

Guava Cache 在广告系统中的优化 – 上善若水,人淡如菊
source link: http://www.panaihua.com/guava-cache/?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
我们现在做的事情简单的说就是对流量、用户行为、特征等多维度分析,从而给用户推荐最精准的广告。这个过程就是我们现在做的事情也是我们广告组最核心的任务。本文主要从 Guava Cache 知识点的角度讲述它在我们系统中的优化过程,并不会嗸述太多知识点。
面临的问题
我们将广告的信息存放在 Redis,在线上跑了一段时间并没有问题。就在一天 Redis 出现超时的告警,而且频率越来越高。我们开始对流量进行分析,发现是业务快速增长已达到 Redis 的极限。所以燃眉之急的任务就是减少 Redis 的压力。
缓存,在我们日常开发中是必不可少的一种解决性能问题的方法。
其主要作用是暂时在内存中保存业务系统的数据处理结果,并且等待下次访问使用。在日常开发的很多场合,由于受限于硬盘IO的性能或者我们自身业务系统的数据处理和获取可能非常费时,当我们发现我们的系统这个数据请求量很大的时候,频繁的IO和频繁的逻辑处理会导致硬盘和CPU资源的瓶颈出现。缓存的作用就是将这些来自不易的数据保存在内存中,当有其他线程或者客户端需要查询相同的数据资源时,直接从缓存的内存块中返回数据,这样不但可以提高系统的响应时间,同时也可以节省对这些数据的处理流程的资源消耗,整体上来说,系统性能会有大大的提升。
为什么要使用Guava Cache
缓存的解决方案有很多种,第一个想到的肯定是第三方缓存服务器。刚开始我们使用的是 Memcache ,但是它只支持简单的key-value存储,并不能满足我们现有的场景所以改成了 Redis 。但是 Redis 是单线程的,如果请求数很多,会出现瓶颈导致线程阻塞,也就是我们现在面临的问题。这个时候就需要引入本地缓存了。
Guava Cache 说简单点就是一个支持LRU的ConCurrentHashMap,它没有 Ehcache 那么多的各种特性,只是提供了增、删、改、查、刷新规则和时效规则设定等最基本的元素,并提供了线程安全的实现机制。做一个 jar 包中的一个功能之一,Guava Cache 的极度简洁无非是不二之选,简单易用,性能好。
对于我个人而言,Guava 的开发活跃度和良好的质量保证是我更愿意转而使用 Guava 的的原因之一。Guava 几年发展下来各界发表的各类文章和其自身良好的文档风格也极大的帮助了该库的传播使用。
为了快速适应从 redis 迁移到 Guava Cache,以及业务优先的原则,简单的使用了它的 API ,大致如下:
LoadingCache<Long, AdvertVO> advertCache = CacheBuilder.newBuilder().concurrencyLevel(200).expireAfterWrite(60,
TimeUnit.SECONDS).initialCapacity(500).maximumSize(1000).recordStats().build(new CacheLoader<Long, AdvertVO>() {
@Override
public AdvertVO load(Long advertId)
throws Exception {
return getAdvertByCache(advertId);
}
});
ASPECTJ上面的代码使用了两种方式清除数据。
maximumSize从字面意思看是按照缓存的大小来移除,如果到达指定的条目数,就会把不常用的键值对从cache中移除。但是要注意的是并不是完全到了指定的size系统才开始移除不常用的数据,而是接近这个size的时候系统就会开始做移除的动作。expireAfterWrite根据某个键值对被创建或值被替换后多少时间移除,即当缓存项在指定的时间段内没有更新就会被回收。需要注意的是它在回源的load方法上加了控制,对于同一个key,只会让一个请求回源load,其他线程阻塞等待结果。这样会很好地防止缓存失效的瞬间大量请求穿透到后端引起雪崩效应,它的请求回源过程如下: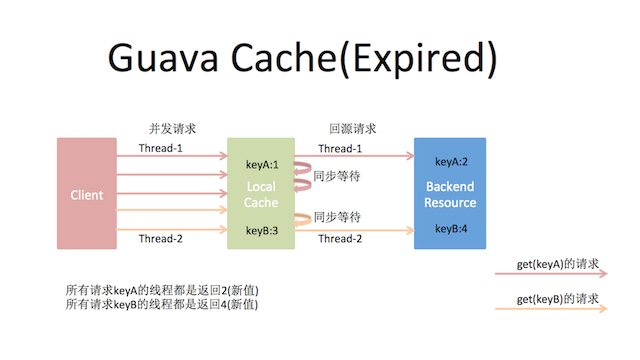
这里提一下
expireAfterAccess的清除方式,之前活动中心的团队有人使用它出现了问题。场景是这样的:
db中没有数据时接口调用缓存数据;在新增db记录后,接口返回的数据一直是错误数据。造成这个问题怀疑是代码笔误,因为后来我们对所有系统进行排查都没有发现用它的地方。那么什么场景使用它才合适呢?expireAfterAccess:当缓存项在指定的时间段内没有被访问就会被回收。反过来说就是如果在设置的超时时间内不断访问这个缓存,就永远不会执行load操作,所以在访问频次很低的时候或者有手动触发更新操作的场景才可以使用。
就这样广告的redis缓存安全地迁移到了Guava Cache,虽然看似很简单,但是我们在背后还做了很多其它的事情,比如保证数据的一致性。
第二次优化
刚才说的对于同一个key,只让一个请求回源,所以频繁的过期和加载,锁等待等过程会让性能有较大的损耗。而且其他线程都在等待状态,虽然对后端服务不会造成压力,但请求blocked了,整个请求还是会被堵一下。用户抽券的时候,从点击到展示的时间是3秒,如果超过这个时间,将会流失流量,最终导致的就是损失。因此我们考虑使用refreshAfterWrite。
LoadingCache<Long, Long> ADVERT_GROUP_CACHE = CacheBuilder.newBuilder().initialCapacity(1000).
recordStats().refreshAfterWrite(15, TimeUnit.MINUTES).build(new CacheLoader<Long, Long>() {
@Override
public Long load(Long advertId) throws Exception {
GroupMemberDO groupMemberDO = getgroupByAdvertid(advertId);
return groupMemberDO == null || groupMemberDO.getGroupId() == null ? 0L : groupMemberDO.getGroupId();
}
@Override
public ListenableFuture<Long> reload(final Long key, Long oldValue) throws Exception {
ListenableFutureTask<Long> task = ListenableFutureTask.create(new Callable<Long>() {
public Long call() throws Exception {
return load(key);
}
});
executorService.submit(task);
return task;
}
});
GRADLErefreshAfterWrite的特点是,刷新时仍只有一个线程回源取数据,但其他线程只会稍微等一会,没等到就返回旧值,整个请求看起来就比较平滑了。这样就有效地可以减少等待和锁争用,所以它会比expireAfterWrite性能好。它的回源过程如下图:
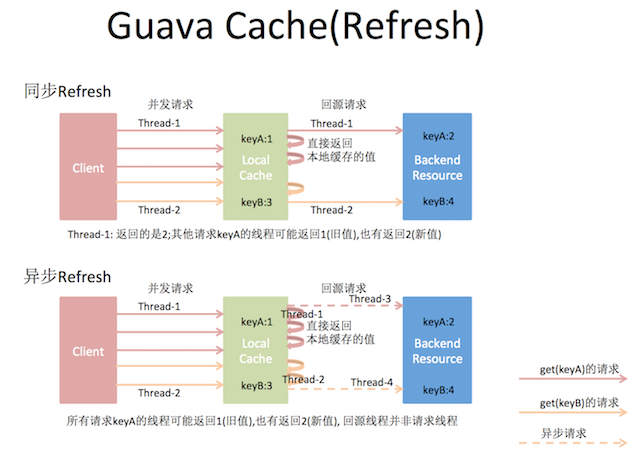
第三次优化
上面代码的也有一个缺点,因为到达指定时间后,它不能严格保证所有的查询都获取到新值。了解过guava cache的定时失效(或刷新)的同学都知道,Guava Cache 并没使用额外的线程去做定时清理和加载的功能,而是依赖于查询请求。在查询的时候去比对上次更新的时间,如超过指定时间则进行回源。所以,如果使用refreshAfterWrite,在吞吐量很低的情况下,如很长一段时间内没有查询之后,发生的查询有可能会得到一个旧值(这个旧值可能来自于很长时间之前),这将会引发问题。是否有一个折中的办法在第二次优化的基础之上增加超时刷新呢?
源码分析Guava Cache的get方法:
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
if (count != 0) { // read-volatile
// don't call getLiveEntry, which would ignore loading values
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e != null) {
long now = map.ticker.read();
V value = getLiveValue(e, now);
if (value != null) {
recordRead(e, now);
statsCounter.recordHits(1);
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference<K, V> valueReference = e.getValueReference();
if (valueReference.isLoading()) {
return waitForLoadingValue(e, key, valueReference);
}
}
}
// at this point e is either null or expired;
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error) cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
}
throw ee;
} finally {
postReadCleanup();
}
}
REASONML如果不存在缓存e值的时候会直接执行load方法,如果存在会继续判断value是否过期,如果过期了,会执行load方法而非reload方法,如果没有过期,会继续判断是否执行reload方法。
从代码来看,在get的时候,是先判断过期,再判断refresh,所以我们可以通过设置refreshAfterWrite为1s,将expireAfterWrite设为2s,当访问频繁的时候,会在每秒都进行refresh,而当超过2s没有访问,下一次访问必须load新值。
expireAfterWrite(30, TimeUnit.MINUTES)
STYLUS所以最终的代码在第二部的基础上又增加了超时的设置,保证了在过去很久之后也不会读取到旧值了。
我们现在做的事情都是围绕如何提高广告的ROI展开的,随着业务的不断增长,技术覆盖面也越来越广。这就对我们技术的要求更高,不能只实现需求就完事了,还要不断的琢磨技术,真正的掌握技术,让技术在系统中发挥出最大的作用,从而保证系统稳定以及为业务发展奠下扎实的基础。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK