

GPT4单项仅7.1分,揭露大模型写代码三大短板,最新基准测试来了
source link: https://www.qbitai.com/2024/03/132007.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
GPT4单项仅7.1分,揭露大模型写代码三大短板,最新基准测试来了

多团队联合出品
DevBench团队 投稿
量子位 | 公众号 QbitAI
首个AI软件工程师Devin正式亮相,立即引爆了整个技术界。
Devin不仅能够轻松解决编码任务,更可以自主完成软件开发的整个周期——从项目规划到部署,涵盖但不限于构建网站、自主寻找并修复 BUG、训练以及微调AI模型等。
这种 “强到逆天” 的软件开发能力,让一众码农纷纷绝望,直呼:“程序员的末日真来了?”
在一众测试成绩中,Devin在SWE-Bench基准测试中的表现尤为引人注目。
SWE-Bench是一个评估AI软件工程能力的测试,重点考察大模型解决实际 GitHub 问题的能力。
Devin以独立解决13.86%的问题率高居榜首,“秒杀”了GPT-4仅有的 1.74%得分,将一众AI大模型远远甩在后面。
这强大的性能让人不禁浮想联翩:“未来的软件开发中,AI将扮演怎样的角色?”
上海人工智能实验室联合字节跳动SE Lab的研究人员以及SWE-Bench团队,提出了一个新测试基准DevBench,首次揭秘大模型在多大程度上可以从PRD出发,完成一个完整项目的设计、开发、测试。
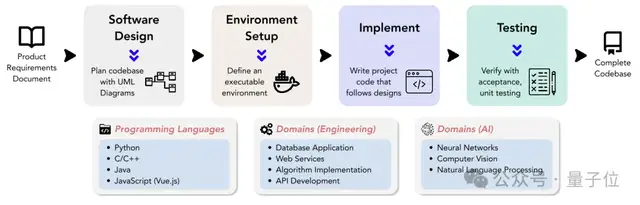
具体地说,DevBench首次对大模型进行了从产品需求文档(PRD)到完整项目开发各阶段表现的评测,包括软件设计、依赖环境搭建、代码库级别代码生成、集成测试和单元测试。

实验证明,DevBench可以揭露GPT、CodeLlama、DeepSeek-Coder 等大语言模型在软件研发不同阶段的能力短板,如面向对象编程能力不足、无法编写较为复杂的构建脚本(build script),以及函数调用参数不匹配等问题。
大语言模型距离可以独立完成一个中小规模的软件项目开发还有一段路要走。
目前,DevBench的论文已经发布在预印平台arXiv,相关代码和数据开源在GitHub上。(链接见文末)
DevBench 有哪些任务?
△ 图为DevBench框架概览
传统的编程基准测试往往关注代码生成的某个单一方面,无法全面反映现实世界编程任务的复杂性。
DevBench的出现,打破了这一局限,它通过一系列精心设计的任务,模拟软件开发的各个阶段,从而提供了一个全面评估LLM能力的平台。
DevBench围绕五个关键任务构建,每个任务都关注软件开发生命周期的一个关键阶段,模块化的设计允许对每个任务进行独立的测试和评估。
软件设计:利用产品需求文档PRD创建UML图和架构设计,展示类、属性、关系,以及软件的结构布局。该任务参考MT-Bench,采用LLM-as-a-Judge的评测方式。评测主要依据两个主要指标:软件设计一般原则(如高内聚低耦合等)和忠实度(faithfulness)。
环境设置:根据提供的需求文档,生成初始化开发环境所需的依赖文件。在评测过程中,该依赖文件将在给定的基础隔离环境(docker container)内通过基准指令进行依赖环境搭建。随后在这个模型搭建的依赖环境中,该任务通过执行代码仓的基准示例使用代码(example usage),评估执行基准代码的成功率。
代码实现:依据需求文档和架构设计,模型需要完成整个代码库的代码文件生成。DevBench开发了一个自动化测试框架,并针对所使用的具体编程语言进行了定制,集成了Python的PyTest、C++的GTest、Java的JUnit和JavaScript的Jest。该任务评估模型生成代码库在基准环境中执行基准集成测试和单元测试的通过率。
集成测试:模型根据需求,生成集成测试代码,验证代码库的对外接口功能。该任务在基准实现代码上运行生成的集成测试,并报告测试的通过率。
单元测试:模型根据需求,生成单元测试代码。同样,该任务在基准实现代码上运行生成的单元测试。除了通过率指标外,该任务还引入了语句覆盖率评价指标,对测试全面性的进行定量评估。

DevBench 包含哪些数据?
DevBench数据准备过程包括三个阶段:仓库准备、代码清理和文档准备。
- 在准备阶段,研究人员从GitHub中选择高质量的仓库,确保它们的复杂性可管理。
- 在代码清理阶段,标注人员验证代码的功能性,对其进行精炼,并补充和运行测试以确保质量。
- 文档准备阶段涉及为仓库创建需求文档、 UML图和架构设计。
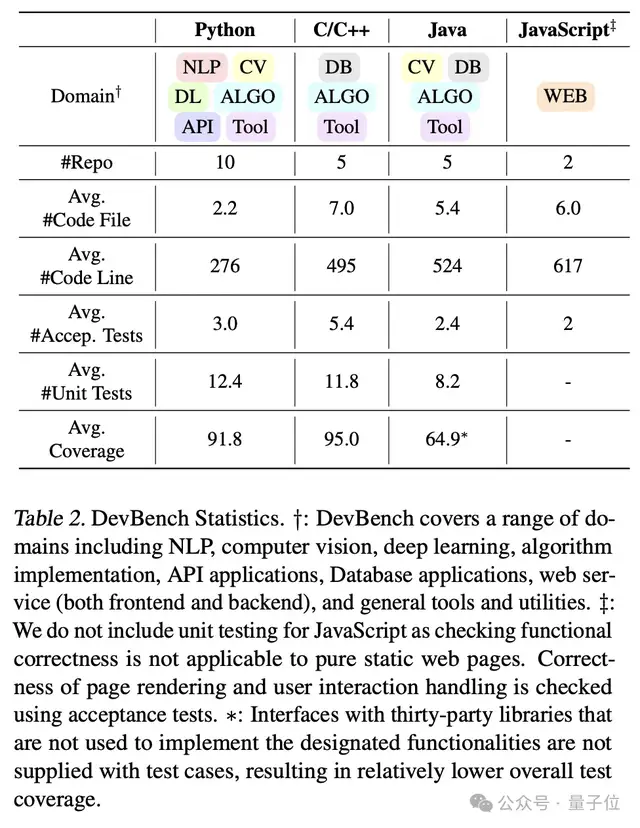
最终,DevBench的数据集包含4个编程语言,多个领域,共22个代码库。这些代码仓库的复杂性和所使用编程范式的多样性为语言模型设置了巨大的挑战。
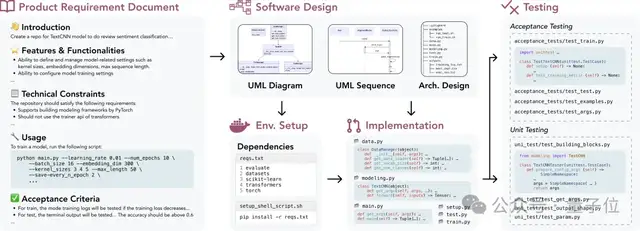
几个有趣的例子:
TextCNN
大模型能完整地写一个TextCNN做文本二分类的模型吗?能够自己把数据集从HF拉下来,把训练跑起来是基本要求。还需模型按照文档的需求定制超参数、记录log、存储checkpoint、同时保证实验可复现性。
(https://github.com/open-compass/DevBench/tree/main/benchmark_data/python/TextCNN)
Registration & Login
前端项目往往依赖较多的组件库和前端框架,模型是否能够在可能出现版本冲突的前端项目中应对自如?
(https://github.com/open-compass/DevBench/tree/main/benchmark_data/javascript/login-registration)
People Management
模型对SQLite数据库的创建和管理掌握的怎么样?除了基本的增删改查操作,模型能否将校园人员信息和关系数据库的管理和操作封装成易用的命令行工具?
(https://github.com/open-compass/DevBench/tree/main/benchmark_data/cpp/people_management)
Actor Relationship Game
“六度分隔理论”在影视圈的猜想验证?模型需要从TMDB API获取数据,并构建流行演员们之间通过合作电影进行连接的人际连系网。
(https://github.com/open-compass/DevBench/tree/main/benchmark_data/java/Actor_relationship_game)
ArXiv digest
ArXiv论文检索小工具也被轻松拿捏了?ArXiv的API并不支持“筛选最近N天的论文”的功能,但却可以“按发表时间排序”,模型能够以此开发一个好用的论文查找工具吗?
(https://github.com/open-compass/DevBench/tree/main/benchmark_data/python/ArXiv_digest)
研究团队利用DevBench对当前流行的LLMs,包括GPT-4-Turbo进行了全面测试。结果显示,尽管这些模型在简单的编程任务中表现出色,但在面对复杂的、真实世界的软件开发挑战时,它们仍然遇到了重大困难。特别是在处理复杂的代码结构和逻辑时,模型的性能还有待提高。
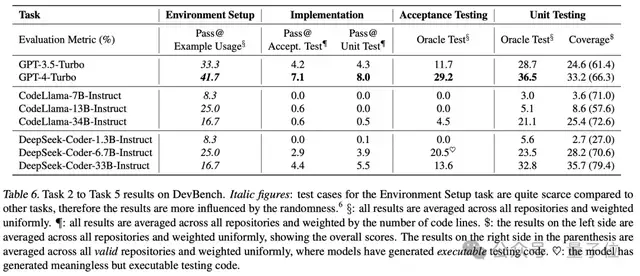
DevBench不仅揭示了现有LLMs在软件开发中的局限性,也为未来模型的改进提供了宝贵的洞见。通过这一基准测试,研究人员可以更好地理解 LLMs的强项和弱点,从而有针对性地优化它们,推动AI在软件工程领域的进一步发展。
此外,DevBench 框架的开放性和可扩展性意味着它可以持续适配不同的编程语言和开发场景。DevBench 还在发展过程中,非常欢迎社区的朋友参与共建。
Devin 在 SWE-Bench 上一路领先,它的优异表现可以扩展到其他评测场景吗?随着 AI 软件开发能力的持续发展,这场码农和 AI 的较量让人倍感期待。
还有OpenCompass大模型评测体系
DevBench现已加入OpenCompass司南大模型能力评测体系,OpenCompass是上海人工智能实验室研发推出的面向大语言模型、多模态大模型等各类模型的一站式评测平台。
OpenCompass具有可复现、全面的能力维度、丰富的模型支持、分布式高效评测、多样化评测范式以及灵活化拓展等特点。基于高质量、多层次的能力体系和工具链,OpenCompass 创新了多项能力评测方法,支持各类高质量的中英文双语评测基准,涵盖语言与理解、常识与逻辑推理、数学计算与应用、多编程语言代码能力、智能体、创作与对话等多个方面,能够实现对大模型真实能力的全面诊断。DevBench更是拓宽了 OpenCompass 在智能体领域的评测能力。
DevBench论文:https://arxiv.org/abs/2403.08604
GitHub:https://github.com/open-compass/devBench/
OpenCompass https://github.com/open-compass/opencompass
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK