

一文读懂P4可编程交换芯片
source link: https://www.sdnlab.com/23761.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文主要内容根据中国银联周雍恺博士在P4峰会上的报告整理而成。
IHS Market预测,数据中心以太网交换机市场中,商用芯片出货将在2023年达到所有芯片的62%,高于2018年的56%;与此同时,专有/定制芯片将从2018年的38%下降至25%左右,可编程芯片将从2018年的6%上升至13%。由此可见,可编程交换芯片,未来将有极大的发展空间。
所谓“可编程交换芯片”
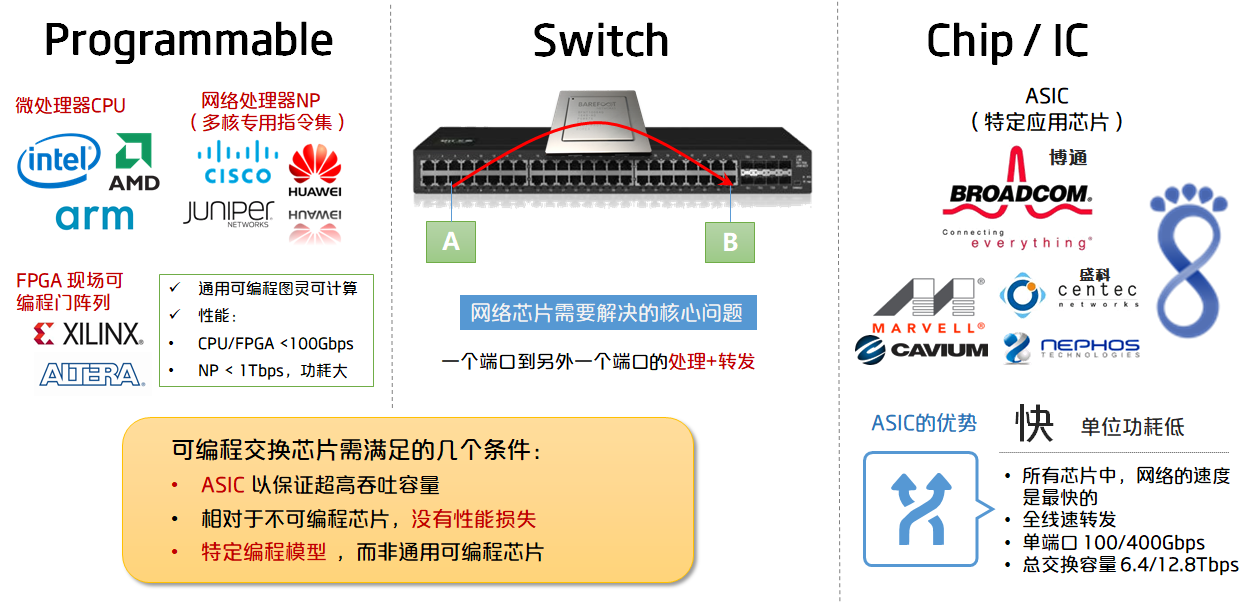
可编程交换芯片(Programmable Switch Chip/Integrated Circuit),先看交换,对于交换机,它所需要解决的核心问题是从一个端口到另外一个端口的处理与转发。
再看可编程,最常用的是以指令集为核心的CPU,以及以LUT门电路为核心的FPGA芯片,他们都是通用的可编程芯片,可以实现一切图灵可计算的问题。在网络领域,还有专门为网络处理优化的多核架构指令集,称作NP(网络处理器)。CPU和FPGA的总吞吐能力小于100Gbps,而NP最大的也只能做到1Tbps,而且所带来的功耗相当之大。
最后看芯片,这里指的是ASIC (Application Specific Integrated Circuit),也就是针对特定应用所涉及的芯片,它最大的特征就是快,同时单位处理的功耗相当之低。在所有的芯片中,网络的速度是最快的,一直强调的是全端口线速转发。目前基于ASIC的芯片,最大单端口能够做到100G或者400Gbps,总交换容量可以达到6.4T或12.8Tbps。
因此,高性能可编程交换芯片应当具备如下三点特性:
第一是ASIC,以保证交换的极致性能(包括吞吐量,低延时以及低功耗)。
第二是相对于同等级的固定流水线芯片,转发性能不可以降级。
第三是面向网络处理特定模型的可编程,而不可能是通用的可编程模型。
网络数据平面的可编程模型
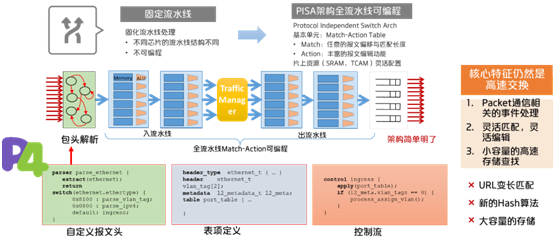
当前网络数据平面影响力最大的可编程模型无疑就是P4。
P4的可编程模型是相对于传统固定流水线的交换芯片而言的,它的架构是PISA(Protocol Independent Switch Arch)全流水线可编程架构。
简要来说,它的基本单元是match-action table。
match单元可以匹配任意报文的偏移与字段长度。
action单元,则有相对比较丰富的报文编辑功能
此外,片上资源SRAM与TCAM也可以进行灵活的配置。
整个P4的控制过程包括包头解析,可编程入流水线,可配置缓存管理TM,以及可编程出流水线的处理。对应的编程框架包括,自定义报文头,match-action表项的定义,以及全流水线控制流的串接。
可以看出,P4模型的核心特征仍然是基于网络包处理的高速交换,它可以实现Packet通信相关事件的处理,灵活匹配,灵活编辑,以及小容量的高速存储查找。
当然,交换性能的要求决定了P4只能实现包处理相关的可编程性,必定不是一个通用的编程模型。有一些是他所不能处理的,比如URL变长字段的匹配,编写一个新型的哈希算法以及大容量的存储,这些都是CPU,FPGA以及外挂的DRAM内存所擅长处理的。
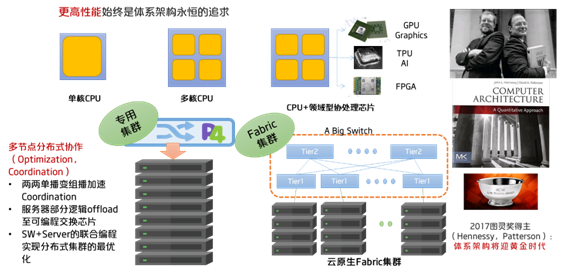
从体系架构的视角来看,更高的性能始终是体系架构永恒的追求。最早是单核的CPU,当主频无法再继续提升之后,便出现了多核的CPU用以处理并行的任务,随着摩尔定律逐渐走向瓶颈,CPU配合领域型协处理芯片的综合架构设计将成为主流。2017年图灵奖的得主John Hennessy和David Patterson坚信,未来10年体系架构将再次迎来黄金时代,领域型的芯片将会崛起。在这个过程中,有一套标准的编程模型是至关重要,P4所扮演的就是网络交换领域的这样一个角色。
P4的应用场景
关于P4的应用主要有4个方面:
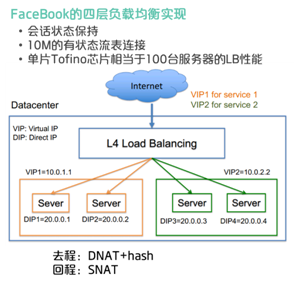
首先是替代传统的网元。在这方面最著名的实现就是Facebook SilkRoad负载均衡的实现。他利用P4可以全局调度片上资源的特性,在Tofino芯片上实现了高达1000万条有状态流表的负载均衡,同时吞吐量可以达到Tbps,性能远超市场上现有的四层负载均衡设备。
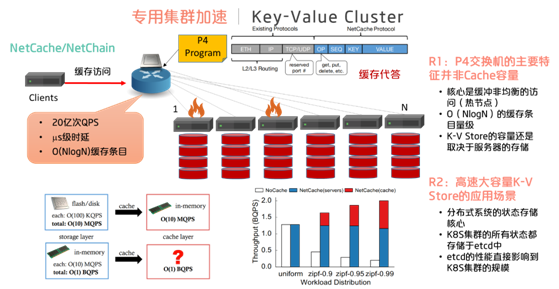
其次是专用的集群。通常网络交换只是进行了流量的转发。必须要配合服务器集群,才能构成一个完整的系统。可编程交换在其中,可以发挥的作用是参与多节点分布式的协作与协调。例如,两两单播可以变为组播加速coordination,此外,服务器的部分逻辑可以卸载到可编程的交换芯片上。可编程交换机加服务器集群的联合架构设计,可以最大程度地优化专用的分布式集群。在这里比较典型的是NetCache的应用,它实现了一个高性能的Key-Value对象存储集群。由于交换机的表项容量很有限,所以主要的键值对存储还是由后端的服务器以及大容量的磁盘来提供。交换机在此处主要实现的功能,是均衡不均匀的访问请求,避免热点的出现。也就是说,外部流量对于后端存储的访问越不均匀,则可编程交换机所能带来的增益越高,并且能够有确定性的时延响应保障。高性能的键值对存储,对于分布式协调尤为重要,它直接决定了一个分布式的可扩展规模。例如,Kubernetes集群的所有状态都存储于etcd中,etcd的性能直接影响到Kubernetes集群的规模。
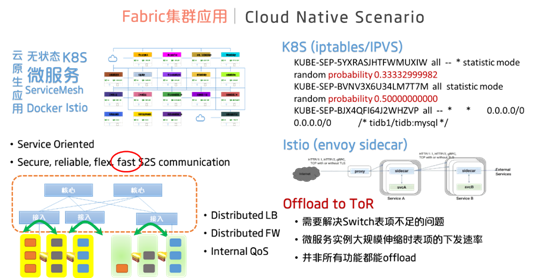
第三种是由小交换机通过CLOS组网结构所构成的Fabric集群,相当于一个大的交换机。在数据中心场景,它所需要实现的便是一个云原生的Fabric集群。当前,数据中心Fabric控制的实现主要有两种路线,一是Fabric仅实现简单的Underlay路由,复杂的逻辑则由主机或者智能网卡来承担,以SONiC为代表;二是云网络的功能诸如租户隔离、服务负载均衡、安全控制、流量控制、INT等都尽量下沉至Fabric中实现,以ONF的Stratum、加拿大公司Kaloom为代表。P4在后者的场景中将发挥重要的作用。
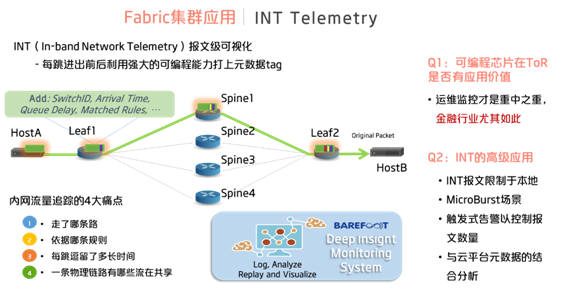
第四,就是网络遥测Telemetry的应用。这也是P4当年横空出世时的杀手级功能,其中最有名的就是INT(Inband Network Telemetry)。它的出现主要是为了解决内网流量追踪的四大痛点:一是网络包走了哪条路径,二是依据哪条规则选择的这条路径,三是在每跳的节点逗留了多长时间,四是有哪些其他的流在共享这条物理链路。INT充分利用了P4的可编程特性,在经过每一跳交换机之后,加上相应的元数据tag,这样在最后一跳将这些tag弹出送到后台即可分析出前面四个问题中所需要的信息。由此,就可以实现在线的报文级的可视化,这对于网络的诊断以及监控运维,是非常重要的,也使得网络的数据平面从此开始变得逐渐透明以及可侦测。
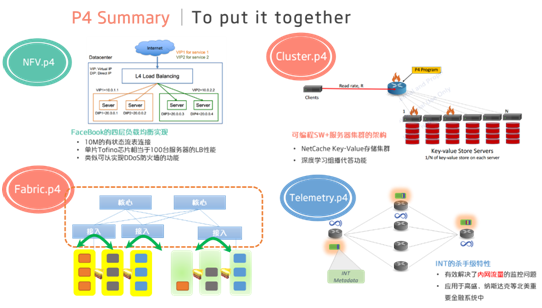
最后以4个抽象的P4文件来概括上述的应用场景。NFV.p4替代甚至优化传统网元的实现,例如负载均衡,DDoS防火墙,云网关,流发生器,TAP分流器等;Cluster.p4通过可编程交换机加速特定的分布式集群,例如NetCache加速分布式键值对存储,NetChain加速分布式协调,SwitchML加速机器学习等;Fabric.p4则是通过CLOS结构组建的数据中心大交换机,目标是利用切片以及内网负载均衡实现云原生的Fabric集群;Telemetry.p4主要面向数据平面的在线诊断以及可视化需求,使得超高速的数据平面依旧可观可测。
数据平面可编程的重要意义
可编程网络模型以及可编程交换芯片的出现,有着诸多的意义:
1、事关SDN软件定义网络的终极理想,P4把软件定义的边界下沉到了转发流水线的层次,从此网络全栈可以软件化定义。对于SDN来说,芯片可编程才是最彻底的SDN,它对于整个系统来说既是硬件,也是一个平台。
2、在体系架构上,随着领域型芯片的趋势一定,网络领域新芯片的接口竞争也在加剧。P4很早就进行了这方面的生态布局,影响力从学术界逐渐蔓延到工业界。对此,网络芯片领域的传统霸主博通也推出了类似的NPL网络编程语言。
3、从用户的角度,这是第一次可以对超高速ASIC数据平面的转发行为与流水线逻辑进行自行定制,我们可以期待未来网络领域将会有更多的创新可能。
学习了解更多P4可编程交换芯片的内容,未来网络学院和Barefoot共同打造的《Barefoot Academy – P4实战特训营》课程是你的不二选择。我们针对本土化市场特性组建了本土化讲师团队和针对性的培训课程,受到了业界的了广泛关注和良好口碑。欢迎大家报名参加Barefoot大学在2020年1月的《Barefoot Academy – P4实战特训营》,届时我们也会分享P4可编程技术在Intel的最新发展战略。
报名通道:https://edu.sdnlab.com/training/2122.html
报名咨询:微信/手机:17366207183;邮箱:[email protected]
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK