

[Redis源码阅读]dict字典的实现
source link: http://www.hoohack.me/2018/01/07/read-redis-src-dict?amp%3Butm_medium=referral
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
dict的用途
dict是一种用于保存键值对的抽象数据结构,在redis中使用非常广泛,比如数据库、哈希结构的底层。
当执行下面这个命令:
> set msg "hello"
以及使用哈希结构,如:
> hset people name "hoohack"
都会使用到dict作为底层数据结构的实现。
结构的定义
先看看字典以及相关数据结构体的定义:
/* 字典结构 每个字典有两个哈希表,实现渐进式哈希时需要用在将旧表rehash到新表 */
typedef struct dict {
dictType *type; /* 类型特定函数 */
void *privdata; /* 保存类型特定函数需要使用的参数 */
dictht ht[2]; /* 保存的两个哈希表,ht[0]是真正使用的,ht[1]会在rehash时使用 */
long rehashidx; /* rehashing not in progress if rehashidx == -1 rehash进度,如果不等于-1,说明还在进行rehash */
unsigned long iterators; /* number of iterators currently running 正在运行中的遍历器数量 */
} dict;
/* 哈希表结构 */
typedef struct dictht {
dictEntry **table; /* 哈希表节点数组 */
unsigned long size; /* 哈希表大小 */
unsigned long sizemask; /* 哈希表大小掩码,用于计算哈希表的索引值,大小总是dictht.size - 1 */
unsigned long used; /* 哈希表已经使用的节点数量 */
} dictht;
哈希表节点
/* 哈希表节点 */
typedef struct dictEntry {
void *key; /* 键名 */
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; /* 值 */
struct dictEntry *next; /* 指向下一个节点, 将多个哈希值相同的键值对连接起来*/
} dictEntry;
dictType
/* 保存一连串操作特定类型键值对的函数 */
typedef struct dictType {
uint64_t (*hashFunction)(const void *key); /* 哈希函数 */
void *(*keyDup)(void *privdata, const void *key); /* 复制键函数 */
void *(*valDup)(void *privdata, const void *obj); /* 复制值函数 */
int (*keyCompare)(void *privdata, const void *key1, const void *key2); /* 比较键函数 */
void (*keyDestructor)(void *privdata, void *key); /* 销毁键函数 */
void (*valDestructor)(void *privdata, void *obj); /* 销毁值函数 */
} dictType;
把上面的结构定义串起来,得到下面的字典数据结构:
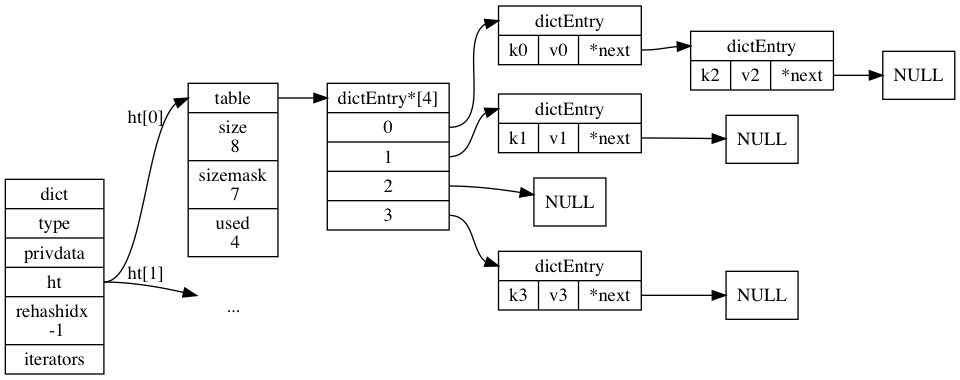
根据数据结构定义,把关联图画出来后,看代码的时候就更加清晰。
从图中也可以看出来,字典的哈希表里,使用了链表解决键冲突的情况,称为链式地址法。
rehash(重新散列)
当操作越来越多,比如不断的向哈希表添加元素,此时哈希表需要分配了更多的空间,如果接下来的操作是不断地删除哈希表的元素,那么哈希表的大小就会发生变化,更重要的是,现在的哈希表不再需要那么大的空间了,在redis的实现中,为了保证哈希表的负载因子维持在一个合理范围内,当哈希表保存的键值对太多或者太少时,redis对哈希表大小进行相应的扩展和收缩,称为rehash(重新散列)。
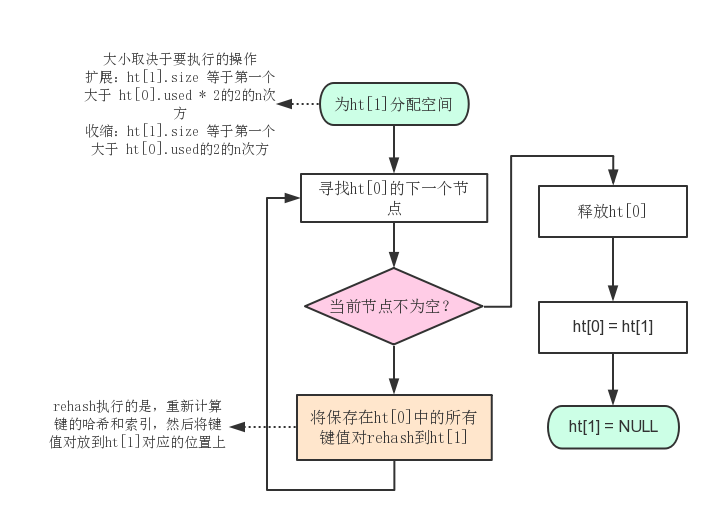
执行rehash的流程图
负载因子解释
负载因子 = 哈希表已保存节点数量 / 哈希表大小
负载因子越大,意味着哈希表越满,越容易导致冲突,性能也就越低。因此,一般来说,当负载因子大于某个常数(可能是 1,或者 0.75 等)时,哈希表将自动扩容。
渐进式rehash
在上面的rehash流程图里面,rehash的操作不是一次性就完成了的,而是分多次,渐进式地完成。
原因是,如果需要rehash的键值对较多,会对服务器造成性能影响,渐进式地rehash避免了对服务器的影响。
渐进式的rehash使用了dict结构体中的rehashidx属性辅助完成。当渐进式哈希开始时,rehashidx会被设置为0,表示从dictEntry[0]开始进行rehash,每完成一次,就将rehashidx加1。直到ht[0]中的所有节点都被rehash到ht[1],rehashidx被设置为-1,此时表示rehash结束。
结合代码再深入理解
/* 实现渐进式的重新哈希,如果还有需要重新哈希的key,返回1,否则返回0
*
* 需要注意的是,rehash持续将bucket从老的哈希表移到新的哈希表,但是,因为有的哈希表是空的,
* 因此函数不能保证即使一个bucket也会被rehash,因为函数最多一共会访问N*10个空bucket,不然的话,函数将会耗费过多性能,而且函数会被阻塞一段时间
*/
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
assert(d->ht[0].size > (unsigned long)d->rehashidx);
/* 找到非空的哈希表下标 */
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* 实现将bucket从老的哈希表移到新的哈希表 */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* 如果已经完成了,释放旧的哈希表,返回0 */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* 继续下一次rehash */
return 1;
}
在渐进式rehash期间,所有对字典的操作,包括:添加、查找、更新等等,程序除了执行指定的操作之外,还会顺带将ht[0]哈希表索引的所有键值对rehash到ht[1]。比如添加:
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
int index;
dictEntry *entry;
dictht *ht;
/* 如果正在rehash,顺带执行rehash操作 */
if (dictIsRehashing(d)) _dictRehashStep(d);
/* 获取新元素的下标,如果已经存在,返回-1 */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; // 如果正在进行rehash操作,返回ht[1],否则返回ht[0]
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
使用一个标记值标记某项操作正在执行是编程中常用的手段,比如本文提到的rehashidx,多利用此手段可以解决很多问题。
我在github有对Redis源码更详细的注解。感兴趣的可以围观一下,给个star。
Redis4.0源码注解。可以通过commit记录查看已添加的注解。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
更多精彩内容,请关注个人公众号。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK