

渗透基础——利用Unicode编码混淆字符串
source link: https://3gstudent.github.io/3gstudent.github.io/%E6%B8%97%E9%80%8F%E5%9F%BA%E7%A1%80-%E5%88%A9%E7%94%A8Unicode%E7%BC%96%E7%A0%81%E6%B7%B7%E6%B7%86%E5%AD%97%E7%AC%A6%E4%B8%B2/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

渗透基础——利用Unicode编码混淆字符串
0x00 前言
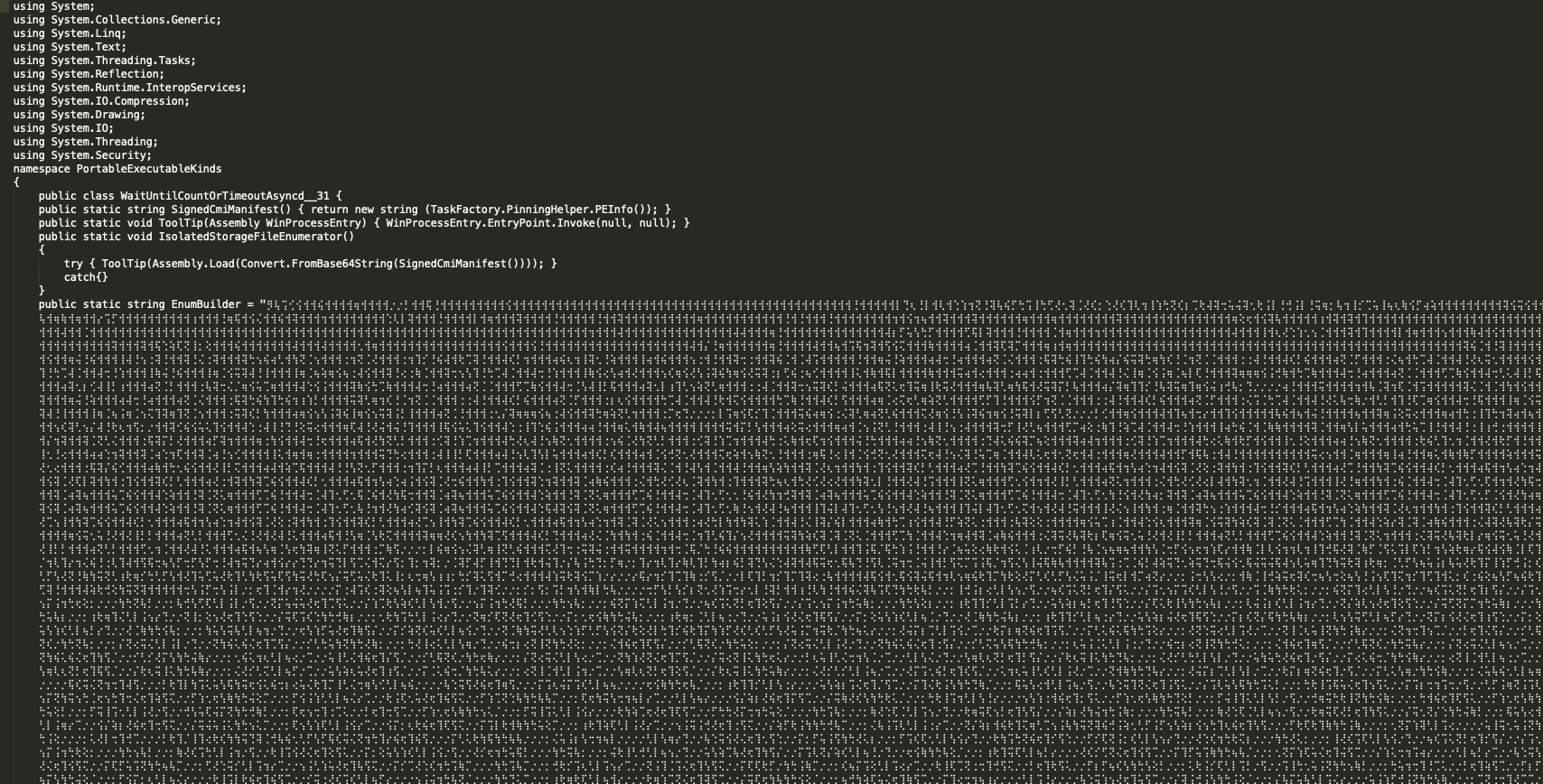
在渗透测试中,通常会对关键代码(例如shellcode)进行混淆,以此来对抗静态检测和分析。 我最近看到了一个有趣的样本,使用Braille Patterns(盲文点字模型)对字符串进行混淆,这对静态分析造成了很大的困难。
样本地址:
https://www.virustotal.com/gui/file/06f90a471f65de9f9805a9e907d365a04f4ebed1bf28b458397ad19afdb9ac00/detection
本文将会介绍这种利用Unicode编码混淆字符串的方法,通过程序分别实现对Braille Patterns(盲文点字模型)的编码和解码,分享使用其他Unicode字符表编码和解码的思路。
0x01 简介
本文将会介绍以下内容:
- 样本字符的实现原理
- 通过程序实现编码
- 通过程序实现解码
- 使用其他Unicode字符表编码和解码的思路
0x02 样本字符的实现原理
基础知识1:Unicode
Unicode是一个编码方案,是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求
简单理解:我们在计算机中看到的任何字符都对应唯一的一个Unicode码
对应到上面提到的样本,虽然使用了Braille Patterns(盲文点字模型)对人工分析造成了困难,但是如果将每一个字符转换成Unicode码,就可以克服这个问题
基础知识2:Braille Patterns(盲文点字模型)
是专供盲人摸读、书写的文字符号
盲文共有64种符形,即每个字符的样式有64种
盲文点字模型在Unicode码表上共有256个区位,即有256个Unicode码对应盲文点字模型
为了能够支持更多的字符,在对应关系上使用以下方式:
- 小写英文字母对应单个Unicode码
- 阿拉伯数字对应两个Unicode码,第一个Unicode码固定为
U283C - 大写英文字母对应两个Unicode码,第一个Unicode码固定为
U2820
注:
小写英文字母也对应两个Unicode码,第一个Unicode码固定为U2830,但通常省略第一个Unicode码
我们在代码混淆的过程中,可以不遵循以上语法,提高代码分析的难度
例如先将代码作base64编码(共有64个字符),再随机对应到Braille Patterns(盲文点字模型)的256个区位上
综上,我们可以得出实现原理:将待加密的字符转换成Unicode码,再从Unicode码转换成实际的符号
所以解密也十分简单:不需要考虑符号多么复杂,先转换成Unicode码,再进行分析
为了提高效率,下面分别介绍程序实现编码和解码的方法
为了直观的理解,程序实现上均使用Braille Grade 1编码,即逐个字母的转换,不包括缩写等单词
0x03 通过程序实现编码
对于编码的实现,优先考虑简单实用,所以选择通过网页实现编码
可供参考的资料:
http://www.byronknoll.com/braille.html
这个网站支持Braille Grade 1编码
通过查看源代码可以发现,http://www.byronknoll.com/braille.html通过js脚本实现Braille Grade 1编码
所以我们只需要简单的修改(修复一些转码bug,去掉一些功能)即可
查看转码过程是否存在bug,我们需要知道每个盲文字符对应的Unicode码和HTML码,可供参考的资料:
https://www.ziti163.com/uni/2800-28ff.shtml?id=83#
Unicode码同英文字符的对应关系可参考资料:
http://www.doc88.com/p-695153826363.html
原来的代码分别支持大、小写字母,数字和部分特殊符号,在特殊符号的处理上存在一些bug,例如+和!的转换不正确
我修改过的代码已上传至github,可直接访问进行编码,地址如下:
https://3gstudent.github.io/tool/BrailleGenerator.html
支持以下字符:1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ),!/-.?;'$
测试如下图

注:
我的代码只作为开发的模板,所以+和!的转换bug未修复,未支持+和=
0x04 通过程序实现解码
为了能够同利用方式相结合(例如内存加载PE文件),所以这里使用C sharp实现
关于内存加载PE文件的细节可参考之前的文章《通过.NET实现内存加载PE文件》
程序实现流程如下:
1.将从BrailleGenerator.html获得的盲文字符存储在数组中 2.将盲文字符转码成Unicode字符,需要注意阿拉伯数字和大写字母占用两个Unicode字符 3.通过对应关系,将Unicode字符转换成实际的字符
代码已上传至github,地址如下:
https://github.com/3gstudent/Homework-of-C-Sharp/blob/master/BrailleToASCII.cs
支持以下字符:1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ),!/-.?;'$
支持.Net3.5及更新版本
编译命令如下:
C:\Windows\Microsoft.NET\Framework\v3.5\csc.exe BrailleToASCII.cs
or
C:\Windows\Microsoft.NET\Framework\v4.0.30319\csc.exe BrailleToASCII.cs
0x05 使用其他Unicode字符表编码和解码的思路
将代码转换成Unicode码,通过自定义的映射关系生成新的Unicode码,最后转换成对应的符号
可供参考的代码:
https://github.com/3gstudent/3gstudent.github.io/blob/master/tool/BrailleGenerator.html
在利用上依照加密的映射关系进行解密就好
如果是分析代码经过混淆的样本,可在代码加载过程前设置断点,获得解码后的内容
0x06 小结
本文以Braille Patterns(盲文点字模型)为例,介绍了利用Unicode编码混淆字符串的基本方法,通过程序分别实现对Braille Patterns(盲文点字模型)的编码和解码,简要介绍使用其他Unicode字符表编码和解码的思路。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK