

联想万全异构智算平台发布:集成五大技术创新,突破计算效率瓶颈
source link: http://www.dostor.com/p/87353.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
联想万全异构智算平台发布:集成五大技术创新,突破计算效率瓶颈-存储在线
在4月18日,以“AI for All,让世界充满AI”为主题的联想创新科技大会(2024 Lenovo Tech World)上,联想重磅发布了联想万全异构智算平台。该平台集成了联想为满足AI应用大潮所打造的五大技术创新,为AI 2.0时代大模型训练和推理构建稳定高效的基础设施底座。
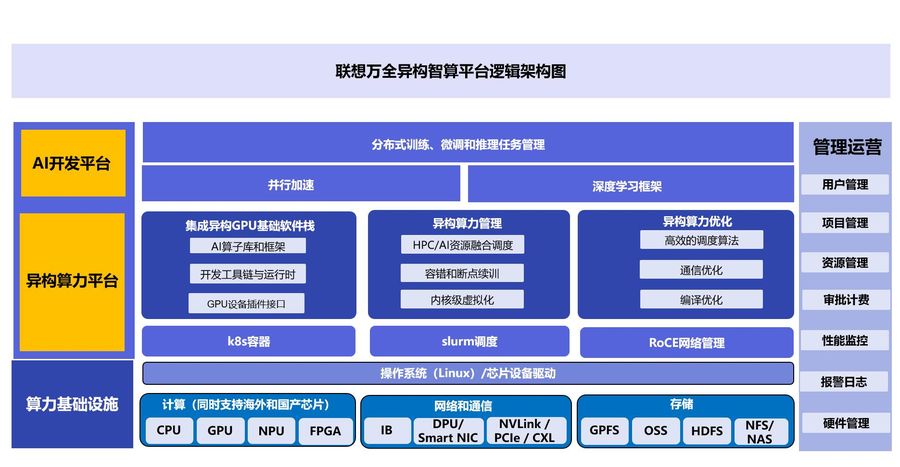
当前,以大模型为基础特征的AI 2.0时代已经到来,“大模型+大算力+大数据”成为新一代人工智能发展的基本范式。然而,智能计算较通用计算的投入成本、技术门槛更高,广大用户需要一个新的计算开发和管理平台,能够集成算力管理与调度,数据治理与模型优化、训练精调和推理应用开发等多层次的能力,为使用者提供更简单、更高效、更稳定的算力体验。
联想万全异构智算平台应运而生,其差异化价值在于能够以创新技术突破计算效率瓶颈。对于用户而言,异构智算平台能够帮助用户提高应用部署速度,降低业务TCO(全周期使用成本)。在基础设施层面,它能够提升算力利用率和可用性。
据介绍,联想万全异构智算平台是一个能高度自动化完成AI全流程开发的平台,可输出高可用算力并不断突破计算效率瓶颈的利器。用户可自动完成AI计算并发布模型或发布推理服务。此外,平台也为专业的AI开发用户留有手动深入调整计算过程的空间,包括工具和模型的选择,算力配置的调整,对任务的定制化监控等。
此外,联想万全异构智算平台集成了算力匹配魔方、GPU内核态虚拟化、联想集合通信算法库、AI高效断点续训技术、AI与HPC集群超级调度器,这五大创新技术,这五大技术从不同方面帮助用户解决问题。
算力匹配魔方:为用户跳过繁杂的算力选择和验证。
基于海量的硬件评测和AI算子算法集成工作,联想构建了AI场景与算法与集群硬件三者匹配关系的算力魔方知识库,来标识AI场景、算法、集群配置这三者的匹配关系。针对不同场景,可以全自动规划和调度最佳算法和集群配置,用户只需输入场景和数据,即可自动加载最优算法和调度最佳集群配置。
GPU内核态虚拟化:挖掘处理器潜力,让vGPU利用率从80%提升到95%。
在AI推理和中小训练中,子任务通常以虚拟GPU进行承载,业界目前普遍在操作系统层以用户态对GPU做虚拟化,而用户态虚拟化因不能对GPU做深层控制,会造成虚拟算力不稳定,调度开销大等问题,从而造成近20%的算力损耗。
为此,联想研究院开发了在GPU驱动层的内核态虚拟化算法。该算法具备三大革新:一是对算力和显存精准隔离的算法能以<3%的误差精准控制容器资源。二是在GPU驱动层做资源调度,去掉在驱动之上不必要的操作。三是在GPU驱动层将虚拟GPU的颗粒度精细到1%。新算法可以将虚拟化造成的GPU算力损耗降到5%以下,极致情况可以降到1%以下,大幅提升GPU利用率。
联想集合通信算法库:突破集群计算瓶颈,使训练效率提升10%—15%。
在大规模的AI集群中,性能释放的最大瓶颈受制于网络通信慢。网络通信慢会导致GPU空闲等待,计算效率降低。针对大规模集群网络通信瓶颈的挑战,联想万全异构智算平台能自动感知集群网络拓扑,并选择和采用经联想增强的集合通信算法使数据传输在最佳路径。以千卡规模集群为例,采用集成了联想集合通信库的联想万全异构智算平台做管理调度,可使网络通信效率提升超10%,并且集群规模越大,效果越显著。
AI高效断点续训技术:实现分钟级AI断点续训,让AI集群持续可用。
据统计,目前千卡集群每月至少有15次的故障断点。在常规的断点续训手段下,每次恢复训练需要几个小时,产生的额外费用超过百万元。联想万全异构智算平台针对故障特征来对数据做多级备份,大幅精简了备份数据量,同时令备份数据从最佳路径被提取。同时,对大量的AI训练故障进行了特征采样,基于AI故障特征库,开发了预测AI训练故障的AI模型,实现“用AI来预测AI”。此外,联想万全异构智算平台集成了从服务器BMC,存储管理,网络OS的硬件监控,到调度器故障监控,再到对AI训练收敛程度的监控,对AI故障的抓取能够做到万无一失。
由此三大革新,联想能将断点续训恢复时间缩减到分钟级,大幅提升了训练效率。以千卡集群为例,联想每月可节约上百万元算力费用支出,让宝贵的AI算力持续可用。
AI与HPC集群超级调度器:破局算力孤岛,1小时内自动完成跨集群资源调度和共享。
对于有些同时拥有AI和HPC算力的用户,希望能在不同集群间,根据任务优先级和资源状况,充分共享利用GPU节点。然而,由于AI和HPC集群的调度方式完全不同,用户在不同集群间共享资源时,既要通晓两种调度方法,又要付出大量操作,导致无法实现资源共享。
联想AI与HPC超级调度器架构的精髓之处就是做出能指挥双类型调度的最精简架构,在AI的K8S调度和HPC的Slurm调度之上,能够切换AI和HPC的调度沟通,能全局监控任务和动态共享资源,使得用户可以充分利用基础设施的每一分算力。

联想集团副总裁、中国基础设施业务群总经理陈振宽表示,“联想万全异构智算平台”是AI 2.0时代联想中国基础设施战略框架的核心。未来联想将挑战超过万卡规模集群的通信算法优化,挑战秒级的断点续训,深入研究相变式液冷技术,布局模块化液冷数据中心,助力联想AI算力朝着更强大、更稳定、更高效和更绿色的方向实现高质量发展。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK