

@adlrocha - I have been underestimating JS - @adlrocha Weekly Newsletter
source link: https://adlrocha.substack.com/p/adlrocha-i-have-been-underestimating
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
@adlrocha - I have been underestimating JS
Understanding V8 and NodeJS Steams

I wasn’t a huge fan of Javascript in general and NodeJS in particular. I was usually more fond of other lower-level languages such as Go or Rust. I mistakenly thought Javascript and NodeJS couldn’t give me the low-level control I usually want in order to get the most out of my applications. Too many frameworks, too many things under the hood I didn’t understand, very broad data types, etc. Not cool.
To my surprise, I was completely wrong. My problem was that I hadn’t gone deep enough into Javascript programming to be able to release its full potential. Fortunately, thanks to my obsession lately with WASM, browser engines, compilers, and virtual machines, I’ve been discovering certain concepts that have made me reconsider my opinion around the Javascript ecosystem. By understanding the internals of JS and NodeJS you can easily achieve powerful things I thought were only reserved for other lower-level and more complex programming languages.
V8: The High Performance engine
In order to start performing low-level actions with Javascript, and drive its performance to the limit, it is worth understanding what our JS code is doing under the hood. For instance, you may need high precision in your JS computations, but do you know if the Number type is an int32 or a float64? Even more, you want to perform complex computations over large pieces of data with high performance in mind, do you know where is this data stored in your hardware, or the maximum size in which you need to divide your data to process it efficiently? The answer to all this questions are usually solved by the Javascript VM. There are several JS engines out there: V8 from Google, SpiderMonkey from Mozilla, JavaScriptCore from Apple, etc. For the purpose of this publication I’ll focus on V8, which is the one used by NodeJS.
So what is V8 exactly? V8 is Google’s open source high-performance JavaScript and WebAssembly engine, written in C++. In short, it is a C++ program which receives Javascript code, compiles it and executes it. Thus, V8:
Compiles and executes JS code.
Handles the call stack and runs your JS functions in order.
Manages memory allocation for objects, i.e. the memory heap.
Performs garbage collection tasks for objects no longer used in a program.
And provides the representation of all the data types, operators, objects and functions.
In some cases, as in NodeJS, V8 also provides the event loop, but this is not the case with certain browser which use V8 but implement their own event loop.
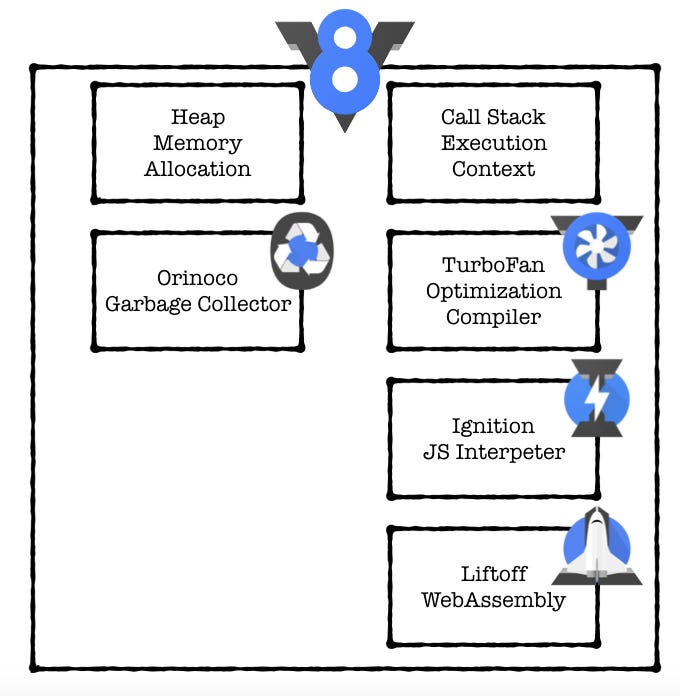
V8 is a single threaded execution engine. It’s built to run exactly one thread per JavaScript execution context. You can actually run two V8 engines in the same process — e.g. web-workers, but they won’t share any variables or context like real threads. This doesn’t mean V8 is running on a single thread, but it does mean it provides a JavaScript flow of a single thread.
On the runtime, V8 is mainly managing the heap memory allocation and the single threaded call stack. The call stack is a list of function to execute, by calling order. Every function which calls another function will be inserted one after the other directly, and callbacks will be sent to the end. This is actually why calling a function with setTimeout of zero milliseconds sends it to the end of the current line and doesn’t call it straight away (0 milliseconds). These are the kind of concepts we need to bear in mind if we want to drive the performance of our JS program to the limit.
V8’s JIT Compilation and Garbage Collection
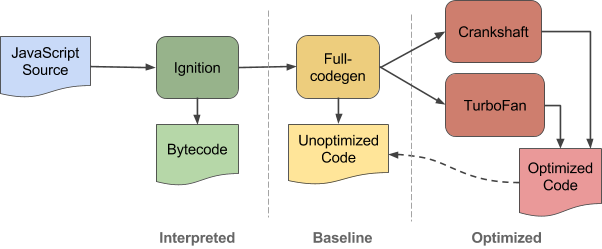
The speed of V8 comes from its just-in-time (JIT) compilation of JS to native machine code. How is this done? Firstly, the code is compiled by a baseline compilation which generates non-optimized machine code. On runtime, the compiled code is analyzed and can be re-compiled for optimal performance. The modules in charge of performing this tasks are Ignition, Crankshaft and Turbofan (in case you want to go a bit deeper on how this compilation is performed).
This JIT compilation is what allows us to use NodeJS’ CLI to directly run commands in console and test some code while we are developing (who hasn’t use this tool to make some quick tests before adding some weird code to his project?).
V8 also includes a garbage collection module, Orinoco. This module runs over the memory heap looking for unused objects and moving things around to free space and ensure you make and efficient use of your memory resources (I can imagine the panic in the faces of some JS developers I know if they had to manage the memory in JS themselves).
Putting it simply, the garbage collection module marks objects allocated in memory as dead or alive. V8 allocates memory in the heap as you create new objects, or new “pointers” (javascript doesn’t have real pointers, so pointers are technically just copied references to an original object. This is another interesting concept to bear in mind in order to write memory-efficient programs).
V8 divides the heap into two parts: young space and old space. When you perform an operations that requires V8 to allocate memory, it allocates space in the first portion. As you keep adding things to the heap, you eventually run out memory, so V8 will have to run a collection to clean up. Newly created objects are allocated super quickly and get scavenged (a shorter and quicker collection) on regular bases to remove already dead objects. Once the objects “survive”, they get promoted to old space, which gets garbage collected in a separate cycle when full.
Older objects are the ones that survive more than one garbage sweep, meaning they keep being referenced by other objects and still need that memory allocation. They normally don’t reference younger objects, but do reference older ones. Understanding how memory is managed in V8 can allow us make better decision when managing data in our program.

Nerdy Footnote I: Within Node.js, if you are curious to know the memory usage of a program you can easily do it using process.memoryUsage(). Learn by example: Buffers
Let’s give a brief example on how understanding what JS does under the hood (and in this specific case NodeJS) can help us write better code. Imagine you have a NodeJS server that needs to receive high amounts of data from a TCP Stream, process it, and store it in a database. How would you do this efficiently in JS? (This is a typical technical interview question, so if you are planning on switching jobs or applying for a big-tech be ready for this kind of questions :) ).
If you come from other lower-level language the answer may come straightforward to you. We can build a Buffer in order to wait for the data received from the stream and divide it in different chunk. We process every chunk when the buffer fills, store the data in the database, and free the buffer in order to keep going. How can we do this in NodeJS? Fortunately, we have a Buffer class to help us perform this task. But how is this buffer translated into memory?
A buffer is represented as a fixed-size chunk of memory which is allocated outside of the V8 Javascript engine (in the heap). Upon initialization, V8 pre-allocates a piece of memory in your device, so when we create a Buffer, the VM requests the allocation of free memory from this fragment to store the buffer. Thus, to create a buffer we can use one of these commands:
const buf = Buffer.from('Hey!')
const buf = Buffer.alloc(1024)
const buf = Buffer.allocUnsafe(1024)
But wait a minute, which one should I use? It depends (and this is why we need to understand a bit about the internals). While both alloc and allocUnsafe allocate a Buffer of the specified size in bytes, the Buffer created by alloc will be initialized with zeroes and the one created by allocUnsafe will be uninitialized. This means that while allocUnsafe would be quite fast in comparison to alloc, the allocated segment of memory may contain old data which could potentially be sensitive. Older data, if present in the memory, can be accessed or leaked when the Buffer memory is read. This is what really makes allocUnsafe unsafe and extra care must be taken while using it. So if we want to take the risk and be super-fast processing our TCP Stream we will have to allocUnsafe our Buffer.
Nerdy Footnote II: In previous versions of NodeJS there was a SlowBuffer class that used a C++ module for the allocation of memory. It was "slow" because the program required extra CPU time to perform the action. This class is now deprecated and it's been replaced by allocUnsafe.NodeJS Stream: A secret weapon
Ok! Our allocUnsafe Buffer works fine but, can’t we do better in the processing of data with our NodeJS server? In fact we can, welcome NodeJS’ streams!
Streams are a way to handle reading/writing files, network communications, or any kind of end-to-end information exchange in an efficient way. Using streams you read data piece by piece, processing its content without keeping it all in memory. So it basically abstracts what we were trying to do with buffers. Streams basically provide two major advantages using other data handling methods:
Memory efficiency: you don't need to load large amounts of data in memory before you are able to process it.
Time efficiency: it takes way less time to start processing data as soon as you have it, rather than waiting till the whole data payload is available to start.
So we don’t need our buffers to fill in order to start processing data. But you know another interesting feature of streams? The ability to use pipes. In our previous example, if we use Buffers, we have to worry ourselves about managing and processing them. NodeJS streams abstract this complexity from us (preventing us from making mistakes and non-efficient pieces of code), and allowing us to specify the processing actions to perform when a chunk of data is received, and where the processed data is sent (through a pipe). With this, the amount of memory to be allocated for the processing of the TCP stream is minimum. If you come from the world of Unix, NodeJS pipes are equivalent to the bash “|” pipes you’ve learned to love.
To illustrate the use of Pipes and streams let’s see how we would use them to implement a simple proxy server that forwards every request received:
http.createServer(function(request, response) {
var proxy = http.createClient(9000, 'localhost')
var proxyRequest = proxy.request(request.method, request.url, request.headers);
proxyRequest.on('response', function (proxyResponse) {
proxyResponse.pipe(response);
});
request.pipe(proxyRequest);
}).listen(8080);In short, to efficiently manage big chunks of data in NodeJS we can use streams, a common and powerful, but usually ignored (at least by me) feature in NodeJS.
Conclusions
To be completely honest, I have been despising JS all these years because I hated not having low-level control of what I was doing, specially when I had to approach applications with high-performance requirements. But it wasn’t Javascript’s fault but mine. I kept using packages and frameworks for everything I needed to do, and I didn’t invest the time to understand what was happening under the hood. I feel this is something that may have happened to many of you if you were used to programming in C, Python or Go, and you had to switch for some projects to JS. In this transition you might not have invested enough time to learn it the right way, and then is when shit happens :) For me, this is one of the drawbacks of the “Building Fast, Breaking Things” philosophy, you may be missing the key of some technologies.
So I would like to close this publication encouraging all of you to go deep in anything you learn to avoid the problems I myself have been facing in the case of Javascript. After this eye-opening experience, I still have tons of things to learn about JS (and other technologies I may have been despising). Fortunately I will be here every Sunday so we can walk down this path together.
References
Understanding garbage collection in V8. You can actually have memory leaks in NodeJS. You don’t believe me? Have a look at this article.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK