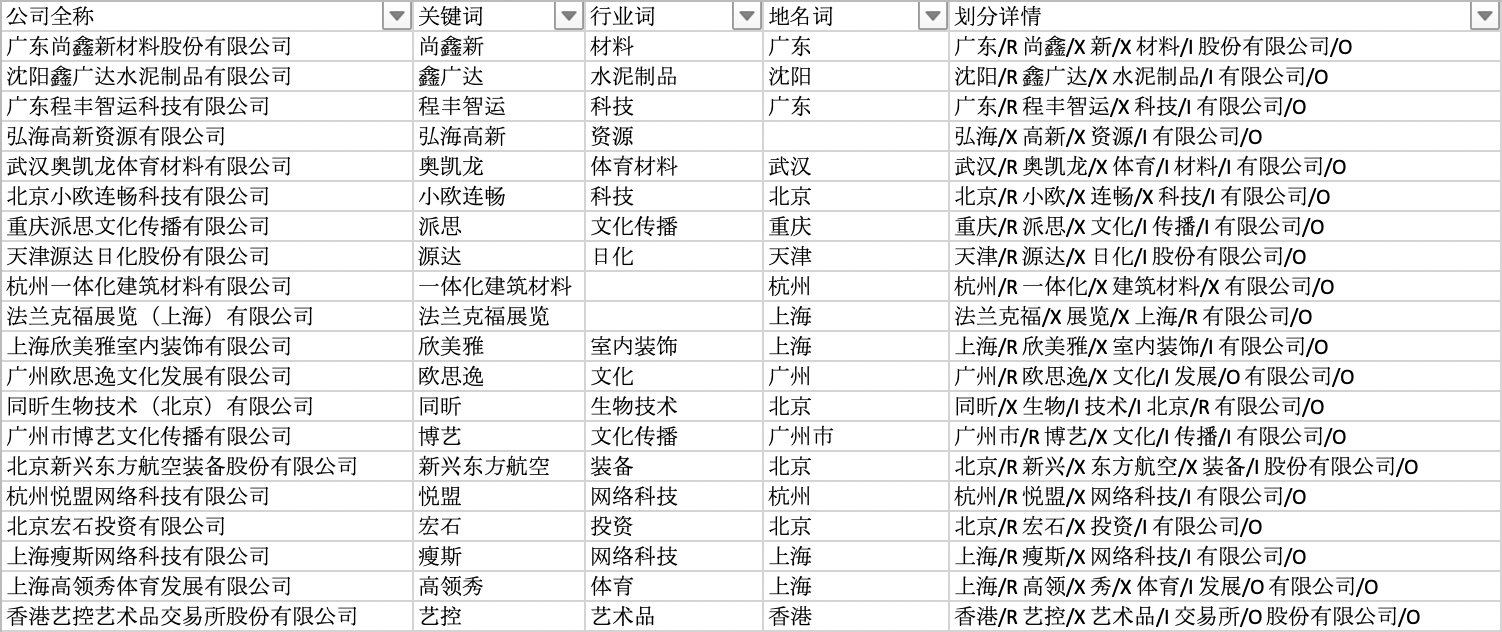
公司名称一般由地区(Region)、关键词(X)、行业(Industry)和公司后缀(Org_Suffix)四部分组成。比如【深圳市万网博通科技有限公司】,地区为【深圳市】、【万网博通】是关键词、【科技】是行业词,【有限公司是】公司后缀,这样我们就可以用 【RXIO】 表示此公司的名称结构。其他结构的公司名称也可以用类似的方式表示,比如:


有了分词及每个token的词性标注,就可以根据词性把不同的token归类到RXIO这四大类中。其中属于公司后缀O类型的数量有限,可以采用建立公司后缀词库的形式识别。地区R类型可以直接使用词性为ns(代表地名)的token完成分类。对于关键词X类型和行业I类型的识别这块是比较模糊的,所以我没有严格的区分,主要结合了 词性 和自定义的行业词库完成对关键词和行业的分类。在对所有公司全称按如上方式清洗后就可以得到一张其形式化表示的数据,如图所示:
2.2 构造可能的简称形式
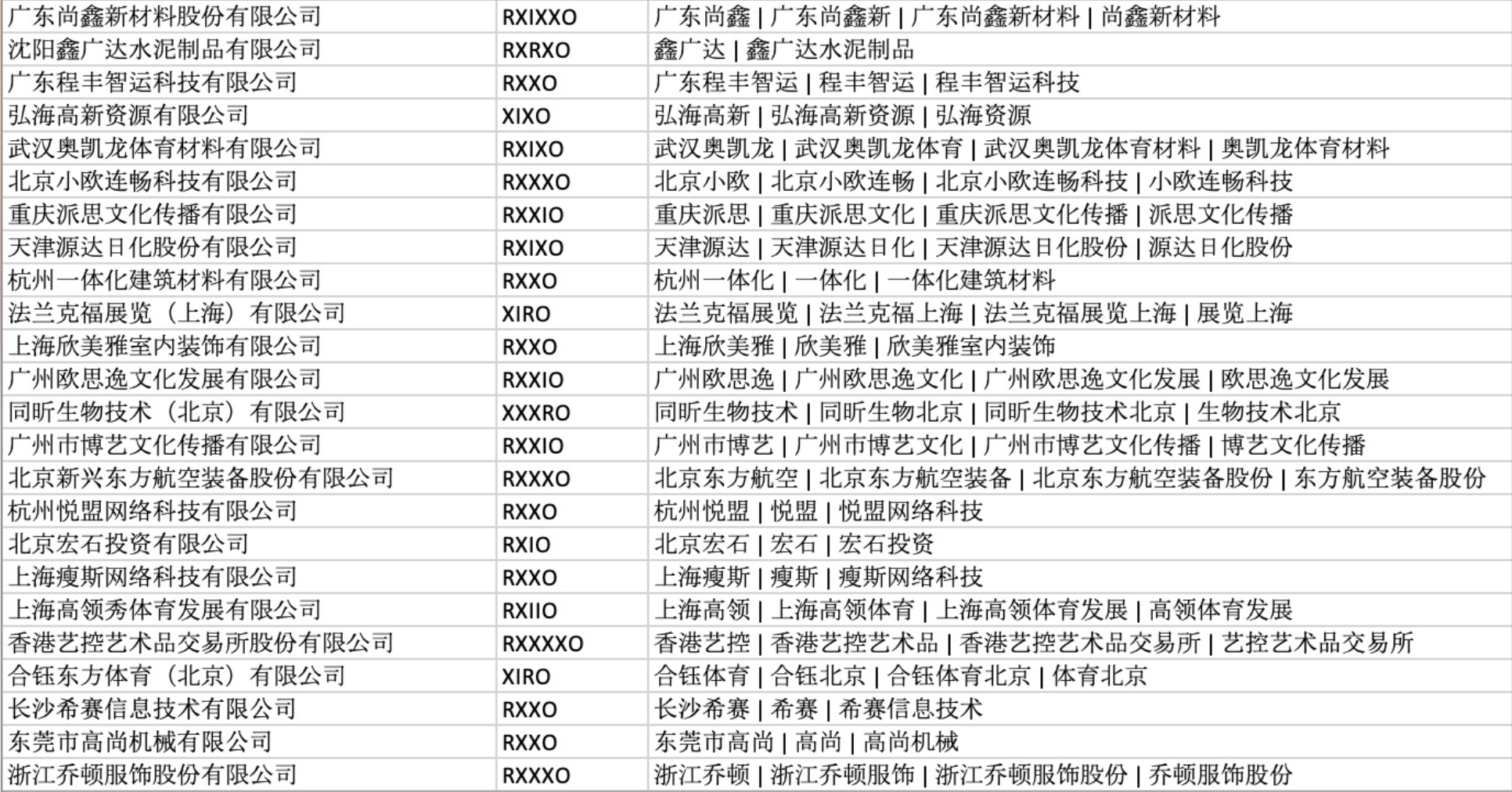
有了公司全称的形式化表示后,下一步是猜测其可能的简称结构。比如【中国移动有限责任公司】的简称是【中移动】就可以表示为 RXO => R[1-1]X,其中R[1-1]代表取第一个地区分词的第一个字,又比如【中国联通有限责任公司】的简称是【中国联通】可以表示为 RXO => RX, 这样我们就得到了【RXO】这种形式公司全称可能的简称形式有 R[1]X 和 RX 两种形式。依次类推,通过对部分公司全称对应的简称形式的统计,我们就可以得到一份规则用来表示不同形式化结构的公司全称可能对应的简称形式:

同时也可以不断向里面添加新的规则,当把2.1步骤获得所有公司全称形式化表示的数据应用这些规则后,就可以得到一份每个公司全称对应的可能的简称形式,如图所示:
2.3 最短编辑距离匹配
有了公司全称的所有可能简称组合后,就可以通过字符串相似度算法来计算他们的匹配度,如果匹配分数达到一定的阈值就可以认为是匹配的。常用的字符串相似度算法有最短编辑距离算法和余弦相似度算法,这里的匹配使用了最短编辑距离的算法实现。关于最短编辑算法的介绍如下:
Minimum Edit Distance(最短编辑距离)算法:任给两个字符串X 和Y,使用以下三种操作将 字符串X 变到 字符串Y :①插入(Insert)操作;②删除操作(delete);③替换操作(substitute),插入操作的代价为1,删除操作的代价为1,替换操作的代价为2。比如 ”intention” 变成 “execution” 执行了三次替换,一次删除,一次插入,因此8就是这两个单词的最短编辑距离。
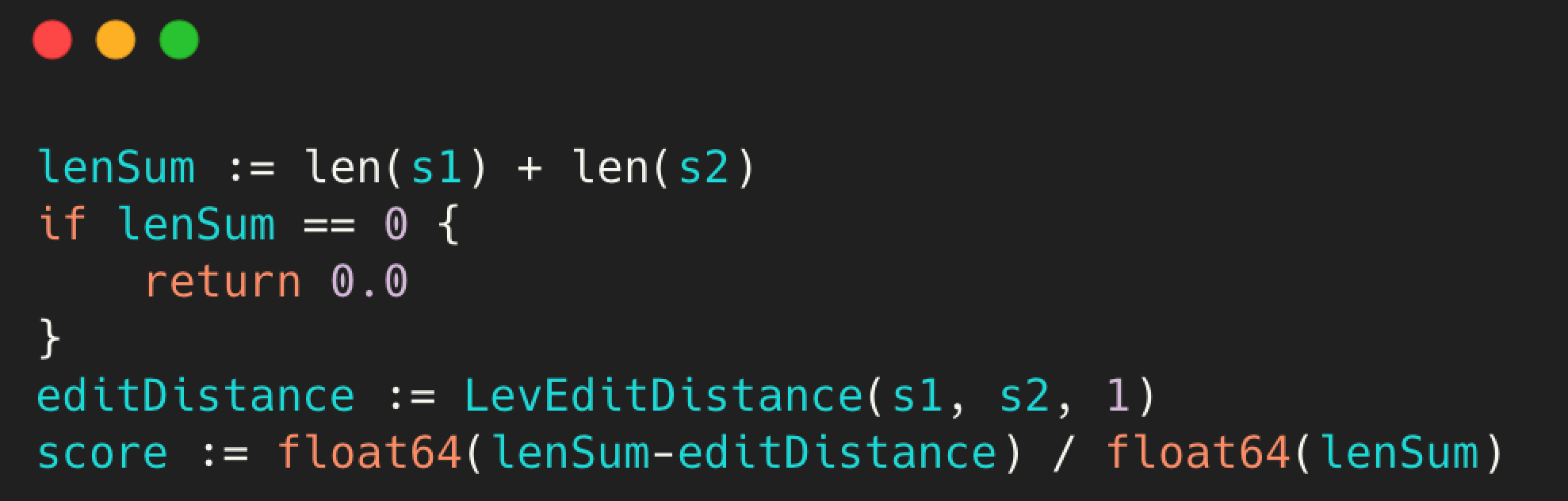
算出最短编辑距离后,可以根据他们字符串的长度计算其相似度,公式如下:
Similarity = (Len(s1+s2) - LevEditDistance(s1,s2)) / (Len(s1+s2))
相关代码如下:
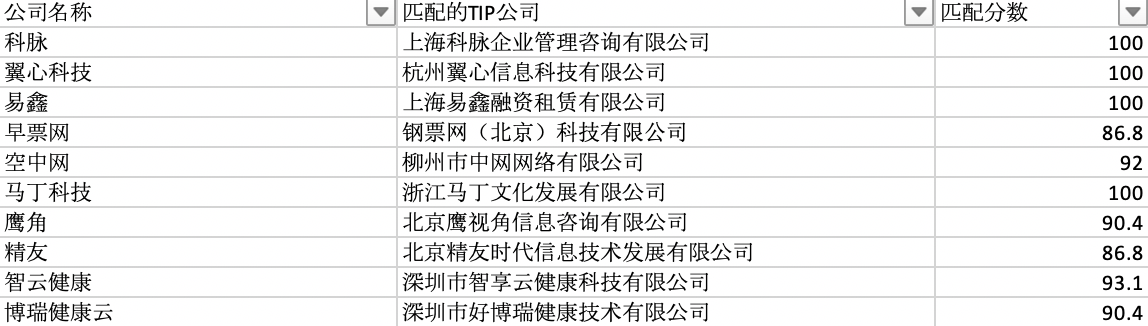
有了相似度计算公式,就可以对一家公司名所有可能的简称形式分别与待匹配公司名计算相似度,然后取分数最高者作为两家公司最终的匹配分数,效果如图:
3. 问题与改进
3.1 最短编辑距离匹配的问题
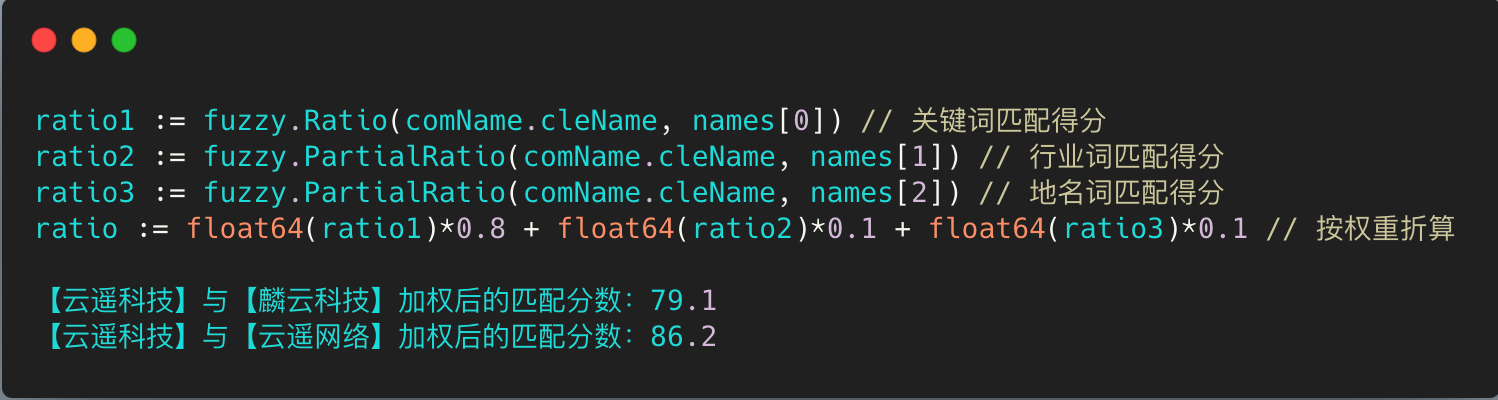
在check匹配分数时会发现有些公司的匹配结果明显不对,但是他们的匹配分数很高的现象。比如【深圳市麟云科技有限公司】的简称猜测是【麟云科技】时与【云遥科技】的相似度最高,匹配得分是92分。而【云遥网络科技(上海)有限公司】的简称【云瑶网络】与【云瑶科技】的相识度匹配得分只有83分。

很明显单纯的使用最短编辑距离来计算公司名称的相似度忽略的 公司名称各部分权重的不同,导致【科技】比【云瑶】关键字的匹配一样或更重要。
3.2 改进最短编辑距离匹配
针对单纯使用最短编辑算法匹配无法反应语意上的相似性,在匹配时引入了对公司名称各部分权重的计算。同样的编辑距离,如果权重越高的词匹配则匹配度越高。比如【云遥网络科技(上海)有限公司】和【深圳市麟云科技有限公司】在分词时已经标注了关键词、行业词和地名词,如果所示:

在匹配时先分别计算每个部分的匹配分数,然后按照8:1:1的权重分配计算最终的加权匹配分数,这样就修正了直接匹配时的不足,让关键词部分匹配分数越高的公司最终的匹配分数越高:
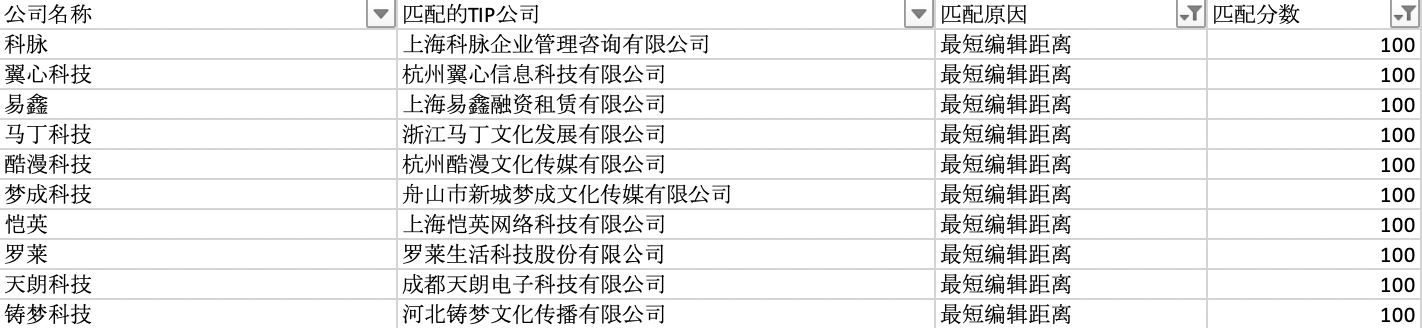
3.3 提升效果
相比原来SQL LIKE形式只匹配了1100+家公司,这种方案在此基础上新增了匹配分数为 100 分的 456 家,匹配分数在 90 分以上的 789 家,匹配分数在 80 分以上的 1810 家。
4. 不足与方向
此种方案主要是在字符串模糊匹配的基础上做了语义化的拆分和加权匹配,它的效果依赖于前期分词和形式化分类的好坏,如果不能正确的按照语义把公司名称拆分并归类到不同的分类中,后面的加权匹配效果就会大打折扣。
随着人工智能的发展,基于深度学习的语义匹配已成为NLP领域基础技术,公司也有相关的开源框架 深度语义匹配框架 可供参考学习。
5. 总结与沉淀
本文需要解决的是公司简称和全称之间的匹配问题,传统的字符串模糊匹配在匹配字符数量相差很大的情况下通常得分很低(简称长度通常在2~6个字符,全称则通常是10个字符以上)。针对此问题本文总结了一些方式和方法来提高匹配率,主要包括如下四个步骤:
- 形式化表示公司全称。对公司全称进行分词并根据各部分的词性形式化的表示公司名称结构(RXIO)。
- 猜测可能的简称形式。根据既定的规则分解出全称可能的简称形式,作为待匹配项。
- 所有待匹配项和简称进行加权模糊匹配。匹配时根据最短编辑距离计算 XIRO 各部分的匹配分数,再按照每个部分的权重计算最终的加权匹配分数,减少非关键词部分对匹配分数的影响。
- 选择所有匹配中的最高分作为此全称和简称匹配的最终得分。
所以在遇到传统单独字符串模糊匹配无法有效解决匹配问题时,尝试通过分词与自定义规则组合,再结合字符串模糊匹配和加权系数,可能取得较好的效果。

Recommend
-
115
如何进行“有效”测试的探讨 Original...
-
81
卓越管理的秘密
-
61
需求分析让人头秃,笔者针对这个问题展开了通俗易懂的阐释,希望给大家以帮助。 你有没有因为需求分析四个字,而感到头发日渐稀少?你有多少个失眠的夜,是在思考领导说的“把系统优化一下”这句简单的话?你又有多少次面对客户无休止的需求变更,而想要拔刀相向的冲...
-
31
欢迎来到大型情感类专题:如何进行有效需求分析——业务场景篇!场景二字,或许我们再熟悉不过了,在整个产品的实现过程中,它都是这么的如影随形。场景是很具体的,因为它是客观存在的,我们凭借肉眼,就能够捕捉到它;但场景又似乎很抽象,我们每天都要纠结场景到...
-
7
产品助理如何和高级的产品经理进行有效沟通? 产品助理如何和高级的产品经理进行有效沟通?可能我问题的问题比较初级,比较担心对方觉得什么都不懂~~
-
8
如何进行有效的数据治理,提升数据价值? 在数据应用过程中,数据采集和数据治理是两大核心抓手。本文继《方法...
-
10
DAO组织应当如何有效进行资金管理? 链捕手 2021-05-01 10:20 摘要: DAO协议管理的加密资产已经超过140亿美元。
-
11
产品经理开评审会,如何有效进行需求评审? 至少需要五年以上经历产品回答:经历过你的需求被上级或者领导评审的心力路程,你如何评审1~3年产品的需求?怎么思考、怎么判断、怎么说、怎么给出建...
-
2
使用端到端立体匹配网络进行单次 3D 形状测量,用于散斑投影轮廓测量标题:Single-shot 3D shape measurement using an end-to-end stereo matching network for speckle projection profilometry期刊:Optics Express [2021]年份:202...
-
3
LCD驱动端与设备端名称匹配过程在tiny4412提供的内核下,LCD屏的平台设备名字和平台驱动名字不匹配也能驱动屏点亮,这是怎么回事的呢?下面我们来分析这是如何实现的。硬件平台Cpu:exynos4412板子:t...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK