

如何构建万台服务器下的立体化监控体系?
source link: http://os.51cto.com/art/201801/563261.htm
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

如何构建万台服务器下的立体化监控体系?
为了更好地帮助大家理解监控的维度,本文先从一个通用的网站架构开始谈起,然后讲一讲 58 集团是怎么在横向和纵向两个维度覆盖各种类型监控的。
主要分为两个部分进行分享:
- 网站的总体架构
- 构建立体化的监控体系
网站的总体架构
业务集群
对于大多数的技术人员来说,最熟悉的就是业务集群,我们在业务集群上实现业务逻辑,由 Nginx 将流量分发到这些业务集群上。

如上图所示,是相关的架构,这部分大家都比较熟悉,我们就不展开了。下面详细说一下大型网站在机房外部和机房内部的流量接入端的架构。
机房外部
用户访问一个页面,从浏览器的地址栏输入网址,按下回车键,到页面加载出来,经过哪些步骤呢。
拿一个典型页面举例,通过浏览器中的开发者工具,我们可以看到加载和渲染这个页面需要加载很多页面资源。
不但加载了很多文档类型的资源,例如 HTML;也加载了很多静态资源,例如 CSS、JS 和图片文件。
我们将前一种划分为动态内容,将后一种划分为静态资源。如果我们在全国只有一个机房,那么全国各地的用户都需要跨越多个区域、多个运营商的网络才能访问到网站,如下图所示,这样访问速度一定不是很快。
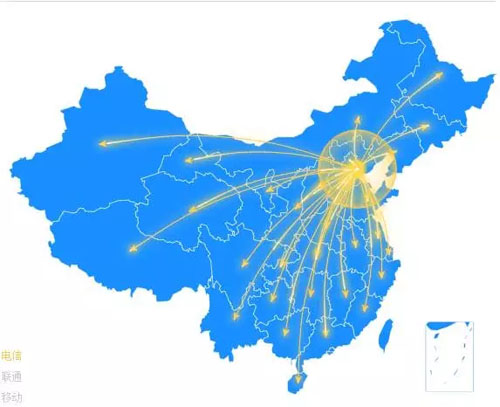
怎么解决这个问题呢?最简单的方法就是让用户就近访问页面资源,在全国各区域、各运营商用户数量比较多的网络内建立节点,让用户就近访问。
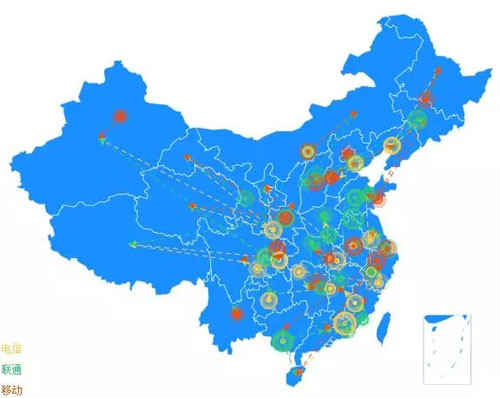
如下图所示,不同颜色的圆圈代表不同的运营商,节点覆盖了页面数量大的区域。
页面上加载的绝大多数资源都是静态资源,通过这种方式可以非常显著地提升页面的加载速度。
这种技术就是 CDN 技术(Content Delivery Network,即内容分发网络)。
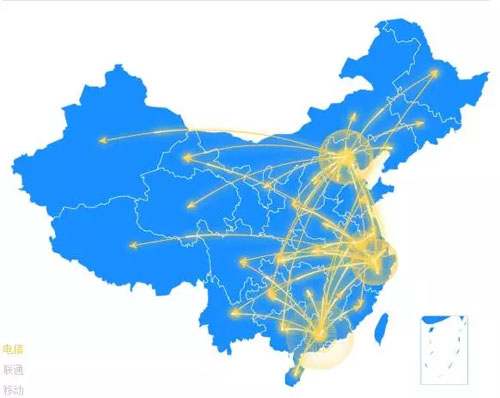
对于动态请求的优化思路也是类似,前面提到的是只有一个机房提供动态请求响应的情况,南方用户的动态请求响应速度是较慢的。
如下图所示,如果在华东、华南等区域部署机房,可以更好地对华东、华南的用户进行覆盖,提升动态内容的访问速度。
那 CDN 是如何实现静态资源的就近访问的呢?使用的就是 DNS 调度的方法。
我们都知道通过 HTTP 协议发起请求的几个步骤如下:
- 域名解析
- 建立连接
- 发送请求
- 接收响应
如下图所示,用户在向域名解析服务器发起域名解析请求的时候,DNS 服务器返回了离该用户最近的 CDN 节点的 IP,从而实现了用户的就近访问。
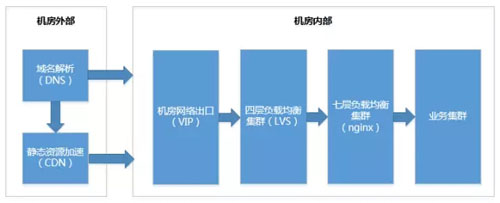
机房内部
如上图,在经过域名解析阶段后,动态的请求会直接访问机房(也可以做动态内容的加速),静态资源在无缓存时也会回源(去机房获取资源文件),这两种情况都会访问机房的 VIP。
分别经过四层负载均衡和七层负载均衡集群后,流量被分发到业务集群。业务集群之间也会存在互相调用的情况。
对每一个关键集群来说都存在主备,主集群出现问题则切换到备集群;也可以主备集群同时提供服务,每个集群都预留承担全部流量的资源。
每个集群内部都包含多台服务器,少量服务器出现异常不影响集群提供服务。机房网络出口提供备份链路,主链路出现问题可以自动切换到备链路。
当遇到极端情况,两条链路都中断的情况,可以切换域名的解析结果和 CDN 的回源 IP 到备份机房的 VIP,然后通过机房之间的专线将流量导入。如果有多个机房,那么直接将流量切到其他正常的机房即可。
构建立体化的监控体系
监控的定位和目标
监控的定位和目标如下:
- 线上服务的守护神,服务稳定性的重要保障
- 运维和研发、测试人员的眼睛,快速发现和排查故障
- 将运维数据进行量化和可视化,便于对网站进行优化
监控系统架构
监控系统的底层模块基于 Open-Falcon,上层做了很多深度的二次开发,整体系统架构图如下:
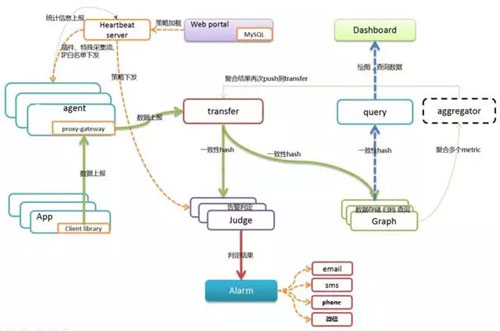
监控的应用规模
监控体系在 58 集团的应用规模如下:
- 覆盖了近万台服务器,包括 58 集团下属的各网站,如 58 同城、赶集网、中华英才网、安居客、转转。
- 监控的业务指标,监控系统中配置了超过 3000 个集群、近 3000 个监控模板、近 300 万个监控指标、每天实时处理的数据量超过 2T。
立体化监控体系概述
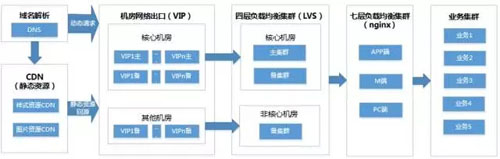
参考网站的架构图,立体化的监控体系包括纵向和横向两个方向。
纵向实现了自底向上各层级的监控,包括网络、服务器、系统层、应用层、业务层,如下图所示:

横向实现了从外到内各层级的监控,包括用户端、机房网络出口端、流量接入端、业务端等,如下图所示:
纵向各层级的监控指标
网络监控
最基本的网络监控包括:
- 机房出口 VIP 是否存活,从机房外对 VIP 进行 ping,如果连续多次发现 VIP 不通则发出告警。
- 流量是否正常,在四层网络设备上监测出入流量和包量等关键指标。
- 机房间专线流量和质量是否正常,以及网络设备及流量是否正常等。在机房之间的网络设备上监控专线的流量和质量,例如:带宽使用量,丢包率、ping 延时等。
服务器监控
服务器的监控包括服务器是否宕机,服务器硬件是否有异常等。
宕机监控,在每个机房都部署监控机,通过 ping 的方式对同机房的服务器进行宕机监控。
为了避免网络抖动的影响,当连续多次发现 ping 不通则发出宕机告警。
在同机房进行部署是为了避免由于机房间网络链路出现问题导致大量的误报宕机。
在监控管理层面通过配置不同的模板,给不同集群、不同角色的用户发送不同的告警,例如:对于数据库主库宕机发送语音告警,其它架构层面支持自动剔除故障机器的宕机发送短信告警即可。
服务器硬件监控,通过在监控 Agent 上部署插件,可以很好地支持多种多样的硬件监控,也非常便于对硬件进行适配。对硬件监控的覆盖程度视业务需求而定。
系统监控
服务器资源使用率,包括 CPU、内存、磁盘、网卡等各项指标。
对于一个中大型互联网公司,业务比较复杂,服务器根据用途被划分为不同的集群,由不同的运维和开发人员负责管理。
那么添加这些监控对于技术人员来说是较大的工作量,且只依靠人去添加监控很难保证监控的覆盖率。我们的思路是尽可能自动化地添加基础的监控。
我们对各个业务在系统监控层面的需求进行归纳,确定了一些核心的监控指标、异常判断条件、告警方式等,生成一个默认的监控模板。
我们的 CMDB 系统包含最基础的服务器资产数据,包括集群的名称、集群中的服务器列表、集群的运维和研发负责人等信息。
这样就可以从 CMDB 中同步这些信息,在监控系统中自动添加每个集群的基础系统监控,也就是自动添加集群、自动创建监控模板(继承了基础监控模板),告警按需求发给运维和研发负责人。
通过这种方式在短时间内做到了所有集群基础监控的 100% 覆盖,起码能做到服务器宕机和系统资源使用率问题导致的异常都能够有效的发出告警,迅速解决了监控初始建设阶段的核心痛点。
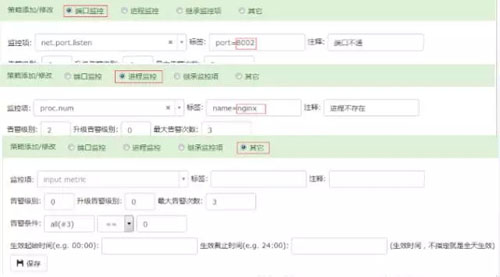
对于某些集群,由于业务的特殊性,基础的监控模板不能满足他的需求,可以继承父模板的监控指标,然后进行告警条件、告警方式的修改。
应用监控
应用监控用来监控部署的应用程序是否正常,包括:端口,进程,功能(页面或接口),QPS,连接数等指标。
一般来说,让运维和开发人员去创建监控模板、关联到集群、配置告警接收人等工作有一定的工作量,而且也有一定的难度。一些情况下,由于配置的问题会导致监控和告警不能生效。
为了解决这个问题,我们基于自动添加的系统监控:
- 一方面从部署上线系统同步应用程序的端口等信息,自动添加端口监控。
- 另一方面基于系统监控的模板,允许用户方便的添加应用监控,例如:只需要填写端口、进程名等就可以方便的添加端口监控和进程监控。
对于功能(页面或接口)、QPS、连接数等指标,我们也提供了部署监控插件进行监控的方式。
用户可以通过帮助文档页面下载多种语言(Java、PHP、Python,Shell等)的监控插件模板,然后进行简单修改,采集到被监控指标后可以方便的接入监控系统。
通过这种方式我们快速提升了应用监控的覆盖率。
业务监控
业务的监控对象包括业务关心的各项指标,例如订单量、成交额等。
由于业务监控和具体的业务相关,不能采用通用的方式进行监控,所以采用自定义监控插件的方式监控。
所有可以采集到的指标都可以添加监控和告警;将数据以 Json 格式发给监控 Agent 即完成数据上报。
横向各层级的监控指标
用户端
有如下几种采集数据的方式:
- 使用在用户端网络内合作用户电脑或手机上部署的探针进行探测。
- 在页面中嵌入 JS 代码,从真实用户的浏览器端对性能数据进行采集。
- 在 APP 端嵌入 SDK,从真实用户的 APP 对访问错误和性能数据进行采集。
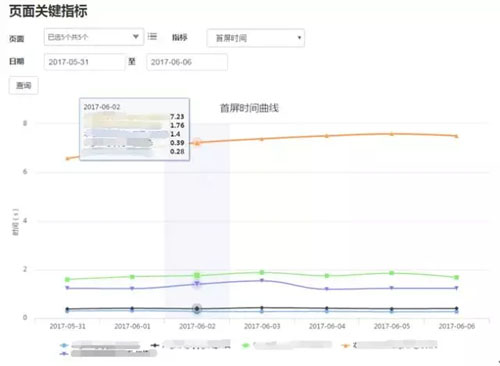
采集的数据包括用户端可用性、首屏时间、全部资源下载时间、全部资源字节数、基础 HTML 页面下载时间等数据,如下图所示:
另外,还可以对 DNS 劫持、链路劫持、访问出错、访问速度较慢的问题进行告警,以 DNS 劫持数据的展示举例:
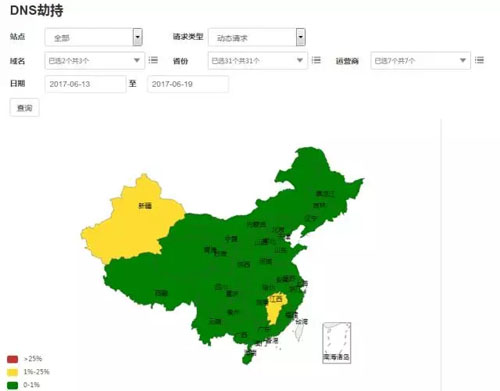
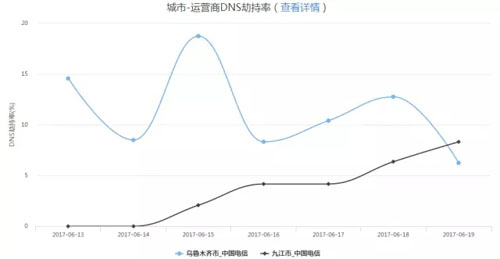
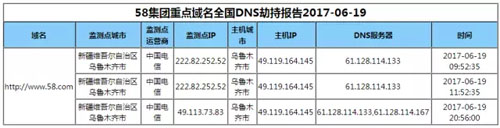
点击图例后,跳转到详情数据:
机房网络出口端
既可以在网络设备上采集流量,也可以在四层负载均衡上采集流量。并可分别对网络的连通性、进出流量、进出包数等关键指标进行监控。
页面和接口监控
对重点页面、接口的可用性、响应时间进行监控。
这些监控都是对机房出口的 VIP 发起请求,流量经过负载均衡服务分发到后端业务集群,业务集群内有少量服务器出现异常,负载均衡服务会自动到另一台服务器重试,异常不会暴露给外部用户。
当探测此处的页面和接口监控发现了异常,那么用户已经可见了,是比较严重的故障。
通过这种监控方式也可以比较客观的评价业务集群的运行状况,重点关注的指标的稳定性和响应时间。
页面监控:对页面的基础页面(即 HTML)进行探测,连续一段时间发现状态码与预期不一致、响应时间过长、找不到匹配的关键词、页面长度较短等情况,会发出告警。
接口监控:对接口进行探测,连续一段时间发现状态码与预期不一致、响应时间过长,接口返回的消息体中业务状态码不符合预期或数据长度较短等情况,会发出告警。
流量接入端
大型网站的流量接入端包括四层和七层的负载均衡集群。
一般的网站可以使用 LVS 提供四层负载均衡服务,技术实力雄厚的公司可以使用自己定制开发的四层负载均衡服务。
七层负载均衡端是流量接入端的重要服务,处于用户流量接入的咽喉要道,重要性不言而喻,所以要有完善的监控。
另外由于所有流量都经过该服务,可以收集到很多用户端访问和后端业务集群运行状况的数据。
一般七层的负载均衡服务使用 Nginx,除了基础的服务器、系统、应用层的监控,还可以实现更多的监控。
有以下几种方式实现:
- 将日志实时传输,集中计算,再将结果给监控服务端。
- 将日志在 Nginx 上实时计算,传送结果给监控服务端。
- 用 Lua 实现 Nginx 扩展,实时计算,传送结果给监控服务端。
我们采用了第一种方式,复杂的计算不占用 Nginx 集群的计算资源。
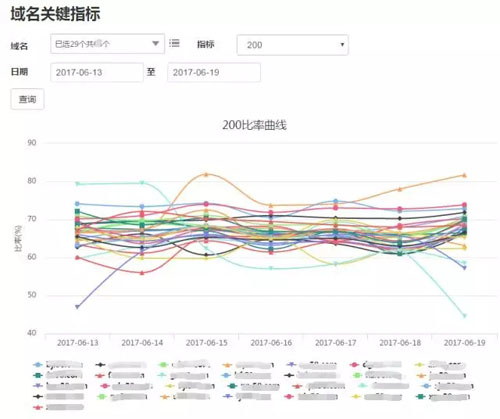
采集的指标包括(如下图):
- 各域名的各种状态码的数量和比率、响应时间。
- 各后端集群的各种状态码的数量和比率、响应时间。
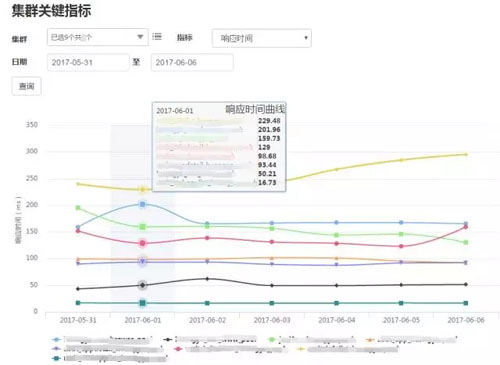
业务集群端
在流量接入端已经能够对业务集群的可用性、响应时间等关键指标进行监控和告警,对业务集群还可以按照纵向各层级添加监控指标。
其他核心功能
监控数据展示
用户能够按照服务器和集群查看监控指标,为了便于用户使用,可以直接查询最常用的监控指标。
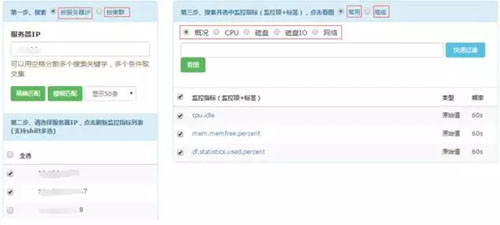
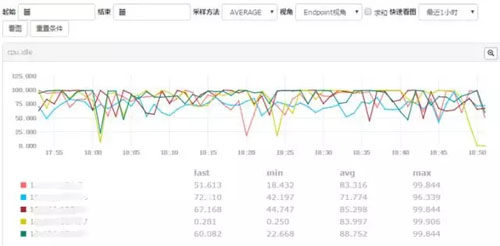
可以在一个视图中展示所有机器的某项监控指标:
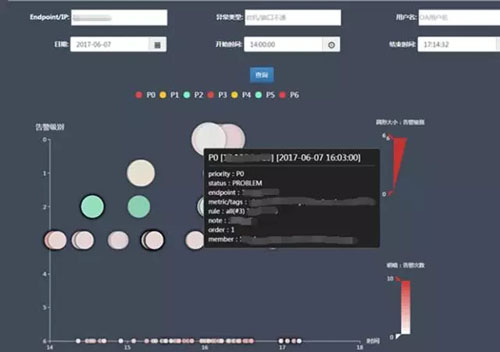
监控异常查看
为了方便用户查看当前有哪些异常,我们提供了监控异常查看页面,且可以对信息进行搜索:

另外还可以在时间维度上查看所有近期的告警:
监控墙
为了便于值班和巡检,我们提供了监控墙功能,可以展示在监控大屏上:
容量管理
为了便于提升服务器的资源利用率,及时发现系统性能瓶颈,为服务器申请提供数据支持,基于监控系统的数据,我们开发了容量管理系统。
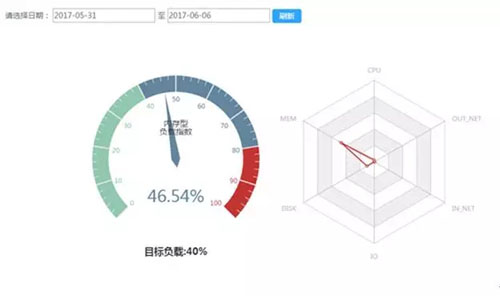
第一步先实现集群的基本容量评估,通过几项主要的系统负载参数(CPU、内存、磁盘空间、磁盘 IO、网卡出入流量使用率)对集群负载进行分析。后续可以加入更多的业务指标来对容量进行管理。
龚诚,58 集团技术工程平台部高级经理,曾任职于百度、新浪微博等公司,负责运维及自动化团队的技术和管理工作;拥有丰富的网站稳定性建设、网站优化等经验。

Recommend
-
63
在 2018 年春节期间,组件运维团队运维设备超过 4 万,单人运维设备超 2 万。在海量服务运维过程中我们面临了哪些挑战?
-
43
本文我们来聊聊分布式系统中的最后一道保障——监控。 监控这个事情,有点像我们平时对人的健康体检。想要效果好、结果靠谱,就得“全面体检”,每一项都做,否则哪怕检查报告都是正常,也不代表没有问题。下面这个景象是不是很熟悉...
-
13
金城银行:立体化帮扶,助力“专精特新”企业再攀高峰 0评论 2022-03-03 17:44:45 来源:南早网 ...
-
5
东方红资产管理:打造立体化“固收+”策略产品线,创造长期稳健回报 近期,随着资本市场震荡,投资者避险情绪上升,“固收+”、债券基金等低风险品种渐渐获得青睐。对于投资者来说,如何在眼花缭乱的固收类产品中挑选...
-
2
上接天气下接地气,应急广播立体化推进基层党建应急广播导语:各地应急广播平台将党史学习教育专栏节目纳入...
-
5
iOS版“男妈妈”等123个Emoji正式上线,风格逐渐立体化 首发:
-
3
随着电视大屏步入智能屏时代,从基础的娱乐视听,到云游戏、AI健身等创新性业务,再到智慧家庭等全新场景,电视大屏被赋予更多属性,功能与...
-
3
构建企业监控体系设计思路概述 精选 原创 key_3_feng 2022-09-06 22:43:29...
-
10
微博成为LIV新媒体独家合作伙伴 新浪高尔夫打造完整立体化生态 9月16日,微博宣布成为LIV高尔夫邀请系列赛新媒...
-
6
微博成为LIV新媒体独家合作伙伴 新浪高尔夫打造完整立体化生态-品玩 微博成为LIV新媒体独家合作伙伴 新浪高尔夫打造完整立体化生态 3小时前 9月16日,微博宣布成为LIV高尔夫邀请系列赛新媒体独家合作伙伴,新浪高尔夫...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK