

What Is the Singular Value Decomposition?
source link: https://nhigham.com/2020/10/13/what-is-the-singular-value-decomposition/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
What Is the Singular Value Decomposition?
A singular value decomposition (SVD) of a matrix 

where 




Partition ![U =[ u_1,\dots,u_m]](https://s0.wp.com/latex.php?latex=U+%3D%5B+u_1%2C%5Cdots%2Cu_m%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![V = [v_1,\dots, v_n]](https://s0.wp.com/latex.php?latex=V+%3D+%5Bv_1%2C%5Cdots%2C+v_n%5D&bg=ffffff&fg=333333&s=0&c=20201002)
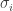








![\notag \Sigma = \left[\begin{array}{ccc}\sigma_1&&\\ &\ddots&\\& &\sigma_n\\\hline &\rule{0cm}{15pt} \text{\Large 0} & \end{array}\right] \mathrm{for}~ m \ge n, \quad \Sigma = \begin{bmatrix} \begin{array}{ccc|c@{\mskip5mu}}\sigma_1&&\\ &\ddots& & \text{\Large 0} \\& &\sigma_m\end{array}\\ \end{bmatrix} \mathrm{for}~ m \le n](https://s0.wp.com/latex.php?latex=%5Cnotag++%5CSigma+%3D+++++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bccc%7D%5Csigma_1%26%26%5C%5C+%26%5Cddots%26%5C%5C%26+%26%5Csigma_n%5C%5C%5Chline+++++++++%26%5Crule%7B0cm%7D%7B15pt%7D+%5Ctext%7B%5CLarge+0%7D+%26++++++%5Cend%7Barray%7D%5Cright%5D++++++%5Cmathrm%7Bfor%7D~+m+%5Cge+n%2C+%5Cquad++++%5CSigma+%3D+++++%5Cbegin%7Bbmatrix%7D+++++++++%5Cbegin%7Barray%7D%7Bccc%7Cc%40%7B%5Cmskip5mu%7D%7D%5Csigma_1%26%26%5C%5C+%26%5Cddots%26+++++++++++++++%26+%5Ctext%7B%5CLarge+0%7D+++++++++++%5C%5C%26+%26%5Csigma_m%5Cend%7Barray%7D%5C%5C++++++%5Cend%7Bbmatrix%7D+%5Cmathrm%7Bfor%7D~+m+%5Cle+n+&bg=ffffff&fg=333333&s=0&c=20201002)
Here is an example, in which the entries of
![\notag A = \left[\begin{array}{rr} 0 & \frac{4}{3}\\[\smallskipamount] -1 & -\frac{5}{3}\\[\smallskipamount] -2 & -\frac{2}{3} \end{array}\right] = \underbrace{ \displaystyle\frac{1}{3} \left[\begin{array}{rrr} 1 & -2 & -2\\ -2 & 1 & -2\\ -2 & -2 & 1 \end{array}\right] }_U \mskip5mu \underbrace{ \left[\begin{array}{cc} 2\,\sqrt{2} & 0\\ 0 & \sqrt{2}\\ 0 & 0 \end{array}\right] }_{\Sigma} \mskip5mu \underbrace{ \displaystyle\frac{1}{\sqrt{2}} \left[\begin{array}{cc} 1 & 1\\ 1 & -1 \end{array}\right] }_{V^T}.](https://s0.wp.com/latex.php?latex=%5Cnotag+A+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Brr%7D+0+%26+%5Cfrac%7B4%7D%7B3%7D%5C%5C%5B%5Csmallskipamount%5D++++++++++++++++++++++++-1+%26+-%5Cfrac%7B5%7D%7B3%7D%5C%5C%5B%5Csmallskipamount%5D++++++++++++++++++++++++-2+%26+-%5Cfrac%7B2%7D%7B3%7D+%5Cend%7Barray%7D%5Cright%5D+%3D+%5Cunderbrace%7B+%5Cdisplaystyle%5Cfrac%7B1%7D%7B3%7D+%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7D+1+%26+-2+%26+-2%5C%5C+-2+%26+1+%26+-2%5C%5C+-2+%26+-2+%26+1+%5Cend%7Barray%7D%5Cright%5D+%7D_U+%5Cmskip5mu+%5Cunderbrace%7B+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+2%5C%2C%5Csqrt%7B2%7D+%26+0%5C%5C+0+%26+%5Csqrt%7B2%7D%5C%5C+0+%26+0+%5Cend%7Barray%7D%5Cright%5D+%7D_%7B%5CSigma%7D+%5Cmskip5mu+%5Cunderbrace%7B+%5Cdisplaystyle%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+1%5C%5C+1+%26+-1++%5Cend%7Barray%7D%5Cright%5D+%7D_%7BV%5ET%7D.+&bg=ffffff&fg=333333&s=0&c=20201002)
The power of the SVD is that it reveals a great deal of useful information about norms, rank, and subspaces of a matrix and it enables many problems to be reduced to a trivial form.
Since 




and hence 

We can write the SVD as

which expresses 



and that the minimum is attained at

In other words, truncating the sum 


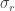
Relations with Symmetric Eigenvalue Problem
The SVD is not directly related to the eigenvalues and eigenvectors of 


so the singular values of 
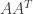
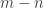


are plus and minus the singular values of 


Consequently, by applying results or algorithms for the eigensystem of a symmetric matrix to
Connections with Other Problems
The pseudoinverse of a matrix 

The least squares problem 



We can write 




Applications
The SVD is used in a very wide variety of applications—too many and varied to attempt to summarize here. We just mention two.
The SVD can be used to help identify to which letters vowels and consonants have been mapped in a substitution cipher (Moler and Morrison, 1983).
An inverse use of the SVD is to construct test matrices by forming a diagonal matrix of singular values from some distribution then pre- and post-multiplying by random orthogonal matrices. The result is matrices with known singular values and 2-norm condition number that are nevertheless random. Such “randsvd” matrices are widely used to test algorithms in numerical linear algebra.
History and Computation
The SVD was introduced independently by Beltrami in 1873 and Jordan in 1874. Golub popularized the SVD as an essential computational tool and developed the first reliable algorithms for computing it. The Golub–Reinsch algorithm, dating from the late 1960s and based on bidiagonalization and the QR algorithm, is the standard way to compute the SVD. Various alternatives are available; see the references.
References
This is a minimal set of references, which contain further useful references within.
- Jack Dongarra and Mark Gates and Azzam Haidar and Jakub Kurzak and Piotr Luszczek and Stanimire Tomov and Ichitaro Yamazaki, The Singular Value Decomposition: Anatomy of Optimizing an Algorithm for Extreme Scale, SIAM Rev. 60(4), 808–865, 2018.
- Gene Golub and Charles F. Van Loan, Matrix Computations, fourth edition, Johns Hopkins University Press, Baltimore, MD, USA, 2013.
- Roger Horn and Charles Johnson, Topics in Matrix Analysis, Cambridge University Press, 1991. Chapter 3.
- Cleve B. Moler and Donald Morrison, Singular Value Analysis of Cryptograms, Amer. Math. Monthly 90, 78–87, 1983.
- Yuji Nakatsukasa and Nicholas J. Higham, Stable and Efficient Spectral Divide and Conquer Algorithms for the Symmetric Eigenvalue Decomposition and the SVD, SIAM J. Sci. Comput. 35(3), A1325–A1349, 2013.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK