

解读AI通用计算芯片:GPU训练CPU推理,用最优的成本降低AI算力支出
source link: https://www.51cto.com/article/784165.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
解读AI通用计算芯片:GPU训练CPU推理,用最优的成本降低AI算力支出
原创当前,人工智能已经成为推动企业业务创新和可持续发展的核心引擎。我们知道,算力、算法和数据是人工智能的三大核心要素,缺一不可。今天,笔者就从通用计算芯片这个维度出发,跟大家详细聊聊关于算力的相关技术与市场竞争态势。
所谓AI计算芯片(也称逻辑芯片),就是指包含了各种逻辑门电路,即能够进行运算,又能够进行逻辑判断的数字芯片,包括CPU、GPU、FPGA、ASIC等。这里,我们将通过一些比喻重点跟大家介绍一下CPU与GPU这两种通用计算芯片,希望大家看完本篇文章,能够真正了解CPU与GPU的主要差异,以及相互之间的优劣势。
计算机基本架构及原理
要了解CPU与GPU的本质区别,首先要简单地认识一下计算机的基本架构。
从数据输入到结果输出,现在的计算机大都是基于1940年代诞生的冯·诺依曼架构演进而来。在这个架构中,主要有输入设备、存储器、运算器(ALU,也称逻辑运算单元)、控制器(CU)、输出设备组成。
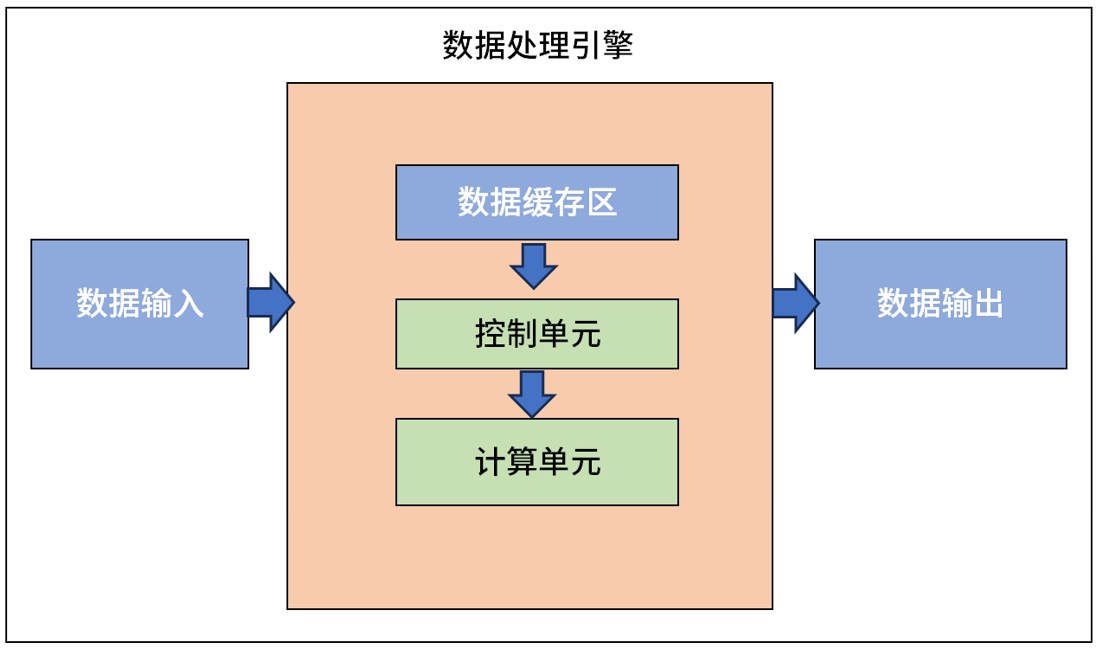
数据输入:将外部数据输入到数据处理引擎中;
数据缓存区:负责计算过程中临时数据的存储与读取,主要用来提高数据的读写效率;
控制单元:负责接收数据处理的控制命令,并且执行对整个处理引擎的控制和状态进行实时反馈;
计算单元:即数据处理的核心;
数据输出:输出处理好的数据,与外界进行交互。
本质上,CPU与GPU都是从冯·诺依曼架构演进而来,但由于采用了不同的架构,因此双方在计算性能上存在着较大的差异。接下来,我们就通过以英特尔为代表的x86架构和以英伟达为代表的CUDA(NV-RSIC)架构,来介绍一下两者的不同之处。
架构设计不同带来的差异
1)CPU:串行计算
作为计算机中的核心部件,CPU就像我们人类的大脑一样,它不仅仅要执行各种复杂的计算任务,还要负责控制其它部件之间的协作。因此,除了计算单元外,控制单元也在CPU中扮演着重要的角色。(CPU架构示意如下图)
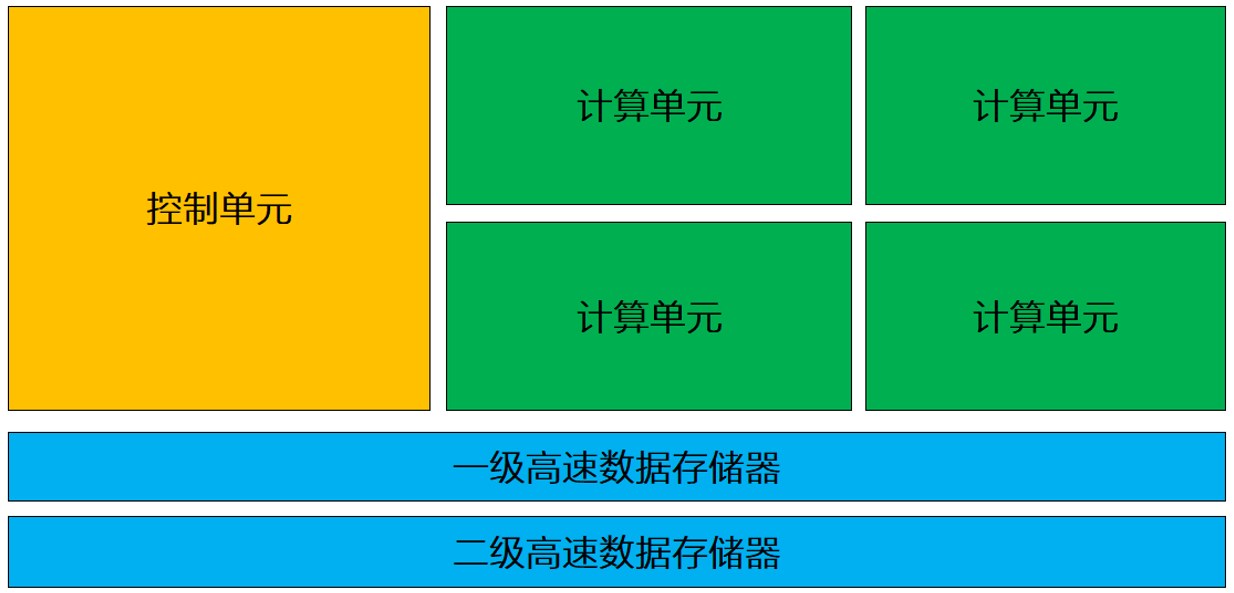
上图可以看到,在整个CPU架构中,负责计算的绿色区域占的面积相对并不算大,反而黄色区域的控制单元占据了不少的空间。因此,除了计算之外,CPU也比较擅长逻辑控制。
和我们的大脑一样,CPU只能同时完成一件事情,是以串行方式进行计算的。指令在CPU中执行的过程就像一个工厂生产车间中的一条流水线,即先读取指令,之后通过指令总线送到控制器中进行译码,并发出相应的操作控制信号;然后运算器按照操作指令对数据进行计算,并通过数据总线将得到的数据存入数据缓存器,完成一条指令的计算过程。(如下图)
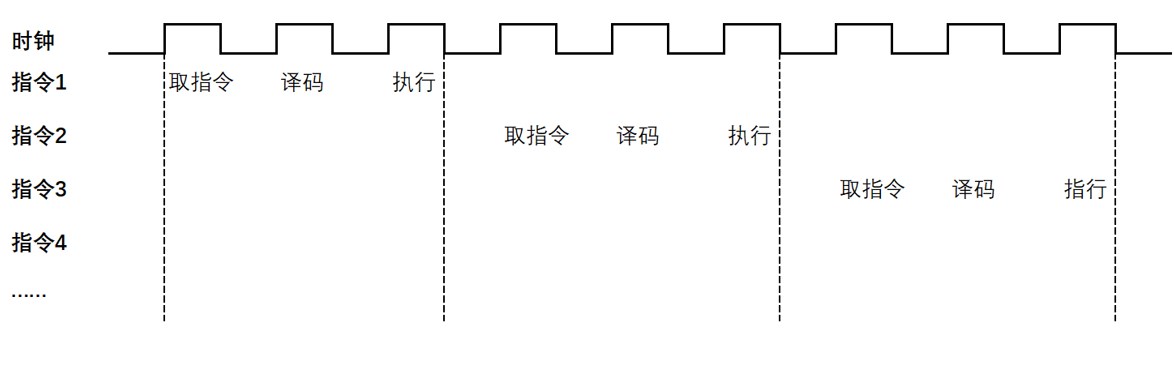
在取指令 ->指令译码 ->指令执行这个过程中,只有在指令执行的时候计算单元才发挥作用,这样取指令和指令译码的两段时间,计算单元就不会工作,这就会造成计算效率不高。
为了提高指令执行的效率,在不同的指令之间,通过预先读取后面的几条指令,使得指令流水处理,这样就减少了指令等待的过程,提高了指令执行效率。(如下图)
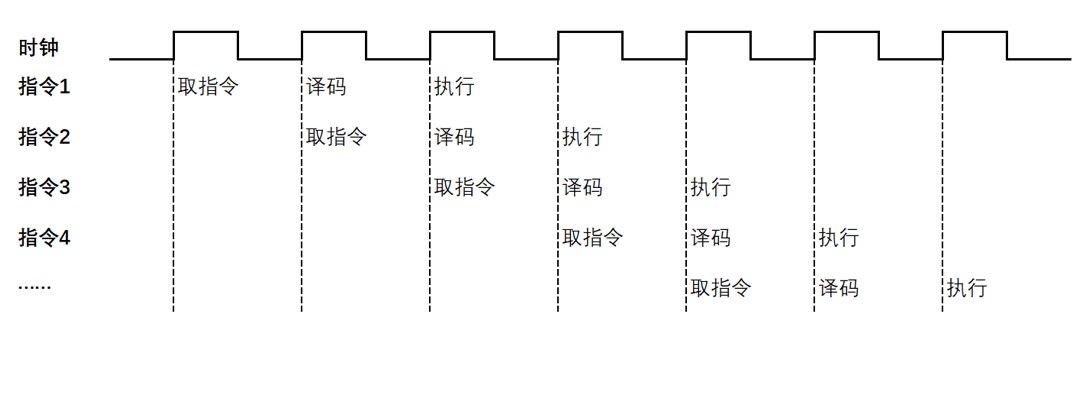
当然,提高时钟频率、增加更多的核心数量,也能够有效地提高CPU的计算效率,但随着技术瓶颈的出现,提高核心数量和提高时钟频率的难度越来越大,且带来的性能提升比例越来越小。
不难发现,受架构影响,CPU有着很强的逻辑运算能力,但并不擅长1+1=2的大量数据的并行计算。因此,在AI训练过程中,需要大规模并行计算时,CPU的优势就非常不明显了。
2)GPU:并行计算
在计算机中,GPU最初设计的初衷是加速图形图像处理,即专用加速器。因此,GPU内部采用了并行计算的设计,控制单元仅占很小的一部分。(见下图)

上图可以看到,GPU内部拥有大量的计算单元。由于采用了并行架构设计,每一组计算单元都有单独的缓存和控制器。
由于具有大量的计算单元,仅用来进行图形图像处理,应用范围过于狭窄,也无法真正发挥GPU的价值。于是,NVIDIA提前感知到AI将成为未来的主要技术趋势,并将GPU内部的计算单元进行了通用化的重新设计,GPU变成了GPGPU,即通用并行计算平台,也就是今天我们所指的GPU。
GPU不仅能够处理图形数据,还可以处理非图形化数据,特别是在运算量远大于数据调度和传输的计算时,GPU的性能远远大于CPU,因此在进行大量数据的训练时,GPU有着更强的优势。
当然,由于控制单元并不占优势,因此在进行逻辑运算时,GPU并不占优势。也就是说,让GPU进行大量数据的简单运算,速度更快,就像把大量的土豆全部切成片,GPU会更快。但是,如果让它执行将一小部分土豆切成丝,一大部分切成片这样的任务时,GPU就不占优势了。
CPU vs GPU:合理搭配降低AI总体成本
通过以上介绍不难发现,由于底层架构存在着较大的差异,因此双方在AI运算中也扮演着不同的角色。
举个例子,CPU具备更强的逻辑运算能力,就好像一位资深的老教授;GPU并行计算能力更优,就好像很多小学生同时进行1+1的简单计算。在同时进行大量简单的计算任务时,人数越多越占优势,完成的时间就越短;但是,如果在进行微积分等更加复杂的计算任务时,CPU就更加占有优势。
具体到AI计算方面,由于CPU有着更强的逻辑运算能力,就更加适合推理;而GPU拥有大量的计算单元,就更适合训练。
当然,无论是英特尔还是英伟达,都在通过不断进行架构优化,来提高AI的计算能力。例如英特尔,在最新推出的第五代至强可扩展处理器中,通过在每个内核中都内置英特尔AMX加速AI模块器的方式,让AVX-512和AMX都可以在CPU上使用,以提高AI推理的性能。根据官方给出的数据,基础平均性能较上一代提升21%,而AI推理性能的提升则高达42%。同时,得益于内置的英特尔高级矩阵扩展功能,第五代至强处理器无需搭配独立的AI加速器,就可以直接应付严苛的AI工作负载。
英伟达GTC2024上发布的全新B200 GPU,采用了两个GPU die集成在同一芯片上的设计,并配备了192GB的HBM3e超大内存。基于GB200 NVL72打造的MGX系统,能够实现30TB的统一内存,130TB/s的总带宽,甚至是单机柜exaFLOP级(FP4精度)的AI算力。英伟达表示,即便面对1.8万亿参数的GPT-MoE-1.8T超大模型,也可以实现比同数量H100 GPU高出4倍的训练性能。
虽然目前GPU的热度远高于CPU,但在笔者看来CPU仍然不可替代。原因在于,CPU不但具备更强的推理能力,并且拥有更高的性价比。这是因为,目前大部分数据中心中并不缺少CPU计算资源,且相对部署已经更加完善和成熟。因此,考虑到成本因素,包括采购成本、部署成本、使用成本(功耗)等,也成为众多厂商选择CPU进行推理的重要原因。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK