

二次元的胜利!漫画家才是永远不会被AI替代的铁饭碗?
source link: http://36kr.com/p/5104341.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
二次元的胜利!漫画家才是永远不会被AI替代的铁饭碗?-36氪
编者按:本文来自微信公众号脑极体(unity007),36氪经授权发布。
作为一个AI垂直自媒体的作者,我工作中的很大一部分就是替AI“带路”,然后告诉人类读者们,你们的这项和那项工作都要被AI替代了。
一直以来,人类似乎都站在一个毫无还手之力的弱势地位,或许未来真的像一些悲观者想象中那样,我们有AI司机、AI售货员、AI诗人,但人类自己却成了可怜的乞讨者。
直到今天,我第一次发现有一项工作AI在一段时间以内都无法超越人类,而这次胜利属于二次元——不会被AI代替的工作,是漫画家。
连漫画都看不懂,谈什么毁灭世界?
漫画家不会AI代替的原因很简单,因为马里兰大学的一位教授进行了一项研究,最终发现AI根本看不懂漫画。

以上是一则非常简单的四格漫画,对于人类来说理解起来非常容易:小猫在思考创作素材,然后发现了小狗,要求小狗讲个笑话,小狗说“你很漂亮”导致小猫非常愤怒。
实际上,在最后一个画面中,小狗没有入镜,而“你很漂亮”本来是表扬,要和上一个画面中的“笑话”连接起来,才能解释出小猫的情绪。
对于AI来说,理解这些呈现在画面之外的信息,简直太困难了。
在马里兰大学的实验中,研究者搭建了一个由120万张漫画画格组成的数据集,并提取出了每个画格中的文本,利用LSTM模型,希望AI能对漫画进行一个连贯的了解。
关于LSTM(长短期记忆网络)此前已经介绍过很多,这一模型的特点就是加入了记忆的概念,可以处理和预测时间序列较长元素。虽然在长文本、机器翻译等等方面表现的都不错,但在看漫画这件事上,LSTM彻底挫败了。
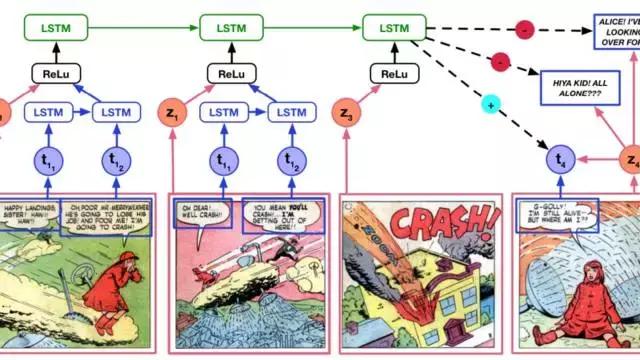
在经过大量训练后,研究人员给了AI一组以前没见过的漫画,要求AI理解并预测下一个画面中的文字信息或画面内容,结果AI的成绩一塌糊涂。而人类的预测正确程度,通常能达到80%的正确率。
视觉叙事?何必强人工智能所难
严格来说,漫画这种东西属于“视觉叙事”——把信息隐藏于图像之中。同样是视觉叙事,AI理解电影就比理解漫画容易的多,电影的主角是人,而人脸长的都是一个样子,想要训练AI读出人脸表情、识别情绪是件很简单的事,更何况电影还会有详细的剧本。
但漫画最大的特点,就是视觉上不具有连贯性。就像上文的四格漫画一样,第三张图小狗还在画面中,第四张图就不在了。人类可以很快的理解到,名为淡定狗的小狗扔下一句话就淡定的离开。可对于AI来说,读出这种在画面和文字之外的信息实在是强人工智能所难。

其次,不同漫画的绘画、叙事风格迥异,对于AI的训练来说也是个难点。简单的四格漫画中,每一格的场景都是相同的,可在其他漫画中,可能这一格是打斗的场景,下一格就是一张愤怒的人脸。能看懂四格漫画AI,再去看那种有镜头切换感的漫画,也是一头雾水。至于画风方面,不同漫画家对于人脸描绘方式都有很大差异,换成AI来理解,难度又会加大了。
还有一点,视觉叙事这件事是建立在“逻辑”和“常识”两个概念基础之上的。比如小猫说讲个笑话,小狗说“你好漂亮”,理解这个情节就需要“你说我漂亮是笑话=你说我丑”这一基础的逻辑。又比如哆啦A梦中常见的老鼠梗也需要“猫通常不怕老鼠”这一基础常识。这些东西对于人类来说都很简单,可是AI是不具备这些常识和逻辑概念的,我们也不能像编百科全书那样,把这些概念灌输到AI的大脑之中。
围棋界的大手,到了甄嬛传里也是一集死
其实结合AI在围棋领域的胜利和在漫画上的失败,我们可以看出,AI在完全信息信息领域中的表现和不完全信息领域中的表现完全不同。
完全信息本来是经济学中的一个属于,意思是参与者可以理解整个市场的所有信息。在这里,我们可以看做一项工作的数据集。在围棋这项工作中,所有的信息都可以归纳为数据集:游戏的规则、每一步的打法。可在漫画中,我们最多能把画面中做上详细的标注,把文本信息都提取出来。可隐藏在图片文字之外的逻辑关系、常识等等只可意会不可言传的东西,是无法向AI提供的。
而AI做的最差的,就是read between the lines。
以此类推,AI在戏剧、歇后语、四国军棋的暗棋(一种包含了欺骗的军旗玩法)包括谈恋爱等等一切充满了不完全信息、欺骗与反欺骗、解读意象、常识和逻辑的游戏中表现都不会太好。
这么看来,AI有点像《三体》里初期的智子,不会隐藏自己的想法,也不能明白隐瞒、欺骗这种概念。所以,我们真的不必对AI的胜利感到恐惧,它会是办公室里人缘最差的那位同事和后宫里一集死的路人,某一项能力的突出并不能弥补它在不完全信息方面的短板。更何况意象、类比、反讽、隐喻这种东西,是人类最擅长的手段。

我相信,未来世界最好的样子一定是人类和AI各司其职,做各自最擅长的事情。在视觉叙事这类AI特别不擅长的事情上,它们依然能给人类提供很多帮助。
比如用生成对抗神经网络创造人物形象、用监督学习+卷积网络来为线稿上色、甚至开发一款会自动放大文字的漫画阅读App。这些并不是幻想,而是正在发生的现实。当这些繁复的机械劳动被AI代劳后,我们也就能更多的投入到自己擅长的事情中来:利用不完全信息环境讲好更多故事,让这个世界保持应有的趣味。
该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK