

Building an Analytics Tech Stack
source link: https://kdboller.github.io/2017/03/22/building-an-analytics-tech-stack.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Building an Analytics Tech Stack
Mar 22, 2017
In an ongoing attempt to be helpful to and learn from others serving in similar job capacities, I am continuing to review my experiences in building out our data infrastructure over the past ~12 months and discuss the most helpful applications which currently sit within our analytics tech stack. In my most recent post, Data Informed Experiments, I discussed the difference between being “data informed” and being “data driven”. I also provided some perspective related to building a “data informed” organizational culture – my intent is to share what we have learned along the way and discuss the applications which enable us to take advantage of all of the work we’ve completed to-date.
When I arrived at FloSports a little over a year ago, I joined as a Product Director of Subscription Revenue. The company had great momentum in a market, live sports streaming, which was and continues to experience remarkable growth. However, from a data and analytics standpoint, a data warehouse did not yet exist; reporting was somewhat fragmented and siloed among departments, often living in Google Sheets. Although financial and subscription reporting and KPI monitoring was in place, it was clear that the analytical foundation would have a very challenging time scaling alongside the company’s significant growth trajectory. Among other aspects of our business model, in just a year and a half we’ve grown from producing and selling subscriptions against live events for 5 sports to over 20 sports, and this continues to grow.
For business intelligence (BI), most companies consolidate their key data sources into a centralized data warehouse (DW); the process of extracting data from various sources and loading it into the DW is referred to as ETL; for reporting purposes, a business intelligence / reporting application is connected to the data warehouse, allowing for dashboards to be created with reports that leverage one or more of the DW’s data sources. While the build out of a DW is time consuming and can be challenging at times, the quick highlights of this process for us, which we kicked off less than a year ago, include the following:
- Select where your data warehouse will reside / be hosted; like many other growth, tech companies, we selected Amazon Redshift
- Identify your most critical data sources and build a roadmap for data source expansion
- Evaluate build versus buy options along the way for key elements of the warehouse; I’ll discuss Segment in more detail later in this post
- Outline and document the business rules and logic which will define how data is modeled and how the facts about your data will be reported on
- Model all data and ensure that you have a ‘source of truth’ which you will use to validate each source loaded into your data warehouse
- Choose BI visualization and ETL tools which best suit your organization’s requirements, budget and your team’s overall technical sophistication
For the remainder of this post, I’ll highlight a few important tools which we’ve made use of since the second half of last year. These applications are incredibly important to every aspect of the analysis that we conduct and report on – in combination with our data warehouse, they’ve empowered me to be able to leave the world of “CSV extract, read into Jupyter Notebook, extract back to CSV, paste into financial model, and output to powerpoint”; I truly could not be more thankful.
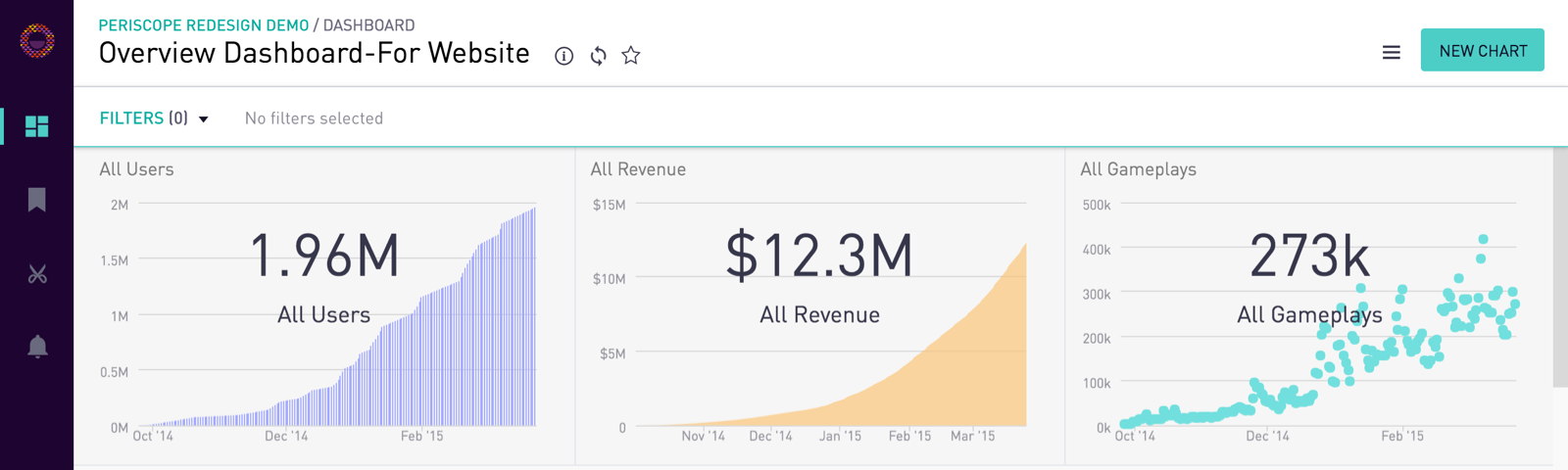
I was aware of Periscope Data while we were in the process of standing up our data warehouse; however, this post on Medium by Samsun Hu provided tremendous insight into the benefits of Periscope relative to more traditional, and generally costlier, BI tools.
At FloSports, we use Periscope as our ‘consumer facing’ dashboard product – we have permissioned our dashboards by Groups and placed our business users into the Groups which align with their reporting needs and use cases. Here are my primary observations:
Benefits
- Filters: these allow for highly interactive dashboards, where end users can filter on different sports and date ranges to manipulate the returns in the various queries; this assists with scalability -- we can build a single dashboard which can be cut a number of different ways and on demand without data team involvement
- Views: Views can be added, via directly loading SQL or CSV files, bypassing the need for ETL and enabling quick proof-of-concept dashboards which allow for demos of new data sources / data modeling
- Data Cache: this ETLs customer databases into Periscope’s Redshift clusters, making queries highly performant and also enabling cross database joins, materialized views, and query-able CSV uploads
- Outstanding customer support; data scientists are available via chat during business hours, oftentimes reviewing queries you are working on and helping you figure out how to write more complicated queries (or if you’re just stuck and need another set of eyes)
Considerations
- Cost: While Periscope Data is very easy to get going, pricing scales by every 1 billion rows; as one example on why this can be frustrating, we point our Staging database to Mode (see below) to avoid being bumped up to the next pricing tier
- Internal research / analytics; creating finalized dashboards for end user consumption is great; however, in terms of internal analysis, creating “burner” dashboards starts to become a maintenance headache
- For this reason, we prefer to use Mode for internal research / collaboration type work (also see below)
Mode Analytics
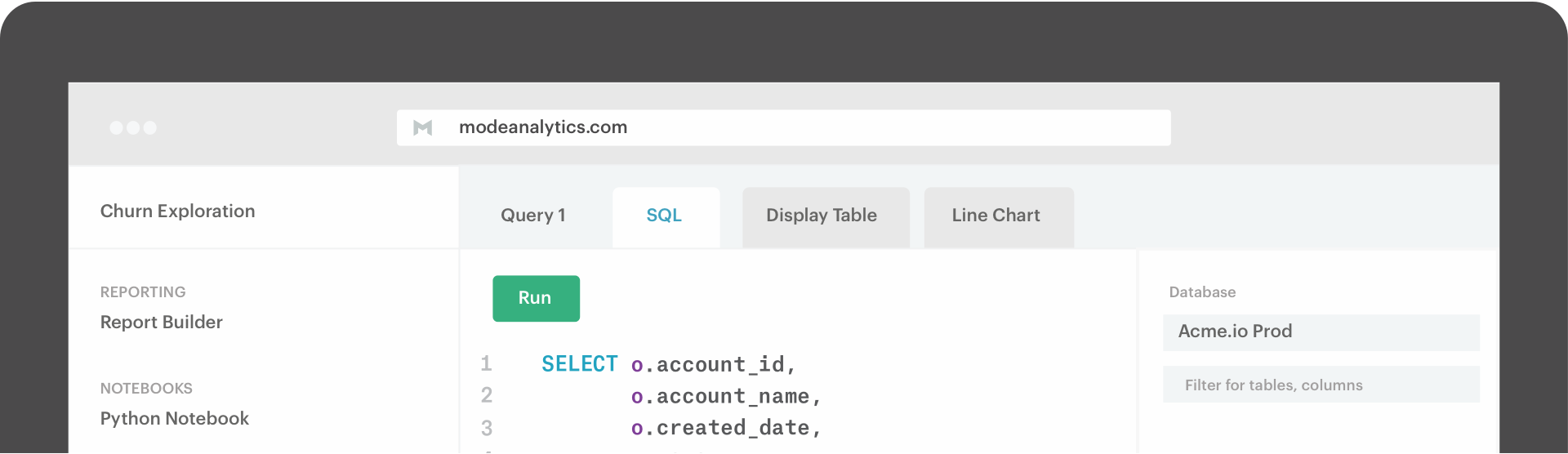
Mode Analytics markets its product as “a SQL editor, Python notebook, and visualization builder, all rolled into one.” After using it since November, I’m a huge, huge fan and I spend a significant amount of several days per week working in Mode.
Benefits
- Report builder concept; create a report, which includes a series of separate SQL queries and also allows for quick visualizations and an overall dashboard summary of data returns
- Shareability of reports; similar in concept to Google Drive, share report links with other team members within Mode, who can then edit, add to, or clone your report for further analysis
- We sometimes conduct analysis in Mode and export the dashboard as a PDF report which we send to business users
- The ability to read data into a Python notebook; create a dataset via an SQL query and read it directly into the Python Notebook within the same application for more detailed analysis
- Their blog and tutorials for SQL and Python are some of the best I’ve seen -- and you can create a Mode account and learn the application for FREE on public data sets
Considerations
- Dashboard features; while Mode is generally a great product, the one limitation is the ability to create interactive dashboards, e.g., filterable by attributes, which we make tremendous use of within Periscope Data
Segment
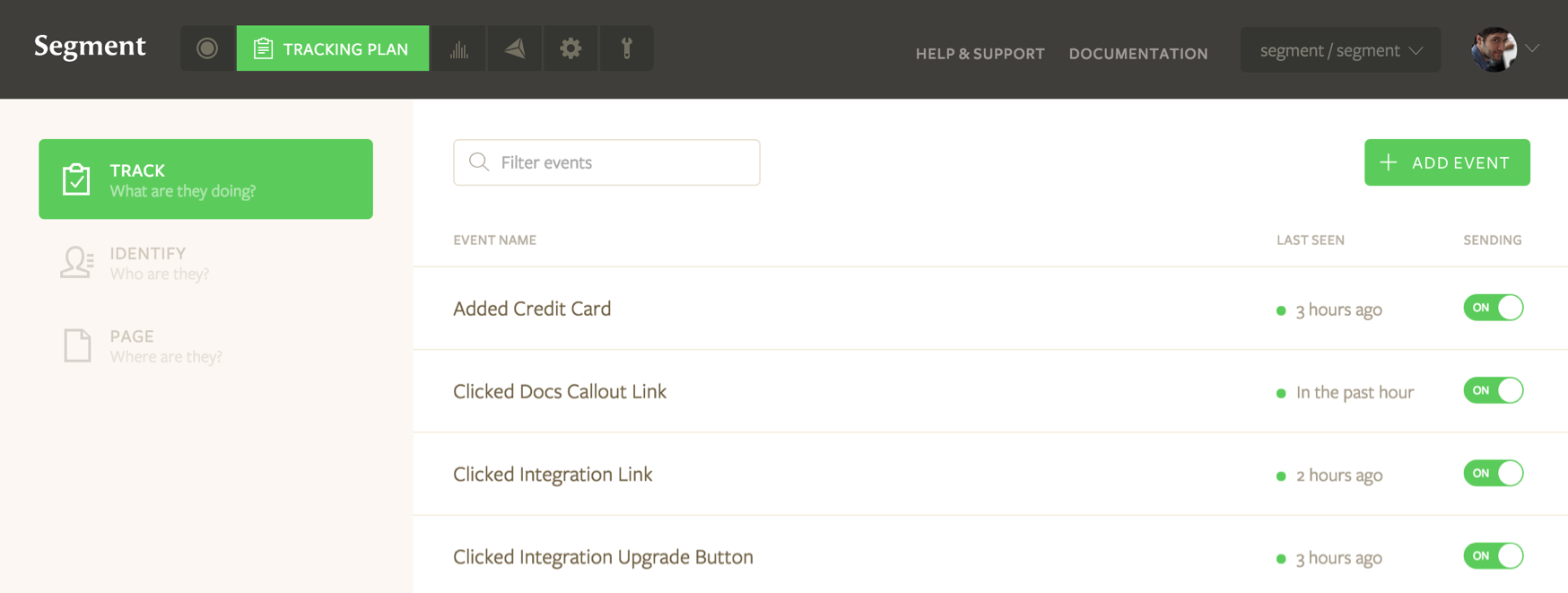
When building out a DW, there will always be a tradeoff between time spent engineering the ETL process / workflow(s) and creating reporting tables, e.g., aggregate fact tables, conducting machine learning, etc. The ETL serves as the plumbing of the DW and it’s obvious that high quality data is requisite to enabling key insights; as Bob Becker from the Kimball Group wrote: “At its foundation, the DW/BI environment must be a repository of high quality data. The biggest challenges for most DW/BI efforts are data-related. In general, the effort to develop the ETL processes required to provide high quality data is typically more demanding than anticipated” (my emphasis added).
At FloSports, we are currently implementing Segment to serve as our customer data platform as well as the ETL-as-a-service for several of our data sources. We initially evaluated Segment’s Sources product earlier this year, which ETLs Zendesk, Salesforce, Stripe and a few other widely used cloud app sources. In the buy versus build scenario, the key question we were asking ourselves was whether or not we wanted to invest the time and resources in figuring out how to best ETL all of the data sources on our roadmap; or could we find a way to short circuit this? If we could bypass certain parts of the ETL, we would free up much more of our engineering time to generate valuable reporting which stitches multiple data sources together.
My personal view is to always maintain focus and to drill on your core competency as much as possible – no off-the-shelf solution can define the logic which our business model dictates, and our user journey and combination of data sources are unique to our business. However, the process by which we ETL the data into a centralized repository does not need to be our core competency; after extensive evaluation, we determined that Segment was a very viable option which enables us to acquire several important, and widely used, data sources.
Further, we want to warehouse all of our data across our applications and all 3rd party integrations and external data sources; and we really need a common identifier approach to tracking anonymous and logged in users across our various properties and platform. As a result, after extensive diligence we decided Segment’s customer data platform seemed to be the most time efficient and productive way to accomplish this, in combination with their Sources product.
Benefits
- Cloud App Sources; the punchline here is this is ETL-as-a-service, point and click data source integration with your existing warehouse
- 200+ native integrations; Segment will send data generated within your apps to 3rd party services; similar in concept to a tag manager, except that Segment stores all data generated...forever
- Warehouse connection; track data within your app and Segment will send the generated data to your connected data warehouse
- Extensively helpful during diligence; we diligenced Segment for almost 2 months; our counterparts were knowledgeable and very helpful in assisting us with getting our heads around the benefits of a partnership
Considerations
- If you get the enterprise plan, this will be a material expense line item on your budget; I built a bottoms-up model that projected our Monthly Tracked Users (MTUs) for the next two years in order to discuss volume-based pricing
- Nevertheless, you can either build this all in-house or leverage Segment for certain elements; there are tradeoffs with any SaaS product versus a build, but if we spend the majority of our time generating insights and drilling on our core competencies, we should generate the high ROI we anticipate
- ** You may want to discount my review here in general, as we are currently implementing Segment, whereas I’ve been working with Periscope and Mode for 6+ months
This concludes my initial review of our journey in building out our data infrastructure over the past ~12 months and an overview of the most helpful applications which currently sit within our analytics tech stack. As our data warehouse product owner, I’ve taken a rather methodical approach in evaluating these applications, and we’ve found them to all be great products with excellent customer support and transparent visibility into their own product roadmaps. Over the course of the next year, we will be in the process of transitioning from smoothing out and expanding our analytics foundation to setting up our analytics stack to scale. I look forward to continuing to share our lessons learned and achieved victories along the way.
If you have any feedback or insights into how you’ve built out and grown your analytics infrastructure, and / or your approach to BI, I would love to hear from you in the comments.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK