

阿里通用多模态大模型 OFA 研究实践
source link: https://zhuanlan.zhihu.com/p/689373516
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
阿里通用多模态大模型 OFA 研究实践
导读 本文将介绍通义实验室关于通用多模态大模型的研究,以及与前沿大语言模型的结合。
主要内容包括以下三部分:
1. Generative Multimodal Pretraining (OFA)
2. Representational Multimodal Pretraining (ONE-PEACE)
3. 总结与展望
分享嘉宾|林俊旸 阿里巴巴通义实验室 通义千问开源负责人
编辑整理|王琳娜
内容校对|李瑶
出品社区|DataFun
01Generative Multimodal Pretraining (OFA)
首先来介绍的工作是 OFA(One for All)。它是通用多模态、多任务预训练相关的一项研究。
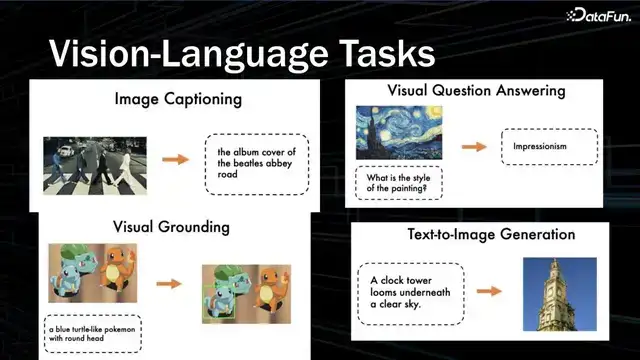
人类是通过感知多种维度的信息来感知世界的,比如人会感知到视觉、语言、听觉等等。多模态的工作通常是在模型里关联处理各种模态,其中 Visual Language 任务是把图像和文本联系起来。
Vision-Language 的典型任务包括:
- Image Captioning:给一张图,生成描述。早期的模型是生成比较短的描述,现在的模型已经可以生成故事、诗歌类型的长描述。
- Visual Question Answering:以 QA 的方式理解图像信息。早期 VQA 主要是做分类的问题,后面发展为 openside 的 answer 的问题。
- Visual Grounding:根据 Prompt 文本找出相应的物体。类似于 Object Detection 物体检测。
- Text Image Generation:文本生成图像。目前是采用 diffusion 技术。
这些任务本质上都可以统一到 sequence to sequence 的 format,因此可以通过一个统一的通用模型来完成。
自然语言预训练工作取得了非常成功的效果。Transformer、GPT 和 BERT 的出现对 NLP 领域产生了很大的影响,scaling model 可以解决很多传统的例如 RNN 的问题,输入更多的数据也能得到更好的效果。在 VL 领域,是否也可以用类似于自然语言的无监督方法来预训练呢?
纯文本是比较容易获取的,但图文相对不容易获取,因为天然的具有关联关系的图文数据集是比较少的。之前的做法是使用 weakly supervised 的 image-text pairs,例如从网页里面去收集各种数据,带图片的 html 会有短的描述,就可以形成图和文的联系。另一方面,如果要把图文数据放到预训练当中,多模态模型中就要增加任务image-text pairing。在这个模型基础上,通过简单的 finetuning 就可以迁移到下游任务。
多模态领域预训练的模态交互部分可以分成两种方式:一种是 Single Stream,就是把 BERT 放入 VL,这种方式非常直接,效果非常好,如 UNITER;另一种是 Dual Stream,如 ViLBERT 和 LXMERT。
文本基于 Bert 训练,图像训练类似 OD 方式提取特征信息,让 Bert 能够理解。
Bert 只能做分类,不能做生成。在多模态领域,Google 团队做了类似于 Multi Model TF 的工作。用 Transformer Encoder 和 Decoder 架构去实现图像和文本的建模。图像方面也做了相应的升级,因为 OD 的方法比较麻烦,后面越来越 end-to-end,直接把图片放到大模型里。不仅是 VL 领域,Audio 也是类似的,end-to-end 是一个大趋势。
在此基础上,还需要将所有任务形式统一到一个模型上。在 2021 年底,预训练对于VL 领域的重要性已经被广泛认可,用大规模的数据去进行 VL 建模是非常关键的。大家都期待一个 end-to-end 的模型。再进一步,希望将各种模态的任务都统一到一个架构中。
OFA 是在 2022 年初提出来的工作。后面也有一系列的工作,例如 Gato、Unified-IO、GIT、BEiT-3 以及 Google 的 PaLI 等等,都是朝着 unification 的方向发展。
Unified model 应该具备以下三个性质:
- Task Agnostic。统一的任务表示,以支持不同类型的任务,包括分类、生成、自监督任务等,并且对预训练或微调兼容。
- Modality Agnostic。希望一个模型可以懂不同的模态。例如 Transformer 是 agent 的角色,不用感知具体是图像还是文本都可以建模。需要解决的问题是unified input and output representation。
- Task Comprehensive。有足够多的任务种类,以稳健地积累泛化能力。在 2022 年做 NLP 会关注 FLAN 和 T0 的方向,收集大量的 NLP 任务,再找出其中一小部分去看 zero-shot 的表现。这些都是为了实现通用的模型,使其能够迁移到新的任务上面去。
我们所做的工作都是围绕着上述三个要求展开的。要统一不同的模态,主要解决 3 种问题。
- 文本 ID 化,Byte-pair encoding 的方式自然地形成 ID;
- 图像 ID 化,把图像转换成 ID,使其能够适配到 Transformer 比如 decode 的模型,从而能够 decode 输出;
- Bounding box,用连续的坐标,对图片的高和宽进行分桶,得到相应的 ID。事实证明,分桶的方法只要分得足够细,就能够做出很好的效果,甚至在 OD 任务上都可以做出惊艳的效果。
本质上要把 input、output 统一起来,ID 是一个非常关键的元素。
模型结构上并没有非常大的改动,当然研究的方向也有很多新的挑战者,比如 RWKV、retentive network 工作。OFA 只是在 Transformer 架构基础上做了一些细节的调整,保证模型训练得更好、更稳。比如 LayerNorm 的设计主要 follow Normformer 的实现。在attention 以及 FC 等插入 LayerNorm 层,还有 Sandwich LN、Magneto 等工作都是为了实现稳定性。
比较特别的一点是 visual backbone 没有采用 OD 的方式,而是用了简单的 ResNet 的前三个 stage,把图转换成一系列的 vectors,然后跟 token 的 embeddings 合在一起。
最重要的核心是解决多任务的问题。要学足够多的任务,但是 VL 里面并没有很多样的任务。我们使用的 VL 中比较大规模的任务包括以下一些:
Visual Grounding。用 prompt,例如 which region does the text “Man in white shirt”describe?去找出相应的 bonding box。对应的 bonding box 实现了 ID 化,在词表里面相应地进行输出即可。反过来也可以根据 bounding box 去生成相应的描述。比如 What does the region describe?给出 region 对应的 ID,去生成相应的 description。
Image text pairing。可以变成二分类的问题,去问 yes or no question。
Image captioning。建模图像和文本联系。根据图像生成相应的文本。
VQA。数据量也比较大。
单模态的任务,以及更大的数据量,对模型效果的影响还是比较大的。
自然语言简单训练文本。不过用的是masked language modeling 的方式,而不是language modeling 的方式。
图像方面做的是 detection 的任务,还有对图像挖空去填充。本质上,类似于 masked language modeling 的操作。
经过这样的学习之后,不管是单模态还是多模态,都可以统一成 sequence by sequence 的形式,统一到 OFA 架构中去。
具体使用的数据量级还是比较大的,并且尽可能使用开源数据。
下游的任务包括:
跨模态的理解,例如 VQA(Vision Question Answering)、SNLI-VE;
图像到文本的生成,例如经典的 MSCOCO Caption;
Visual Grounding 使用的是 RefCOCO;
文本到图像的生成,例如 MSCOCO。
Unimodal 测试发现多模态模型在单模态任务上也能取得 comparable SOTA 的结果。
上图展示了与其它模型的比较。OFA Tiny 只有 3,000 多万的参数量,而评分可以与UNITER 接近。OFA 规模增加后,VQA 评分在 82 的水平。Base3 则达到了 84 的水平。
Image Captioning 的模型在 Hugging Face Space 上很受关注。Cross-Entropy Optimization 的 CIDEr 为 145 分。CIDEr Optimization,类似于 reinforcement learning 的方式,通过 CiDER 把它作为 reward,能提升到 155 分。
在 RefCOCO 上,Base 规模的模型得分超过了 UNICORN。随着参数量增大,分数提升还是比较明显的。Base Model 不到 2 亿的参数,Large Model 是 4 亿到 10 亿。所以 scaling 效果明显,更大的模型参数有可能效果更好。
Text to Image 任务跟 GLIDE 和 CogView 的网页端比较相符,也是不太看重 FID。模型还可以画出风格比较有趣的图,但全面做绘画还是相对较难。
UniModel 方面,多模态的模型比如 SimVLM 和 LXMERT 在单模态任务上跟 BERT 相比,还有一定差距,比 SOTA 和 DeBERTa 差距更大。
OFA 在单模态任务纯文本方面还不错。因为多模态融入单模态的预训练对文本初始化。
Text Generation 做了简单的摘要的任务,效果也还不错。
在图像分类方面,还不够理想。因为 classification 最高水平在 90 分以上,OFA 的 85.6 分不是很高水平。生成式范式要做到顶尖的水平,可能要研究包括 representation 和其它视觉任务。直接通过 general 方式会更难做。所以后面会做统一到 representation 赛道或 Hot 赛道,不是完全在 general model。
多任务会有冲突的情况。比如 image infill 一定程度上会影响文本生成的任务。因为在预训练加入生成 image 的 token,两个任务的特征分布是存在差异的。如何平衡多个任务是值得探讨的一个问题。
Visual Grounding 根据文本把对应的物体找出来。一般的训练数据是比如会场照片、街道照片等等,但没有动漫标注的数据。而预训练数据集里有动漫的图片。所以模型就把两个 merge 在一起。在动漫的图片给文本提示,模型也能够画出来。在 Hugging Face 的 spaces 和 Model Scope 上面都有 demo。大家可以去尝试体验。
OFA 在 github 上已有超过 2,000 的 star。ReadMe 有详细的教程,解释了如何使用、怎么去配 dataset,以及怎么翻相应的脚本等等。
在 ModelScope、Hugging Face 的 spaces 上面都可以找到相应 demo。
针对业务需求,我们也做了中文版的 OFA。MUGE Caption 是去年办的比赛。在天池上面进行测试,对比了比较旧的模型,测试证明预训练为任务带来了非常显著的提升,例如 ResCOCO-CN,randomization 直接训的准确率较低,加上预训练就能提升到比较好的分数。
新的 framework 理念是把任务都融入到 system 里。因为OFA 的核心是Transformer Engine。所有输入 adapt 成 Engine 可以处理的形式。由 Input Data Processor & Adapter 处理各种模态,例如语音、video 以及 motion。Output Adapter 也是一样的道理,做的方式是比较简单的接口。
Generalist Model 加 MoE 的版本。这里的 MoE 是 Multiway 的 Transformer,不是真正意义 token level 的 mixture of Xbox 方法。
Generalist Model 在每个任务上面,不用单独 finetune,能取得比较好的效果,超过了 UnifiedIO。
然而,OFA 也有一些局限性,比如想做 Visual Grounding 任务用 general 方式来做就很难。Representation learning 还有很大的空间,是否可以做 unified representation learning,这就引出了我们的第二项工作 ONE-PEACE。
02Representational Multimodal Pretraining (ONE-PEACE)
我们希望 Representation learning 可以将 vision、language、audio 都统一到一个模型,这就是 ONE-PEACE 的基本理念。
比较经典的工作有 BERT、sentence BERT,还有更加相关的 SimCSE,采用的是对比学习的方式,MAE 用类似于 masked language modeling 的方式来学习表征。Audio 也有像类似于 HuBERT 的工作。
我们所关注的是 CLIP 的工作。对于图文 pair 的数据,用简单的 contrastive learning 把文本和图像 align 起来,Image Encode 能 transfer 到各种任务上面。
Chinese CLIP 项目的影响力超出了我们的预期。在此之前没有很好的 CLIP 版本来做中文的图文检索,每次翻译成中文很不方便,而且效果不好,因为中文的图有自己的特色,所以使用中文数据来 finetune,用 LiT 的方法训练。接口非常简单。Transformers 官方库也有了 Chinese CLIP 模型。
ONE-PEACE 是受到了 Data2Vec 的启发。现在表征模型的发展会关注 feature distillation 方向,其效果甚至比 LiT、Masked Modeling 等方式更好。
沿着这一思路,如果有模型能够把所有模态 distillation 训练,就需要找到作为中介的模态。都与中介模态相关联,所有不同模态就能够联系在一起。所以前两个月 image one 把所有模态都 bind 到了 image 上面,而 ONE-PEACE 则是把所有模态 bind 到文本上面。
目前在 language、vision 和 audio 模态做到的效果比较好。ONE-PEACE 有emergent zero-shot 的能力。
模型架构改动比较 engineering,比如函数换成 GELU。现在 GELU 是比较流行的activation 函数。比如 LLAMA 结构用 SwiGLU 会取得更好的效果。比较特别的一点是 follow BEiT-3 的 multi-way 的方式,能取得比较好的效果。
Loss 的设计方面,除了使用经典的 contrast learning loss 之外,我们还需要确保图像和文本之间的绑定关系。同样地,音频和文本之间也采用 contrast loss 进行绑定。类似于 feature distillation 方式的更加细粒度的 contrastive learning 的方式有 student model。而 student model 是带 masking 的,要去拟合没有 masking 的 teacher model 方式。
实现方式是先 V-L pretraining 再 A-L pretraining。
可能合起来训练是最好的,但由于资源等问题是分开来做的。整体规模达到了 4B。
在 ImageNet 上达到了 89.8 的分数,也没有用私有的数据。
在 Segmentation 和 Detection 上面取得分数更高,Detection 上达到了 60 以上的水平。
在 Audio 的 benchmark 中,Retrieval 任务和分类的任务比如像 layout z获得了更高的分数。然而 OFA 在 Retrival 任务上尚未找到有效的方法。
但是 ONE-PEACE 的 representation learning 效果比较理想。
Grounding 任务也超过了之前 OFA Huge 的效果。
Ablation 的具体细节在 paper 里面有详细介绍。
这里额外展示一下 Emergent zero-shot 的能力。原本新的模态只是跟文本联系在一起,但我们发现别的模态两两之间也能产生比较有趣的联系。例如羊咩咩叫的音频和牛哄哄叫的音频跟山的图片联合在一起,模型能找出那些带牛带羊的图。还有狗的照片和 snoring 的声音,模型会找出在睡觉的狗。
又比如文本 beach 再加上动物的声音,模型找回的动物图片是包含沙滩元素的。这也是值得关注的一个方向,只要找到中介模态把各种模态关联起来,性能有很大的提升空间。
接口也很简单。
03总结与展望
我们提出了 OFA 来统一生成性预训练的任务和模式。统一预训练使模型能够在多模式任务中实现 SOTA 的性能。
我们还提出了 ONE-PEACE,一个针对无限模态的表示预训练模型。它是下游模型的强大支柱。
未来的工作主要包括以下三个方向:
首先是以 LLM 作为多模态 AI 系统的 engine。之前的 engine 是训练 Bert 或 T5,而现在可以训练 chatGPT 等模型。
第二是把不同模态连接到 LLM 上。现在的工作比如 Kosmos、mini GPT4 以及LLAMA 和 LLAMA2 等。只要通过 LLM 把多模态联系起来,做 end-to-end 会变得更加简单。
第三是调用工具。在 output 侧,更好的方式就是直接调用 tools。比如做图像生成不用苛求 LLM 能做图像生成,只要让 LLM 学会去调用 stable diffusion 即可。所以服务能传进图片甚至还能生成图片。
以上就是本次分享的内容,谢谢大家。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK