

Dragging React performance forward – Alex Reardon – Medium
source link: https://medium.com/@alexandereardon/dragging-react-performance-forward-688b30d40a33
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Dragging React performance forward
Dragging React performance forward

I work on a drag and drop library for React: react-beautiful-dnd 🎉. The goal of the
library is to provide a beautiful and accessible drag and drop experience for lists on the web. You can read the introduction blog here: Rethinking drag and drop. The library is completely driven by state — user inputs result in state changes which then updates what the user sees. This conceptually allows for dragging with any input type. Doing state driven dragging at scale is full of performance traps. 🦑We recently released version 4 of react-beautiful-dnd which contained some massive performance improvements 🤩
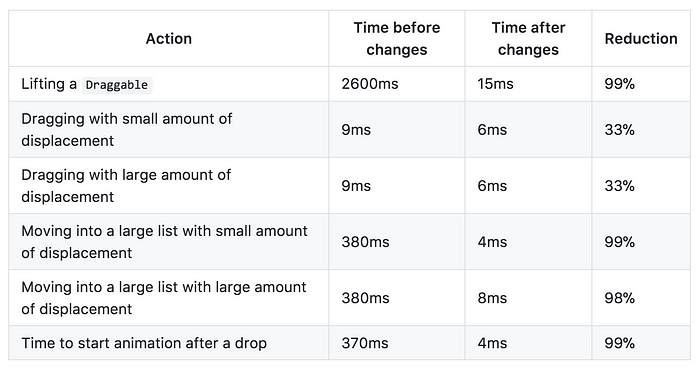
You read correctly, we saw performance improvements of 99% 🤘.The improvements are even more impressive given that the library was already extremely optimised. You can have a play with the improvements for yourself on our large list example or large board example 😎.
In this blog I will explore the performance challenges that we faced and how we overcame them to get such impressive results. The solutions that I will talk about are very tailored for our problem domain. There are some principles and techniques that will emerge — but the specifics might be different across problem domains.
Some of the techniques I describe in this blog are fairly advanced and the majority of them would be best to be used within the boundaries of a React library rather than directly in your React applications.
TLDR;
Hey we are all super busy! Here is a really high level overview of this blog:
Avoid render calls as much as possible. In addition to previously explored techniques (round 1, round 2), here are some new learnings for me:
- Avoid using props for message passing
- Calling
renderis not the only way you can update styles - Avoid offscreen work
- Batch related Redux state updates if you can
State management
react-beautiful-dnd uses Redux under the hood for a big part of it’s state management. It is an implementation detail and consumers of the library are welcome to use whatever state management they like. A lot of the specifics in this blog are geared towards Redux applications — however, there are general techniques that are universally applicable. For the purpose of clarity here are some terms for those unfamiliar with Redux:
- store: a global state container — usually put on the
contextso that connected components can subscribe to updates - connected components: components that have direct subscriptions to the store. Their responsibility is to respond to state updates in the store and pass props onto unconnected components. These are commonly referred to as smart or container components
- unconnected components: components that are not aware of Redux at all. They are often wrapped by connected components to hydrate them with props from the state. These are commonly referred to as dumb or presentational components
Here is some more detailed information on these concepts from
if you are interested.
First principles
When it comes to React performance as a general rule you want to avoid calling a component’s render() function as much as possible. A render call can be expensive due to:
- Heavy processing in
renderfunctions. - Reconciliation
Reconciliation is the process where React builds up a new tree and then reconciles it with its current view of the world (the virtual DOM) — performing actual DOM updates if required. A reconciliation is triggered after a component calls render.
render function processing and reconciliation is expensive at scale. If you have 100’s or 10,000’s of components you probably do not want each component reconciling on every update to shared state in a store. Ideally only the components that need to update have their render function called. This is especially true for drag and drop where we are pushing for 60 updates per second (60fps).
I explore techniques for avoiding unnecessary render calls in two blogs I have previously written (round 1, round 2) and the React docs talk on this subject also. As with everything there is a balance to be struck, if you are too aggressive with avoiding render you can introduce a lot of potentially redundant memoization checks. This topic has been covered elsewhere so I will not go into any more detail here.
In addition to render costs, when using Redux the more connected components you have the more state queries (mapStateToProps) and memoization checks you need to run on every update. I talk about state queries, selectors and memoization relevant to Redux in detail in the round 2 blog.
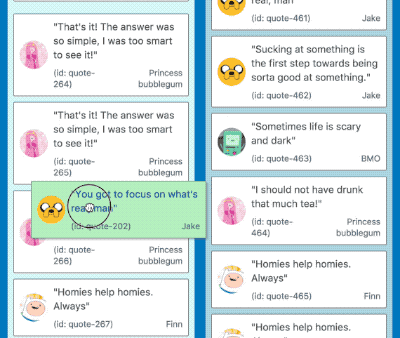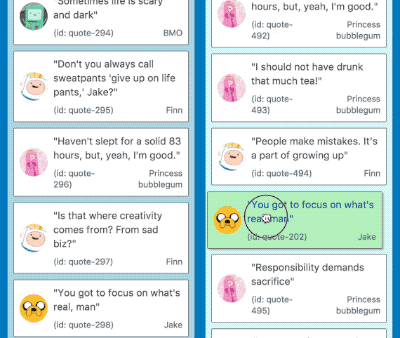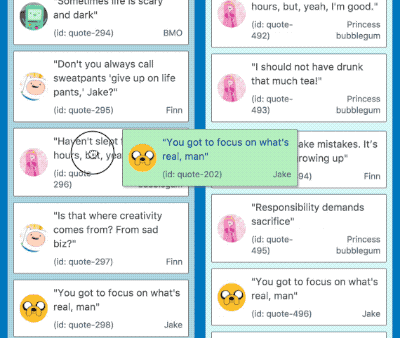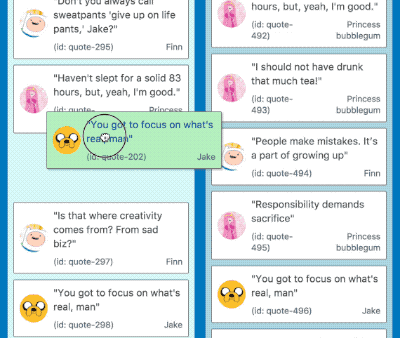
Problem 1: A long pause before a drag starts
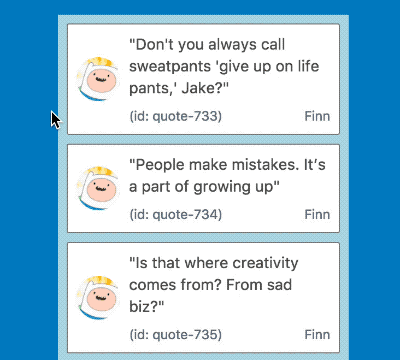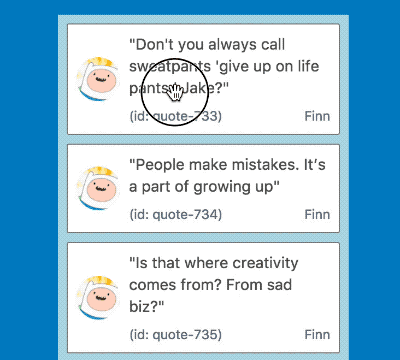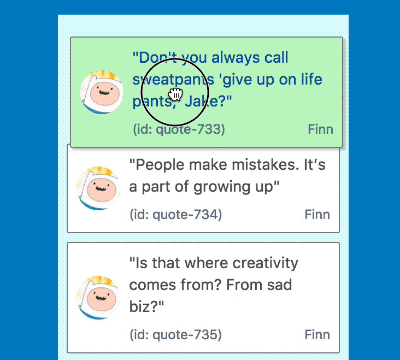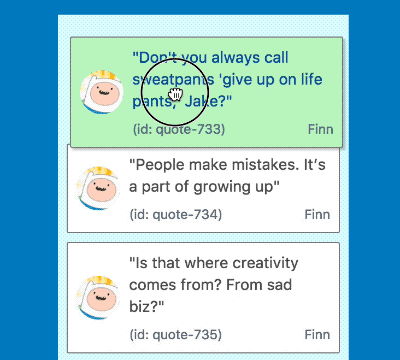
Notice the difference in time from when the mouse down circle appears and when the card turns green. Yuck!
When lifting an item in a big list it would take considerable time for the drag to start, in a list of 500 items this was 2.6 seconds 😢! This is a terrible experience for users who rightly expect drag and drop interactions to be instant. Let’s take a look at what was going on, and a few techniques we used to overcome the issue.
Issue 1: Naive dimension publishing
In order to perform a drag we took a snapshot of the dimensions (coordinates, sizes, margins and so on) of all the relevant components and put them into our state and the beginning of a drag. We would then use this information during the drag to calculate what needs to move. Let’s take a look at how we did this initial snapshot:
- When we start a drag we put a
requeston thestate - Connected dimension publishing components read this
requestand see if they need to publish anything - If they need to publish they set a
shouldPublishprop on the unconnected dimension publisher - The unconnected dimension publisher collects the dimensions from the DOM and publishes them using a
publishcallback
Okay, so here are some of the pain points:
1. When we start a drag we put a
requeston thestate
2. Connected dimension publishing components read this request and see if they need to publish anything
At this point every connected dimension publisher needs to execute a check against the store to see if they need to request dimensions. Not ideal, but not terrible. Let’s move on
3. If they need to publish they set a
shouldPublishprop on the unconnected dimension publisher
We were using a shouldPublish prop to pass a message to a component to perform an action. An unfortunate by-product of this is that it would cause a render of the component — which would cause a reconciliation of itself and it’s children. When you do this for a lot of components it is expensive.
4. The unconnected dimension publisher collects the dimensions from the DOM and publishes them using a
publishcallback
There is where things get even worse. First off, we would read a lot of dimensions from the DOM at once which can take a bit of time. From there each dimension publisher would individually publish a dimension. These dimensions would get stored on the state. This change in state would cause store subscriptions to fire which would execute the connected component state queries and memoization checks in step 2. It would also cause other connected components in the application to similarly run redundant checks. So whenever an unconnected dimension publisher published a dimension it would cause redundant work for all of the other connected components. It was a O(n²) algorithm — or worse! Ouch.
The dimension marshal
To get around these problems we created a new actor to manage the dimension collecting flow: a dimension marshal. Here is how the new dimension publishing works now:
Pre drag work:
- We create a
dimension marshaland put it on thecontext - When a dimension publisher mounts into the DOM it reads the
dimension marshaloff thecontextand registers itself with thedimension marshal. Dimension publishers no longer watch the store directly. As such there is no more unconnected dimension publisher.
Drag start work:
- When we start a drag we put a
requeston thestate(unchanged) - The
dimension marshalreceives therequestand directly requests the critical dimensions (the dragging item and its container) from the required dimension publishers for a drag to start. These are published to the store and the drag can start. - The
dimension marshalthen asynchronously requests the dimensions from all the other dimension publishers in a following frame. Doing this splits the cost of collecting dimensions from the DOM and the publishing of the dimensions (next step) into seperate frames. - In another frame the
dimension marshalperforms a batchpublishof all of the collected dimensions. At this point the state is completely hydrated and it only took three frames.
Other performance advantages of this approach:
- Fewer state updates which results in less work for all connected components
- No more connected dimension publishers which means that the processing that was done in these components no longer needs to occur.
Because the dimension marshal is aware of all of the ids and indexes in the system it is able to directly request any dimension directly O(1). This also enables it to decide how and when to collect and publish dimensions. Previously we had a single message shouldPublish which everything responded to all at once. The dimension marshal gives us a lot of flexibility in tuning the performance of this part of the lifecycle. We could even implement different collection algorithms depending on device performance if required.
Summary
We improved the performance of dimension collecting by:
- Not using props to pass messages which had no visible updates.
- Breaking up work into multiple frames
- Batching state updates across multiple components
Issue 2: Style updates
When a drag starts, we need to apply some styles to every Draggable (such as pointer-events: none;). To do this we were applying an inline style. In order to apply the inline style we needed to render every Draggable. This had the result of calling render on potentially 100’s of Draggable items right when the user was trying to start dragging — at the cost of about 350ms for 500 items.
So, how would we go about updating these styles without causing a render?
Dynamic shared styles 💫
For all Draggable components we now apply a shared data attribute (eg data-react-beautiful-dnd-draggable ). At no point do the data attributes change. However, we dynamically change what styles that are applied to these data attributes through a shared style element that we create in the head of the page.
Here is a simplified version of this technique:
You can see how we actually do it if you are interested
At different points of the drag lifecycle we redefine the content of the style rules themselves. You would usually do change styles on an element by toggling a class. However, by using dynamic style definitions we can avoid needing to render any components to apply a new class name 👍
We use a data attribute rather than a class name to make using the library easier for consumers — they do not need to merge our provided class name with their own class names.
Using this technique we were also able to optimise other phases in the drag and drop lifecycle. We are now able to update styles items without the need to render them.
Note: you could achieve a similar technique by creating pre-baked style rule sets and then changing a class on the body to activate the different rule sets. However, by using our dynamic approach we were able to avoid needing to add classes on the body as well as allowing us to have rule sets with different values over time rather that just fixed ones.
Do not fear, the selector performance of data attributes is good and is orders of magnitude in difference from render performance.
Issue 3: Blocking unwanted drag starts
When a drag started we also called render on a Draggable to update a canLift prop to false. This was used to prevent the starting of a new drag at particular times in the drag lifecycle. We need this prop as there are some combinations of mouse and keyboard inputs that can allow a user to start a drag while already dragging something else. We still really needed this canLift check — but how could we do it without calling render on all of the Draggables?
State hydrated context function
Rather than updating a prop to each Draggable through a render to stop a drag from occurring, we added a canLift function onto the context. This function was able to get to the current state from the store and execute the required checks. In this way we were able to execute the same checks but without needing to update a Draggable's props.
This code is drastically simplified, but it illustrates the approach
It is probably obvious that you only want to do this very sparingly. However, we found it to be a really useful way of providing store hydrated information to components without updating their props. Given that this check happens in response to a user input and has no rendering implications we were able to get away with it.
No more long pause before a drag starts
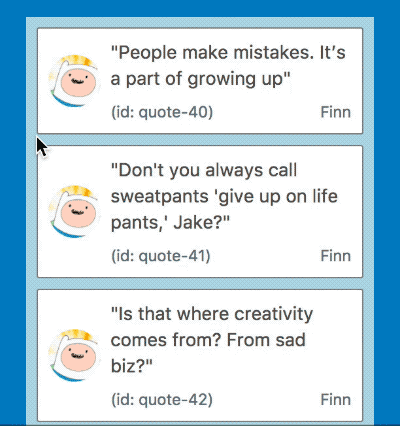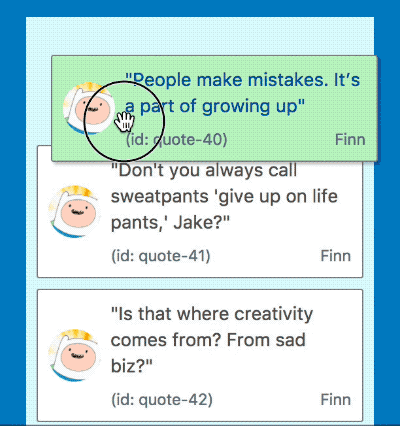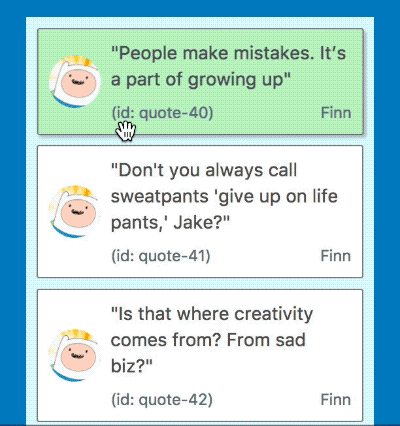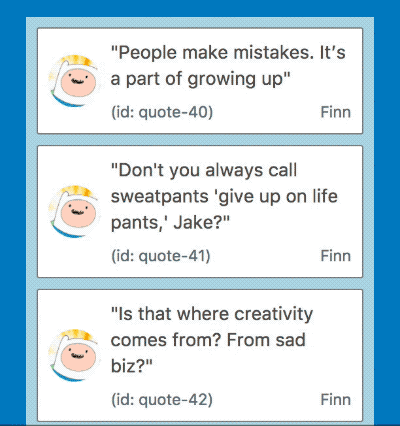
Starting a drag with 500 items now occurs instantly
By using the techniques outlined above we where able to bring the time to start dragging down from 2.6s with 500 draggable items to 15ms (within a single frame) which is a reduction of 99% 😍!
Problem 2: Slow displacement
Frame rate drop when displacing large amount of items
When moving from one big list to another there was a significant frame rate drop. Moving into a new list would cost about 350ms for when there are 500 draggable items.
Issue 1: Too much movement
One of the core design features of react-beautiful-dnd is that items naturally move out of the way of other items while a drag is occurring. However, when you move into a new list you can often be displacing large amounts of items all at the one time. If you move to the top of a list it would need to push down everything in the whole list to make room. The offscreen css transitions themselves are not too expensive. However, communicating with the Draggables to tell them to move out of the way is done through a render which is expensive to do for lots of items all at once.
Virtualised displacement
Rather than displacing items that the user cannot see, we now only move things that are partially visible to the user. So items that are completely invisible are not moved. This drastically reduces the amount of work we need to do when moving into a big list as we only need to render the visible draggable items.
When detecting what is visible we need to consider the current browser viewport as well as scroll containers (elements with their own scrollbars). Once the user scrolls we update the displacement based on what is now visible. There were some complications in ensuring that this displacement looks correct as the user scrolls. They should not be able to tell that we are not moving items that are not visible. Here are some rules we came up with to create an experience that looks correct to the user.
- If an item needs to move and it is visible: move the item and animate its movement
- If an item needs to move but it it invisible: do not move it
- If an item needs to move and is visible and it previously needed to move but was invisible: move it but do not animate its movement.
Because we are only displacing visible items, it now does not matter how big the list you are moving into is from a performance perspective, as we only move the items that the user can see.
Why not use virtualised lists?
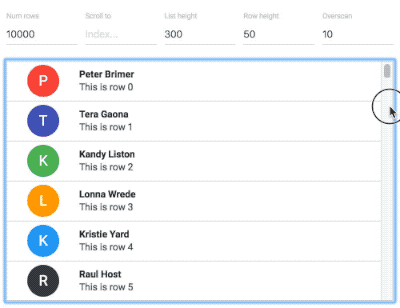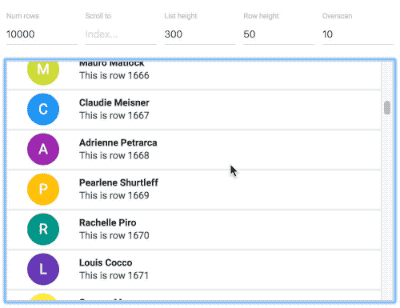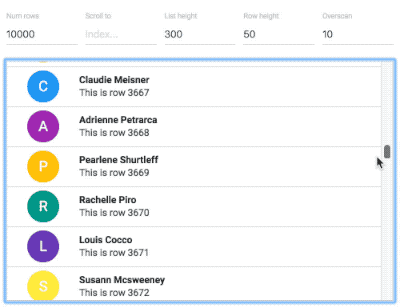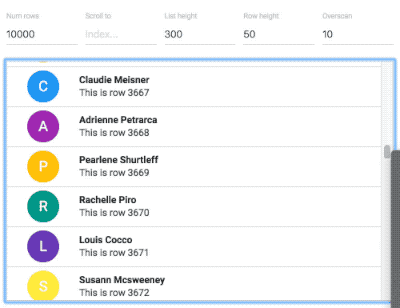
An example of a 10,000 item virtual list from react-virtualized
Avoiding offscreen work is a difficult task and the techniques you use will be different depending on your application. We wanted to avoid moving and animating already mounted elements that are not visible during a drag and drop interaction. This is different to avoiding rendering offscreen components completely using some sort of virtualisation solution such as react-virtualized. Virtualisation is amazing, but adds considerable complexity to a code base. It also breaks some native browser functionality such as printing and finding (command / control + f). Our decision was to provide great performance for React applications even when they are not using virtualised lists. This makes it really easy to add beautiful, performant drag and drop to your existing applications with very little overhead. That said, we are planning on supporting virtualised lists as well — so consumers will be able to choose if they want to use virtualised lists to reduce big list render times. This would be useful if you had lists comprised of 1000’s of items.
Issue 2: Droppable updates
When a user drags over a Droppable list we let the consumer know by updating a isDraggingOver property. However, doing this causes a render of a Droppable — which in turn causes a render on all its children — which could be 100’s of Draggable items!
We do not control a consumers children
To avoid this we created a performance optimisation recommendation in the docs for consumers of react-beautiful-dnd to avoid rendering the children of a Droppable if it is unneeded. The library itself does not control the rendering of a Droppable's children and so the best we can do is offer a suggested optimisation. This suggestion allows users to style a Droppable in response to being dragged over, while avoiding calling render on all of its children.
Instant displacement
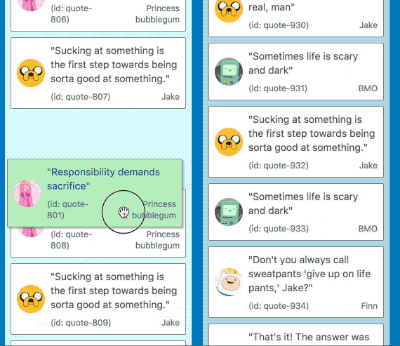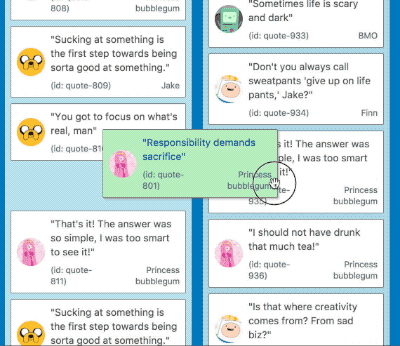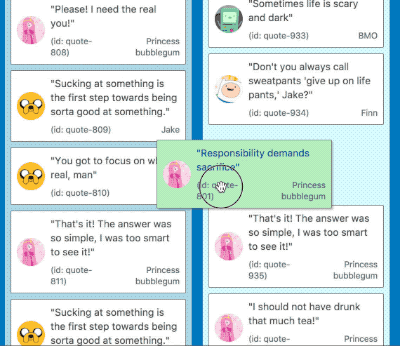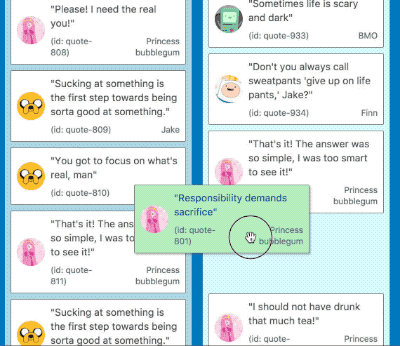
Butter smooth movement between large lists
By implementing these optimisations we were able to reduce the time to move between lists comprised of 500 items with large amounts of displacement from 380ms to 8ms — a single frame! Another 99% reduction
Other: lookup tables
This optimisation is not specific to React — but it was useful when dealing with ordered lists
In react-beautiful-dnd we often use arrays to store ordered data. However, we also want to do fast lookups of this data to retrieve an entry, or to see if an entry exists. Normally you would need to do an array.prototype.find or something similar to get the entry from the list. If you are doing this a lot this can be punishing for large arrays.
There are lot of techniques and tools to get around this problem (including normalizr). A common approach is to store your data in anObject map and have an array of id’s to maintain the order. This is such a great optimisation and speeds things up a lot if you need to regularly look up values in a list.
We did things a little differently. We use memoize-one (a memoization function which only remembers the latest arguments) to create lazy Object maps for instant lookups where needed. The idea is that you create a function that takes an Array and returns a Object map. If you pass the same array to the function multiple times, you return the previously computed Object map. If the array changes, you recompute the map. This lets you have an instant lookup table without needing to recompute it regularly or needing to explicitly store it in your state.
Using look up tables drastically sped up drag movements where we were checking if an item was present in an array in every connected Draggable component on every drag update (O(n²) across the system). By using this approach we are able to compute a Object map once per state change and let the connected Draggable components use a shared map for O(1) lookups.
Final words ❤️
I hope you have found this blog useful in thinking about some optimisations you could apply to your own libraries and applications. Check out react-beautiful-dnd for yourself and have a play with our examples.
Thank you to
and
for their assistance in coming up with the optimisations and
,
,
,
,
,
, Ali Chamas and other assorted
’s for their help putting this blog together.
Recording
I gave a talk which goes over the main points of this blog at React Sydney.
Dragging React performance forward at React Sydney
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK