

大模型推理优化技术之显存优
source link: https://dingfen.github.io/2023/11/30/2023-11-30-LLM-KVCache/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
大模型推理优化技术之 KV Cache
推理大模型时充分榨干 GPU 的性能是每个程序员所追求的。不过,要做到这一点,我们首先需要知道大模型推理的具体步骤,并分析它的性能瓶颈是什么,是受到算力限制还是内存限制,从而方便我们下一步的优化。而目前业内认为 LLM 模型的推理性能主要受限于内存。
KV Cache 是大模型推理性能优化的最常用技术。该技术可以在不影响计算精度的前提下,以空间换时间,提高推理性能。目前业界主流 LLM 推理框架均默认支持并开启了该功能。在咱们之前介绍 huggingface llama 实现的博客中有提到过,当 use_cache = True 时,KV cache 功能就默认打开。那么什么是 KV cache 呢?它又是如何加速大模型推理性能的呢?
要尝试理解 KV cache,就不得不提及当前大模型的一般推理过程。事实上,目前大多数热门的 LLM (例如 GPT-3)的推理部分本质上是一个译码器(decoder)。它们针对输入的序列文本,一个词一个词地输出文本。具体地说,这些 LLM 接受一系列 token 作为输入,并以自回归方式输出后续的 token,直到它们满足条件要求(例如,已达到生成的 token 数量或遇到停止词),或直到它生成特殊的标记标志着生成过程的结束。此过程涉及两个阶段:预填充阶段(prefill phase)和译码阶段(decode phase)。
所谓 token 实际上描述模型中未被转化成人类语言的序列文本,参见下面的解释:
tokens are the atomic parts of language that a model processes. One token is approximately four English characters. All inputs in natural language are converted to tokens before inputting into the model.
预填充阶段
在预填充阶段,LLM 处理输入 token 以计算 transformer 架构中 decoder 的 Key 和 Value 矩阵,此时 decoder 参与计算的 Query 矩阵为空(随机数)。根据 transformer 的计算过程(读者可参考网上海量介绍 transform 的文章),这些矩阵用于输出第一个 token。然后,每个新 token 都依赖于之前的所有的 token,但由于输入是完全已知的,因此从高层次看,这是一个可高度并行的矩阵运算,能充分发挥 GPU 的利用率。
在译码阶段,LLM 一次自回归生成一个输出 token,直到满足条件为止。每个连续输出 token 都需要知道先前迭代的所有输出 key 和 value。此时 Query 的序列长度是 1,而 key 和 value 的长度则是之前产生的所有输出长度,这就像是矩阵向量运算,与预填充阶段相比,它未充分利用 GPU 计算能力。GPU 的处理速度受限于数据(权重、键、值、激活)从内存传输到计算单元的速度。因此,这是个内存限制的运算阶段。
注意,不同的 LLM 可能会使用不同的 tokenizer ,而不同的 tokenizer 产生的 token 数量和其代表的含义也有区别。若要比较它们之间的输出 token 也并不简单。而我们容易犯的一个谬误是:在比较推理吞吐量时,直接观察单位时间内产生的 token 数量。然而,即使两个 LLM 的每秒输出 token 相似,但如果它们使用不同的 tokenizer,那么它们真实的推理性能可能不相同。这是因为两者的 token 可能表示不同数量的字符。
再回顾一下 transformer 中计算注意力权重的过程:
Attn=softmax(QKTd)V Attn = softmax(\frac{QK^T}{\sqrt{d}})V Attn=softmax(dQKT)V
decoder 的输入在进入译码层后,就会分别经过 query key value 三个线性层,变为 Q K V 矩阵,然后进入 Masked multi head attention 做下图的运算。图中的 mask 是为了防止当前生成的 token 根据未来 token 的信息产生。

注意到,Transformer 模型具有自回归推理的特点,即每次推理都会将上次推理输出的结果作为输入的一部分,而每次推理会输出下一个 token,反复执行多次后得到最终的输出。因此,推理时,Transformer 的前后两轮的输出只相差一个 token,存在重复计算!
比如,图上例子中,若不使用 KV cache 技术,在推理生成“学”和“生”字时,前三行的 QK 矩阵和注意力矩阵的值都是一样的。以第一行为例,注意力矩阵的向量值取决于 Q 矩阵的第一行(K V 咱不关心)。每次计算得到的注意力矩阵向量,只有最后一行是全新的,用于产生新的 output。
因此,KV Cache 的办法就是将之前已经计算过的张量保存下来,下次推理时直接计算一行 Q 矩阵就行了,前面的数据可以直接使用之前保存的张量,避免重复计算。
KV cache 技术已经应用在 huggingface transformer 库中:代码如下:
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
if layer_past is not None:
past_key, past_value = layer_past
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
present = (key, value)
else:
present = None
if self.reorder_and_upcast_attn:
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
else:
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
PYTHON准备好 query key 和 value 矩阵后,当 layer_past 非空(事实上第一个词生成后就是非空的),那么直接将 past_key 和 past_value 取出,然后concat连接起来组成这次推理的 key 和 value 值。
KV cache 可在内存空间充足的场景下使用,能有效地提升推理性能。但需要注意的是,如果生成的序列非常长(大于 2048 )那么就很有可能出现 out of Memory。都说 LLM 训练和推理时内存开销巨大,那么到底有多大呢?程序员该如何快速评估一个 LLM 推理时大致需要消耗多少内存?
内存开销粗算
粗略地看,LLM 在 GPU 上推理时,有两样东西占用了最多的内存空间:
- 模型权重:模型参数占用内存。以 Llama-2-7b 为例(70 亿参数),通常使用 FP16 加载时,那么显存大小约为 70 亿 × 2 字节(FP16)= 14 GB。
- KV cache:被缓存起来的自注意力张量。现在我们粗略计算一下 KV cache 占用的内存大小。首先,每一个 transformer 子层都含有一层注意力层,每层注意力都需要一个 KV cache,KV cache 中一个向量的维度是
hidden_size。再考虑batch_size和seq_len,每个输出的 token 都需要这样的 KV cache,而 GPU 通常会同时并行处理batch_size个这样的输入/输出,于是有:
KV cache size per token = 2 * batch_size * seq_len * num_layers * hidden_size * sizeof(data_type)
第一个系数为 2 表示了 Key 和 Value 矩阵。以之前博客中的 llama-2-7b 的配置文件为例:
{
"architecture": ["LlamaForCausalLM"],
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 11008,
"max_position_embeddings": 4096,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 32,
"pretraining_tp": 2,
"rms_norm_eps": 1e-05,
}
当执行的输入 batch 大小是 2,输入序列的长度为 512 时,即输入 token 矩阵维度是 (bsz, seq_len, hidden_size) = (2, 512, 4096) ,权重数据类型为 FP16 时:
KV Cache 大小 = 2 * batch_size * seq_len * num_layers * hidden_size * sizeof(data_type) = 2 * 2 * 512 * 32 * 4096 * 2 = 512 MB
额,遗憾的是,512 MB 大小已经不能称之为 Cache 了,这样大小的缓存显然无法放进当前任何一款显卡的 L2/3 Cache 中。现在英伟达最好的卡 H100 的 SRAM 缓存大概是 50MB,而 A100 则是 40MB,差的可不是一点半点。所以,我们对 KV Cache 的优化还未止步。
KV Cache 的推理优化
回到之前我们给出的公式:
KV Cache Size = 2 * batch_size * seq_len * num_layers * hidden_size * sizeof(data_type)
上面的公式中,batch_size 取决于用户输入,而 num_layers 和 hidden_size 是架构的基本(擅自改动会影响模型表现),那么针对 KV cache 的进一步优化就只能从以下四方面入手:
- kv_heads:MQA/GQA 技术,减少 KV 的头数,进而减少显存占用
- seq_len: 通过减少序列长度, 以减少 KV Cache 大小,如使用循环队列管理窗口 KV
- KV-Cache:从操作系统的内存管理角度,减少碎片,如 Paged Attention
- data type: 从量化角度减少 KV cache 的宽度,如使用 LLM-QAT 进行量化
接下来,我们简要地介绍一下这四项优化技术。
GQA/MQA 优化技术
在 transformer 中,最原始的是 MHA(Multi-Head Attention),Query Key Value 三部分有相同数量的头,并一一对应。每次做注意力计算,每个头的这三个矩阵按上文所述的公式计算完成后,将所有头的结果拼接起来就行(见下图右上部分)。
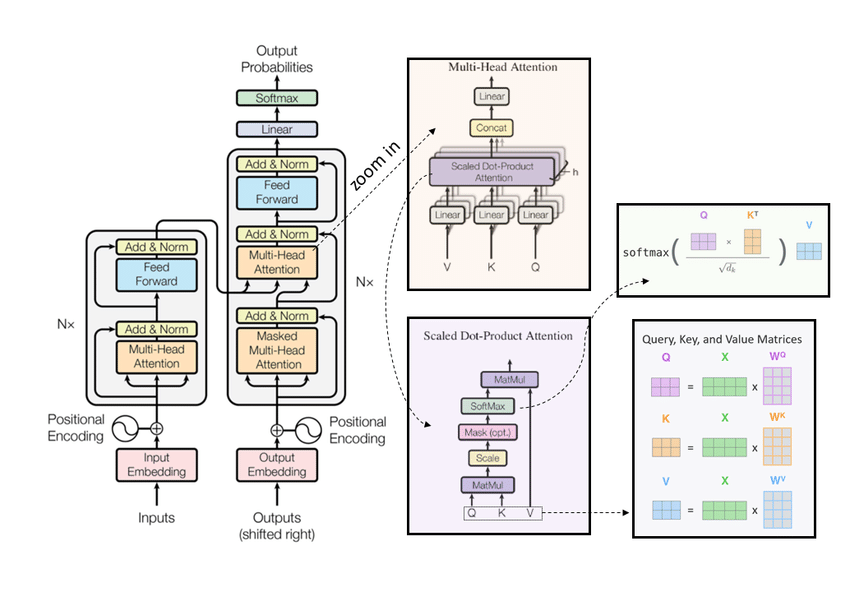
MQA(Multi Query Attention) 对此提出的改进是:保持 Query 的头数,但 Key 和 Value 只能有一个头,相当于所有的 Query 矩阵共享一组 Key 和 Value 矩阵。直观来看,这的确大幅减少了 KV Cache 大小,而实验结果表明,这样改进能提高 30%-40% 的吞吐,却只会稍微影响模型效果,具体可参看 Llama2 论文。

Table 18: Attention architecture ablations. We report 0-shot results for all tasks except MMLU(5-shot) and GSM8K(8-shot). For GSM8K and Human-Eval we report maj@1 and pass@1 results. For NQ and TriviaQA we report EM. For all other tasks we report accuracy.
由于 MQA 改变了注意力机制的结构,因此模型通常需要从训练开始就支持 MQA 。也可以通过对已经训练好的模型进行微调来添加多查询注意力支持,仅需要约 5% 的原始训练数据量就可以达到不错的效果。包括 Falcon、SantaCoder、StarCoder 等在内很多模型都采用了 MQA 机制。
GQA(Grouped Query Attention)是一种介于 MHA 和 MQA 的折中方案。它将 Query Heads 分组,并在每组中共享一个 Key 和 一个 Value,使得 GQA 既能缩小 KV Cache ,加快推理速度,又不会损失过多的模型效果。Llama2 采用了 GQA 机制。

序列长度优化
仔细观察 LLM 推理时计算注意力的方式:token 的输出是串行的,上一个 token 的 Key 和 Value 可以被下一个 token 复用。若推理的文本很长(远长于训练时最长序列),那么我们可以牺牲模型的效果,舍弃掉过于久远的 token 以减少 KV Cache 的大小。另外,这也可以降低计算量,自注意力的时间复杂度是 token 序列的 $ \mathcal{O}(N^2)$(因为是 $ QK^T $,其中 $ Q $ 和 $ K $ 的矩阵维度都是 seq_len)。至于舍弃的方式,又有几种不同的实现手段:
-
固定窗口长度及其变种。如 Longformer,该方法实现简单:在注意力机制下,仅计算每个单词的前 w 个单词的注意力,其余单词对应的 Key 矩阵为零。每个单词仅计算前 w 个单词,类似于一个长 w 的窗口在序列上滑动(左二图)。于是空间复杂度被限制到了窗口最长大小上。此外,它还有很多变种,Dilated 滑动窗口间隔地计算单词注意力;Global 滑动窗口会间隔地计算单词的全局注意力,以尽可能消除对实验精度的影响。虽然实验表明该方法不论在时间和空间上相对原先的自注意力都有明显提升,但该方法对精度的影响较大。更多精彩内容可参加它的论文和相关博客。

-
带有 KV 重计算的滑动窗口。该方法需要每次计算都重新计算从当前位置倒数 L 长度 token 序列的 KV 张量,但重计算的复杂度是 $ \mathcal{O}(NL^2) $ 。由于重计算的存在,其精度可以保证,也能节省空间,但是性能提升就不明显了。
-
箭型注意力窗口。该方法在 LM-Infinit 和 StreamingLLM 中均有提及。起因是大家发现了有趣的注意力下沉现象,即保持初始 token 的 KV 将在很大程度上恢复固定窗口后的注意力效果。于是,在窗口注意力的基础上,初始 token 的 KV 将被保留,从而在图上形成了一个“箭型”的注意力窗口。更多精彩内容可参考相关论文和博客。

PageAttention 优化
vLLM 提出的 Paged Attention 技术从显存管理的角度出发,通过允许非连续的内存空间存储 KV cache 的方式高效地计算注意力。其灵感来自于操作系统中虚拟内存和分页的思想。
通常,我们会采取批处理的方式完成深度学习模型的推理:同时处理 batch_size 个输入序列,从而更高效地利用了内存带宽,提高 GPU 利用率。然而,该传统的批处理方法不太适用于 LLM,因为它非常不灵活。前文提到,LLM 推理是迭代地输出一个个 token ,且每次输出产生多少 token 完全依赖于用户输入。于是批处理时会出现这样的情况:某些输入已经提前完成“回答”,产生了所有输出 token,但某些还在继续输出 token,见下右图。由于传统批处理方法非常不灵活,在最后一个序列未完成前,无法释放这些批处理的占用内存资源。于是,图中所示 GPU 在批次的处理中有很多内存空间和时间未被充分利用(序列1、3和4的序列末标记后的白色方块)。
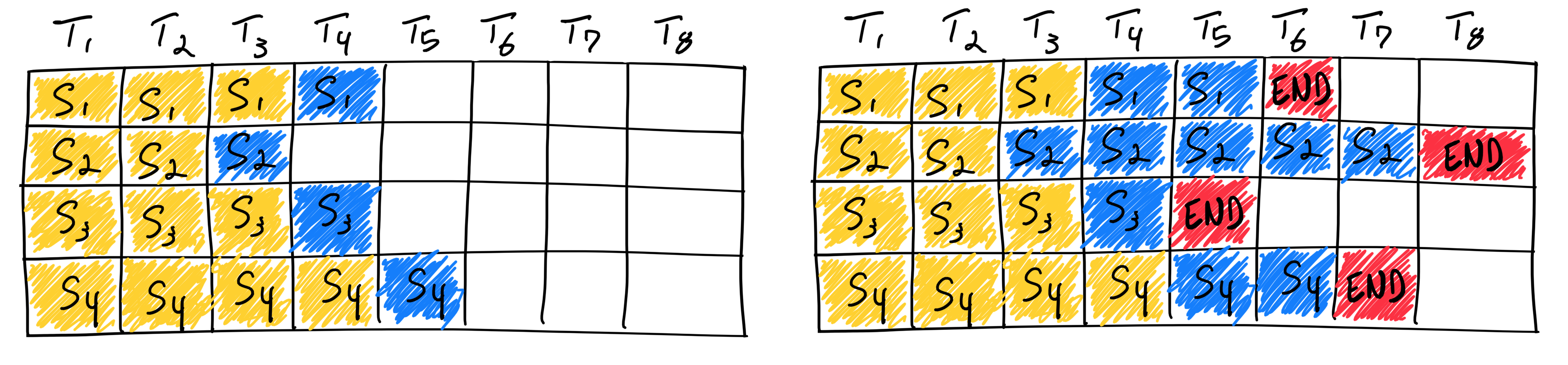
题外话,ORCA 这篇论文
也注意到了这一点,并认为是不灵活的批处理调度机制导致了这一问题:只要通过细粒度的调度机制将这些“白块”补齐了就行。于是,他们提出了迭代层级的批处理调度方式(iteration-level scheduling)和选择性批处理(selective batching),让基于 FasterTransformer 的 GPT-3 175B 延迟和吞吐量都提高了约 37 倍。
Paged Attention 将 KV cache 分割到不同的固定大小的“页”上。然而,这也意味着,关于 KV cache 的分配是 just-in-time 的,而不是提前预分配好的:当开始新一轮 token 生成时,框架不能分配固定大小的连续 cache 给 KV 张量。相反,在每次迭代开始前,调度器都可以决定是否需要为这一轮迭代动态地分配内存空间。
一旦我们将 KV cache 的分配类比到操作系统中对内存的分配,我们就可以将 KV cache 内的每个固定长度的块当作虚拟内存中的页,token 可以看作字节,每个生成序列看作进程。通过一个映射表可将连续的逻辑块映射到非连续的物理块,而物理块可以根据新生成的 token 按需分配:
上图的 gif 清晰地展示了生成 token 的过程,逻辑 KV cache 是连续的,当它被填满后会重新分配一个物理 KV 块来存放新的 token。在分块之后,只有最后一个块可能会浪费内存。这么做的好处很明显:系统可以在一个batch中同时输入更多的序列,提升GPU的利用率,显著地提升吞吐量。
paged Attention 的另一个好处是高效内存共享。例如,在并行采样的时候,一个输入序列(prompt)需要生成多个输出序列。这种情况下,对于这个输入序列的计算和内存可以在输出序列之间共享。
通过块表可以自然地实现内存共享。类似进程之间共享物理页,在 Paged Attention 中的不同序列通过映射便可实现共享。为了确保安全共享,Paged Attention 跟踪物理块的引用计数,并实现了 Copy-on-Write 机制。 内存共享减少了 55% 内存使用量,大大降低了采样算法的内存开销,同时提升了 2.2 倍的吞吐量。
更多关于 Paged Attention 的相关细节和用法,可参考他们的论文与开源工程
该类方法从数据类型入手,充分利用每一个 bit。通过量化与稀疏压缩 KV cache 的显存消耗。
当前主流推理框架都在逐步支持 KV cache 量化,一个典型的案例是 lmdeploy
本篇博客从大模型推理的过程出发,重点讲了 KV Cache 的原理与实现,粗略罗列了针对 KV Cache 的若干优化方法。大模型还在快速发展迭代,本博客也将实时更新。
为完成本篇博客,本人学习参考了许多知乎文章、外文博客和相关论文(相关链接都在文中以超链接的方式给出)。我在此一并感谢这些文章的作者们,是他们的辛勤劳作、共享传播和源码开放推动了 AI 领域的蓬勃发展。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK