

效率低、易欺骗…什么阻碍了深度学习实现通用人工智能
source link: http://www.sohu.com/a/214942710_99985415?amp%3Butm_medium=referral
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
效率低、易欺骗…什么阻碍了深度学习实现通用人工智能
错的不是深度学习,而是期望深度学习走向通用人工智能的你我。
撰文 | 邱陆陆
人工智能度过了轰轰烈烈的 2017,有人山人海的学术会议,也有雨后春笋般的新兴独角兽。而迈入 2018,我们除了观望创业者们如何在现实世界中搭建他们精心描绘的人工智能蓝图(起码搭个地基),也对注入了大量新鲜血液的研究领域抱有了更高的期待。
然而知名研究者,纽约大学心理学和神经科学教授 Gary Marcus 在新年第 2 天,就泼出了第一盆冷水:他在 arXiv 上发布了一篇长达 27 页的文章,历数今日的深度学习十大无法逾越的鸿沟,得出「深度学习不是人工智能的通用解决方案」的结论。

Gary Marcus 在 2017 机器之心 GMIS 大会上
机器之心第一时间编译了全文。然而尽管 Marcus 在文章开头强调本文「写给该领域的研究人员,也写给缺乏技术背景又可能想要理解该领域的 AI 消费者」,并且在抛出论点前给出了一小段背景介绍,但论述中仍然充满了容易让人分散注意力的大量专业术语。那么如果拨开这些藤蔓,Gary Marcus 在批判深度学习时,究竟在批判什么呢?
深度学习需要大量数据,但这为什么是一个弱点?
批评深度学习依赖大数据,其实是在批评它效率太低。
大数据究竟有多大?这里有一组具体的数字:
以 2012 年的 Krizhevsky,Sutskever 和 Hinton 的一篇知名论文为例:文章中的用于对 1000 类图像进行分类的模型有 65 万个节点,6000 万个参数,使用了 100 万个样本进行训练。
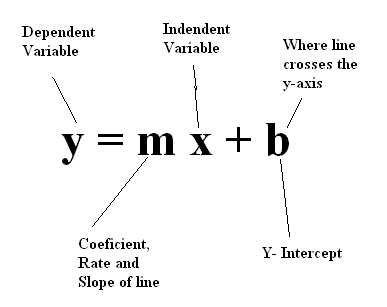
最简单的模型
这是什么概念?与世界上最简单的模型 y = mx + b 做对比,这里有 1 个自变量 x,有 2 个需要优化的参数 m 和 b,需要几个或者几十个样本来优化 m 和 b 的值。而一个 6 年前的深度学习模型里,就相当于有 65 万个 x,6000 万个 m,使用了 100 万个样本来优化参数的值。
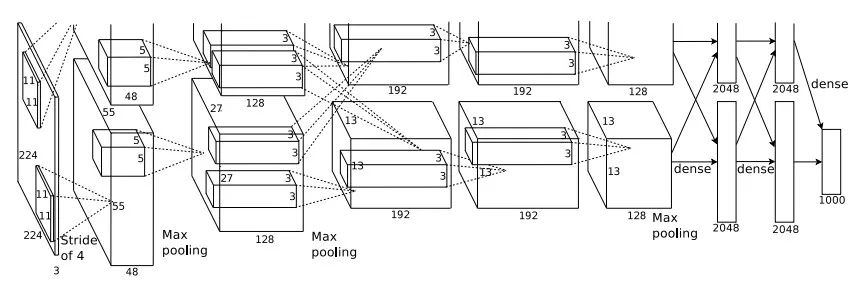
6 年前的神经网络
然而这个模型训练好了之后,仅能分辨它见过的这 1000 类物体。作为对比,人类日常生活中常见的物体至少以万为单位,地球上的物体则以百万为单位。
不仅如此,他还提到了深度学习领域教父级人物 Geoffery Hinton 2017 年的一个观点:卷积神经网络(常用于处理图像的深度学习模型)可能会遭遇「指数低效」并由此走向失败。Hinton 的观点是,识别物体需要模型有捕捉各种转换的能力,虽然处理不变性转换(比如同一物体不同角度的转换)的能力已经在模型中存在了,但如果想要捕捉其他也普遍存在于自然界的转换,则需要在大量扩大模型规模(6000 万参数)和大量增加训练样本数量(100 万张图片)两种方法中至少二选其一——选择的结果是,模型需要的计算量指数上涨。
因此,Marcus 的第一个观点是,以这么铺张浪费的方法进行下去,别说通用人工智能了,就算是专用人工智能也会早早遇到计算的瓶颈而走不下去。
深度学习太「肤浅」:学到的都是表象而不是本质
换句话说就是谴责深度学习「背答案」。
Marcus 的谴责对象有大名鼎鼎的 DeepMind 家会打各种 Atari 游戏的强化学习模型。
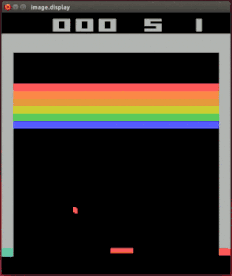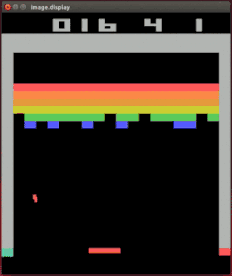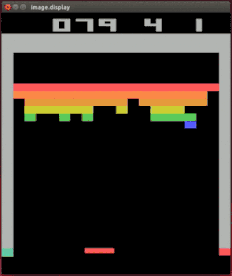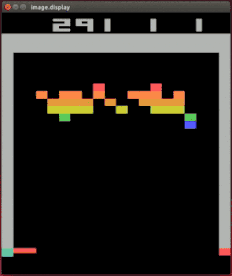
DeepMind 的打砖块达人
Vicarious 的研究者发现,只要稍微改动一点设定,模型立刻就从高手变成连基本规则都不清楚的小白。

a:原版打砖块设定;b:加了一块打了没用的「墙」;c:把一半的砖块变成越打越多的「负砖块」;d:稍微挪动接球拍的高度;e:在砖块两端添加空隙;f:多个球
此外还有一些非常有自嘲精神的学者尝试以子之矛攻子之盾,自己调整数据「攻击」自己的模型。
研究者 Robin Jia 和 Percy Liang 建了 16 个阅读理解问答系统。原本在被问到「谁赢得了超级碗 XXXIII?」时,有 75% 的系统可以在阅读一小段文字后正确回答:John Elway。然而如果在这一段文字里插入「谷歌大神 Jeff Dean 曾经赢得 XX 碗比赛。」这句废话,能正确回答的系统比例锐减到了 36%。
他用这个例子来质疑,所谓「能学习抽象概念」的机器学习模型,是不是在「不懂装懂」呢?
深度学习太「单纯」:挖坑就跳,一骗一个准
最早提出深度学习系统的「可欺骗性(spoofability)」的论文可能是 Szegedy et al(2013)。然而四年过去了,尽管研究活动很活跃,但目前仍未找到稳健的解决方法。
Marcus 举出了更多人类用简单手段给深度学习模型挖坑的例子——甚至都不算是挖坑了,这基本相当于平地摔。
比如有深度学习的图像描述系统将黄黑相间的条纹图案误认为校车:

把 3D 打印的乌龟模型误认为是步枪:

更致命的可能是交通标志错误识别:

一个最新的例子,只要在日常场景里加如一小张带花纹的贴纸,香蕉就会被误认为是烤面包机:
因此,恐怕自动驾驶汽车在上路之前,是不是要先尝试找出上述问题的解决方案,或者,制定完备的应对措施呢?
错的不是深度学习,而是你
在罗列了深度学习模型与通用人工智能之间的种种不可逾越的鸿沟之后,Marcus 话锋一转:其实深度学习的本质就是以概率论为代表的数学,它很有用,但它的底层数学基础限定了它的有用范围:它是数据足够多的封闭式的分类问题的一个几乎完美的答案,但也仅仅是这类问题的答案。
通用人工智能根本就不是这类问题,因此错的不是深度学习,而是对深度学习抱有错误期望的你:你指望一个特别好用的电动螺丝刀帮你锯木头、测电压、量尺寸?
因此 Marcus 这篇长文的真正目的是,谴责媒体和投资人对于 AI 概念的过度炒作并预警:这样的炒作只会带来大量的期望泡沫,而随着时间推移、泡沫破灭,70 年代的人工智能低谷会卷土重来,失望的资金会如同潮水一样离开这个领域。而且这一切已经初现苗头,《连线》杂志最新的文章《自动驾驶步入幻想破灭阶段》,就是一个很好的例子。
他用了一个机器学习中的数学术语描述这一现象,「局部极小值陷阱」。
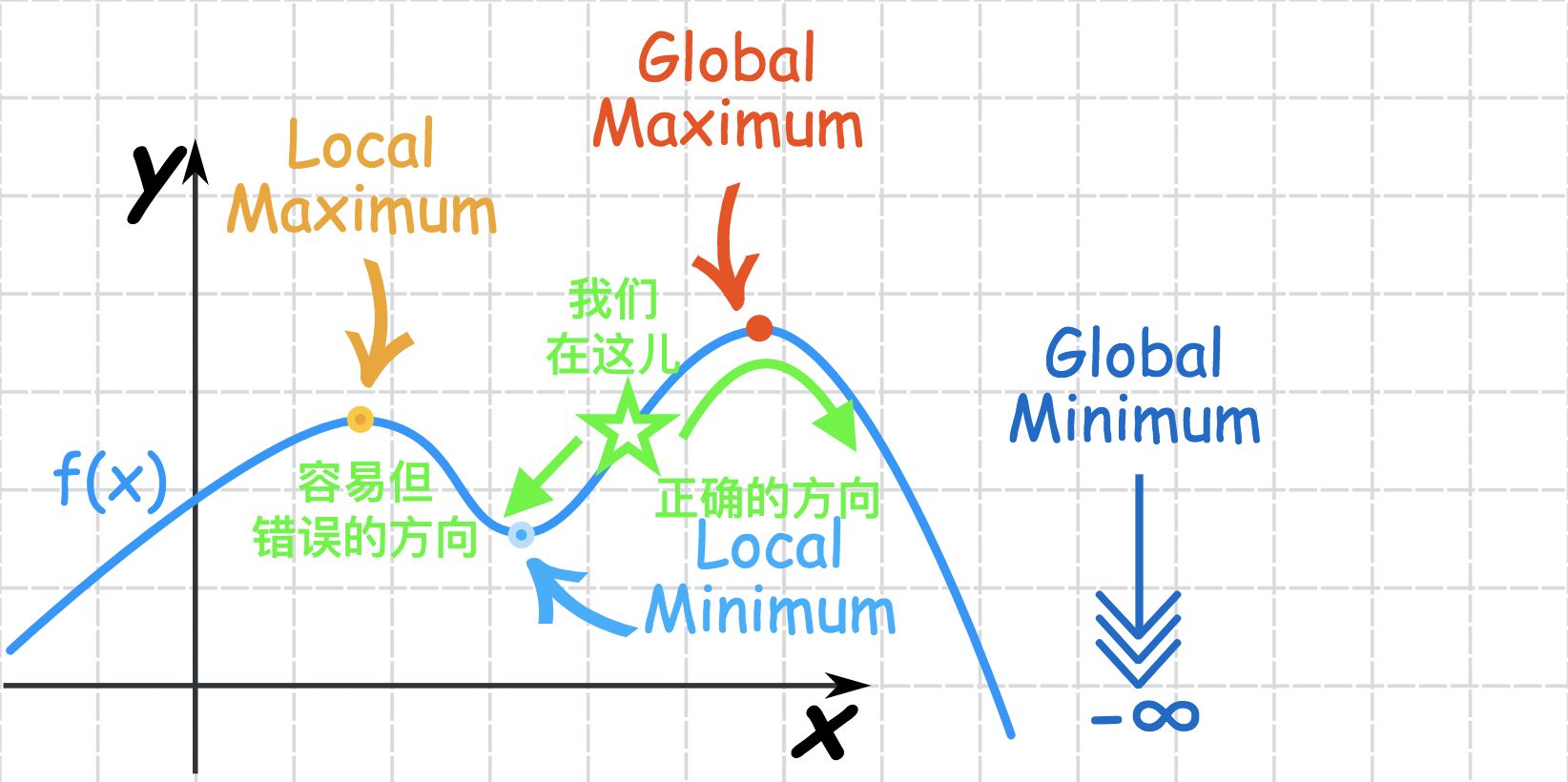
机器学习模型选择最合适的参数的过程,就像在这条弯弯曲曲的函数线上通过小步摸索的办法寻找最小值,路线上有太多看起来像最小值的小坑洼,而真正的最小值只有一个。
我们探索最聪明的 AI 的路径也一样,在起伏的山路上寻找最低点,可山路上充满着看起来像最低点的小坑洼。我们有没有过分沉迷于这样远非最佳的小坑洼呢?有没有过于专注地探索可用但局限的模型、热衷于摘取易于获取的果实,而忽略那些风险很大,但是最终或许可以带来更稳健发展的「小路」呢?
深度学习虽好,但没有那么好。调整过高的预期,转移过分集中的关注点,放平心态不要急于求成,或许才是热潮中的我们应该做的事情。
自动驾驶:、、、、、返回搜狐,查看更多
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK