

Does Your GROUP BY Order Matter?
source link: https://www.brentozar.com/archive/2024/03/does-your-group-by-order-matter/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Does Your GROUP BY Order Matter?
Sometimes when you do GROUP BY, the order of the columns does matter. For example, these two SELECT queries produce different results:
CREATE INDEX Location_DisplayName ON dbo.Users(Location, DisplayName); SELECT TOP 100 Location, DisplayName, COUNT(*) AS Duplicates FROM dbo.Users GROUP BY Location, DisplayName ORDER BY Location, DisplayName; SELECT TOP 100 DisplayName, Location, COUNT(*) AS Duplicates FROM dbo.Users GROUP BY DisplayName, Location ORDER BY DisplayName, Location; |
Their actual execution plans are wildly different:

They both use the index to retrieve their data, sure, but:
- They both use index scans on the same index, but the first one only has to read data for the first 100 Location, DisplayName combos. The second one has to read all of the rows because the first 100 DisplayNames could be anywhere in the Location_DisplayName index.
- The first one can dump the results out as-is, whereas the second one has to sort all of the rows by DisplayName, Location. The second one takes a hell of a lot longer to do that.
- The first one is so lightweight that it’s single-threaded, whereas the second one goes parallel.
Okay, sure, makes sense. But what about when the GROUP BY column order doesn’t matter, like this:
CREATE INDEX Location_DisplayName ON dbo.Users(Location, DisplayName); SELECT TOP 101 Location, DisplayName, COUNT(*) AS Duplicates FROM dbo.Users GROUP BY Location, DisplayName ORDER BY COUNT(*) DESC; SELECT TOP 101 DisplayName, Location, COUNT(*) AS Duplicates FROM dbo.Users GROUP BY DisplayName, Location ORDER BY COUNT(*) DESC; |
Note that I’m doing a GROUP BY on the same columns in the index, but I’m doing an ORDER BY on something else altogether. This is really common in grouping reports where you wanna see things by a new calculated number.
In theory, the order of the GROUP BY columns doesn’t matter here. It doesn’t matter if I group by Location then DisplayName, or if I group by DisplayName then Location. In either case, I’m gonna have to sort the data by COUNT(*) DESC anyway, so the order of stuff in the meantime doesn’t matter.
To find out if our query text matters, let’s run both queries and check out their actual execution plans in SQL Server 2016 compat level:
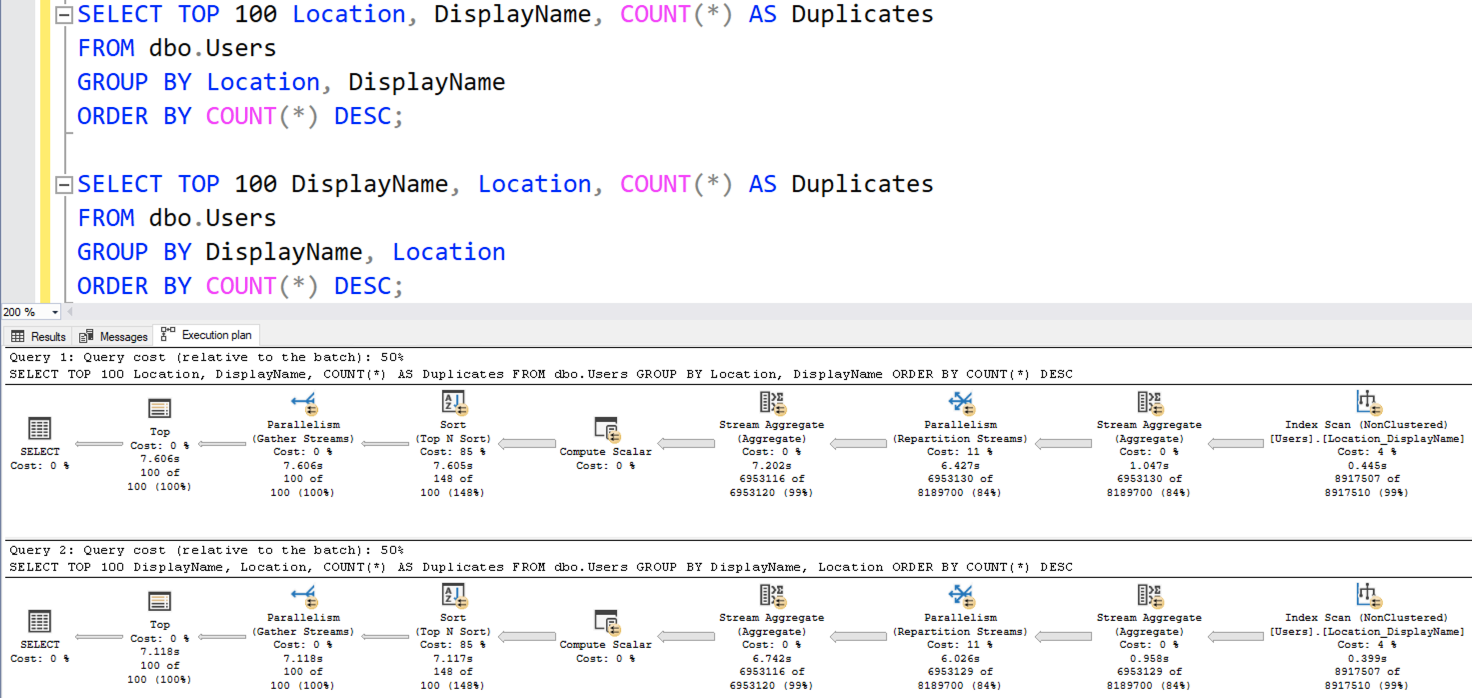
They’re identical! SQL Server is doing witchcraft in the second plan, where:
- The index is on Location, DisplayName, but
- SQL Server seems to be doing a stream aggregate on DisplayName, Location
Or is it? Check out the properties of the stream aggregate operator:

SQL Server says, “I’mma output DisplayName, Location, but I’mma group by Location, then DisplayName.” I LOVE THIS. SQL Server is smart enough to understand that the order of columns in the GROUP BY doesn’t matter.
SQL Server 2022 compat level has a different set of execution plans that run much more quickly, but the answer is still the same: both queries have the same operators in the plan, and both perform identically:
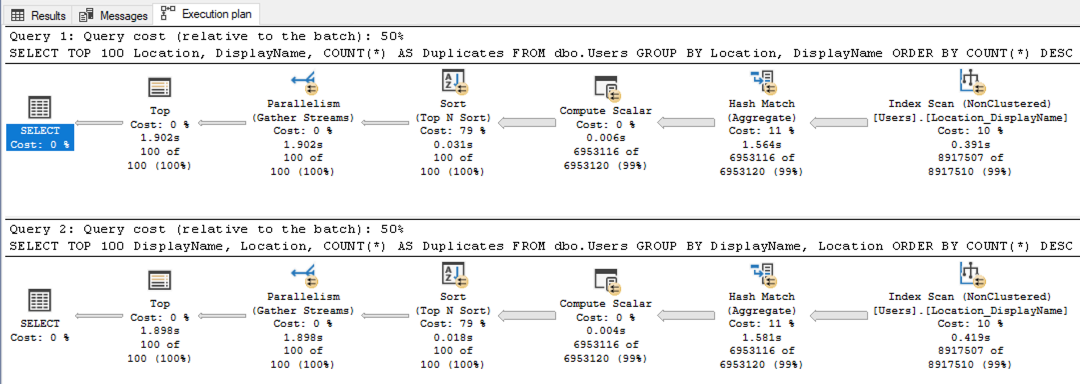
Nice work, SQL Server. Extra time spent at plan compilation, coming up with these kinds of optimizations, results in faster query execution. This is a good example of the kinds of things I refer to as the choose-your-own-adventure-book in my Fundamentals of Query Tuning class.
Side note – I wrote this post after reading how PostgreSQL is getting this optimization in the future. Work on it began back in 2018!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK