

扩散+超分辨率模型强强联合,谷歌图像生成器Imagen背后的技术
source link: https://www.51cto.com/article/713837.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
扩散+超分辨率模型强强联合,谷歌图像生成器Imagen背后的技术-51CTO.COM
近年来,多模态学习受到重视,特别是文本 - 图像合成和图像 - 文本对比学习两个方向。一些 AI 模型因在创意图像生成、编辑方面的应用引起了公众的广泛关注,例如 OpenAI 先后推出的文本图像模型 DALL・E 和 DALL-E 2,以及英伟达的 GauGAN 和 GauGAN2。
谷歌也不甘落后,在 5 月底发布了自己的文本到图像模型 Imagen,看起来进一步拓展了字幕条件(caption-conditional)图像生成的边界。

仅仅给出一个场景的描述,Imagen 就能生成高质量、高分辨率的图像,无论这种场景在现实世界中是否合乎逻辑。下图为 Imagen 文本生成图像的几个示例,在图像下方显示出了相应的字幕。

这些令人印象深刻的生成图像不禁让人想了解:Imagen 到底是如何工作的呢?
近期,开发者讲师 Ryan O'Connor 在 AssemblyAI 博客撰写了一篇长文《How Imagen Actually Works》,详细解读了 Imagen 的工作原理,对 Imagen 进行了概览介绍,分析并理解其高级组件以及它们之间的关联。
Imagen 工作原理概览
在这部分,作者展示了 Imagen 的整体架构,并对其它的工作原理做了高级解读;然后依次更透彻地剖析了 Imagen 的每个组件。如下动图为 Imagen 的工作流程。
首先,将字幕输入到文本编码器。该编码器将文本字幕转换成数值表示,后者将语义信息封装在文本中。Imagen 中的文本编码器是一个 Transformer 编码器,其确保文本编码能够理解字幕中的单词如何彼此关联,这里使用自注意力方法。
如果 Imagen 只关注单个单词而不是它们之间的关联,虽然可以获得能够捕获字幕各个元素的高质量图像,但描述这些图像时无法以恰当的方式反映字幕语义。如下图示例所示,如果不考虑单词之间的关联,就会产生截然不同的生成效果。

虽然文本编码器为 Imagen 的字幕输入生成了有用的表示,但仍需要设计一种方法生成使用这一表示的图像,也即图像生成器。为此,Imagen 使用了扩散模型,它是一种生成模型,近年来得益于其在多项任务上的 SOTA 性能而广受欢迎。
扩散模型通过添加噪声来破坏训练数据以实现训练,然后通过反转这个噪声过程来学习恢复数据。给定输入图像,扩散模型将在一系列时间步中迭代地利用高斯噪声破坏图像,最终留下高斯噪声或电视噪音静态(TV static)。下图为扩散模型的迭代噪声过程:

然后,扩散模型将向后 work,学习如何在每个时间步上隔离和消除噪声,抵消刚刚发生的破坏过程。训练完成后,模型可以一分为二。这样可以从随机采样高斯噪声开始,使用扩散模型逐渐去噪以生成图像,具体如下图所示:

总之,经过训练的扩散模型从高斯噪声开始,然后迭代地生成与训练图像类似的图像。很明显的是,无法控制图像的实际输出,仅仅是将高斯噪声输入到模型中,并且它会输出一张看起来属于训练数据集的随机图像。
但是,目标是创建能够将输入到 Imagen 的字幕的语义信息封装起来的图像,因此需要一种将字幕合并到扩散过程中的方法。如何做到这一点呢?
上文提到文本编码器产生了有代表性的字幕编码,这种编码实际上是向量序列。为了将这一编码信息注入到扩散模型中,这些向量被聚合在一起,并在它们的基础上调整扩散模型。通过调整这一向量,扩散模型学习如何调整其去噪过程以生成与字幕匹配良好的图像。过程可视化图如下所示:
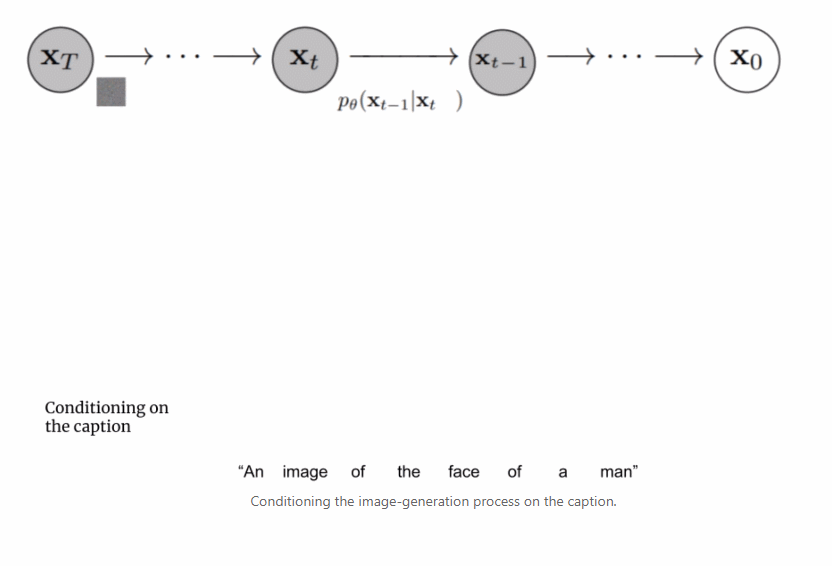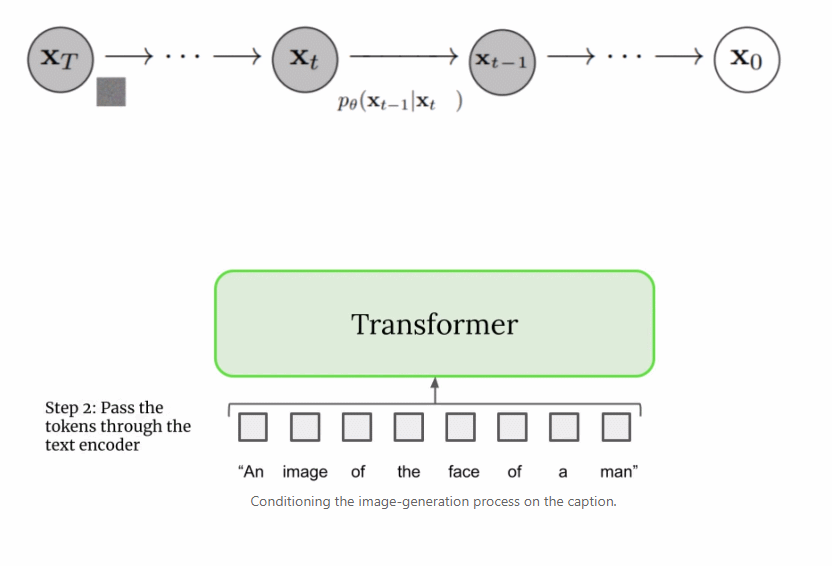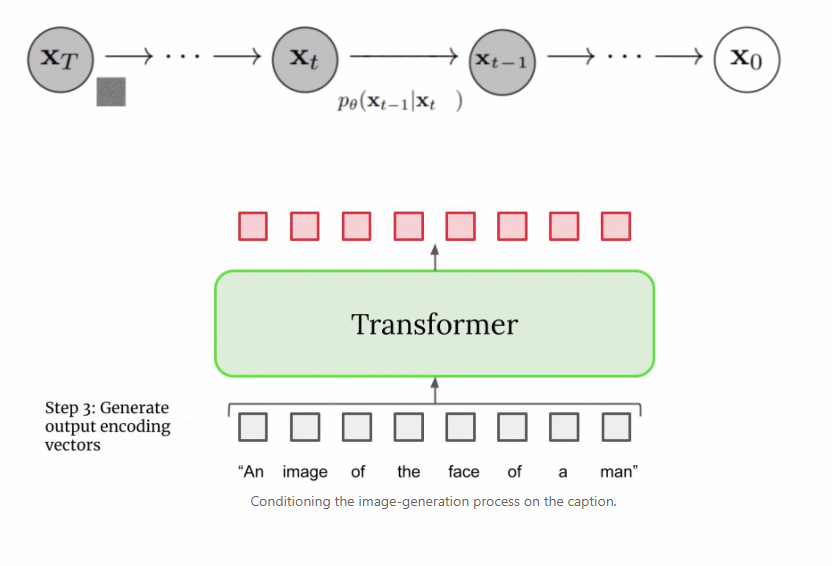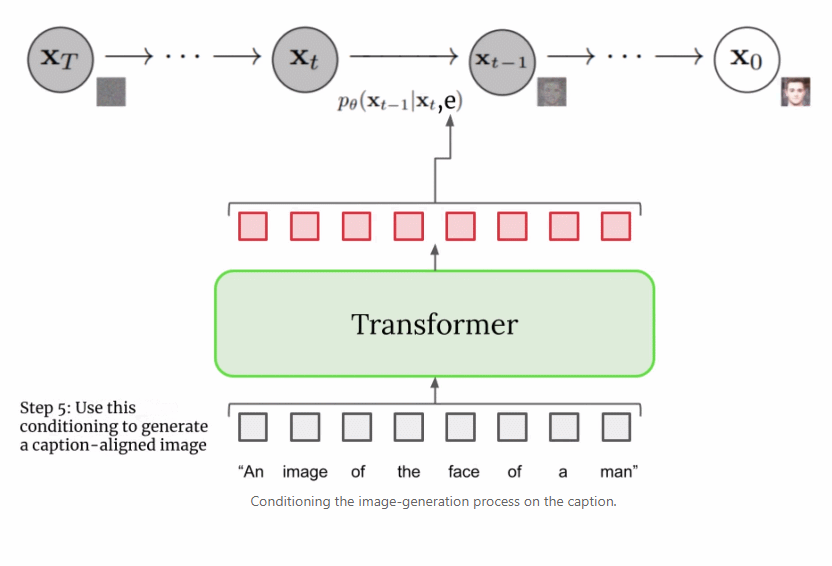
由于图像生成器或基础模型输出一个小的 64x64 图像,为了将这一模型上采样到最终的 1024x1024 版本,使用超分辨率模型智能地对图像进行上采样。
对于超分辨率模型,Imagen 再次使用了扩散模型。整体流程与基础模型基本相同,除了仅仅基于字幕编码调整外,还以正在上采样的更小图像来调整。整个过程的可视化图如下所示:
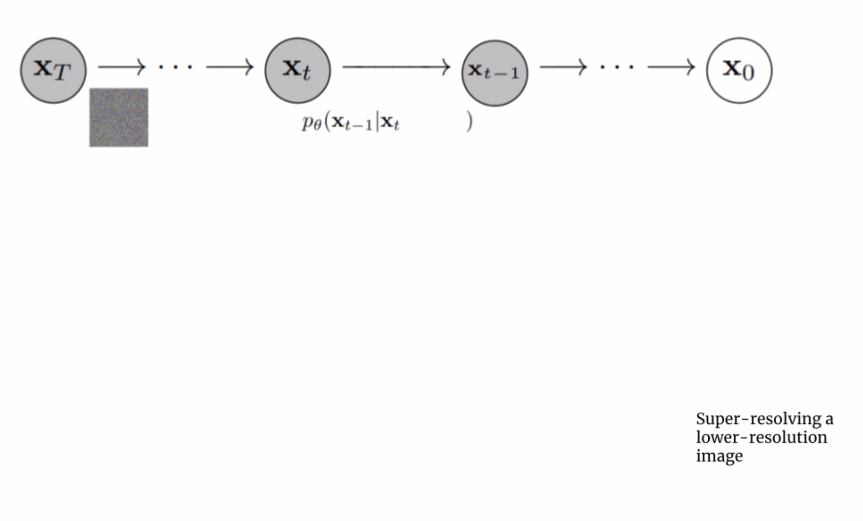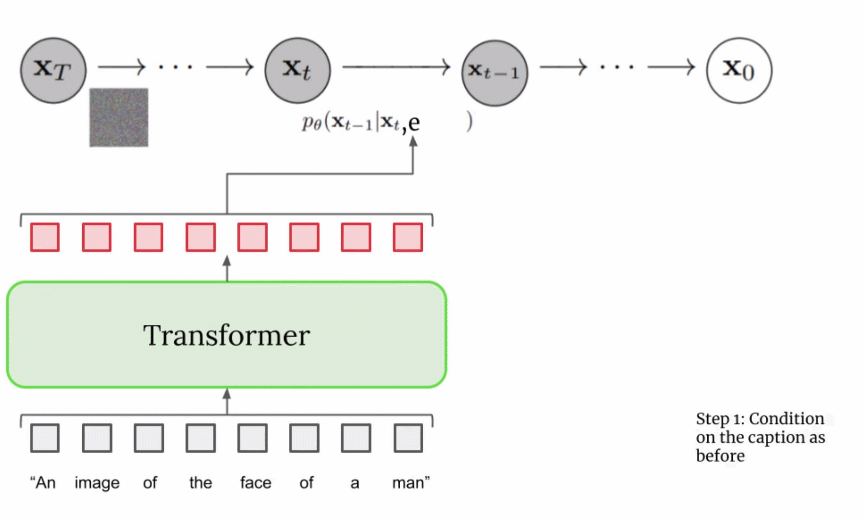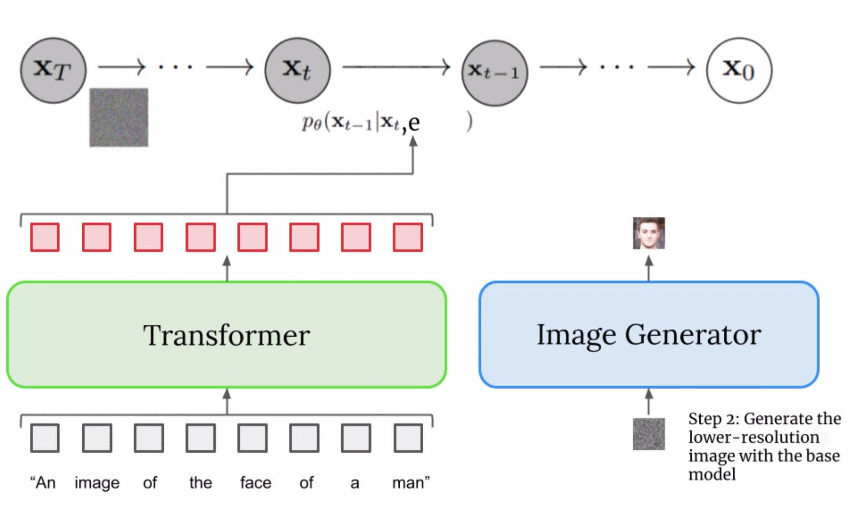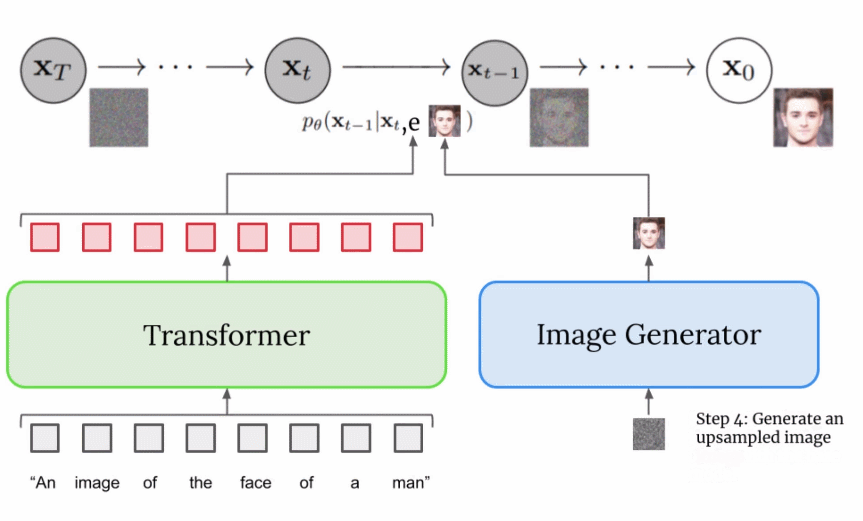
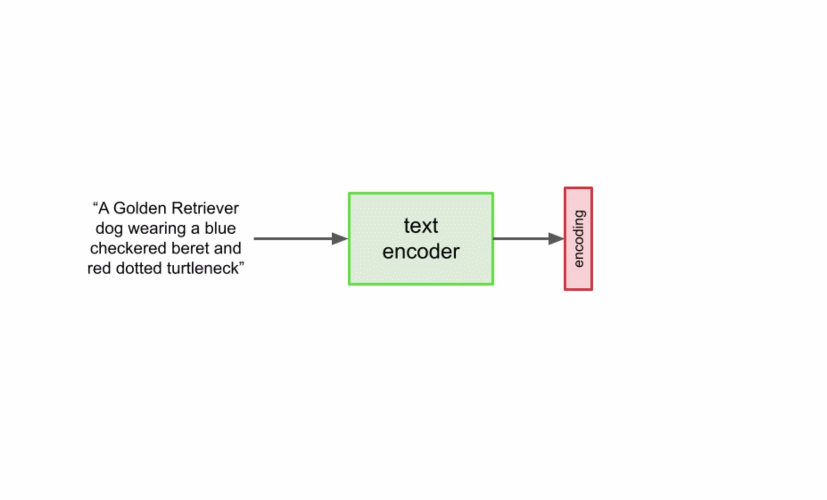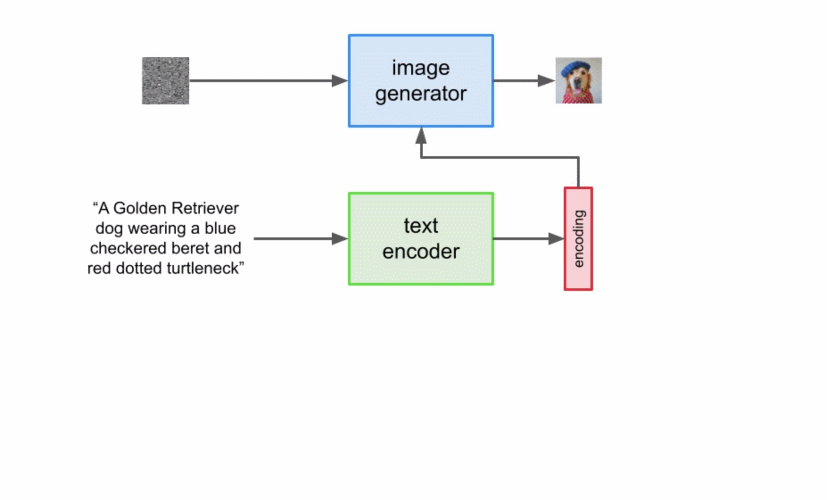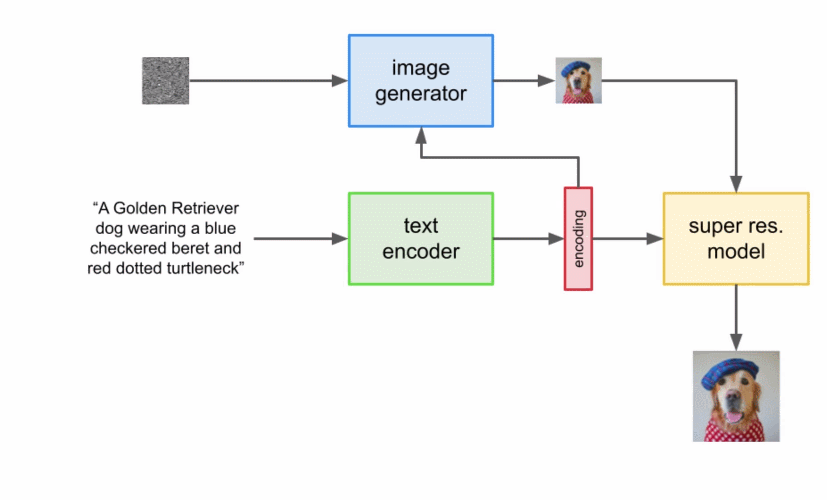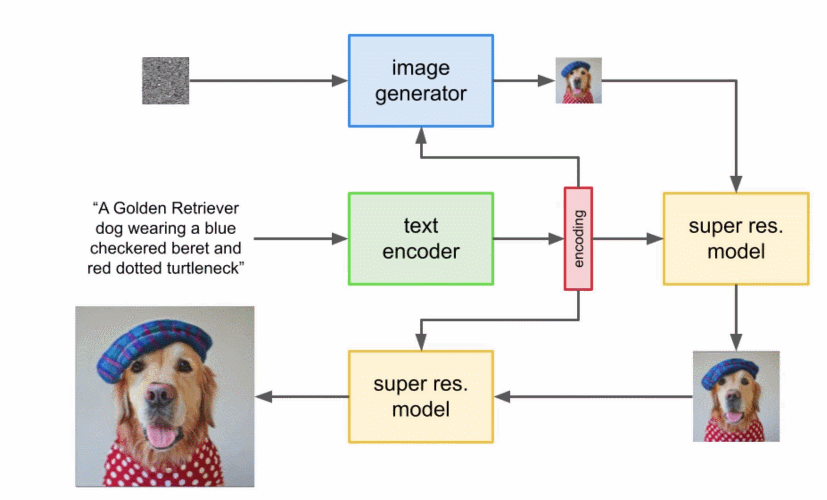
这个超分辨率模型的输出实际上并不是最终输出,而是一个中等大小的图像。为了将该图像放大到最终的 1024x1024 分辨率,又使用了另一个超分辨率模型。两个超分辨率架构大致相同,因此不再赘述。而第二个超分辨率模型的输出才是 Imagen 的最终输出。
为什么 Imagen 比 DALL-E 2 更好?
确切地回答为什么 Imagen 比 DALL-E 2 更好是困难的。然而,性能差距中不可忽视的一部分源于字幕以及提示差异。DALL-E 2 使用对比目标来确定文本编码与图像(本质上是 CLIP)的相关程度。文本和图像编码器调整它们的参数,使得相似的字幕 - 图像对的余弦相似度最大化,而不同的字幕 - 图像对的余弦相似度最小化。
性能差距的一个显著部分源于 Imagen 的文本编码器比 DALL-E 2 的文本编码器大得多,并且接受了更多数据的训练。作为这一假设的证据,我们可以在文本编码器扩展时检查 Imagen 的性能。下面为 Imagen 性能的帕累托曲线:
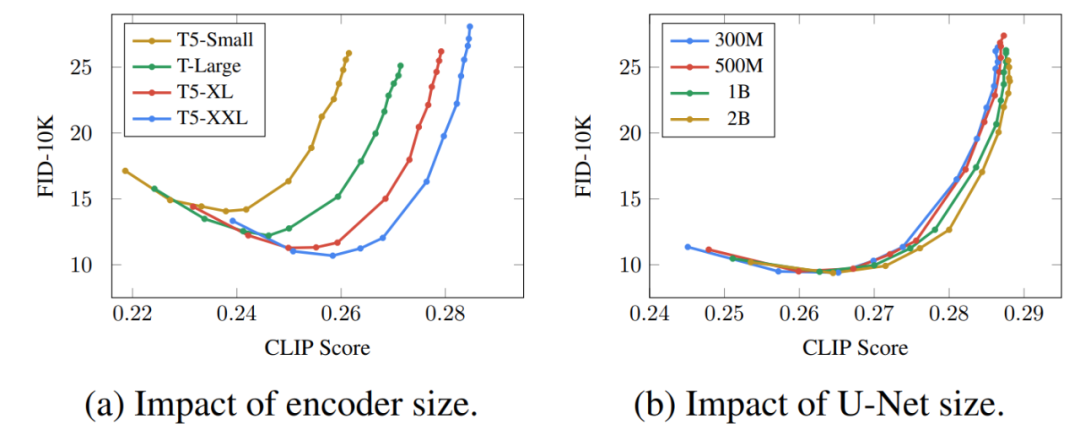
放大文本编码器的效果高得惊人,而放大 U-Net 的效果却低得惊人。这一结果表明,相对简单的扩散模型只要以强大的编码为条件,就可以产生高质量的结果。
鉴于 T5 文本编码器比 CLIP 文本编码器大得多,再加上自然语言训练数据必然比图像 - 字幕对更丰富这一事实,大部分性能差距可能归因于这种差异。
除此以外,作者还列出了 Imagen 的几个关键要点,包括以下内容:
- 扩展文本编码器是非常有效的;
- 扩展文本编码器比扩展 U-Net 大小更重要;
- 动态阈值至关重要;
- 噪声条件增强在超分辨率模型中至关重要;
- 将交叉注意用于文本条件反射至关重要;
- 高效的 U-Net 至关重要。
这些见解为正在研究扩散模型的研究人员提供了有价值的方向,而不是只在文本到图像的子领域有用。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK