

深度学习基础 (九)--Softmax (多分类与评估指标) · TesterHome
source link: https://testerhome.com/topics/11262?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

之前一直在学习回归和二分类, 今天记录一下多分类的情况。
Softmax
二分类和多分类其实没有多少区别。用的公式仍然是 y=wx + b。 但有一个非常大的区别是他们用的激活函数是不同的。 逻辑回归用的是 sigmoid,这个激活函数的除了给函数增加非线性之外还会把最后的预测值转换成在【0,1】中的数据值。也就是预测值是 0<y<1。 我们可以把最后的这个预测值当做是一个预测为正例的概率。在进行模型应用的时候我们会设置一个阈值,当预测值大于这个阈值的时候,我们判定为正例子,反之我们判断为负例。这样我们可以很好的进行二分类问题。 而多分类中我们用的激活函数是 softmax。 为了能够比较好的解释它,我们来说一个例子。 假设我们有一个图片识别的 4 分类的场景。 我们想从图片中识别毛,狗,鸡和其他这 4 种类别。那么我们的神经网络就变成下面这个样子的。

我们最后的一层中使用的激活函数就是 softmax。 我们发现跟二分类在输出层之后一个单元不同的是, 使用 softmax 的输出层拥有多个单元,实际上我们有多少个分类就会有多少个单元,在这个例子中,我们有 4 个分类,所以也就有 4 个神经单元,它们代表了这 4 个分类。在 softmax 的作用下每个神经单元都会计算出当前样本属于本类的概率。如下:
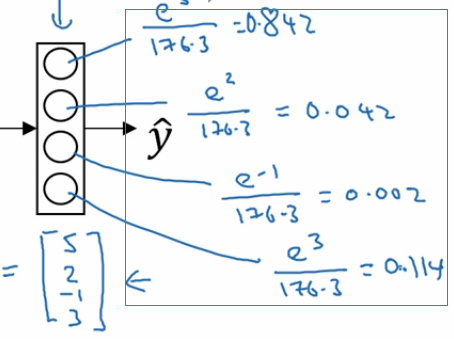
如上图,该样本属于第一个分类的概率是 0.842, 属于第二个分类的概率是 0.042,属于第三个分类的概率是 0.002,属于第四个分类的概率是 0.114. 我们发现这些值相加等于一,因为这些值也是经过归一化的结果。 整个效果图可以参考下面的例子, 这是一个比较直观的图。
Softmax 的损失函数
既然 softmax 的输出变成了多个值,那么我们如何计算它的损失函数呢, 有了损失函数我们才能进行梯度下降迭代并根据前向传播和反向传播进行学习。如下图:
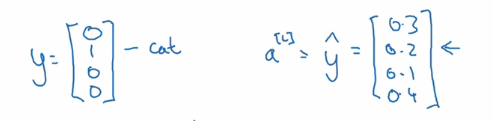
还是假设有 4 个分类,那么实际的预测向量,也会有 4 个维度。 如上图左边的样子。 如果是属于第二个分类,那么第二个值就是 1, 其他值都是 0。 假设右边的向量是预测值, 每个分类都有一个预测概率。 那么我们的损失函数就是。
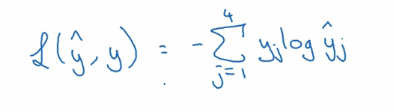
由于实际值得向量只有一个是 1,其他的都是 0. 所以其实到了最后的函数是下面这个样子的
OK,有了损失函数,我们就可以跟以前做逻辑回归一样做梯度下降就可以了。
混淆矩阵和评估指标
我们之前评价二分类的时候有混淆矩阵,AUC 等评估指标。 在多分类中我们同样有这些指标,只不过计算方式略有不同。 就如混淆矩阵。如有 150 个样本数据,这些数据分成 3 类,每类 50 个。分类结束后得到的混淆矩阵为:
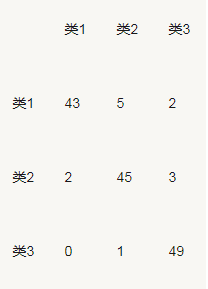
其中第一行说明类 1 的 50 个样本有 43 个分类正确,5 个错分为类 2,2 个错分为类 3。
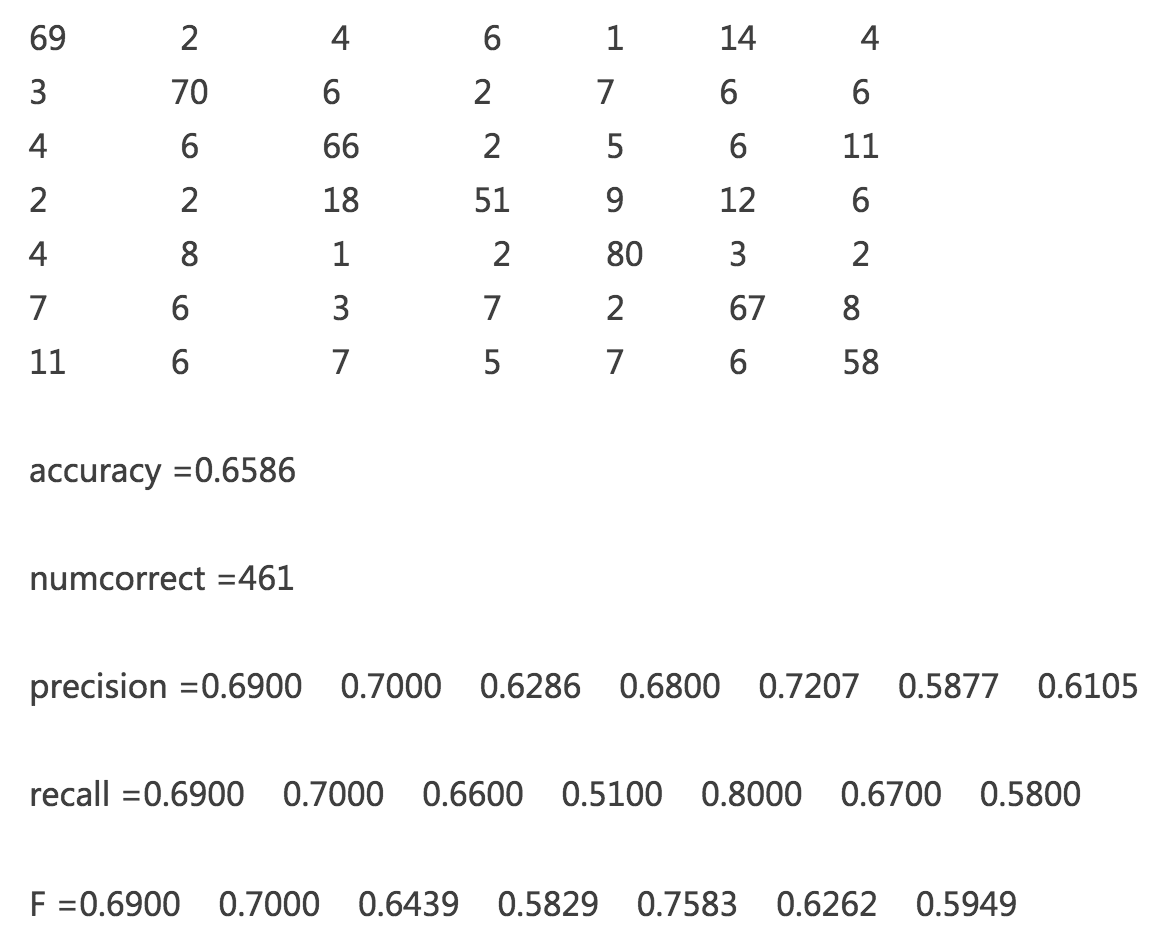
上面是一个 7 分类,有 700 个样本,每类一百个共 700 个样本的混淆矩阵。我们可以通过混淆矩阵计算出准确率,同时也可以计算出每一个分类的召回,精准和 F1 score。
Recommend
-
70
深度学习基础文章合集 · TesterHome TesterHome社区,测试之家,由众多测试工程师组织和维护的技术社区,致力于帮助新人成长,提高测试地位,推进质量发展。Inspir...
-
50
TesterHome软件测试社区,人气最旺的软件测试技术门户,提供软件测试社区交流,测试沙龙。
-
25
作者:吴海波 蘑菇街 整理:Hoh Xil 来源:误入机器学习的码农@知乎专栏 ▌引言 在互联网的排序业务中,比...
-
31
↑↑↑关注后" 星标 "Datawhale 每日干货 &
-
7
假设您的任务是训练ML模型,以将数据点分类为一定数量的预定义类。 一旦完成分类模型的构建,下一个任务就是评估其性能。 有许多指标可以帮助您根据用例进行操作。 在此文章中,我们将尝试回答诸如何时使用? 它是什么? 以及如何实施?
-
8
深度学习分类任务常用评估指标 - 华为云开发者社区的个人空间 - OSCHINA - 中文开源技术交流社区 摘要:这篇文章主要向大家介绍深度学习分类任务评价指标,主要内容包括基础应用、实用技巧、原理机制等方面,希望对大家...
-
16
没有测量就没有科学,同样,机器学习任务也离不开评估指标。评估指标一般来源于对业务的抽象,本文总结分类问题中常用的评估指标。 在机器学习、深度学习中,有不同的任务,大致可以分为分类、 排序、 回归、序列标注(如分词、NER)、序列预测(如时间...
-
4
分析与拓展:多分类模型的输出为什么使用softmax?多分类模型的输出为什么使用softmax?最近在知乎上看到类似的回答,我觉得都没有说到本质上去,都是在回答why之后的side effect。这里给出我认为满意的解释。 数学的语言是最清晰的,这里解释...
-
11
精度可以作为度量模型好坏的一个指标,它表示预测正确的样本数占所有样本数的比例。 但是在实践中,我们通常不仅对精确的预测感兴趣,还希望将这些预测结果用于更大的决策过程 1、 二分类指标 我们先看一下测量精度可能会...
-
12
...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK