

GitHub - qq547276542/Agriculture_KnowledgeGraph: 农业知识图谱(KG):农业领域的信...
source link: https://github.com/qq547276542/Agriculture_KnowledgeGraph
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
README.md
Agriculture_KnowledgeGraph
demo:http://p2052x6533.iok.la:44910
目录结构:
.
├── MyCrawler // scrapy爬虫项目路径(已爬好)
│ └── MyCrawler
│ ├── data
│ └── spiders
├── data\ processing // 数据清洗(已无用)
│ └── data
├── demo // django项目路径
│ ├── Model // 模型层,用于封装Item类,以及neo4j和csv的读取
│ ├── demo // 用于写页面的逻辑(View)
│ ├── label_data // 标注训练集页面的保存路径
│ │ └── handwork
│ ├── static // 静态资源
│ │ ├── css
│ │ ├── js
│ │ └── open-iconic
│ ├── templates // html页面
│ └── toolkit // 工具库,包括预加载,命名实体识别
│ └── KNN_predict
├── KNN_predict // KNN算法预测标签
├── dfs_tree_crawler // 爬取互动百科农业实体树形结构的爬虫
└── wikidataSpider // 爬取wiki中的关系
可复用资源
- hudong_pedia.csv : 已经爬好的农业实体的百科页面的结构化csv文件
- labels.txt: 5000多个手工标注的实体类别
- predict_labels.txt: KNN算法预测的13W多个实体的类别
项目配置
系统需要安装:
- scrapy ---爬虫框架
- django ---web框架
- neo4j ---图数据库
- thulac ---分词、词性标注
- py2neo ---python连接neo4j的工具
- pyfasttext ---facebook开源的词向量计算框架
- pinyin ---获取中文首字母小工具
- 预训练好的词向量模型wiki.zh.bin(仅部署网站的话不需要下载) ---下载链接:http://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.zh.zip
(以上部分除了neo4j在官网下,wiki.zh.bin在亚马逊s3下载,其它均可直接用pip3 install 安装)
项目部署:
- 将hudong_pedia.csv导入neo4j:开启neo4j,进入neo4j控制台。将hudong_pedia.csv放入neo4j安装目录下的/import目录。在控制台依次输入:
// 将hudong_pedia.csv 导入
LOAD CSV WITH HEADERS FROM "file:///hudong_pedia.csv" AS line
CREATE (p:HudongItem{title:line.title,image:line.image,detail:line.detail,url:line.url,openTypeList:line.openTypeList,baseInfoKeyList:line.baseInfoKeyList,baseInfoValueList:line.baseInfoValueList})
// 新增了hudong_pedia2.csv
LOAD CSV WITH HEADERS FROM "file:///hudong_pedia2.csv" AS line
CREATE (p:HudongItem{title:line.title,image:line.image,detail:line.detail,url:line.url,openTypeList:line.openTypeList,baseInfoKeyList:line.baseInfoKeyList,baseInfoValueList:line.baseInfoValueList})
// 创建索引
CREATE CONSTRAINT ON (c:HudongItem)
ASSERT c.title IS UNIQUE
以上两步的意思是,将hudong_pedia.csv导入neo4j作为结点,然后对titile属性添加UNIQUE(唯一约束/索引)
(如果导入的时候出现neo4j jvm内存溢出,可以在导入前,先把neo4j下的conf/neo4j.conf中的dbms.memory.heap.initial_size 和dbms.memory.heap.max_size调大点。导入完成后再把值改回去)
进入/wikidataSpider/wikidataProcessing中,将new_node.csv,wikidata_relation.csv,wikidata_relation2.csv三个文件放入neo4j的import文件夹中(运行relationDataProcessing.py可以得到这3个文件),然后分别运行
// 导入新的节点
LOAD CSV WITH HEADERS FROM "file:///new_node.csv" AS line
CREATE (:NewNode { title: line.title })
//添加索引
CREATE CONSTRAINT ON (c:NewNode)
ASSERT c.title IS UNIQUE
//导入hudongItem和新加入节点之间的关系
LOAD CSV WITH HEADERS FROM "file:///wikidata_relation2.csv" AS line
MATCH (entity1:HudongItem{title:line.HudongItem}) , (entity2:NewNode{title:line.NewNode})
CREATE (entity1)-[:RELATION { type: line.relation }]->(entity2)
LOAD CSV WITH HEADERS FROM "file:///wikidata_relation.csv" AS line
MATCH (entity1:HudongItem{title:line.HudongItem1}) , (entity2:HudongItem{title:line.HudongItem2})
CREATE (entity1)-[:RELATION { type: line.relation }]->(entity2)
以上步骤是导入爬取到的关系
-
下载词向量模型:http://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.zh.zip
将wiki.zh.bin放入 KNN_predict 目录 。 (如果只是为了运行项目,步骤2可以不做,预测结果已经离线处理好了) -
进入demo/Model/neo_models.py,修改第9行的neo4j账号密码,改成你自己的
-
进入demo目录,然后运行脚本:
sudo sh django_server_start.sh
这样就成功的启动了django。我们进入8000端口主页面,输入文本,即可看到以下命名实体和分词的结果(确保django和neo4j都处于开启状态)
农业实体识别+实体分类
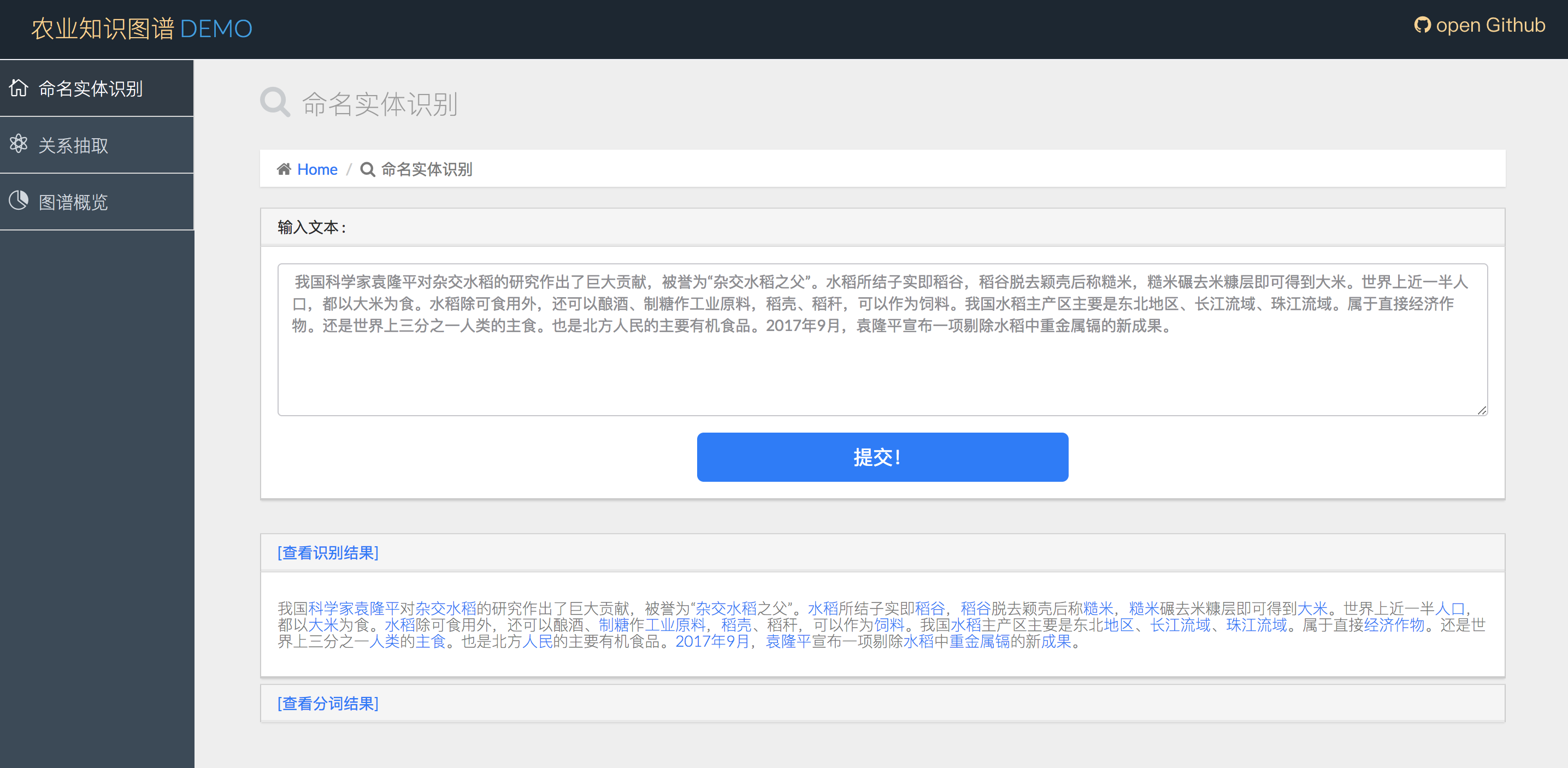
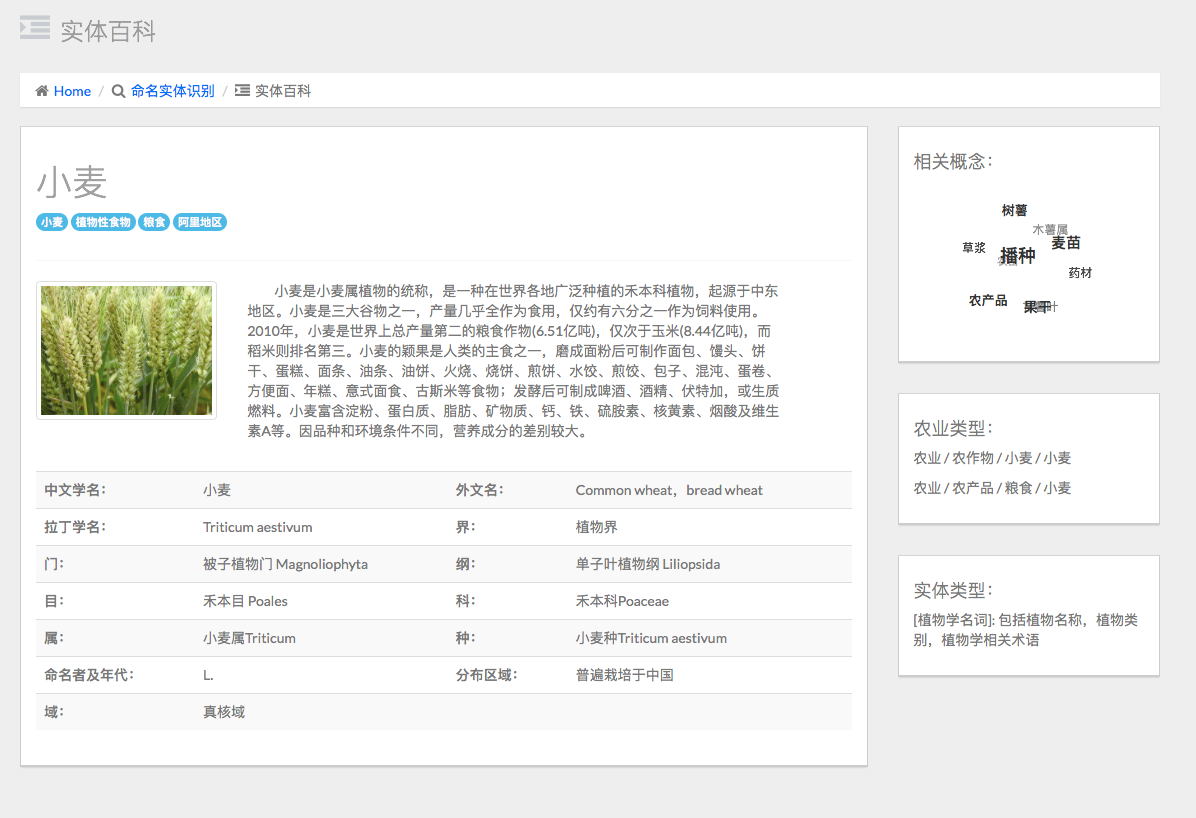
点击实体的超链接,可以跳转到词条页面(词云采用了词向量技术):
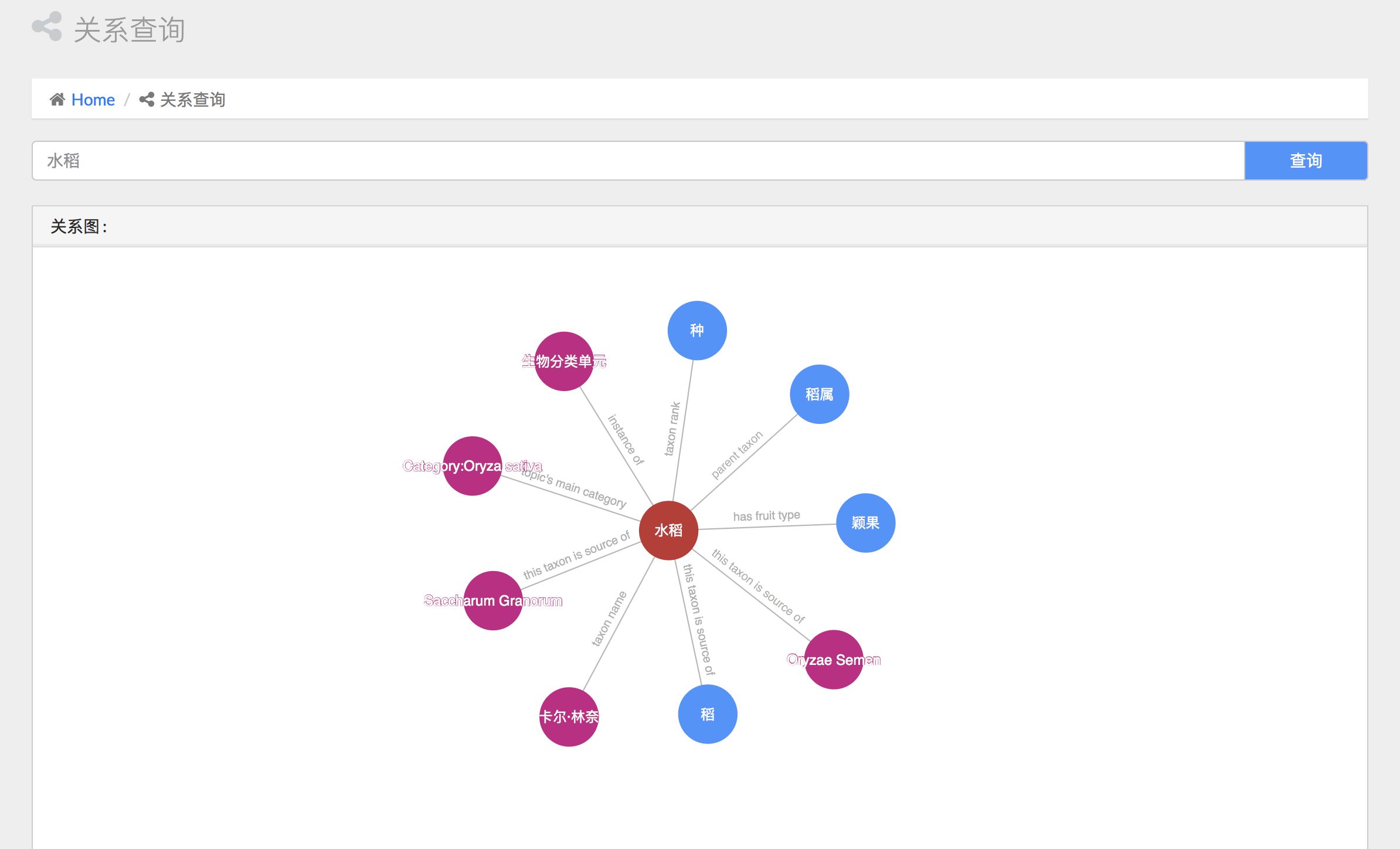
关系查询
关系查询部分,我们能够搜索出与某一实体相关的实体,以及它们之间的关系:
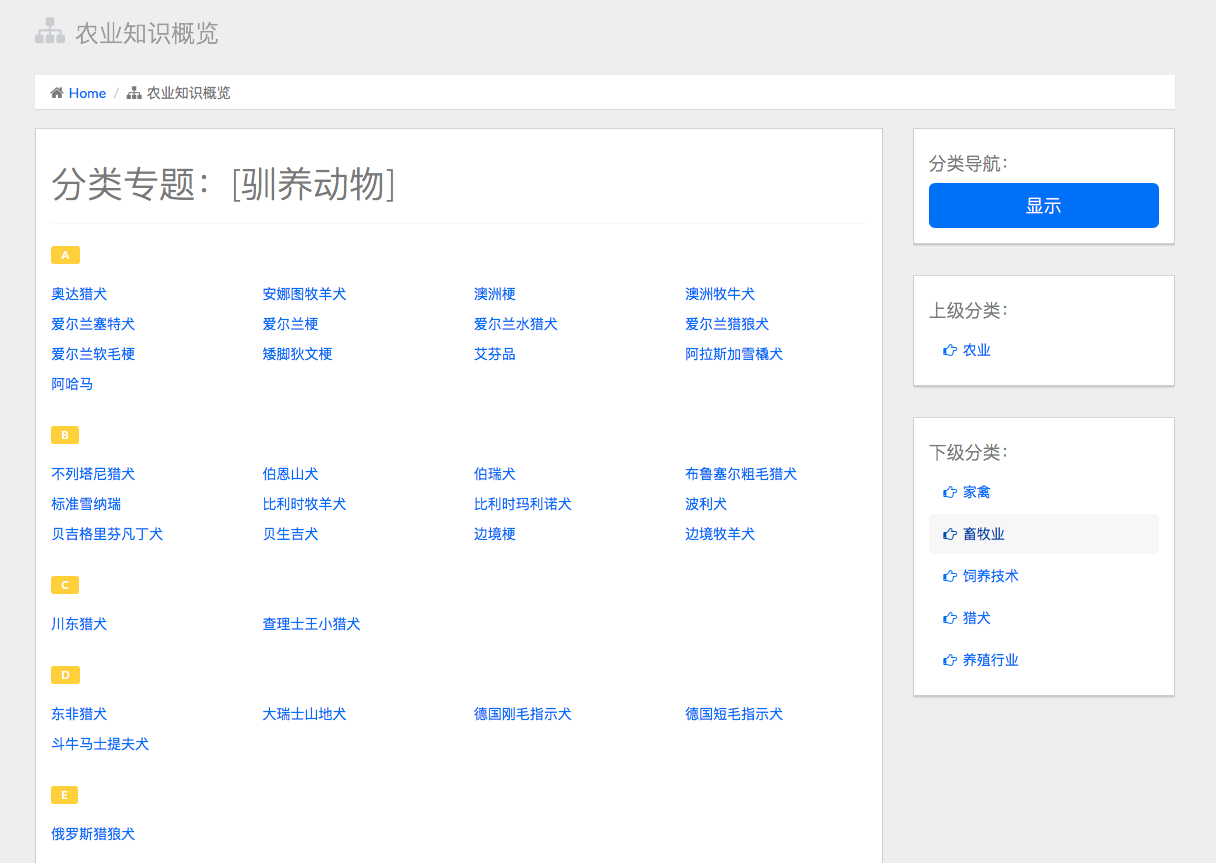
知识的树形结构
农业知识概览部分,我们能够列出某一农业分类下的词条列表,这些概念以树形结构组织在一起:
农业分类的树形图:
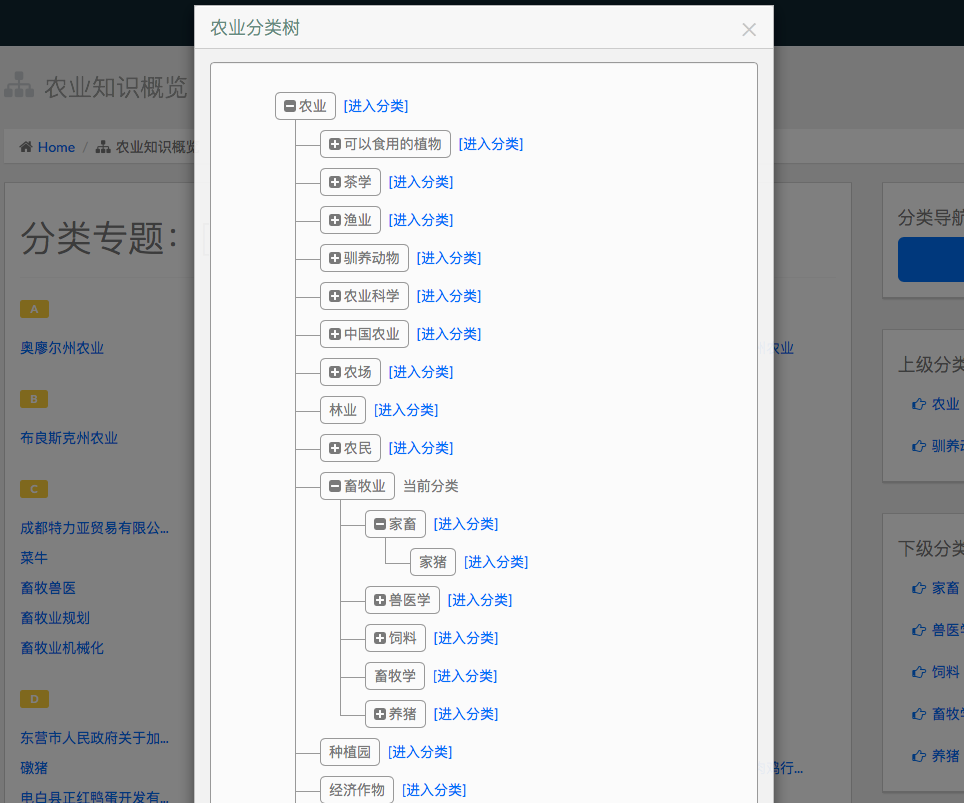
训练集标注
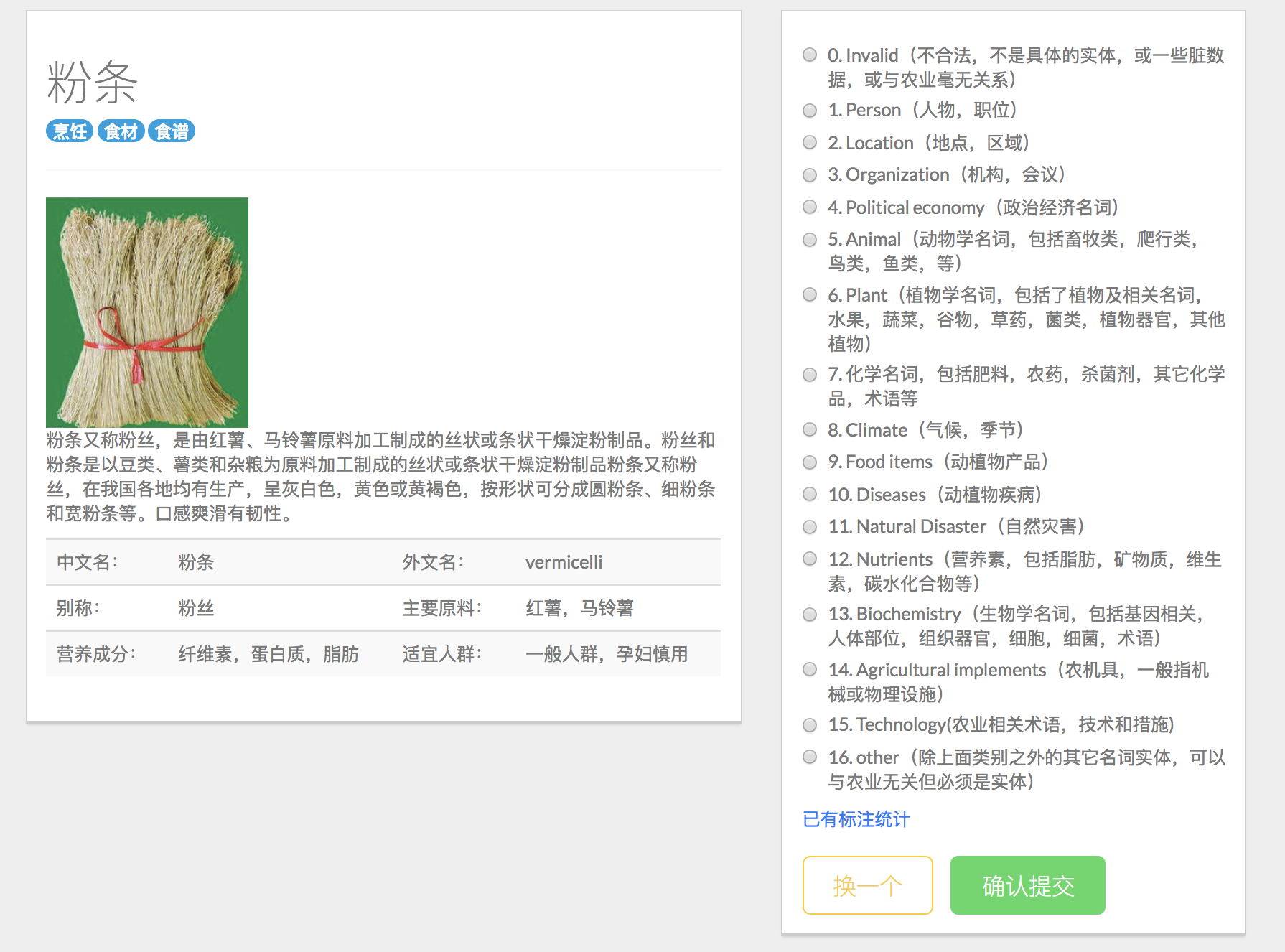
我们还制作了训练集的手动标注页面,每次会随机的跳出一个未标注过的词条。链接:http://localhost:8000/tagging-get , 手动标注的结果会追加到/label_data/labels.txt文件末尾:
我们将这部分做成了小工具,可复用:https://github.com/qq547276542/LabelMarker
(update 2018.04.07) 同样的,我们制作了标注关系提取训练集的工具,如下图所示
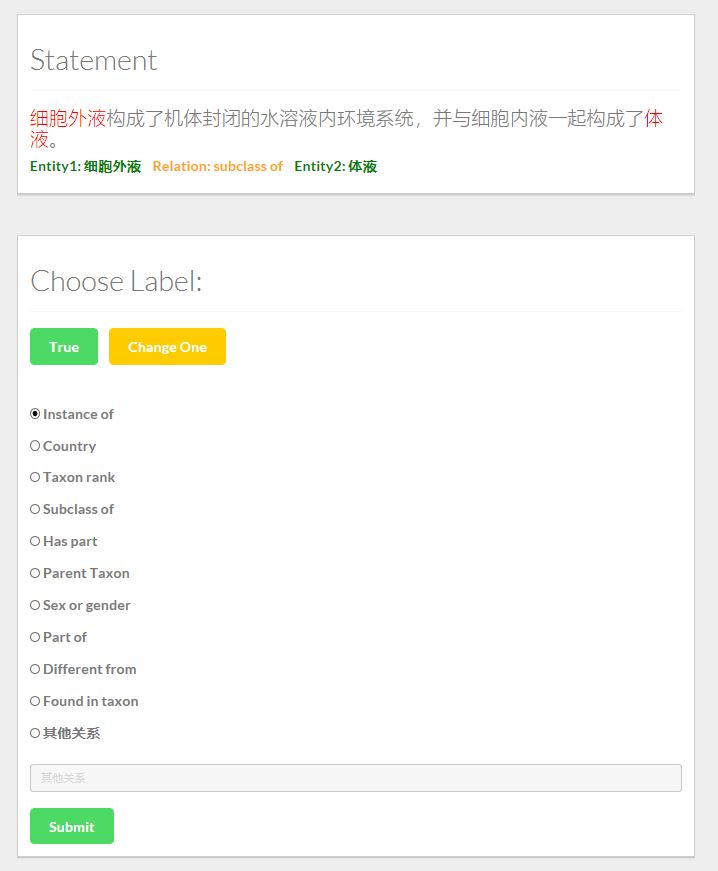
如果Statement的标签是对的,点击True按钮;否则选择一个关系,或者输入其它关系。若当前句子无法判断,则点击Change One按钮换一条数据。
说明: Statement是/wikidataSpider/TrainDataBaseOnWiki/finalData中train_data.txt中的数据,我们将它转化成json,导入到mongoDB中。标注好的数据同样存在MongoDB中另一个Collection中。关于Mongo的使用方法可以参考官方tutorial,或者利用这篇文章简单了解一下MongoDB
我们在MongoDB中使用两个Collections,一个是train_data,即未经人工标注的数据;另一个是test_data,即人工标注好的数据。

使用方法: 启动neo4j,mongodb之后,进入demo目录,启动django服务,进入127.0.0.1:8000/tagging即可使用
思路
图谱实体获取:
1.根据19000条农业网词条,按照筛法提取名词(分批进行,每2000条1批,每批维护一个不可重集合)
2.将9批词做交集,生成农业词典
3.将词典中的词在互动百科中进行爬取,抛弃不存在的页面,提取页面内容,存到数据库中
4.根据页面内容,提取每一个词条页面的特征,构造相似度的比较方法,使用KNN进行分类
5.最后获取每个词条的所属类别,同时能够剔除不属于农业的无关词条
命名实体识别:
使用thulac工具进行分词,词性标注,命名实体识别(仅人名,地名,机构名) 为了识别农业领域特定实体,我们需要:
- 分词,词性标注,命名实体识别
- 以识别为命名实体(person,location,organzation)的,若实体库没有,可以标注出来
- 对于非命名实体部分,采用一定的词组合和词性规则,在O(n)时间扫描所有分词,过滤掉不可能为农业实体的部分(例如动词肯定不是农业实体)
- 对于剩余词及词组合,匹配知识库中以分好类的实体。如果没有匹配到实体,或者匹配到的实体属于0类(即非实体),则将其过滤掉。
- 实体的分类算法见下文。
HudongItem
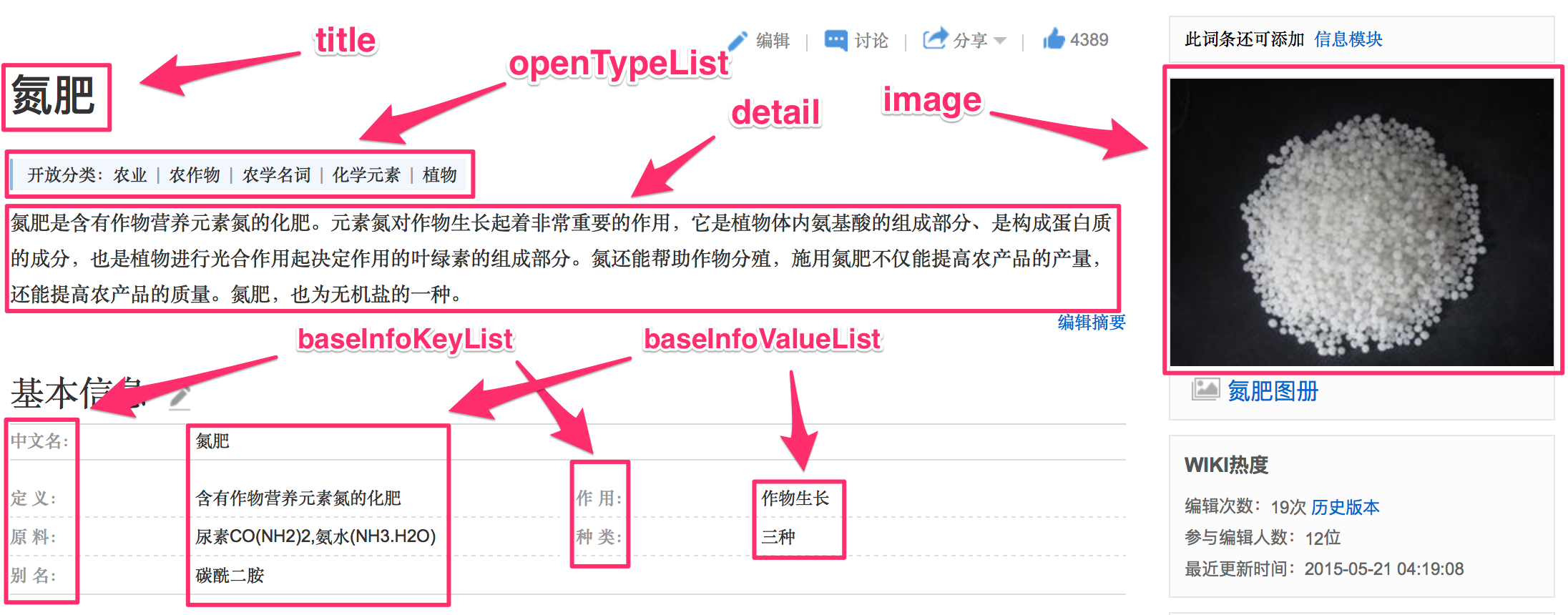
页面分类
分类器:KNN算法
- 无需表示成向量,比较相似度即可
- K值通过网格搜索得到
定义两个页面的相似度sim(p1,p2):
- title之间的词向量的余弦相似度(利用fasttext计算的词向量能够避免out of vocabulary)
- 2组openType之间的词向量的余弦相似度的平均值
- 相同的baseInfoKey的IDF值之和(因为‘中文名’这种属性贡献应该比较小)
- 相同baseInfoKey下baseInfoValue相同的个数
- 预测一个页面时,由于KNN要将该页面和训练集中所有页面进行比较,因此每次预测的复杂度是O(n),n为训练集规模。在这个过程中,我们可以统计各个分相似度的IDF值,均值,方差,标准差,然后对4个相似度进行标准化:(x-均值)/方差
- 上面四个部分的相似度的加权和为最终的两个页面的相似度,权值由向量weight控制,通过10折叠交叉验证+网格搜索得到
Labels:(命名实体的分类)
Label NE Tags Example 0 Invalid(不合法) “色调”,“文化”,“景观”,“条件”,“A”,“234年”(不是具体的实体,或一些脏数据) 1 Person(人物,职位) “袁隆平”,“习近平”,“皇帝” 2 Location(地点,区域) “福建省”,“三明市”,“大明湖” 3 Organization(机构,会议) “华东师范大学”,“上海市农业委员会” 4 Political economy(政治经济名词) “惠农补贴”,“基本建设投资” 5 Animal(动物学名词,包括畜牧类,爬行类,鸟类,鱼类,等) “绵羊”,“淡水鱼”,“麻雀” 6 Plant(植物学名词,包括水果,蔬菜,谷物,草药,菌类,植物器官,其他植物) “苹果”,“小麦”,“生菜” 7 Chemicals(化学名词,包括肥料,农药,杀菌剂,其它化学品,术语等) “氮”,“氮肥”,“硝酸盐”,“吸湿剂” 8 Climate(气候,季节) “夏天”,“干旱” 9 Food items(动植物产品) “奶酪”,“牛奶”,“羊毛”,“面粉” 10 Diseases(动植物疾病) “褐腐病”,“晚疫病” 11 Natural Disaster(自然灾害) “地震”,“洪水”,“饥荒” 12 Nutrients(营养素,包括脂肪,矿物质,维生素,碳水化合物等) “维生素A”,"钙" 13 Biochemistry(生物学名词,包括基因相关,人体部位,组织器官,细胞,细菌,术语) “染色体”,“血红蛋白”,“肾脏”,“大肠杆菌” 14 Agricultural implements(农机具,一般指机械或物理设施) “收割机”,“渔网” 15 Technology(农业相关术语,技术和措施) “延后栽培",“卫生防疫”,“扦插” 16 other(除上面类别之外的其它名词实体,可以与农业无关但必须是实体) “加速度",“cpu”,“计算机”,“爱鸟周”,“人民币”,“《本草纲目》”,“花岗岩”Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK