

大道至简:这一轮人工智能(AI)突破的原因其实很「简单」
source link: https://www.woshipm.com/ai/6044074.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

大道至简:这一轮人工智能(AI)突破的原因其实很「简单」
大道至简,本文用通俗易懂的语言解释了Transformer的核心原理,对于我们这种没有基础的普通人,也是能快速理解的,也能对当前的大模型有更深入的认识。

过去几年中,人工智能(AI)技术的澎湃发展引领了一场前所未有的工业和科技革命。在这场革命的前沿,以OpenAI的GPT系列为代表的大型语言模型(LLM)成为了研究和应用的热点。
IDC近日发布发布的《全球人工智能和生成式人工智能支出指南》显示,2022年全球人工智能(AI)IT总投资规模为1324.9亿美元,并有望在2027年增至5124.2亿美元,年复合增长率(CAGR)为31.1%。
而带来这一轮人工智能科技革命的技术突破是来自2017年的一篇论文《Attention is All You Need》,在这篇论文中,首次提出了Transformer架构,这个架构是目前大语言模型的核心技术基础。GPT中的T就是Transformer的缩写。
下面,我先带大家简明了解下这个突破性架构的核心原理(原文:What Are Transformer Models and How Do They Work?),其实大道至简,原理没有很复杂,对于我们这种没有基础的普通人,也是能快速理解的,也能对当前的大模型有更深入的认识。
顺便抛出一个问题,为什么这轮技术变革不是来自Google、Meta、百度阿里这样的「传统」AI强势公司,而是初创公司OpenAI引领的呢?

Transformer是机器学习中最令人兴奋的新进展之一。它们首次在论文《Attention is All You Need》中被介绍。Transformer可以用来写故事、论文、诗歌,回答问题,进行语言翻译,与人聊天,甚至能通过一些对人类来说很难的考试!但它们究竟是什么呢?你会高兴地发现,Transformer模型的架构并不复杂,它实际上是一些非常有用的组件的组合,每个组件都有其特定的功能。在这篇博客文章中,你将了解所有这些组件。
这篇文章包含了一个简单的概念性介绍。如果你想了解更多关于Transformer模型及其工作原理的详细描述,请查看Jay Alammar在Cohere发布的两篇出色的文章:
- The illustrated transformer 《图解Transformer》
- How GPT3 works 《GPT3是如何工作的》
简单来说,Transformer都做些什么呢?
想象一下你在手机上写短信。每打一个词,手机可能会推荐给你三个词。例如,如果你输入“Hello, how are”,手机可能会推荐“you”或者“your”作为下一个词。当然,如果你继续选择手机推荐的词语,你会很快发现这些词语组成的信息毫无意义。如果你看看每组连续的三四个词,它们可能听起来有点道理,但这些词并没有连贯地组成有意义的句子。这是因为手机中的模型不会携带整个信息的上下文,它只是预测在最近的几个词之后,哪个词更可能出现。而Transformer则不同,它们能够追踪正在写的内容的上下文,这就是为什么它们写出的文本通常都是有意义的。
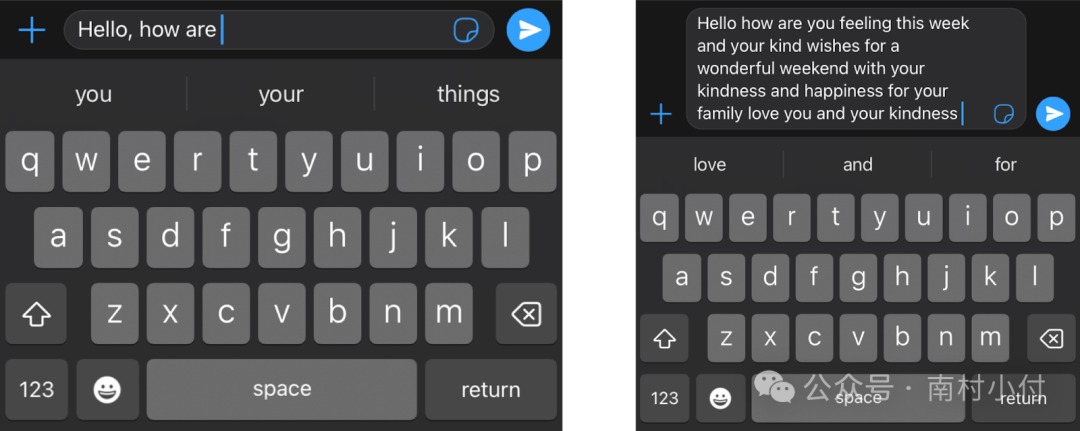
手机可以对短信中使用的下一个单词给出建议,但没有生成连贯文本的能力
我必须得说,当我第一次发现Transformer是一次生成一个词来构建文本的时候,我简直不敢相信。首先,这不是人类形成句子和思想的方式。我们通常先形成一个基本的思想,然后开始细化它,添加词汇。这也不是机器学习模型处理其他事情的方式。例如,图像的生成就不是这样的。大多数基于神经网络的图形模型会先形成图像的粗略版本,然后慢慢细化或增加细节,直到完美。那么,为什么Transformer模型要一词一词地构建文本呢?一个答案是,因为这样做效果非常好。更令人满意的答案是,因为Transformer在跟踪上下文方面实在是太厉害了,所以它选择的下一个词正是继续推进一个想法所需要的。
那么,Transformer是如何被训练的呢?需要大量的数据,实际上是互联网上的所有数据。所以,当你在Transformer输入句子“Hello, how are”时,它就知道,基于互联网上的所有文本,最好的下一个词是“you”。如果你给它一个更复杂的命令,比如说,“write a story.”,它可能会想出来下一个合适的词是“Once”。然后它将这个词添加到命令中,发现下一个合适的词是“upon”,依此类推。一词一词地,它将继续写下去,直到写出一个故事。
命令:Write a story.
回应:Once
下一个命令:Write a story. Once
回应:upon
下一个命令:Write a story. Once upon
下一个命令:Write a story. Once upon a
回应:time
下一个命令:Write a story. Once upon a time
回应:there
现在我们知道了Transformer都做些什么,让我们来看看它的架构。如果你见过Transformer模型的架构,你可能像我第一次看到它时一样惊叹,它看起来相当复杂!然而,当你把它分解成最重要的部分时,就没那么难了。
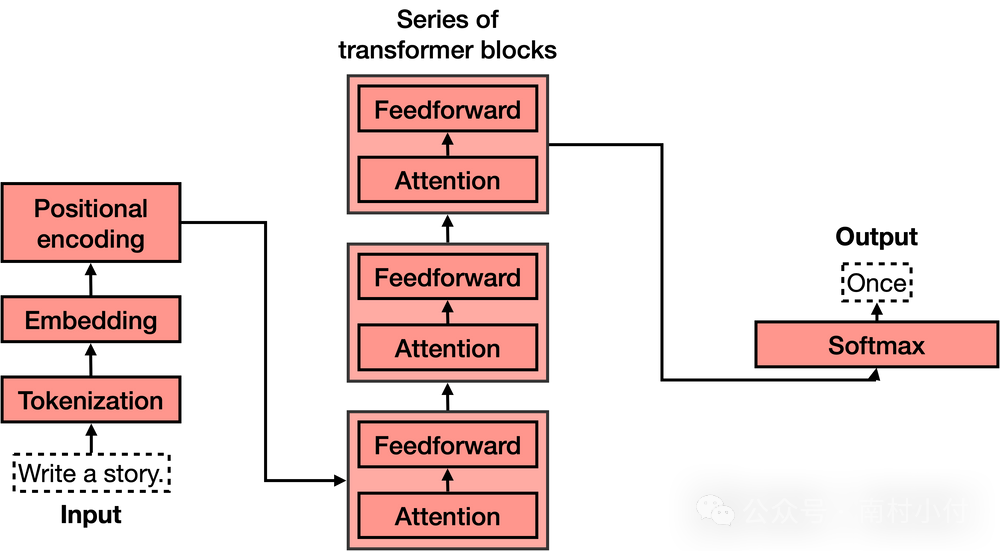
Transformer主要有四个部分:
- 分词(Tokenization)
- 嵌入(Embedding)
- 位置编码(Positional encoding)
- Transformer块(好几个这样的块)
- Softmax
其中,第4个部分,即Transformer块,是所有部分中最复杂的。这些块可以被连在一起,每个块包含两个主要部分:注意力机制和前馈组件。
让我们逐个学习这些部分。
一、Tokenization(分词)
分词是最基本的步骤。它涵盖了一个庞大的词汇库,包括所有的单词、标点符号等。分词步骤会处理每一个单词、前缀、后缀以及标点符号,并将它们转换为词库中已知的词汇。

举例来说,如果句子是“Write a story.”,那么对应的4个token将是<write>,<a>,<story>和<.>。
二、Embedding
一旦输入内容被分词后,就需要将单词转换成机器更容易处理的数字了。为此,我们使用embedding(嵌入)技术。Embedding是任何大型语言模型中最重要的部分之一;它是实现文本与数字转换的桥梁。由于人类善于处理文本而计算机善于处理数字,因此这个桥梁越强大,语言模型就越强大。
简而言之,文本嵌入将每个文本转换为一个向量。如果两个文本片段相似,则其对应向量中的数字也相似(这意味着同一位置上的每对数字都相似)。否则,如果两个文本片段不同,则其对应向量中的数字也不同。
尽管嵌入是数值化的,但我喜欢从几何角度来想象它们。试想一下存在一个非常简单的嵌入方式,可以将每个单词映射到长度为2(即包含2个数值) 的向量上。如果我们按照这两个数值所表示坐标定位每个单词(比如在街道和大道上),那么所有单词都站在一个巨大平面上。在这张平面上,相似的单词会靠近彼此,而不同的单词则会远离。例如,在下面这个嵌入中,“cherry”的坐标是[6,4],与“strawberry” [5,4] 接近但与“castle” [1,2] 相距较远。

在更大的embedding情况下,每个单词都被赋值到一个更长的向量(比如长度为4096),那么这些单词不再存在于二维平面上,而是存在于一个大的4096维空间中。然而,在这个高维大空间中,我们仍然可以认为单词之间有近有远,因此embedding概念仍然具有意义。
词embedding可以推广到文本embedding,包括整个句子、段落甚至更长的文本都会被赋值到一个向量中。然而,在transformer的情形中,我们将使用词嵌入,这意味着句子中的每个单词都会被赋值到相应的向量中。更具体地说,输入文本中的每个token都将被定位到其对应的embedding向量中。
例如,如果我们正在考虑的句子是“Write a story.”并且标记是<write>,<a>,<story>和<.>。那么每个标记都将被赋值到一个向量中,并且我们将有四个向量。

通常embedding将每个单词(token)赋值到一个数字列表中
三、Positional encoding(位置编码)
一旦我们获得了与句子中每个token对应的向量,下一步就是将它们全部转换为一个向量进行处理。将一堆向量转换为一个向量最常见的方法是逐分量相加。
也就是说,我们单独添加每个坐标。例如,如果这些(长度为2)向量分别是[1,2]和[3,4],则它们对应的总和为[1+3, 2+4],即[4,6]。这种方法可以工作,但有一个小细节需要注意:加法满足交换律,也就是说如果你以不同顺序添加相同的数字,则会得到相同的结果。
在这种情况下,“我不难过我很开心”和“我不开心我很难过”两句话将得到相同的向量结果(假设它们具有相同单词但顺序不同)。
这并不好。
因此我们必须想出一些方法来给出两个句子不同的向量表示方式。多种方法可行,在本文中我们选择其中之一:位置编码(Positional Encoding) 。位置编码包括将预定义序列中的一系列向量添加到单词嵌入(embedding) 向量上去,并确保我们获得每个句子都有唯一表示形式且具有相似语义结构、仅单词顺序不同的句子将被分配到不同的向量。在下面的示例中,“Write”、“a”、“story”和“.”所对应的向量成为带有位置信息标签“Write(1)”,“a(2)”,“story(3)”和“. (4)”的修改后向量。
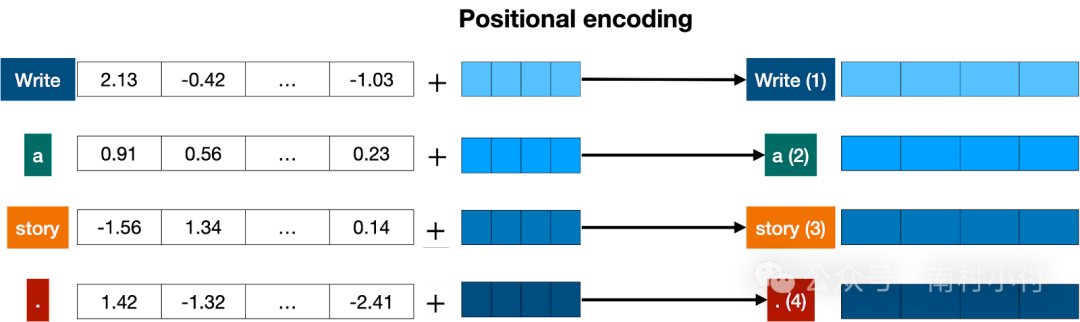
位置编码会为每个单词添加一个位置向量,以便跟踪单词的位置
现在我们知道每个句子都有一个独特的向量,这个向量携带了句子中所有单词及其顺序的信息,因此我们可以进入下一步。
四、Transformer block
让我们回顾一下目前为止的内容。单词被输入并转换成token(分词),然后考虑到它们的顺序(位置编码)。这给了我们每个输入模型的token一个向量。现在,下一步是预测这个句子中的下一个单词。这是通过一个非常大、非常复杂的神经网络来完成的,该网络专门训练用于预测句子中的下一个单词。
我们可以训练这样一个大型网络,但是通过添加关键步骤:Attention(注意力)组件,我们可以极大地改进它。在开创性论文《Attention is All you Need》中引入的注意力机制是Transformer模型的关键成分之一,也是它们如此有效的原因之一。下面将解释注意力机制,但现在先想象它作为一种向文本中每个单词添加上下文的方式。
在前馈网络的每个块中都添加了注意力组件。因此,如果您想象一个大型前馈神经网络,其目标是预测下一个单词,并由几个较小的神经网络块组成,则在每个这些块中都添加了注意力组件。然后,Transformer的每个组件(称为transformer 块)由两个主要组件构成:
- 注意力组件
Transformer是许多Transformer块的串联。
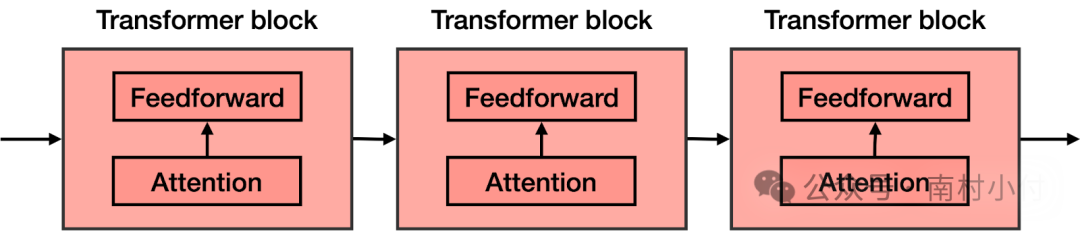
Transformer是许多Transformer块的串联。每个Transformer块由一个注意力组件和一个前馈组件(神经网络)组成。
Attention
Attention步骤涉及一个非常重要的问题:上下文问题。有时,同一个单词可以用不同的意思。这往往会让语言模型感到困惑,因为embedding只是将单词赋值到向量中,而不知道他们使用的单词定义。
Attention是一种非常有用的技术,可以帮助语言模型理解上下文。为了理解Attention的工作原理,请考虑以下两个句子:
句子1:The bank of the river句子2:Money in the bank.
正如您所看到的,单词“bank”在两个句子中都出现了,但含义不同。在第一个句子中,我们指的是河流旁边的土地,在第二个句子中则指持有货币的机构。计算机对此一无所知,因此我们需要以某种方式将这些知识注入其中。什么能帮助我们呢?好吧,似乎句子中其他单词可以拯救我们。对于第一个句子,“the”和“of”这些单词对我们没有任何作用。但是,“river”这个单词让我们知道正在谈论河流旁边的土地。同样,在第二个句子中,“money”这个单词让我们明白“bank”的意思现在是指持有货币的机构。

Attention有助于根据句子(或文本)中的其他单词为每个单词提供上下文
简而言之,注意力机制的作用是将句子(或文本片段)中的单词在词嵌入中靠近。这样,在句子“Money in the bank”中,“bank”一词将被移动到“money”的附近。同样,在句子“The bank of the river”中,“bank”一词将被移动到“river”的附近。这样,两个句子中修改后的单词“bank”都会携带周围单词的某些信息,为其添加上下文。
Transformer模型中使用的注意力机制实际上更加强大,它被称为多头注意力。在多头注意力中,使用了几个不同的嵌入来修改向量并为其添加上下文。多头注意力已经帮助语言模型在处理和生成文本时达到了更高的效率水平。如果您想更详细地了解注意力机制,请查看这篇博客文章及其相应视频。
五、The Softmax Layer
现在你已经知道一个transformer是由许多层transformer块组成的,每个块都包含一个attention和一个feedforward层,你可以将它看作是一个大型神经网络,用于预测句子中的下一个单词。Transformer为所有单词输出分数,其中得分最高的单词被赋予最有可能成为句子中下一个单词的概率。
Transformer的最后一步是softmax层,它将这些分数转换为概率(总和为1),其中得分最高对应着最高的概率。然后我们可以从这些概率中进行采样以获取下一个单词。在下面的例子中,transformer给“Once”赋予了0.5的最高概率,并给“Somewhere”和“There”赋予了0.3和0.2 的概率。一旦我们进行采样,“once”就被选定,并且那就是transformer 的输出结果。
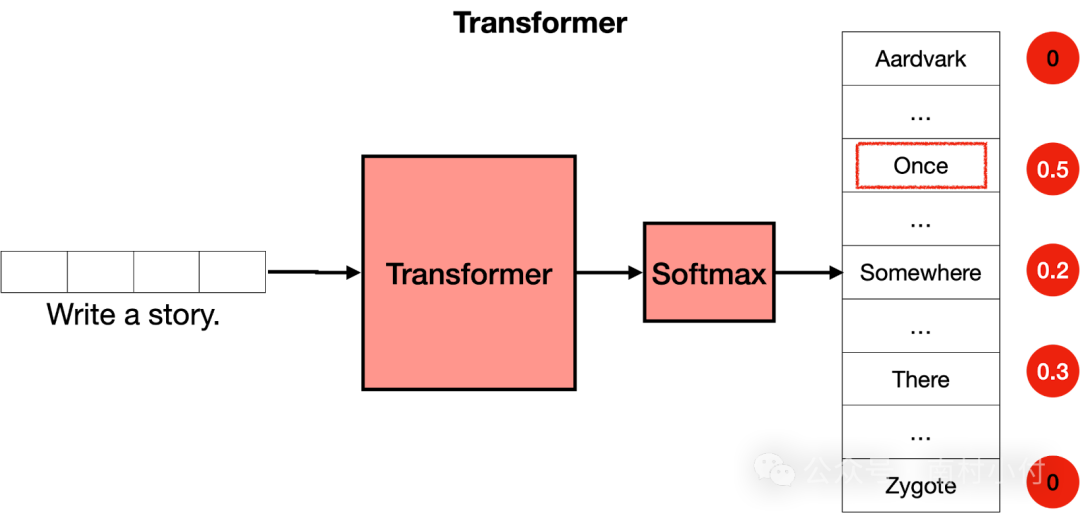
softmax层将分数转换为概率,这些概率用于选择文本中的下一个单词
现在怎么办?
我们只需要重复这个步骤。现在我们将文本“Write a story. Once”输入模型中,很可能输出结果是“upon”。再次重复此步骤,Transformer最终会写出一个故事,例如:“Once upon a time, there was a …”(“从前有一天,有一个……”)。
Summary总结
在这篇文章中,您已经学习了transformers的工作原理。它们由几个块组成,每个块都有自己的功能,共同工作以理解文本并生成下一个单词。这些块如下:
- Tokenizer:将单词转换为token。
- Embedding:将token转换为数字(向量)。
- Positional encoding:在文本中添加单词顺序。
- Transformer block:猜测下一个单词。它由注意力块和前馈块组成。
- Attention:为文本添加上下文信息。
- Feedforward:是Transformer神经网络中的一个模块,用于猜测下一个单词。
- Softmax函数: 将得分转换为概率以便采样出下一个单词。
重复执行这些步骤就可以写出您所看到的transformers创建的惊人文本。
Post Training(后期训练)
现在你已经知道了Transformer是如何工作的,但我们还有一些工作要做。
想象一下:你扮演Transformer,“阿尔及利亚的首都是什么?” 我们希望它回答“阿尔及尔”,然后继续进行。然而,这个Transformer是在整个互联网上训练出来的。互联网很大,并不一定是最好的问题/答案库。例如,许多页面会列出长长的问题列表而没有答案。
在这种情况下,“阿尔及利亚的首都是什么?”之后的下一个句子可能会是另一个问题,比如“阿尔及利亚人口数量?”,或者“布基纳法索首都在哪里?”。Transformer不像人类那样思考他们的回应,它只是模仿它看到过(或提供过)数据集中所见到内容。
那么我们该怎样使Transformer回答问题呢?
答案就在于后期训练。
就像您教导一个人完成某些任务一样,您可以让Transformer执行任务。一旦将Transformer训练成整个互联网上使用时,则需要再次对其进行大量数据集培训以涉及各种问题和相应答案。Transformer(就像人类一样)对他们最后学到的事情有偏见,因此后期训练已被证明是帮助Transformer成功完成所要求任务的非常有用的步骤。
后期训练还可以帮助处理许多其他任务。例如,可以使用大量对话数据集来进行Transformer的后期培训,以使其作为聊天机器人表现良好,或者帮助我们编写故事、诗歌甚至代码。了解更多
如上所述,这是一个概念性的介绍,让您了解transformers如何生成文本。如果您想要深入了解transformer背后的数学原理,请观看以下视频(YouTube)。写在最后
正如你所看到的,Transformer的架构并不复杂。它们是由几个块连接而成,每个块都有自己的功能。它们之所以能够工作得如此出色,主要原因在于它们具有大量参数,可以捕捉上下文中许多方面的信息。我们很期待看到您使用Transformer模型构建什么!
最后,你知道为什么这轮技术变革不是来自人工智能强大的Google或者Facebook,而是来自像OpenAI这样的初创公司呢?
本文由人人都是产品经理作者【南村小付】,微信公众号:【南村小付】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。
Recommend
-
63
前言 之前几个项目中,都多多少少碰到一些组件之间需要通信的地方,而因为种种原因, event bus 的成本反而比vuex还高, 所以技术选型上选用了 vuex, 但是不知道为什么, 团队里的一些新人一听到vuex,就开始退缩了, 因为vuex 很难? 真的很
-
60
-
29
上海居住证转户口的两条路线和一个常见陷阱
-
23
来源:科技日报人们经常说“一孕傻三年”,是指生完孩子后,很多妈妈确实变得有些“傻”。做事丢三落四,转头就忘要做的事情。而有的妈妈如果加上怀二胎,“傻”的时间和状况似乎还要严重一些。这“一孕傻三年”到底是一种夸张的说法,还是确实有它的科学依据
-
18
由 NASA 引领的小型化风潮已经席卷了整个消费电子产品产业。现在,一个领针中即可保存全部贝多芬作品,并可使用耳机聆听。 ———天体物理学家、科学评论员 Neil deGrasse Tyson ……超低功耗嵌入式设备的普及,以及用于...
-
8
大道至简--简单与复杂数据结构之间的性能PK2013-03-01事情源起阿里巴巴的一道笔题.题目大概是要求统计<圣经>中的各个单词出现的次数,按单词首次出现的顺序输出结果.本来没什么技术含量的题,随便用个kv容器都很容易统计单词次数,然后...
-
12
入职快要一个月了,由于工作比较忙,基本上都没有时间写博客了;所以就趁着封培的晚上比较闲,说一下最近的一些体会吧! WLB看似简单,其实很难!WLB指的是,work-life-balance,即:工作生活相互平衡的一种状态; 刚...
-
42
学会这几招,其实取消交易也可以很简单 ...
-
6
Android屏幕常亮功能其实很简单 – Android开发中文站 你的位置:Android开发中文站 > Android开发 >
-
10
安徽中科星联获新一轮融资,加速人工智能技术在智慧农业、数字乡村等领域落地 作者:麦乐迪 发布时间: 2023-06-30 13:30
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK