

滴滴大数据资产治理实践
source link: https://zhuanlan.zhihu.com/p/688312597
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
滴滴大数据资产治理实践
导读 数据资产治理是大数据应用中的重要一环。有效的数据治理可以降本增效,提升数据利用效率。数据治理还需要平台化工具来辅助。本文将介绍滴滴出行在大数据资产治理方面的实践。
今天的介绍会围绕下面五方面展开:
1. 滴滴大数据资产管理平台
2. Hadoop 治理实践
3. ES 治理实践
4. 未来规划
5. 问答环节
分享嘉宾|王义忠 滴滴出行 资深软件开发工程师
编辑整理|许通
内容校对|李瑶
出品社区|DataFun
01滴滴大数据资产管理平台
首先让我们来了解一下滴滴数据体系,以及资产管理平台在这个体系中的定位。
1. 滴滴数据体系
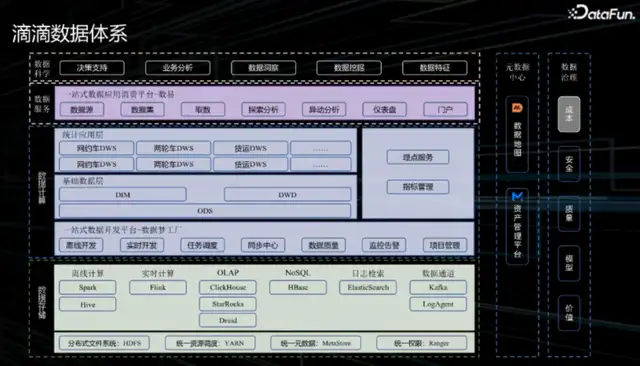
从下往上,最底层是数据底座,包括数据存储、数据计算、实时查询、消息中间件、调度等部分。其上是中间层,数据梦工厂,是数据一站式开发平台,提供数据导入、数据加工、任务调度、数据质量校验等一系列工具。最上层是基于数据底座和数据中间层构建的数据服务与数据应用,并衍生出各种数据产品。资产管理平台便是其中之一。
2. 资产管理平台产品架构
资产管理平台是对整个滴滴大数据中的数据资产进行统一管理的一个平台,底层管理包括存储资源(如 Hive、HDFS)与计算资源(如 Spark)。
从功能上分为成本管理、资产管理和资产治理三大部分。资产治理又包括存储治理、计算治理、质量治理、安全治理。并提供治理提效工具,如治理工作台、自动化治理、权限批回收等。
02Hadoop 治理实践
1. Hadoop 治理的对象
数据梦工厂是构建在 Hadoop 体系之上的一个开发平台。用户在平台上进行开发,包括任务的创建、调度,就会用到 Hadoop 底层的存储资源和计算资源。这些均为 Hadoop 体系中数据治理的对象。
- 存储治理包括:Hive 表、HDFS 路径。
- 计算治理包括:Spark 任务、MR 任务。
2. Hadoop 治理架构
Hadoop 治理架构自底向上分为:元数据层、数据模型层和治理应用层。
- 元数据层包括计算元信息和存储元信息。计算元信息有:Hadoop 执行日志、Spark 执行日志、数梦任务元信息。存储元信息有:HDFS 路径访问审计、Metastore 信息、fsimage。Metastore 信息维护表的元信息和分区元信息。fsimage 为路径存储计算。
- 数据模型层基于底层元数据进行建模。基础信息包括:表血缘、任务血缘、路径访问、表访问等。并基于这些基础信息加工出计算与存储治理项目表、计算健康分、存储健康分、治理空间预估、主动治理收益等信息。
- 治理应用层会为用户提供治理相关工具。计算治理方面包括:任务停用、任务删除、任务代码优化、参数修改。存储治理方面包括:表生命周期调整、表下线、表删除、小文件合并等。基于此还衍生出了一些治理提效工具,如治理工作台,以及一些自动化治理工具。
整个架构中的核心是健康分和治理项。接下来将重点介绍这两部分。
3. Hadoop 治理项设计
治理项反映了用户资源存在的问题,通过分析计算和存储资源,找出治理项,进而指导相关操作。
计算治理项包括:数据倾斜、暴力扫描、参数不合理、高耗任务、无效计算、存在空表、相似加工、同源导入。存储治理项包括:不合理生命周期、空表、无访问表、不规范表、空路径。
在后文中将重点介绍计算治理项中的数据倾斜和暴力扫描,以及存储治理项中的不合理生命周期。
治理项的工作是基于元数据开展的,其中 Spark 执行日志、MR 执行日志是重要的信息源。通过分析执行日志,从中提取关键信息存储到 ODS 层。
Spark 事件监听中的重要信息包括:环境参数内存、vcore、输入输出路径、执行SQL 内容、gc 信息、数据条数、字节数等。MR 事件监听中的重要信息包括:gc 信息、数据条数、字节数、job 统计信息、Map 结束时间、Reduce 结束时间等。
利用这些信息就可以开展治理项工作。
数据倾斜是大数据工作中经常遇到的问题,是重要的治理项。数据倾斜是在并行进行数据处理的时候,由于数据分布不均匀,导致大量数据集中分布到一台或者某几台计算节点上,使得该部分的处理速度远低于平均计算速度,成为处理瓶颈,影响整体计算性能。以 Spark 为例,Spark 为多 task 执行,多数 task 会在一定时间内完成,有少部分 task 会执行时间较长,形成长尾效应。这就是数据倾斜现象,发生的核心原因是数据分布不均。
工作中通过引擎日志分析、倾斜率计算、判断倾斜三步来识别数据倾斜。基于 Spark执行日志和 MR 执行日志,可以获取执行时间、任务处理条数、任务处理字节数。获取这些指标信息后,进而计算各项倾斜率。以执行时间倾斜率为例,计算方法为:执行时间倾斜率 = task 执行时间最大值/task 运行时间中位数。最后利用判别规则识别是否发生数据倾斜,如 max(task 运行时间)>15min && 执行时间倾斜率 > 5 && 近 33 天批次平均执行时间 > 30min。
当系统判断发生数据倾斜时,会根据数据倾斜的常规原因进行分类,并给出优化方案。我们以两个典型场景为例来讨论:热点 key 场景、大表 join 小表场景。
热点 key 场景中,首先在生产任务中识别到数据倾斜,进一步在代码中定位到存在数据倾斜的关键代码段。关键代码段中以 path_normal 这个字段进行聚合。接下来进一步分析 path_normal 这个字段在值上的分布,发现空值在数据规模上远大于其它值。根据分析,给出指导意见,当 path_normal 为空值时使用 path 正常值进行替换。通过这样的指导意见可以解决空值热点 key 带来的数据倾斜问题。
大表 join 小表也是生产中常见的问题。诊断发生这种场景的数据倾斜时,通过mapjoin 方式对小表进行广播,来解决数据倾斜。
暴力扫描也是一个常见治理项。暴力扫描在这里的定义为:当前批次扫描分区多于365 个,并且扫描数据量大于 1G。暴力扫描识别中,解析引擎日志元信息对输入输出进行分析获取扫描数量。同时,关联 Metastore与 FSImage 中的信息,Metastore 中维护了表和分区信息,FSImage 中维护了数据文件路径对应的存储量。结合这些信息可以得出本批次扫描分区数与扫描总数据量。利用这些信息可以判定是否发生暴力扫描。
在产品中会尽量识别出暴力扫描对应的代码行,以便于指导用户进行相应的暴力扫描问题处理。
暴力扫描问题出现的常见原因有:
- 分区筛选条件未配置
- 筛选条件过于宽泛,尤其是多级分区
- 使用隐式 Join 带来扫描问题
以生产上的两个例子来说明。
第一个例子,多级分区筛选条件宽泛。示例中的表以
contry_code/year/month/day/hour 字段为分区小时表,用户在筛选条件中只有 country_code 和 current_stat_date 字段,扫描会设计 contry_code 下面所有的分区。经过诊断,给出建议为:将 year/month/day 分区条件补全。补全后的 SQL 执行会精准定位到具体的分区,避免过多扫描分区。
第二个例子,隐式 Join 带来暴力扫描。代码中用户左表 left join 右表,并写了分区筛选条件。一般会直观认为这个代码已经有分区筛选条件,不存在全表扫描。但是通过 TableScan 发现,代码执行发现有全表扫描。针对这种情况,给出建议为:写子查询时需要将相应的查询条件补充上。这样就可以解决暴力扫描的问题。
讨论完计算相关的治理项后,再来看一下存储治理项。
首先是生命周期不合理。生命周期不合理会造成存储资源的浪费。生命周期不合理有两种情况:
- 生命周期未设置
- 当前生命周期大于推荐生命周期
这里的核心问题是,如何进行生命周期推荐。生命周期推荐依赖于以下信息:
- 分区访问跨度:分区访问时间 减去 分区创建时间
- 表访问跨度:分区访问跨度的最大值
- 93 天访问跨度:93 天内表访问跨度最大值
生命周期推荐根据 93 天访问跨度进行阶梯式推荐。
生命周期推荐中,数据元信息来自于 HDFS 访问审计日志、分区元信息。将元信息汇总后得到表分区访问,进而汇总出表访问。利用表访问可以计算出表访问跨度推荐生命周期。
治理项反映数据资产存在的问题,而健康分是在治理项基础上进一步抽象,用于反映资产健康情况。健康分可以作为治理抓手使用,健康分越低,说明资产健康情况越差,越需要介入治理。
健康分有存储健康分和计算健康分两类。存储健康分又包括:HDFS 健康分、Hive表健康分。
下面介绍计算健康分。计算健康分根据每个治理项扣分来计算,例如:数据倾斜扣40 分。各个治理项的扣分数值是依据其对数据成本的影响来制定的。数据倾斜对成本影响较大,所以定为 40 分。计算健康分为 100 减去所有扣分项。
除此之外,也会从其他视角考虑计算健康分,例如个人、项目账户、项目。因此,引进影响因子作为权重项。影响因子为近 33 天的平均计算消耗。影响因子反映了该资源对于所有维度下计算健康分的影响。利用影响因子对所有资源计算健康分进行调和平均,得到各个视角下的计算健康分。
接下来介绍存储健康分。存储健康分包括表存储健康分和路径存储健康分。
表存储健康分由三部分组成:直接得分、最低得分和各个治理项扣分情况。
直接得分规则有:
- 非可再生数据:100 分
- 非分区表近一个月有使用过:100 分
- 白名单:100 分
- 一个月内创建的新表:99 分
- 视图表最近一个月有访问:100 分
- 视图最近一个月未使用过,直接 20 分
最低得分规则为:只要设置了生命周期,最低分 20 分。
治理项扣分规则为:
- 生命周期扣分:根据用户设置生命周期与推荐生命周期差值,进行阶梯扣分。
- 不规范表扣分:存在不规范直接扣 10 分。
- 孤立数据扣分:表路径不存在,扣 100 分。分区路径不存在,扣 10 分。元数据不存在,扣 30 分。
- 无访问扣分:扣 30 分。
- 空表扣分:扣 10 分。
存储健康得分为:直接得分不为空,则为直接得分;否则,100 减去所有扣分项后,与最低得分比较,取两者之中的较大值。
路径存储健康分与表存储健康分类似。
基于多维度存储健康分考虑,引入存储健康分影响因子。存储影响因子与存储大小相关,影响因子等于开立方(存储大小 + 1)。
最后,来介绍一下健康分模型在日常治理工作中的应用。用户有着不同的角色,以项目负责人为例,进入平台后,首先使用视角切换查看健康分,包括有哪些治理项,扣了哪些分。如图所示,生命周期是一大扣分项。点击进入列表查看,可以使用健康分影响因子进行倒排。通过健康分影响因子可以获取到治理收益最大的待治理任务。
平台中与治理相关的页面包括:健康分页面、Hive 表治理页面、计算治理页面、治理工作台页面等。
03ES 治理实践
接下来介绍 ES 治理实践。ES 治理的主要治理对象是 ES 索引模板。
下图展示了 ES 治理数据架构。
自底向上分别为:数据源层、数据建模层和在线层。
数据源层主要包括两部分信息:索引模板相关的基础信息、索引相关的访问血缘信息。基础信息包括:索引管控平台维护的 ES 模板信息、ES-mapping、es-metric。ES-mapping 维护索引字段、类型、分词等等,这些信息通过 ES 提供的 API 获取。ES-metric 指标信息包括:索引的 doc 数、shard 数、shard 存储分片、shard 存储大小。这些信息通过运维侧采集,落入 Kafka,之后使用 Flink 进行相关转变并落入 ODS 层。
数据建模层使用接入的元信息进行 ODS、DWD、APP 各层建模。明细层包括:访问明细、分区明细、血缘明细、访问跨度、治理收益空间预估、治理收益核算。上层 APP 层也有对应治理表。
在线层,将治理项、治理动作透出给用户。用户可以进行日常治理操作,达到降本增效的目的。
从架构图中可以看出治理项的设计是整个架构的核心。接下来就来讨论 ES 治理项。
ES 治理项包括:空模板、不合理生命周期、字段优化、未设置生命周期、33 天无访问。
下面重点介绍不合理生命周期和字段优化。
ES 的不合理生命周期与 Hadoop 的不合理生命周期判别逻辑一致。主要问题是如何给用户提供推荐生命周期,让用户进行生命周期调整。
首先,获取到 ES 访问日志,基于访问日志进行分区访问跨度识别。然后利用分区访问跨度汇总成索引模板 33 天访问跨度。最后,根据 33 天访问跨度,进行生命周期阶梯推荐。
接下来,我们介绍索引优化。
ES 对于每个 doc 字段进行正排索引和倒排索引的创建。正排主要用于排序和聚合。倒排主要用于搜索查询。两种索引都会占用存储空间。
我们会发现,一些字段建立了索引,但是长时间没有使用到。这种情况下,会推荐对这些字段关闭正排索引和倒排索引,以减少存储浪费。这里的核心是如何识别出长期未访问字段。系统识别未访问字段的流程为:先对 ES 访问日志进行解析清洗,然后汇总出小时级别字段访问信息,进而汇总天级字段访问情况,最后汇总出一段时间内无访问的字段。对于日志索引查看 33 天访问情况,对于其它索引查看 14 天访问情况。产品中会提供给用户无访问字段列表,并指导用户关闭对应的正排索引和倒排索引。
产品界面中包括:治理项、治理项对应的治理资料。针对不同的治理项有相关的治理动作。
以上就是对 Hadoop 和 ES 的治理实践。
04未来规划
最后,分享一下未来治理方向上的规划。
目前,数据治理每年可以为公司节约千万的成本,然而数据治理相关人力投入相当大。未来希望在技术方面进行治理提效,通过技术手段提高治理效率,如提升自动化治理能力,让治理成为 Daily Run 的自动任务,减少人工投入。
另一方面,实现智能治理,提高治理项推荐准确率,多人多面,每个人看到不同的治理推荐。
最后,实现预算控制,针对顶层预算进行管控,业务线、成本账号、项目一层层进行预算管控,将治理前移,减少后续治理压力。
05
问答环节
Q1:倾斜率计算中的常量 0.5 和 0.25 是如何估算出来的?数据倾斜的优化是平台根据原因自动化治理,还是需要用户去配置参数?
A1:权重系数是根据一些数据的测算得到的,不是人为猜测制定。数据倾斜的场景是通过任务血缘、SQL 血缘识别原因类型,推荐给用户治理方法。
Q2:生命周期推荐天数的设置依据是什么?
A2:推荐是根据表在一段时间内访问跨度进行阶梯推荐。
Q3:如何入门数据治理?
A3:首先,需要对这个方向感兴趣。然后,看业界常规治理方法进行入门学习。技术方面,需要了解大数据技术组件。
Q4:生命周期过期的表是进行物理删除,还是人工处理?
A4:目前有 Daily Run 任务进行删除,删除后进入回收站。回收站中三天内的数据可以进行恢复。
Q5:治理项中的公式,针对不同的需求,不同的表对应的计算不同,可以使用相同的公式吗?有些需求复杂数据量大,可能需要的计算时间长。
A5:抽象出的计算公式是比较通用的。有些任务场景本身数据倾斜会比较严重,数据量规模大。从集团层面需要是同一套指标。对此类情况,还是应该看下是否有提升空间。
Q6:从滴滴内部实践看,用户满意程度如何?
A6:大数据用户目前反馈比较好,整体是正向反馈。偶尔会有小的负向反馈,也会及时答复和跟踪处理。
Q7:一个部门可能有非常多待治理任务,您提到的治理因子是如何计算的,以及如何和成本结合起来?
A7:治理因子算法见 ppt。以存储治理因子为例,存储大小与成本直接相关。
Q8:政府部门受限于技术人才限制,如何开展数据治理?从哪些地方会比较容易?如何设计数据治理策略?人员不足的情况下如何做数据治理。
A8:数据治理无法面面俱到,需要抓大放小。需要查看资源情况,是存储成本比较高,还是计算成本比较高。具体到存储,要分门别类地看是哪一方面影响成本。在团队能力不足的情况下,抓几个重点去做。健康分模型和影响因子也是基于抓大放小来设计。能看清成本分布,然后开展治理动作。资产管理平台也有成本管理模块,在成本管理基础上进行资产治理。
以上就是本次分享的内容,谢谢大家。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK