

一键换装神器爆火,老黄换上抱抱脸T恤,CEO本人:我被替代了,和他争CEO职位争不过
source link: https://www.qbitai.com/2024/04/138127.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一键换装神器爆火,老黄换上抱抱脸T恤,CEO本人:我被替代了,和他争CEO职位争不过

马斯克奥特曼也都来参加“时装秀”
西风 发自 凹非寺
量子位 | 公众号 QbitAI
笑不活,最新虚拟试穿神器被网友们玩坏了。
黄院士、马斯克、奥特曼、史密斯等一众大佬衣服集体被扒。
前有老黄卸下皮衣套上糖果包装袋:

后有奥特曼大秀花臂穿CUCCI:
再有老马变成了蛛蛛侠:

好莱坞巨星史密斯也风格大变:

但说回研究本身,确实正儿八经的研究。

名为IDM–VTON,由来自韩国科学技术院和OMNIOUS.AI公司的研究团队基于扩散模型打造。

目前官方放出了demo,大伙儿可以试玩,推理代码已开源。
除了开头所展示的,抱抱脸研究员也玩的不亦乐乎,给老黄换上了专属战袍。其CEO连忙转发打趣:
我被替代了,没法和他争CEO。
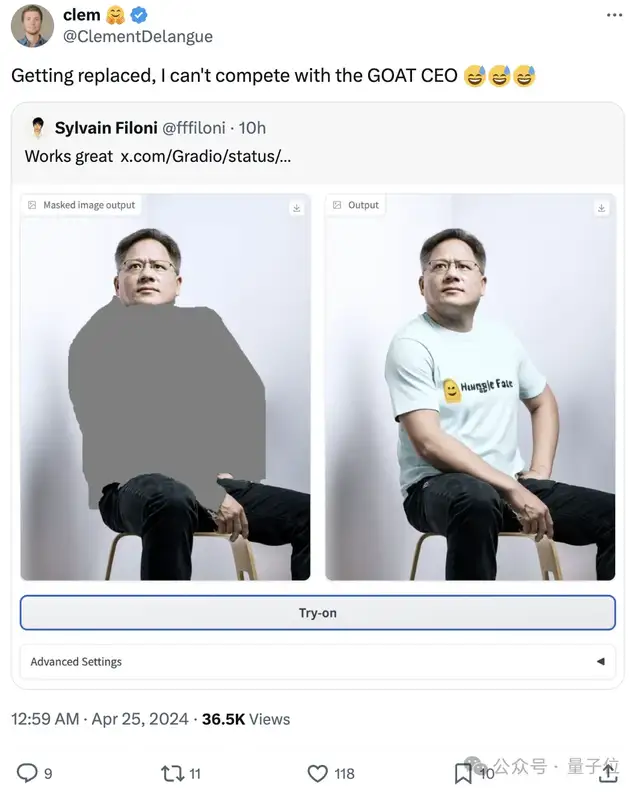
看热闹的网友也是感慨,经过这么多年,终于不用再担心自己“手残”了(AI帮你搞定)。

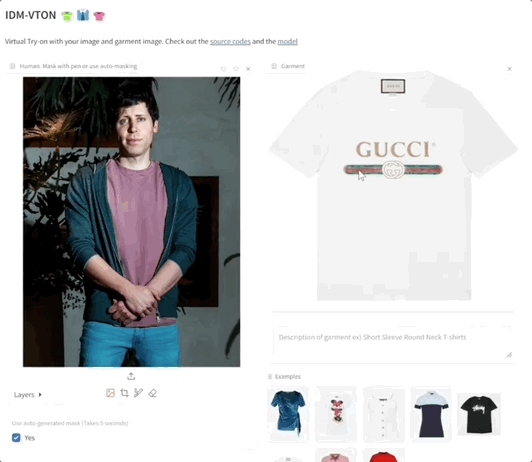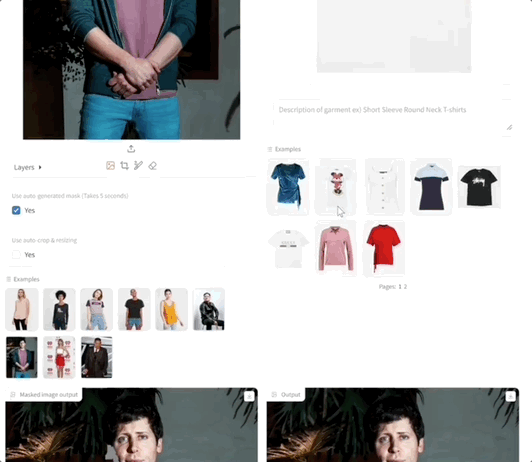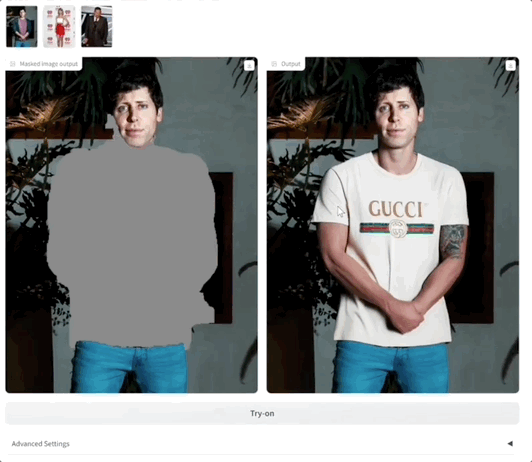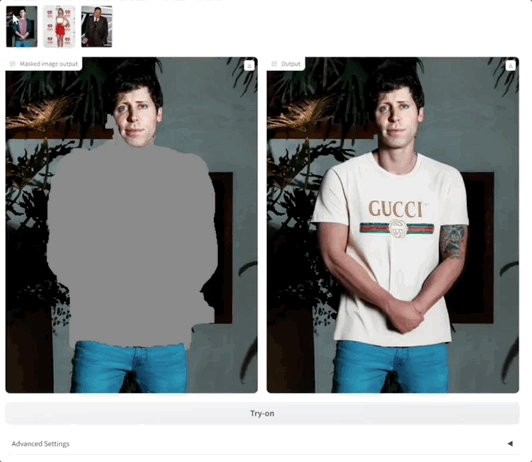
我们也赶紧上手体验了一把。demo整个页面是这样婶儿的:
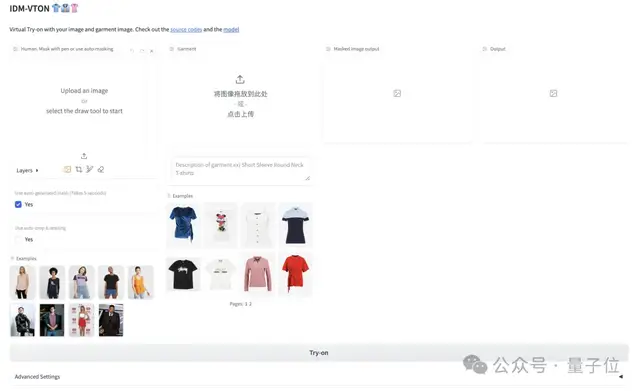
操作起来也是非常简单。
首先上传人物图,可以手动或者自动选择要修改的区域。然后,上传要换的衣服。
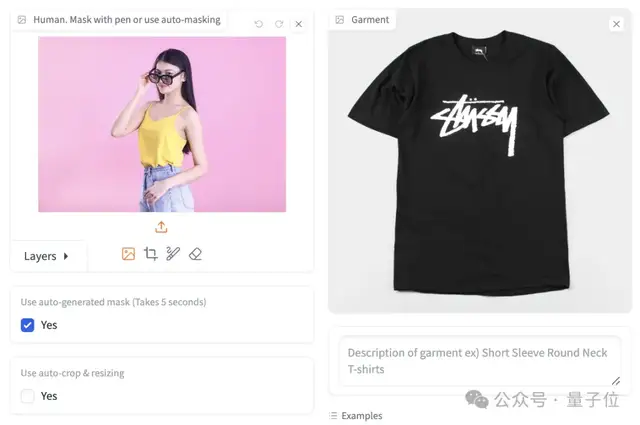
直接点击Try-on,会自动生成掩模图和换装后的图:
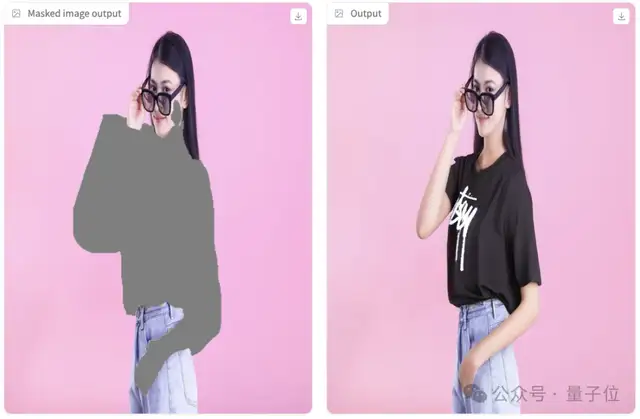
上面这张自动生成的掩模把手也选进去了,所以最后生成的左手效果不好。
我们手动选取涂抹一下,同时人和衣服全部都用我们自己的图。
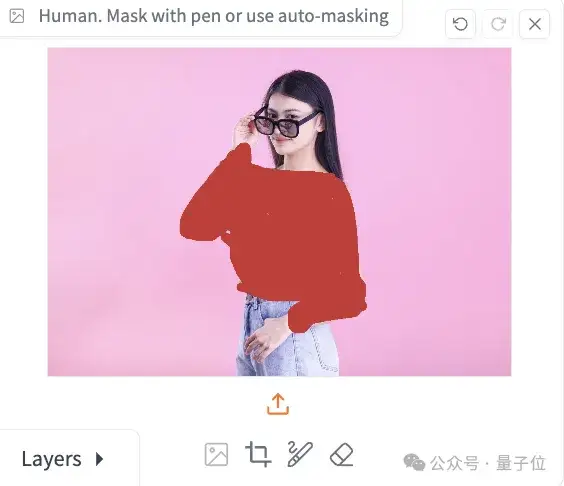

这次效果大伙儿觉得如何?
再来展示一波网友的试玩成品图。
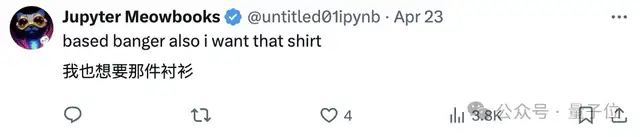
DeepMind联合创始人苏莱曼穿上了微笑面具修格斯联名款T恤:

甚至不少网友真想要这件衣服。
奥特曼再次被网友当成模特:
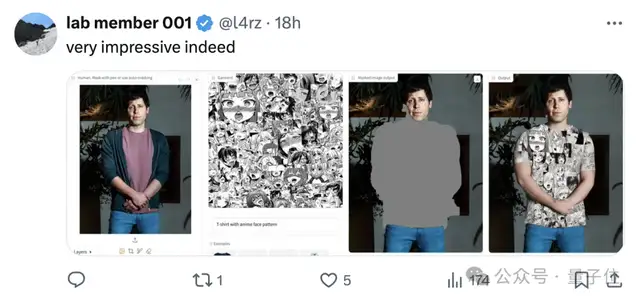
当然也有翻车的时候,比如马斯克穿的就是山寨CUCCI。

看完效果后,接着来看IDM–VTON在技术上是如何实现的。
基于扩散模型
技术方面,IDM–VTON基于扩散模型,通过设计精细的注意力模块来提高服装图像的一致性,并生成真实的虚拟试穿图像。
模型架构大概包含三部分:
- TryonNet:主UNet,处理人物图像。
- IP-Adapter:图像提示适配器,编码服装图像的高级语义。
- GarmentNet:并行UNet,提取服装的低级特征。
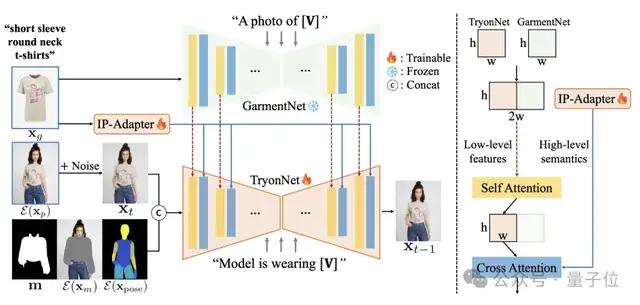
在为UNet提供输入时,研究人员将人物图片的含噪声潜在特征、分割掩模、带掩蔽的图片和Densepose数据整合在一起。
他们还会为服装添加详细描述,例如[V]表示“短袖圆领T恤”。这个描述随后用作GarmentNet(例如,“一张[V]的照片”)和TryonNet(例如,“模特正在穿[V]”)的输入提示。
TryonNet和GarmentNet产生的中间特征进行了合并,随后传递至自我注意力层。研究人员只使用了来自TryonNet的输出的前半部分。这些输出与文本编码器和IP-Adapter的特征一起,通过交叉注意力层进行融合。
最终,研究人员对TryonNet和IP-Adapter模块进行了精细调整,并锁定了模型的其它部分。
实验阶段,他们使用VITON-HD数据集训练模型,并在VITON-HD、DressCode和内部收集的In-the-Wild数据集上进行评估。
IDM–VTON在定性和定量上都优于先前的方法。






IDM-VTON可以生成真实的图像并保留服装的细粒度细节。
更多细节,感兴趣的家人们可以查看原论文。
项目链接:
[1]https://idm-vton.github.io/?continueFlag=589fb545dbbb123446456b65a635d849
[2]https://arxiv.org/abs/2403.05139
[3]https://huggingface.co/spaces/yisol/IDM-VTON?continueFlag=589fb545dbbb123446456b65a635d849
参考链接:
[1]https://twitter.com/multimodalart/status/1782508538213933192
[2]https://twitter.com/fffiloni/status/1783158082849108434
[3]https://twitter.com/ClementDelangue/status/1783179067803533577
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK