

苹果卷开源大模型,公开代码、权重、数据集、训练全过程,OpenELM亮相
source link: https://www.36kr.com/p/2747330104654600
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
苹果发布基于开源训练和推理框架的高效语言模型族 OpenELM。
要说 ChatGPT 拉开了大模型竞赛的序幕,那么 Meta 开源 Llama 系列模型则掀起了开源领域的热潮。在这当中,苹果似乎掀起的水花不是很大。
不过,苹果最新放出的论文,我们看到其在开源领域做出的贡献。
近日,苹果发布了 OpenELM,共四种变体(参数量分别为 270M、450M、1.1B 和 3B),这是一系列基于公开数据集进行预训练和微调的模型。OpenELM 的核心在于逐层缩放,即 OpenELM 中的每个 Transformer 层都有不同的配置(例如,头数和前馈网络维度),导致模型每层的参数数量不同,从而实现了更有效的跨层参数分配。
值得一提的是,苹果这次发布了完整的框架,包括数据准备、训练、微调和评估程序,以及多个预训练的 checkpoint 和训练日志,以促进开源研究。

- 论文地址:https://arxiv.org/pdf/2404.14619.pdf
- 项目地址:https://github.com/apple/corenet
- 论文标题:OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework
结果显示,OpenELM 的性能优于使用公开数据集进行预训练的现有开源 LLM(表 1)。例如,具有 11 亿个参数的 OpenELM 性能优于 OLMo。

方法介绍
OpenELM 架构
OpenELM 采用只有解码器的 transformer 架构,并遵循以下方式:
(1)不在任何全连接(也称为线性)层中使用可学习的偏差参数;
(2)使用 RMSNorm 进行预标准化,旋转位置嵌入(ROPE)用于编码位置信息;
(3)使用分组查询注意力(GQA)代替多头注意力(MHA);
(4)用 SwiGLU FFN 替换前馈网络(FFN);
(5) 使用 flash 注意力来计算可缩放的点积注意力;
(6) 使用与 LLama 相同的分词器(tokenizer)。
一般来讲,LLM 中每个 transformer 层使用相同的配置,从而实现跨层参数的统一分配。与这些模型不同的是,OpenELM 中的每个 Transformer 层都有不同的配置(例如,头数和前馈网络维度),导致模型每层的参数数量不同。这使得 OpenELM 能够更好地利用可用的参数预算来实现更高的精度。苹果使用逐层缩放(layer-wise scaling)来实现跨层参数的非均匀分配。
逐层缩放:标准 Transformer 层由多头注意力(MHA)和前馈网络(FFN)组成。针对 Transformer 层参数分配不均匀的问题,苹果对各个 Transformer 层的注意力头数和 FFN 乘法器进行了调整。
苹果是这样做的。设参数分配均匀的标准 Transformer 模型有 N 层 transformer,假设每层输入的维数为 d_model。MHA 有 n_h 个头,每个头的维度为
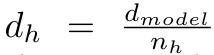
,FFN 的隐藏维度为:
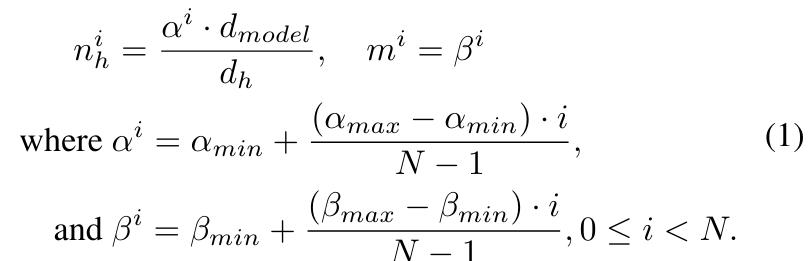
苹果引入参数 α 和 β 两个超参数来分别缩放每层注意力头的数量 n_h 和 m。对于第 i 层,n_h 和 m 计算为:
预训练数据
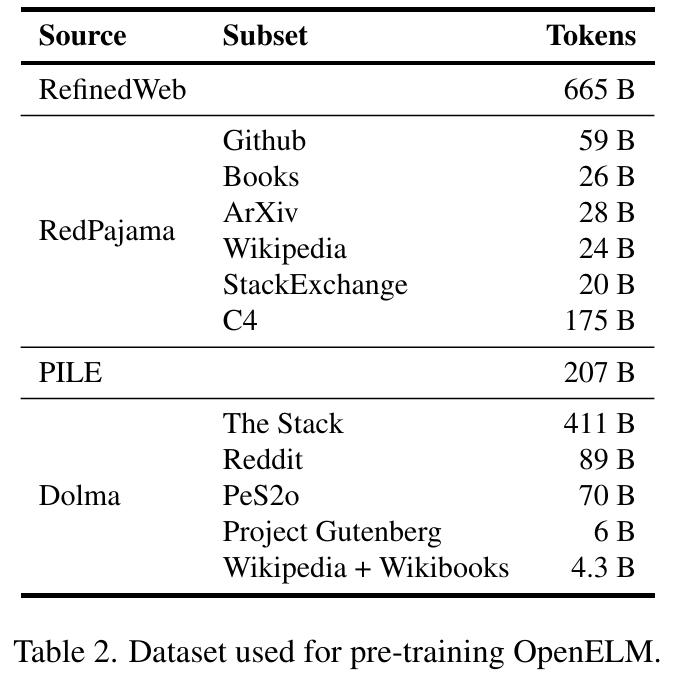
对于预训练,苹果使用公共数据集。具体来说,他们的预训练数据集包含 RefinedWeb、deduplicated PILE、RedPajama 的子集和 Dolma v1.6 的子集,总计约 1.8 万亿个 token 。如下表所示。
训练细节
苹果使用自家开源的 CoreNet 库(以前称为 CVNets ,专门用于训练深度神经网络)训练 OpenELM 变体,训练过程迭代了 35 万次。最终训练出了 OpenELM 四种变体(参数量为 270M、450M、1.1B 和 3B)。
实验
本文评估了 OpenELM 在零样本和少样本设置下的性能,如表 3 所示。研究者将 OpenELM 与公开的 LLM 进行了比较,其中包括 PyThia 、Cerebras-GPT 、TinyLlama 、OpenLM 、MobiLlama 和 OLMo 。与本文工作较为相关的是 MobiLlama 和 OLMo。这些模型都是在类似的数据集上训练的,具有相似或更多的预训练 token。

图 1 绘制了 OpenELM 在 7 个标准零样本任务上随训练迭代次数的准确率。可以发现,在大多数任务中,随着训练持续时间的延长,准确率在总体上会有所提高。此外,通过平均最后五个检查点(每 5000 次迭代收集一次)得到的检查点,在准确率上与经过 350k 次迭代后得到的最终检查点相当,或略有提高。这种改进很可能是由于权重平均降低了噪声。因此,在表 4 的主要评估、表 5 的指令调优实验和表 6 的参数效率调优实验中,研究者使用了平均检查点。
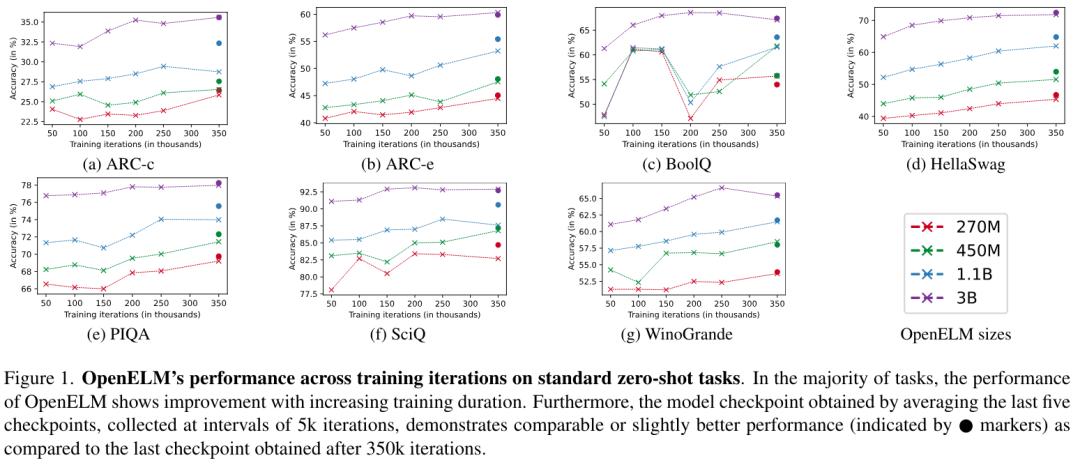
表 4 中的结果横跨各种评估框架,突出了 OpenELM 相对于现有方法的有效性。表 4 中的结果跨越了不同的评估框架,凸显了 OpenELM 相对于现有方法的有效性。例如,与拥有 12 亿个参数的 OLMo 相比,拥有 11 亿个参数的 OpenELM 变体的准确率分别提高了 1.28%(表 4a)、2.36%(表 4b)和 1.72%(表 4c)。值得注意的是,OpenELM 达成了这样的准确率,但是使用的预训练数据比 OLMo 少的多。
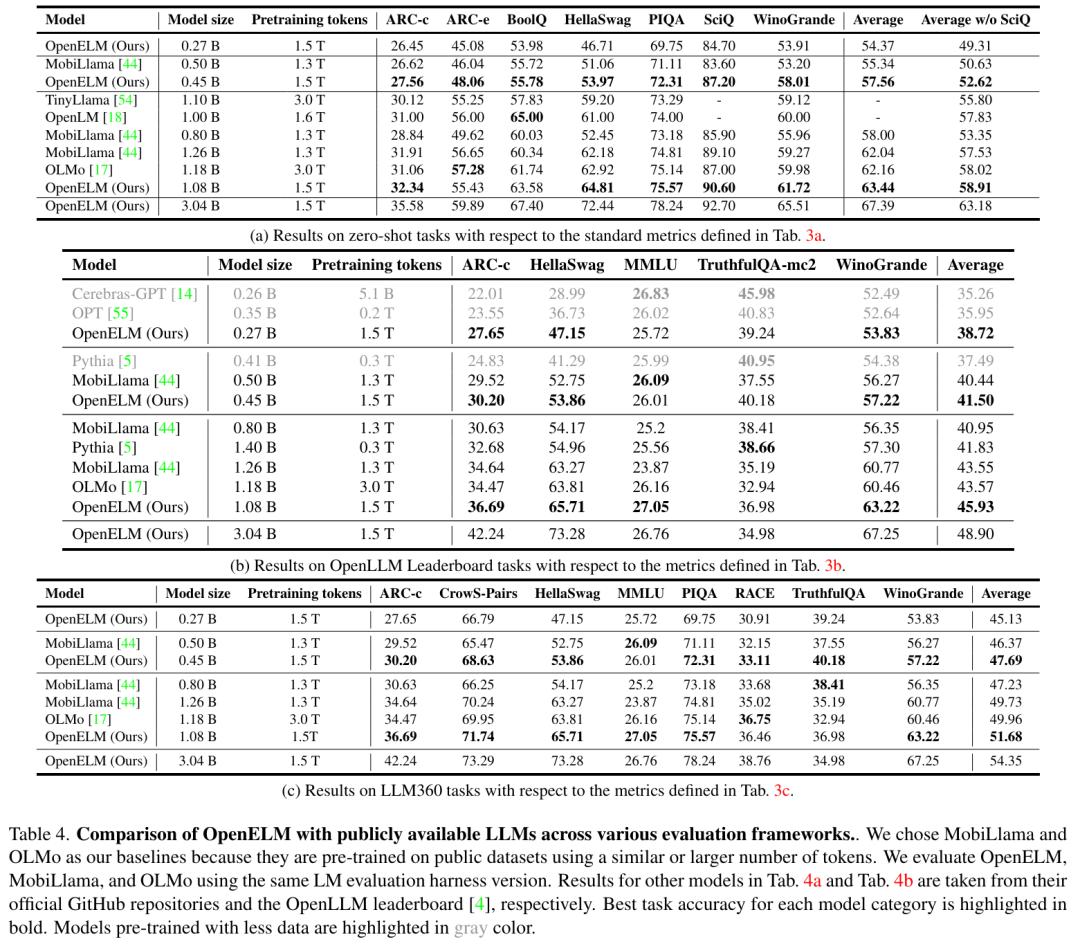
如图 5 所示,在不同的评估框架中,指令微调始终能将 OpenELM 的平均准确率提高 1-2%。
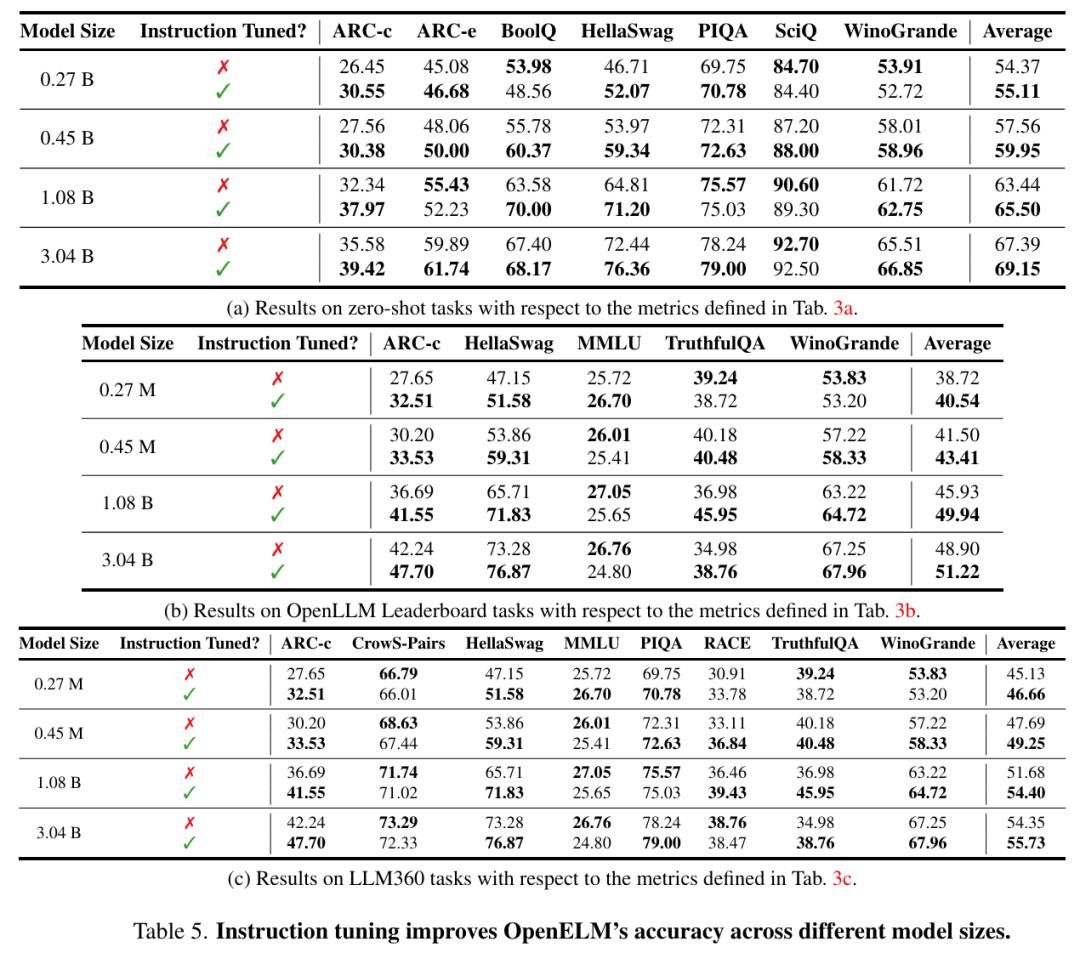
参数高效微调(PEFT)结果。研究者使用常识推理的训练和评估设置。这个设置为不同方法提供了 8 个多项选择数据集的 170k 训练样本进行 PEFT 研究,包括 LoRA 和 DoRA。研究者将 OpenELM 与这些方法整合在一起,并使用 8 个 NVIDIA H100 GPU 对所生成的模型进行了三个训练周期的微调。如表 6 所示,PEFT 方法可以应用于 OpenELM。在给定的 CommonSense 推理数据集上,LoRA 和 DoRA 的平均准确率相似。
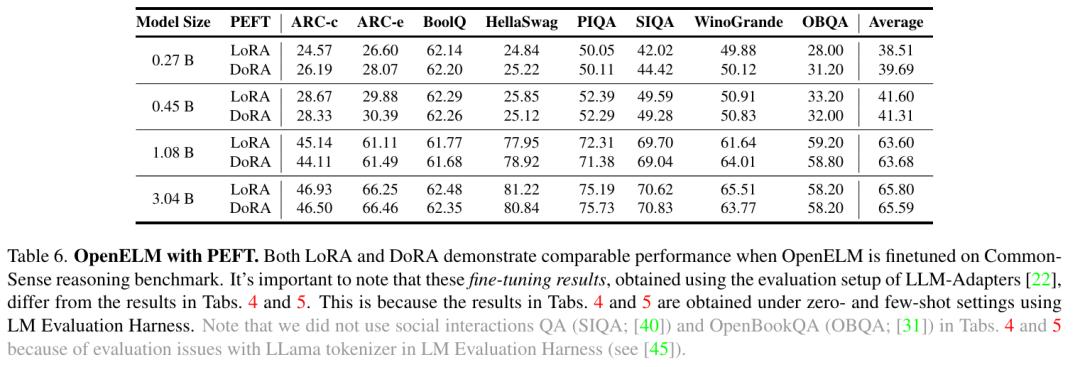
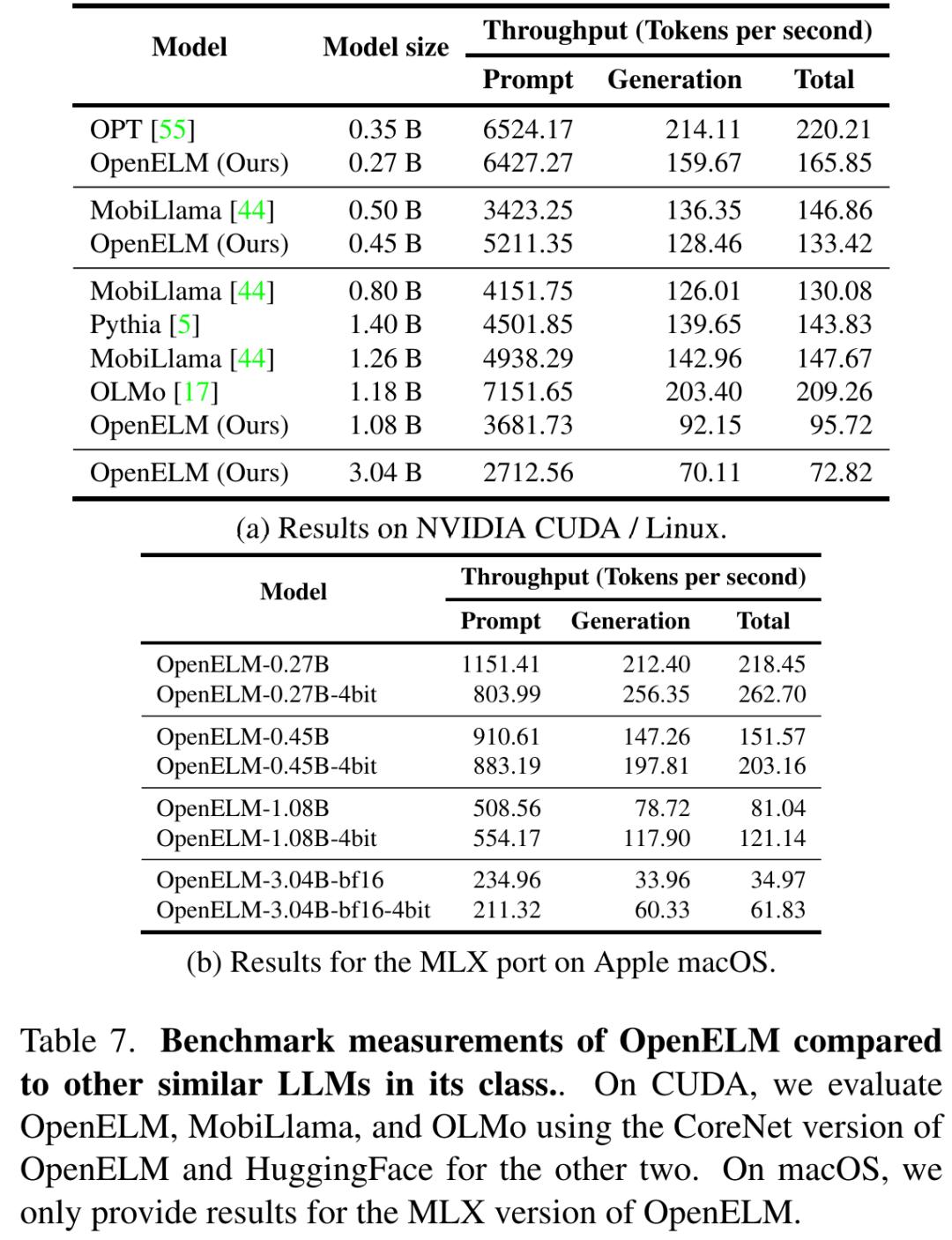
表 7a 和 7b 分别展示了本项工作在 GPU 和 MacBook Pro 上的基准测试结果。尽管 OpenELM 在相似参数数量下准确度更高,但其速度比 OLMo 慢。虽然这项研究的主要关注点是可复现性而不是推理性能,但研究者还是进行了全面的性能分析来判断工作的瓶颈所在。
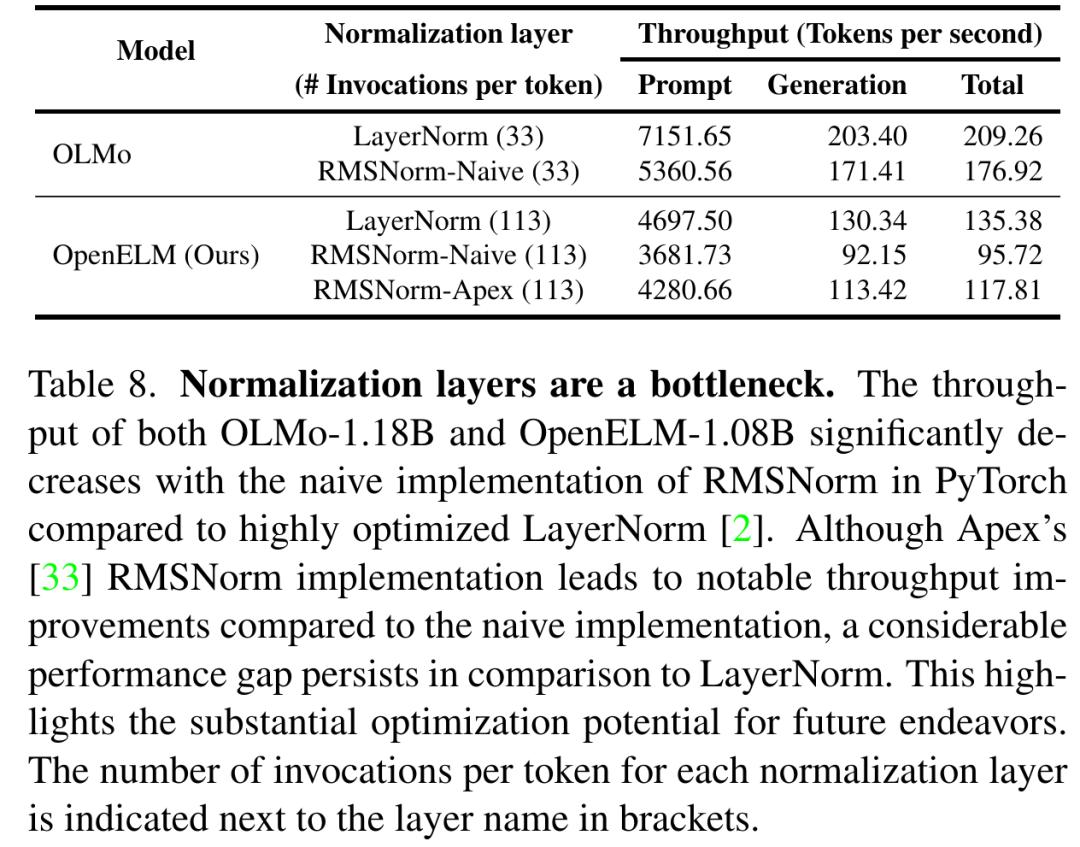
分析表明,OpenELM 的处理时间的相当部分可归因于研究者对 RMSNorm 的简单实现(见表 8)。详细来说,也就是简单的 RMSNorm 实现导致许多单独的内核启动,每个都处理少量输入,而不是像 LayerNorm 那样启动单个融合内核。通过用 Apex 的 RMSNorm 替换简单的 RMSNorm,研究者发现 OpenELM 的吞吐量显著提高。然而,与使用优化 LayerNorm 的模型相比,仍有显著的性能差距,部分原因是(1)OpenELM 有 113 层 RMSNorm,而 OLMo 有 33 层 LayerNorm;(2)Apex 的 RMSNorm 没有为小输入优化。为了进一步说明由 RMSNorm 引起的性能下降,苹果用 RMSNorm 替换了 OLMo 中的 LayerNorm,观察到生成吞吐量显著下降。在未来的工作中,研究者计划探索优化策略以进一步提高 OpenELM 的推理效率。
更多详细内容,请阅读原论文。
本文来自微信公众号“机器之心”(ID:almosthuman2014),编辑:陈萍、大盘鸡,36氪经授权发布。
该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK