

Fine tune LLAMA3 on million scale dataset in consumer GPU using QLora, DeepSpeed
source link: https://medium.com/@sumandas0/fine-tune-llama3-on-million-scale-dataset-in-consumer-gpu-using-qlora-deepspeed-3ae8ad75299a
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Fine tune LLAMA3 on million scale dataset in consumer GPU using QLora, Deepspeed
Highlights,
Model : LLAMA-8b-instruct
Dataset: Openhermes-2.5(700k training, 300k testing)
GPU: 4 RTX 4090, 24GB
Bit of background about me,
I’m a full-time software engineer 2, at the core of our platform team. In my scarce free time, I explore various aspects of the machine learning world, with interests in tabular data, NLP, and sound. Whatever I’m sharing here are scraps from all over the internet consolidated into one place. I have decent experience in training small NLP models and have submitted a solution in a Kaggle competition using DeBERTa v3, scoring enough to be in the top 50%, but I have never tried working with large language models. This is my first time, so please let me know if there are any oversights. Yes, this is my first blog post. Writing this will definitely help me, and hopefully, it will be useful for any readers as well
LLama
Who don’t know about this long necked creature revolutionizing the AI field from its birth. Joke apart release of llama where the whole OSS powered LLM kicked of the revolution which don’t seems like stopping in near future.
To learn more on llama in depth and technical do checkout this Post | LinkedIn , this is one of the most technically simplified explanation I can found all over the internet. Few things they implemented in their architecture like Grouped Multi Query Attention, KV-Cache, Rotary Positional Embeddings(RoPE) which are very cool. These are not in scope of this article. They continued releasing their versions of LLama with latest version came few days ago. And this time with massive data compacted into few GBs of parameters.
Meta Unveils Llama 3–10 Key Facts About The Advanced LLM (forbes.com)
Deepspeed
DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective.
I will be training this model using four RTX 4090 GPUs that I’ve rented from vast.ai, so we need to take some steps to train the models across multiple GPUs. Training on multiple GPUs is a complex task compared to training on a single GPU. Why? When we train on a single GPU, the Optimizer state, parameters and gradients reside in a single system, which helps iterating over models on one GPU.
Now, if we add another GPU, there are two systems that will train the models, each with its own state(Optimizer state, parameters and gradients). After one epoch or several steps, we would like to obtain a single result. Now imagine two systems training two batches of data in parallel; they need to communicate about their state and converge the results with minimal data loss. There are multiple ways to utilize multiple GPUs: we can replicate parameters, gradients, and optimizer state across all GPUs, or we could shard only the optimizer state, or the optimizer state and gradients. DeepSpeed helps in distributing the load over the GPUs without any issues. And accelerate package from Huggingface lets us do this like its piece of cake.
I will use stage 3 which will shard all parameters, gradients and optimizer state which will let us training over less memory requirement,
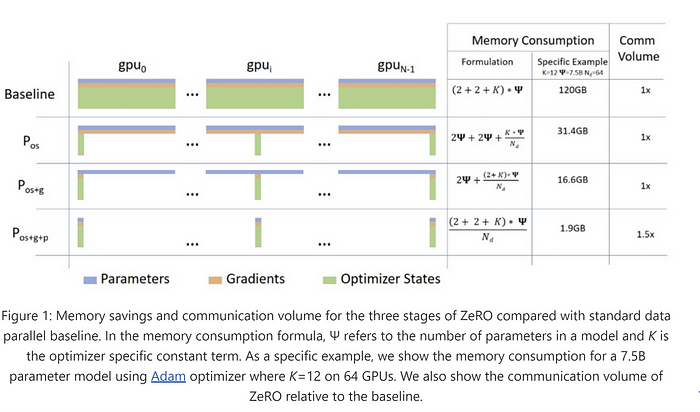
More details in their blog, ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters — Microsoft Research
QLoRA
Until I write something about QLoRA, please take a look into this blog to get more technical context What is QLoRA? | QLoRA — Weights & Biases (wandb.ai), basically 70B/8B models are very large in size means when you fine tune it you will not be able to fully fine tune with any GPU in normal people’s budget, so we tried to fine tune it with very low resource and came LoRA which helped us just training over parameters with low rank and merging them with original weights, then came QLoRA which helped even more reducing memory consumption by quantizing the pre trained LLM to 4 bit precision, quantizing is a topic in itself so not going beyond this.
Also take a look into this article LoRA Fine-tuning & Hyperparameters Explained (in Plain English) | Entry Point AI
Lets start finetuning LLamA 3
We will be finetuning the llama3 instruct model meta-llama/Meta-Llama-3–8B-Instruct · Hugging Face over openhermes dataset provided by teknium.
Data preparation
Meta has their own chat format so tried to follow the format they provided and read their encoding algorithm in their llama3 repository,
Load the dataset
from datasets import load_dataset
dataset = load_dataset("teknium/OpenHermes-2.5")
The encoding utility I took inspiration from llama3 repo,
def _return_header(message)-> str:
role = message["from"]
header = ""
if role == "system":
header = "system"
elif role == "gpt":
header = "assistant"
elif role == "human":
header = "user"
return header
def encode_header(message):
text = ''
text = text + "<|start_header_id|>"
header = _return_header(message)
text = text + header
text = text + "<|end_header_id|>"
text = text + "\n\n"
return text
def encode_message(message)->str:
text = encode_header(message)
text = text + message["value"].strip()
text = text + "<|eot_id|>"
return text
def encode_dialog_prompt(dialog):
text = ''
text = text + "<|begin_of_text|>"
for message in dialog:
text = text + encode_message(message)
return text
ds = dataset.map(lambda x: {"content":encode_dialog_prompt(x['conversations'])}, num_proc=10)
Remove redundunt columns and split it into train and validation
ds = ds.remove_columns(['custom_instruction', 'topic', 'model_name', 'model', 'skip_prompt_formatting', 'category', 'conversations', 'views', 'language', 'id', 'title', 'idx', 'hash', 'avatarUrl', 'system_prompt', 'source'])
train_test_split = ds["train"].train_test_split(test_size=0.3)
And push it to hub,
train_test_split.push_to_hub("sumandas/openhermes-2.5-llama3")
The resultant dataset, sumandas/openhermes-2.5-llama3 · Datasets at Hugging Face, example text
<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are an AI assistant. Provide a detailed answer so user don’t need to search outside to understand the answer.<|eot_id|><|start_header_id|>user<|end_header_id|> Instructions: Given a sentence, generate what should be the most likely next statement. The next statement should be reasonable and logically correct. Input: The screen is full of white bubbles and words, while a pair of hands plays the piano. The bubbles and words disappear and it Output:<|eot_id|><|start_header_id|>assistant<|end_header_id|> Output: becomes apparent that the hands are creating a visual representation of the music being played, captivating the audience with this unique sensory experience.<|eot_id|>
Now its time for training LLama3
All of the resources were already available in internet I just fine tuned those for my setup and requirements,
Prerequisites,
- Install cuda dev kit
conda install cudaor follow developer.nvidia.com/cuda-downloads?target_os=Linux - Install deepspeed
- Install flash-attention pip install flash-attn — no-build-isolation
- Install these libraries, I use uv for faster dependency resolution,
git+https://github.com/huggingface/transformers
git+https://github.com/huggingface/accelerate
git+https://github.com/huggingface/peft
git+https://github.com/huggingface/trl
huggingface-hub
bitsandbytes
evaluate
datasets
einops
wandb
tiktoken
xformers
sentencepiece
deepspeed
torch==2.2.2
Training code
This is Swiss knife training code where you can train in multiple mode as per you convenience, found this in this repo pacman100/LLM-Workshop: LLM Workshop by Sourab Mangrulkar (github.com),
The
training.pyfile is the one we will launch using accelerate with proper configs, just putting the training.py gist here, https://gist.github.com/sumandas0/0483db8514ea43e45cc5e5f5525914ab
This training code uses SFTTrainer from huggingface, more details Supervised Fine-tuning Trainer (huggingface.co)
You can do multiple thing with this, you can train with loftq, unsloth, FFT, normal lora but I will just use QloRa with Deepspeed ZerO stage 3.
First lets define the accelerate config for using deepspeed
Note, If you increase the number of GPU update number in num_processes
Now lets just run the accelerate command to start training,
accelerate launch --config_file "deepspeed_config.yaml" train.py \
--seed 100 \
--model_name_or_path "meta-llama/Meta-Llama-3-8B-Instruct" \
--dataset_name "sumandas/openhermes-2.5-llama3" \
--chat_template_format "none" \
--add_special_tokens False \
--append_concat_token False \
--splits "train,test" \
--max_seq_len 2048 \
--num_train_epochs 1 \
--logging_steps 5 \
--log_level "info" \
--logging_strategy "steps" \
--evaluation_strategy "epoch" \
--save_strategy "steps" \
--push_to_hub \
--hub_private_repo True \
--report_to "wandb" \
--hub_strategy "every_save" \
--bf16 True \
--packing True \
--learning_rate 1e-4 \
--lr_scheduler_type "cosine" \
--weight_decay 1e-4 \
--warmup_ratio 0.0 \
--max_grad_norm 1.0 \
--output_dir "llama3-openhermes-2.5" \
--per_device_train_batch_size 4\
--per_device_eval_batch_size 4\
--gradient_accumulation_steps 2 \
--gradient_checkpointing True \
--use_reentrant True \
--dataset_text_field "content" \
--use_flash_attn True \
--use_peft_lora True \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.1 \
--lora_target_modules "all-linear" \
--use_4bit_quantization True \
--use_nested_quant True \
--bnb_4bit_compute_dtype "bfloat16" \
--bnb_4bit_quant_storage_dtype "bfloat16"
Notes,
- Set env variable HF_HUB_ENABLE_HF_TRANSFER=1 first
- output_dir will also be the repo created in huggingface where all the checkpoints will be stored, checkpoints will be created every 500 steps by default
- I set chat template format as
none, because I already formatted those in my way, if you have other format do use for e.g chatml, zephyr lora_target_modulesis set as all-linear which is QLoRa specific where they published paper to show fine tuning all linear layers gives us comparable result to full fine tune.- For setting up hyperparameters for LoRa, take a look into this awesome blog LoRA Fine-tuning & Hyperparameters Explained (in Plain English) | Entry Point AI
- Set up WANDB_API_KEY=<key> if you are reporting to wandb else remove
report_to='wandb'
This should be it and your training should be running in full force, look for GPU utilization.
Observation
Ran the fine tuning for only 1 epoch, took around 15 hours. Loss curve

fig: training loss train/loss (24/04/25 02:44:11) | huggingface — Weights & Biases (wandb.ai)
WandB summary
{
"train/learning_rate": 0.00004551803455482833,
"eval/steps_per_second": 0.893,
"_wandb.runtime": 51487,
"_runtime": 51480.36651659012,
"_timestamp": 1713698971.6200776,
"train/epoch": 1.0571428571428572,
"train/grad_norm": 0.14189070214353952,
"train/global_step": 8325,
"eval/samples_per_second": 7.141,
"_step": 1665,
"eval/loss": 0.963840126991272,
"train/loss": 0.9674,
"eval/runtime": 7532.9797
}
Last steps,
After the finetuning what model you will get is small adapter model not full model that you can just start using just now, we need to add the adapter to the original meta llama3 weights,
Load PEFT adapter model,
from peft import PeftModel
from transformers import AutoModelForCausalLM
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct",torch_dtype=torch.bfloat16, device_map="auto")
adapter_model = PeftModel.from_pretrained(base_model, "sumandas/llama3-openhermes-2.5")
adapter_model.merge_and_unload()
Now save the adapter model into hf,
adapter_model.push_to_hub("sumandas/llama3-openhermes-2.5")
Inference
import torch
import transformers
from transformers import pipeline
pipe = pipeline("text-generation", model="sumandas/llama3-openhermes-2.5",model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda")
generate_kwargs = {
"do_sample": True,
"temperature": 0.7,
"max_new_tokens": 35,
}
pipe("<|begin_of_text|><|start_header_id|>user<|end_header_id|> Describe the food of Thailand<|eot_id|><|start_header_id|>assistant<|end_header_id|>",max_length=2048)
Response,
Thai cuisine is a blend of bold flavors and aromatic ingredients that create a harmonious balance of sweet, sour, salty, bitter, and spicy taste. The food in Thailand varies between different regions, but some common ingredients found throughout include rice, noodles, vegetables, herbs, and spices. Rice is a staple of Thai cuisine and is served with almost every meal, whether it is stir-fried, boiled, or used to make congee or fried rice. Noodles, made from rice or wheat, are also very popular and can be found served with various broths, sauces, and toppings in many Thai dishes. Thai food is known for its use of fresh herbs and spices such as lemongrass, galangal, coriander, basil, kaffir lime leaves, ginger, and garlic, which give the dishes their distinct flavors. Thai chilies are also widely used to add varying levels of heat to the food. Some popular Thai dishes include Tom Yum soup (hot and sour soup with lemongrass, kaffir lime leaves, and chilies), Pad Thai (stir-fried rice noodles with vegetables, peanuts, and a tangy sauce), and green curry (a spicy curry made with green chilies, coconut milk, and Thai basil). Many Thai dishes are also accompanied by a variety of sauces and condiments, including fish sauce, soy sauce, chili paste, and tamarind sauce. Fresh fruits like mango, papaya, and pineapple are also commonly enjoyed as a sweet ending to a meal. Overall, Thai food is a vibrant and flavorful cuisine that combines traditional ingredients and cooking techniques with a balance of flavors that tantalize the taste buds.<|eot_id|>
Do send my model and dataset some love if it has any worth :)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK