

android中tesseract-ocr的介绍
source link: https://www.longdw.com/2013/12/20/android-tesseract-ocr/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

android中tesseract-ocr的介绍
最近在做身份证号码识别,在网上搜索的一番后发现目前开源的OCR中tesseract-ocr算是比较强大的了,它由HP于1985年到1995年间开发,后来由google直接负责,经过谷歌进一步开发后,目前的tesseract-ocr有了显著的改进。
tesseract-ocr和Leptonica图像库一起工作,它可以读取多种图像格式,并将其转换成超过60种语言的文本。可以工作在Linux,Windows,Mac OSX等系统上,并且可以在android和iphone平台上编译。
目前android版本在这个地址:https://code.google.com/p/tesseract-android-tools/, 这个版本需要自己下载很多关联的库文件,我在编译的时候出了很多问题,后来没办法又在网上找到了这个项目:https://github.com/rmtheis/tess-two,说是tesseract-ocr-tool的一个分支,这个版本的好处是很多相关的库都已经为我们配置好了,我们只要git clone下来编译下就行了,github上相关介绍说的很详细,编译的过程这里就不做介绍了,我在编译的时候出现了permission权限的问题,文件的权限用chmod 777 ./ 这个命令修改下就Ok了。最后编译好的在libs下的so文件就是我们开发所需要的库文件。
android中tesseract-ocr的使用在tess-two这个项目中有例子程序,不过写的都比较简单,这里有个开源的识别项目,做的很好:https://github.com/rmtheis/android-ocr, 我借鉴的就是这个项目来开发的,但是用过后发现,对于身份证识别的效果并不好,识别率不是很高,而且经常识别不出来。OCR用到的识别库:https://code.google.com/p/tesseract-ocr/downloads/list,其实我们可以根据自己的需求来训练一套自己的识别库的,比方说我们要识别验证码,识别身份证号码等,我们就可以用下面的方法来训练一套识别库。
网上关于OCR训练的方法很多,http://my.oschina.net/lixinspace/blog/60124, http://blog.wudilabs.org/entry/f25efc5f/这两篇文章都是比较好的教程,我也是参照这两篇文章来训练的,下面结合我的操作经验来说下训练的过程。
首先我们需要下面几个工具:
tesseract-ocr-3.01, 最新版的3.02我在我机器上用了有点问题
jTessBoxEditor, 该工具是用java写的box编辑器
1、先新建一个trainocr文件夹,将上面两个文件拷贝进来,然后解压这两个文件,我们进入Tesseract-ocr文件夹下新建一个temp文件夹
2、接下来我们准备好我们需要训练的素材如下图
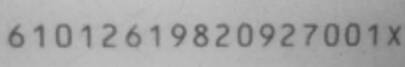
要想提高识别率,我们需要提供多张像上面这样的图片,我训练身份证号码识别库是用了50多张图片,等训练完了我眼睛也花了,图片格式需要为tiff格式的,可以通过windows自带的画图工具来另存为tiff格式,准备好多张图tiff图片后,打开jTessBoxEditor.jar,如下图
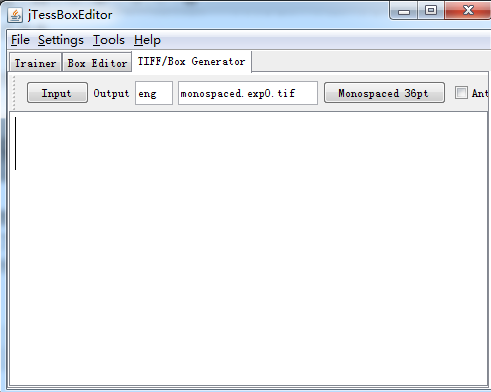
在此之前我们需要在第1步建立的temp文件夹下新建一个custom.tif的文件,接下来我们选择tool–>Merge TIFF 然后选择准备好的多张tiff图片,注意这里是全部选中,然后点击打开,然后选中我们刚刚建立的custom.tif文件,点击保存,这样我们就将多张tiff图片merge到了一个文件里面了。
3、接下来我们开始生成box文件了,cmd命令行进入temp文件夹下,然后输入如下命令
D:\Trainocr\Tesseract-ocr\temp>..\tesseract.exe custom.tif custom batch.nochop makebox
输入完后会在temp文件夹下多了个custom.box文件,该文件记录了识别出来的每个字和它对应的位置坐标。
4、接下来就开始矫正了,同样使用jTessBoxEditor工具,我们切换到Box Editor,然后open打开custom.tif,如图

通过右上角的X,Y,W,H对每个需要改正的字符进行调整,注意调整好后别忘记保存。
5、接下来是计算字符集,输入如下命令
D:\Trainocr\Tesseract-ocr\temp>..\unicharset_extractor.exe custom.box
6、接下来我们需要在temp文件夹下建一个font_properties文件,3.01版本的OCR需要这个文件,该文件的目的是提供输出时识别出来的字体样式信息,文件的格式为
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
timesitalic 1 0 0 1 0
我们可以根据实际情况新建font_properties,我写的是
custom 0 0 0 0 0
意思是普通字体,没有任何格式。
然后执行以下命令
D:\Trainocr\Tesseract-ocr\temp>..\mftraining.exe -F font_properties -U unicharset custom.tr
7、Clustering,输入命令
D:\Trainocr\Tesseract-ocr\temp>..\cntraining.exe custom.tr
8、此时在temp文件夹下已经有很多文件了,需要把inttemp,Microfeat,normproto,pffmtable,unicharset这几个文件加上前缀custom. (注意有个点号),然后输入以下命令
D:\Trainocr\Tesseract-ocr\temp>..\combine_tessdata.exe custom.
出来的结果中我们需要确定type 1,type3, type4, type5对应的后面数据不能为-1,这样我们就可以用这个新字典来识别了,将生成的custom.traineddata文件拷贝到tessdata文件夹下,然后
tesseract test.jpg result | custom
就可以通过新的字典来识别,测试结果表明,识别率确实提高了。现实应用中我们需要使用多张图片来通过上面的步骤来生成我们需要的识别库,这样识别率才能提高。
这段时间不少热心的朋友找我要训练后的字典,这个项目都过去快一年了,都忘光了,技术上的东西文章中都介绍了,其他的大家有空就多在网上搜搜吧。我这里附上我训练过的字典
分类Android
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK