

RAG 范式、技术和趋势 - JadePeng
source link: https://www.cnblogs.com/xiaoqi/p/18075992/rag-survey
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
这里分享同济大学 Haofen Wang的关于检索增强生成的报告:《Retrieval-Augmented Generation (RAG): Paradigms, Technologies, and Trends》 ,RAG 范式、技术和趋势。
RAG 概述
为什么会有RAG, 主要是缘于LLM的一些不足:
- 过时的信息
- 参数化知识效率低
- 缺乏专业领域的深入知识
- 推理能力弱
对在企业里的真实的应用,需要综合考虑:
- 领域支持的精准回答
- 数据频繁更新的需求
- 生成内容需要可追溯可解释
- 可控的成本
- 隐私数据保护
因此有了RAG(Retrieval-Augmented Generation 检索增强生成),RAG的基本流程是,当回答问题时,首先从大量文档中检索到相关信息,然后基于这些信息,让LLMs生成答案。这样通过附加一个外部知识库,无需为每个特定任务重新训练整个大型模型。
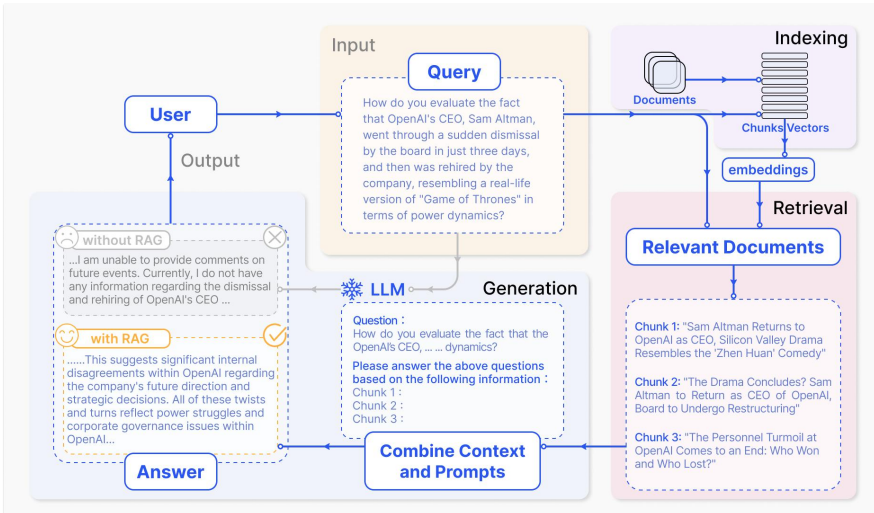
因此RAG模型特别适合于知识密集型任务。
RAG 还是 Fine-tuning
要优化大模型,可以通过提示词优化(Prompt Engineering),RAG 和 Fine-tuning方法。 RAG 和 FT有什么区别?根据对外部知识的依赖程度和模型调整的需求,他们都有适合自己的应用场景。
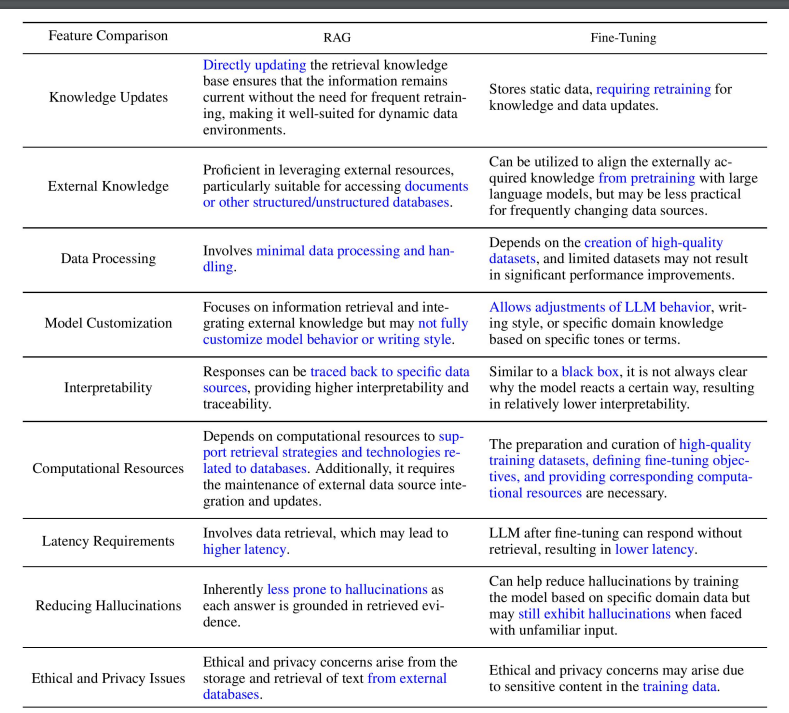
RAG就像是为模型提供了一本定制的带有信息检索的教科书,非常适合特定领域的查询。另一方面,FT就像是随着时间的积累将知识内化的学生,因此更适合模仿特定的结构、风格或格式。FT可以通过增强基础模型的知识、调整输出和教授复杂指令来提高模型的性能和效率。然而,它不擅长整合新知识或快速迭代新的使用案例。RAG和FT并不是相互排斥的,它们是互补的,结合起来使用会产生更佳的效果。
RAG 应用
RAG 非常适合下面的场景:
- 频繁更新的知识
- 需要验证和可追溯性的答案
- 专业领域知识
- 数据隐私保护
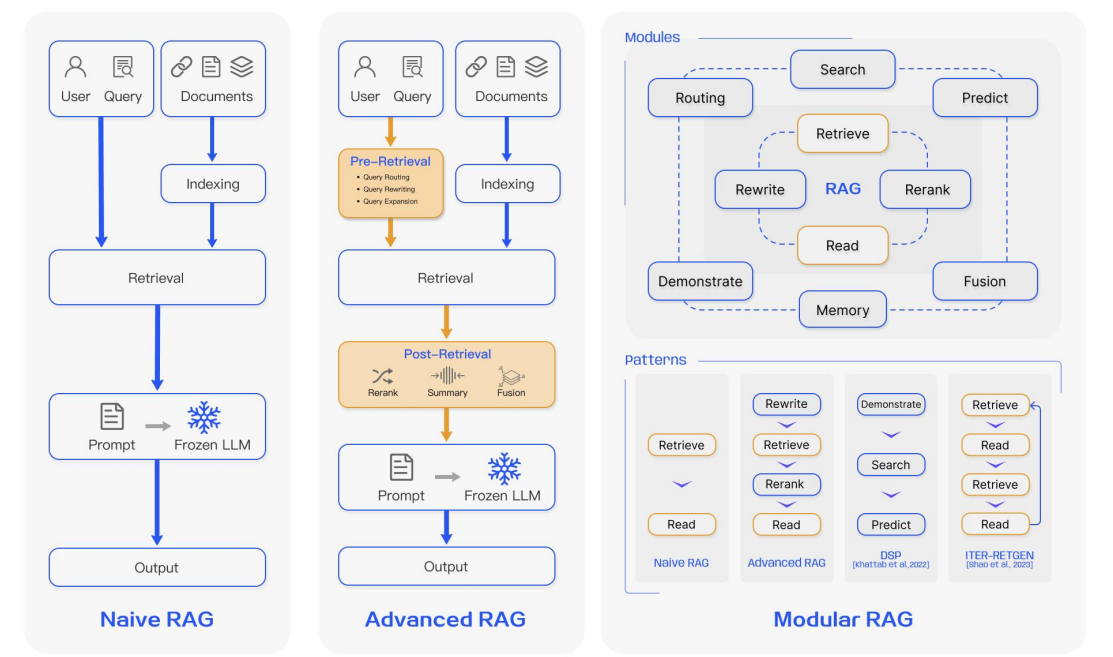
RAG 范式的演变
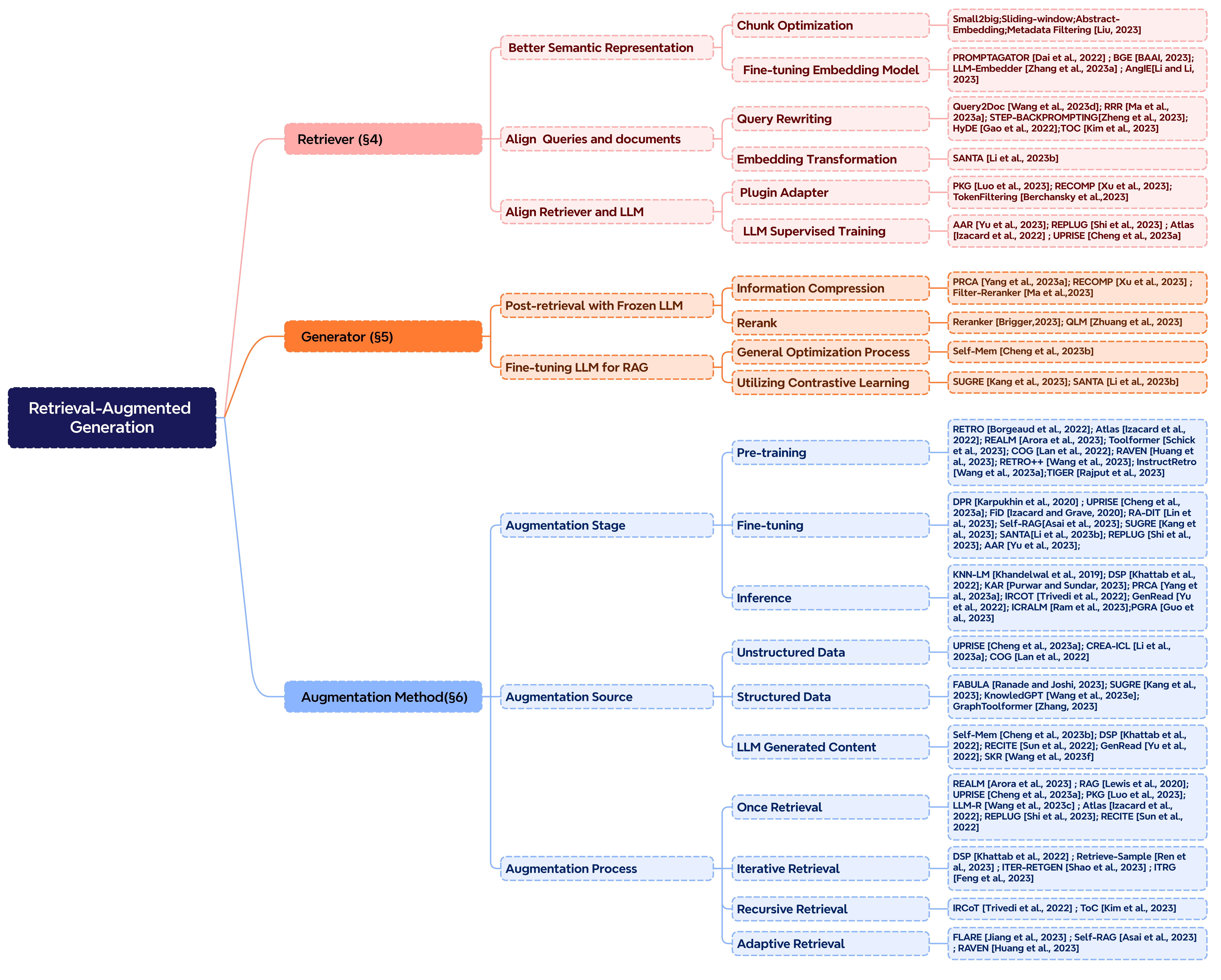
作者将RAG分为Naive RAG,Advanced RAG,和Modular RAG三种范式。
Naive RAG 就是传统的RAG 流程,先Indexing,然后Retrieval,最后Generation。Naive RAG在检索、生成和增强方面面临着许多挑战,因此随后提出了Advanced RAG范式,增加了预检索和检索后处理中的额外处理。在检索之前,可以使用query改写、routing路由和query扩展等方法来对齐问题和文档块之间的语义差异。检索后,对检索到的doc进行一个rerank,可以避免“中间丢失”现象,也可以对上下文进行过滤压缩,缩短窗口长度。
随着RAG技术的进一步发展和进化,产生了模块化RAG的概念。在结构上,它更自由、更灵活,引入了更具体的功能模块,如查询搜索引擎和多个答案的融合。在技术上,它将检索与微调、强化学习和其他技术相结合。在流程方面,RAG模块经过设计和编排,形成了各种RAG模式。
然而,模块化RAG也不是突然出现的,三种方式存在继承与发展的关系。可以这么理解Advanced RAG是模块化RAG的一个特例,而Naive RAG是Advanced RAG的特例。
RAG的三个关键问题
- 检索粒度 可以是token、短语,还是chunk,段落、实体或者知识图谱
- 什么时候检索
- 如何利用检索到的信息
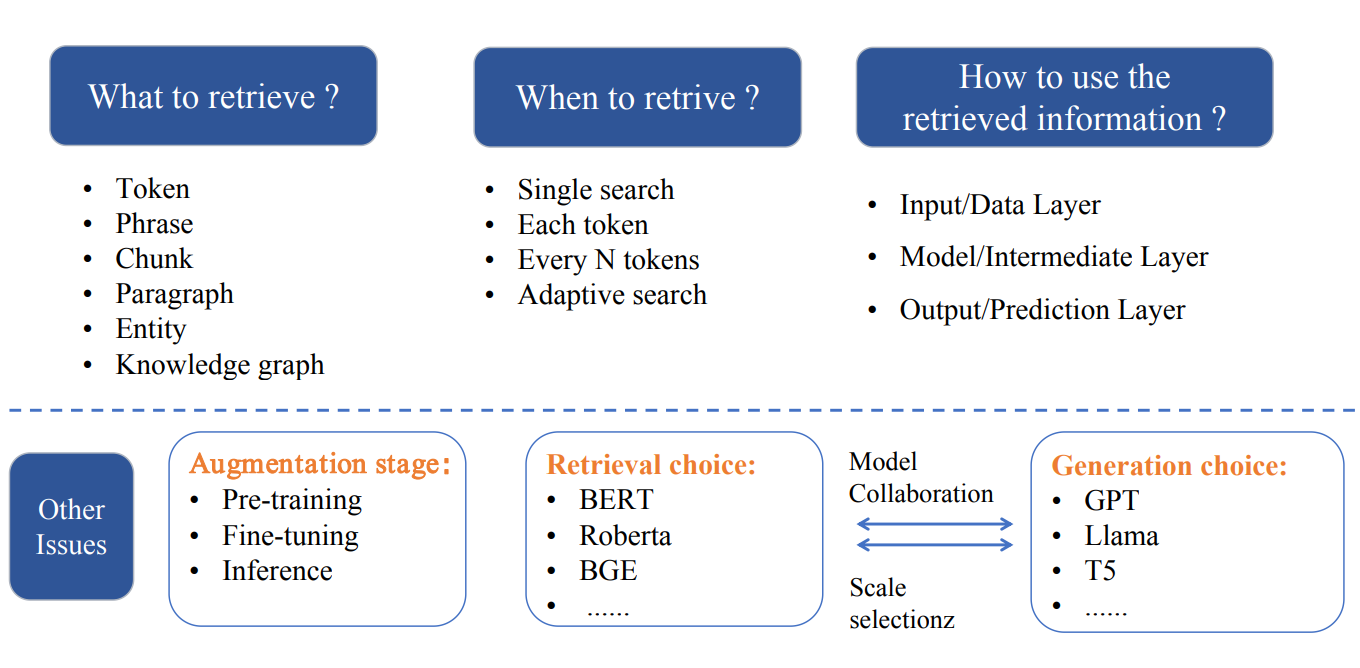
关于检索什么层级的内容,我们可以从检索粒度的粗细,以及数据结构化的高低来看业界研究结果。
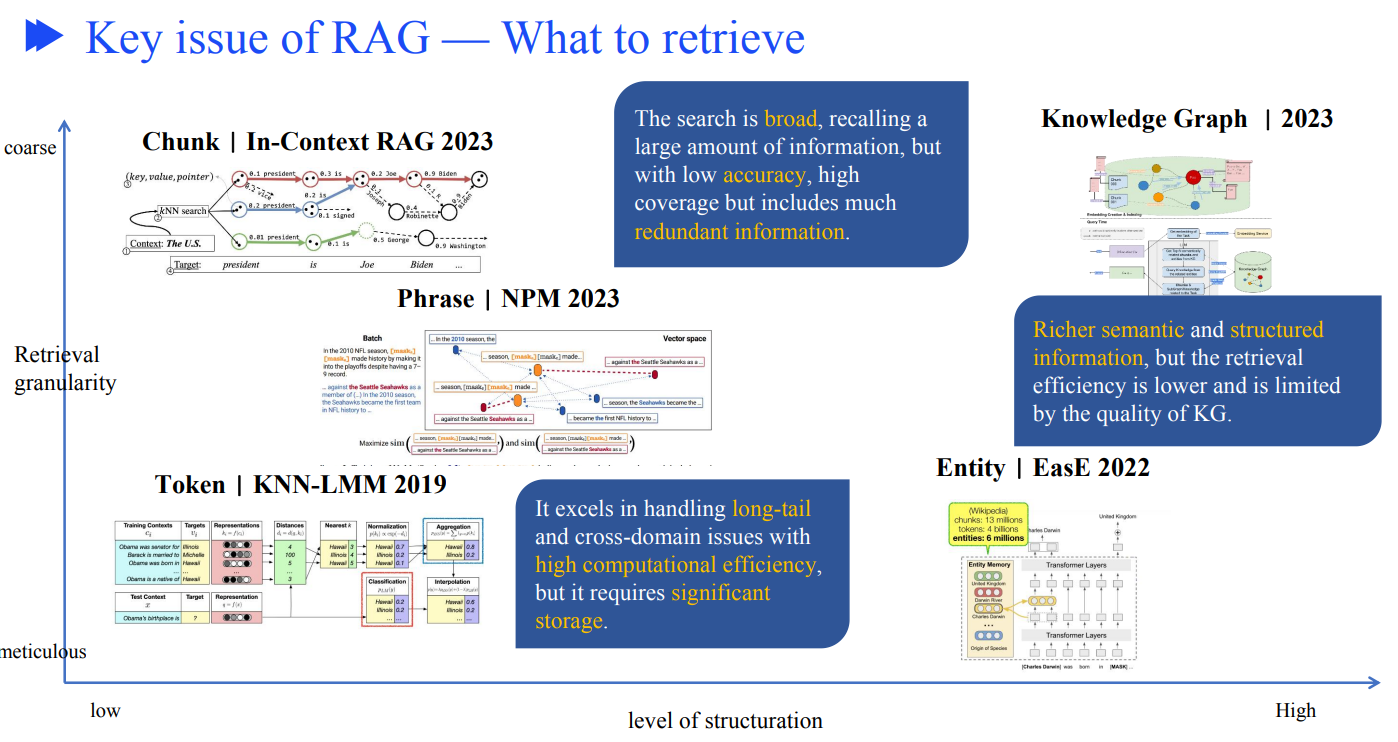
X轴结构化从低到高,Y轴从精细到粗粒度。
三个代表:
- Chunk级别,非结构化数据,搜索会召回大量信息,但是准确度低,会包含冗余信息
- 知识图谱,丰富的语义和结构化数据,检索效率低,效果严重依赖KG的质量
- KNN-LMM 擅长处理长尾和跨域问题,计算效率高,但需要大量存储
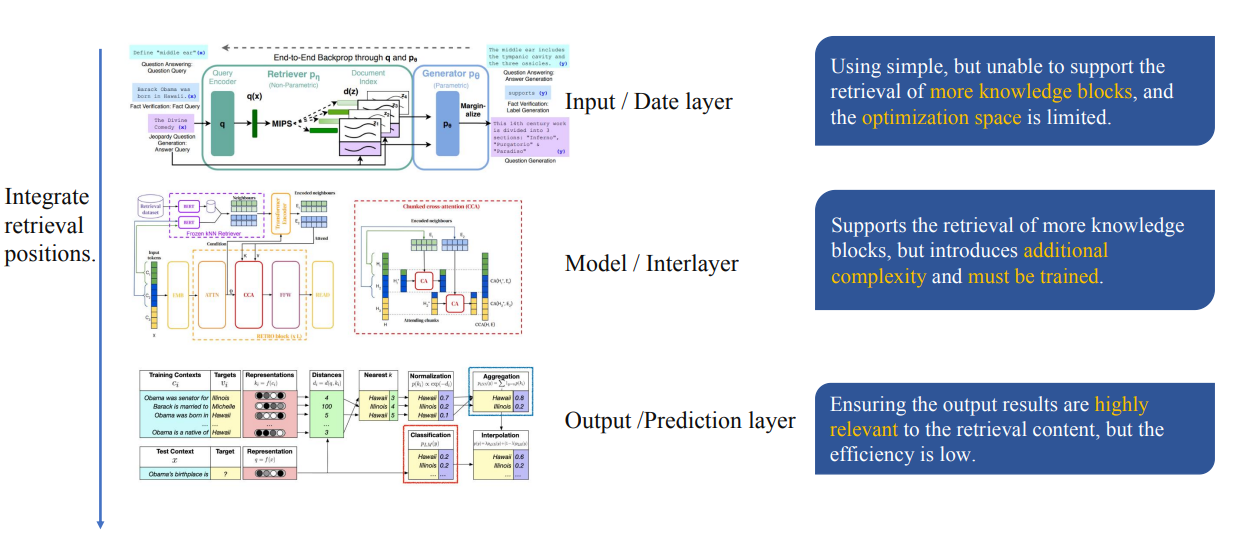
如何使用检索到的内容
在推理过程中,将检索到的信息集成到生成模型的不同层中
检索的时机
按照检索的频率从低到高,有:
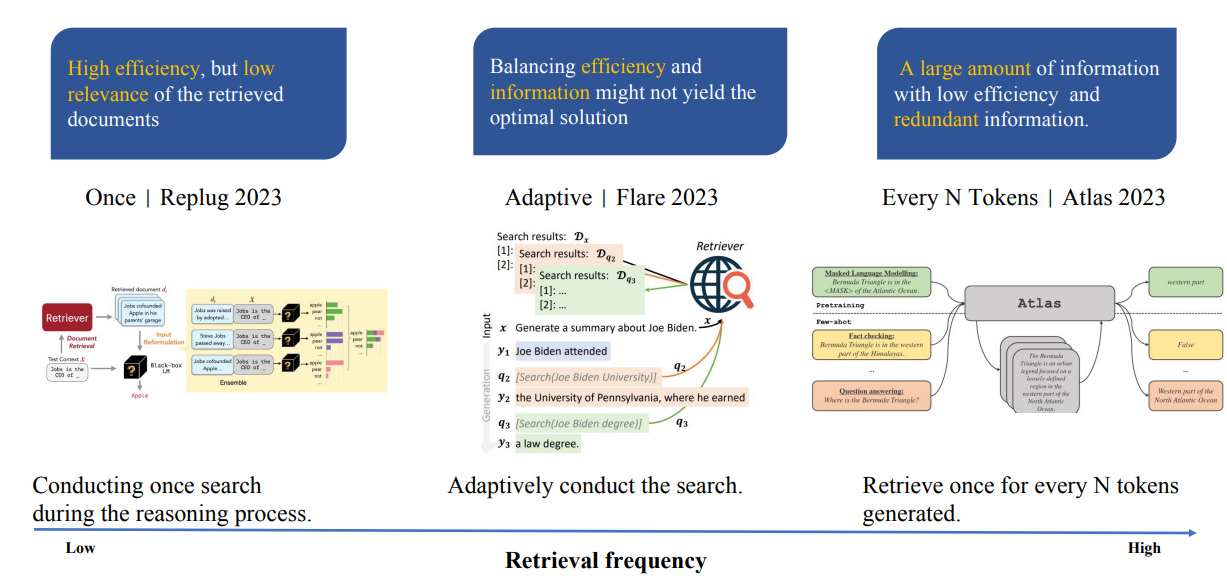
- 一次检索,只检索一次,效率高,但可能导致检索结果相关度低
- 自适应检索,平衡效率和检索效果
- 每N个token检索1次,会导致检索次数过多,并召回大量冗余信息
RAG 技术发展树
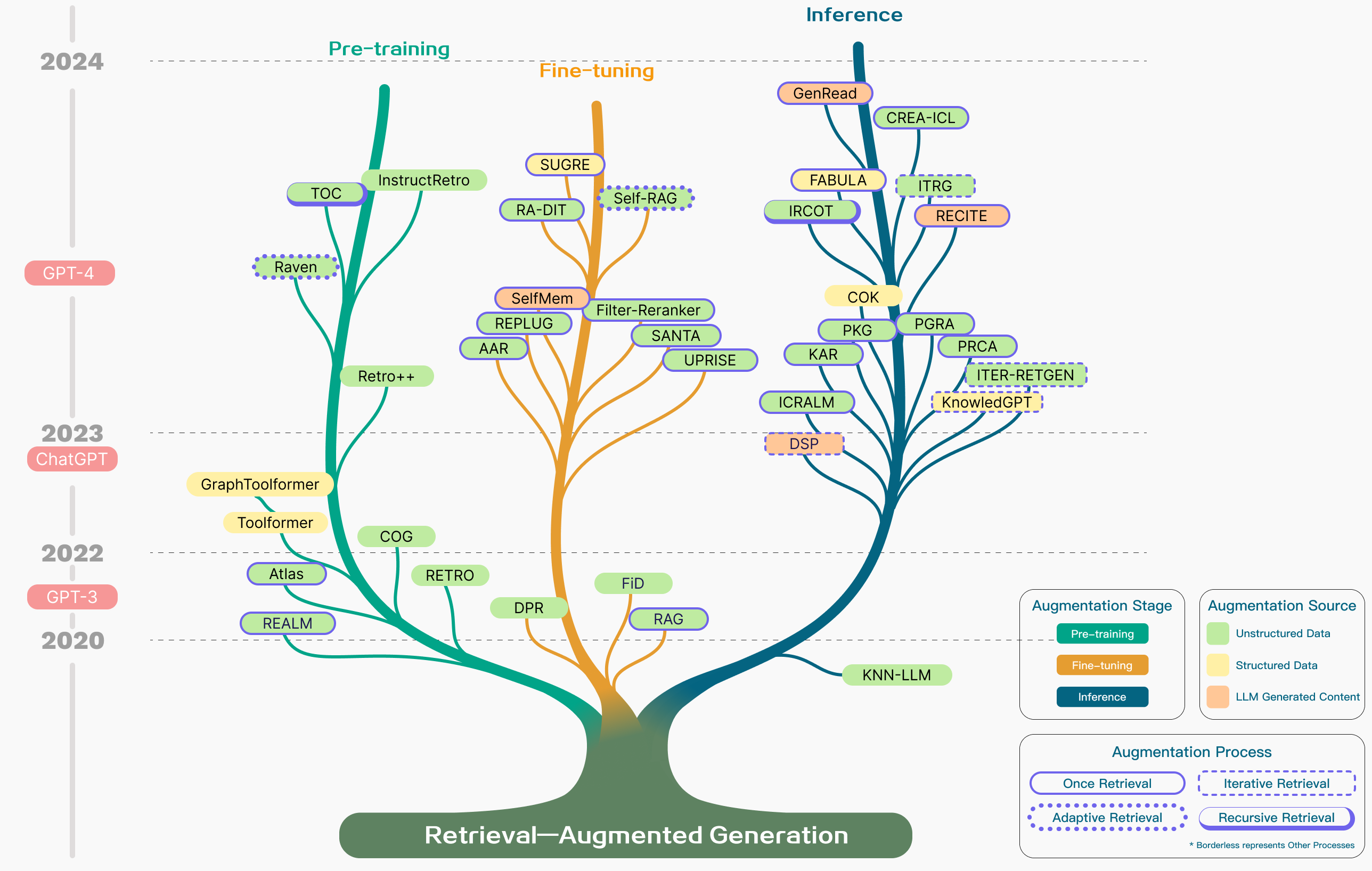
RAG 关键技术
数据索引优化
- 核心是chunk的策略:
- Small-2-Big 在sentense级别做embedding
- Slidingwindow 滑动窗口,让chunk覆盖整个文本,避免语义歧义
- Summary 通过摘要检索文档,然后从文档中检索文本块。
- 另外为了提升效果,还可以添加一些额外的meta信息,例如page,时间,类型,文档标题等。
- 有了meta,就能进行过滤,或者增强信息量
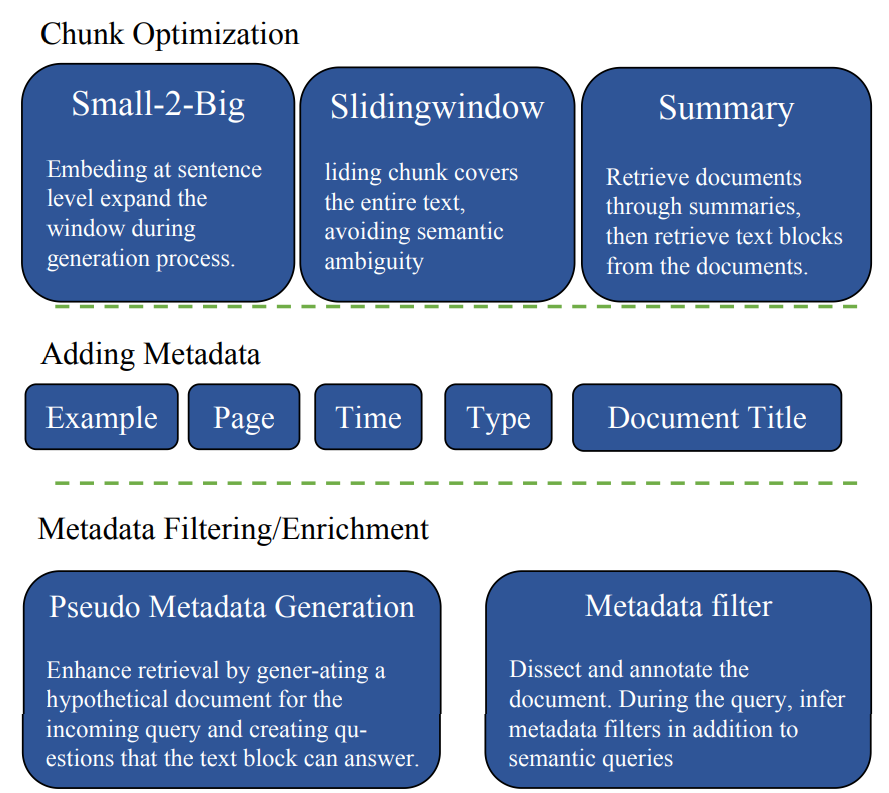
Small 2 Big方法:
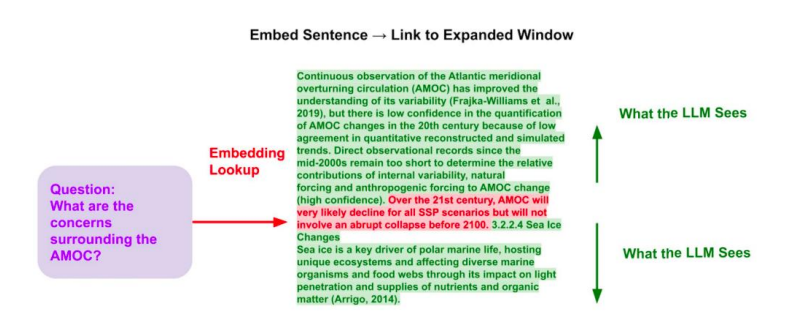
Abstract方法
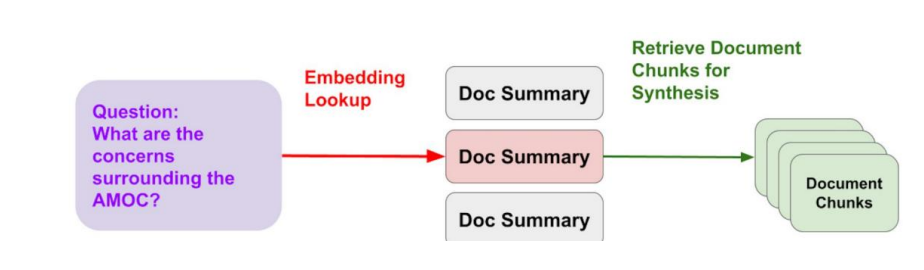
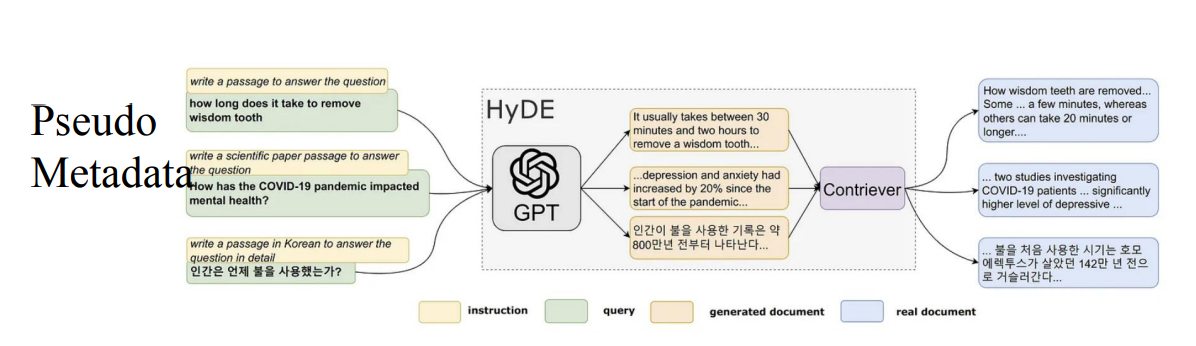
伪metadata方法,也就是HyDE,y将用户的原始查询转换为一个或多个假设性文档。这些文档是针对查询构建的文本片段,它们包含了可能回答查询所需的信息,然后用这些文档计算embedding,从真实文档库检索真实的文档,识别出与原始查询最相关的文档,检索到的真实文档被用作生成响应的上下文信息,可以辅助语言模型生成更准确、更相关的回答。
meta过滤方法:
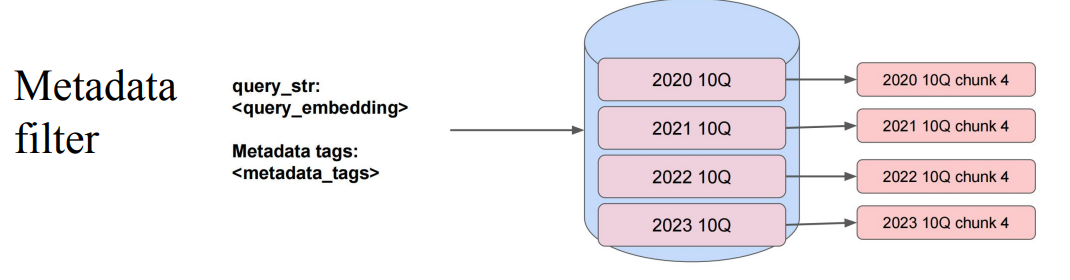
核心就是数据很多,通过meta过滤,可以减少范围,提高精度。
结构化检索文档库
可以分层组织检索文档库
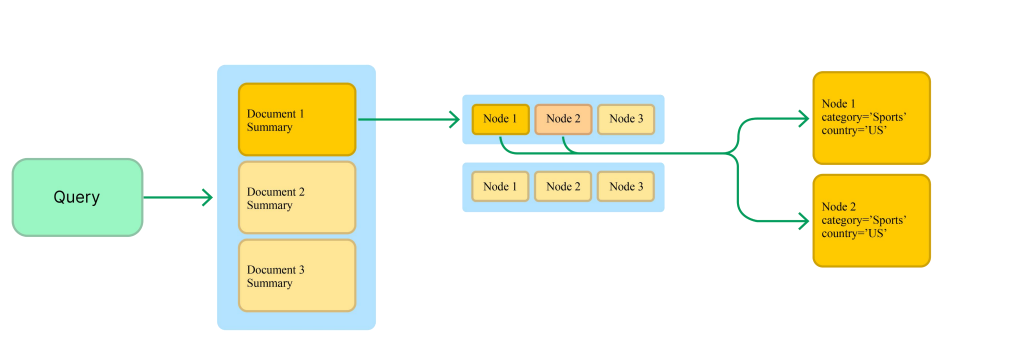
- Summary → Document方法, 用摘要检索取代文档检索,不仅可以检索最直接相关的节点,还可以探索与这些节点相关的其他节点。
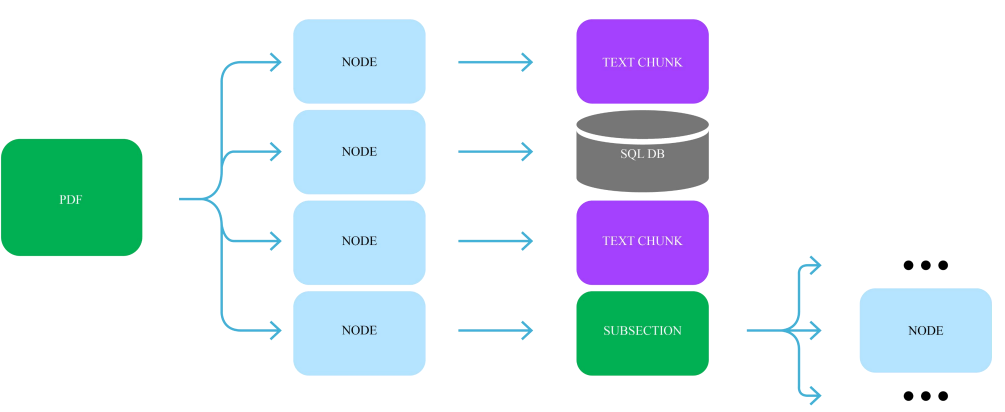
- Document → Embedded Objects 比如一个PDF文档具有嵌入对象(如表、图表),首先检索实体引用对象,然后查询底层对象,如文档块、数据库、子节点
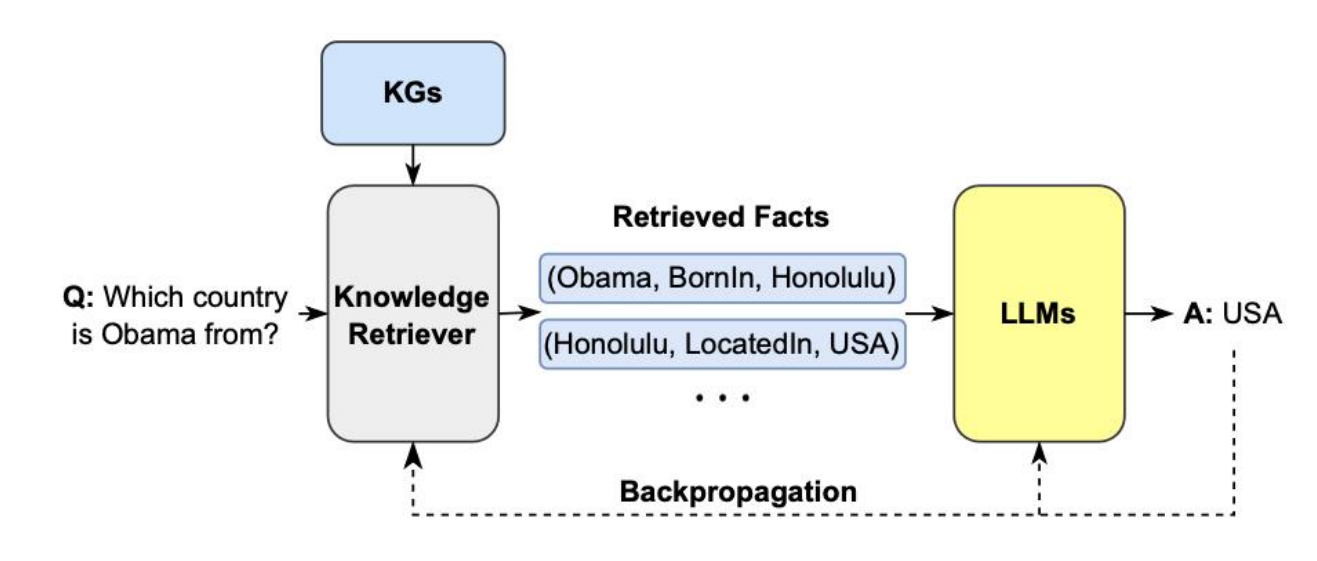
KG作为召回数据源
GraphRAG 从用户的输入查询中提取实体,然后构建子图以形成上下文,并最终将其输入到大模型中进行生成
- 使用LLM 从问题中提取关键entity
- 基于提取的到entity实体,检索子图,并深入到一定的深度,比如2跳或者更多
- 利用获得的上下文通过LLM生成答案
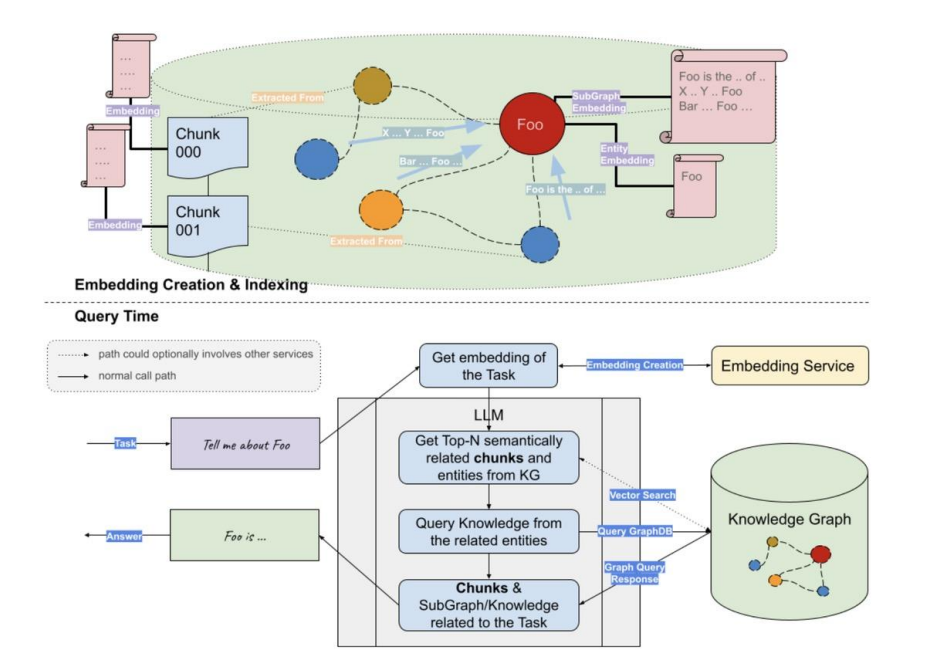
下面是一个具体的案例:
Query 优化
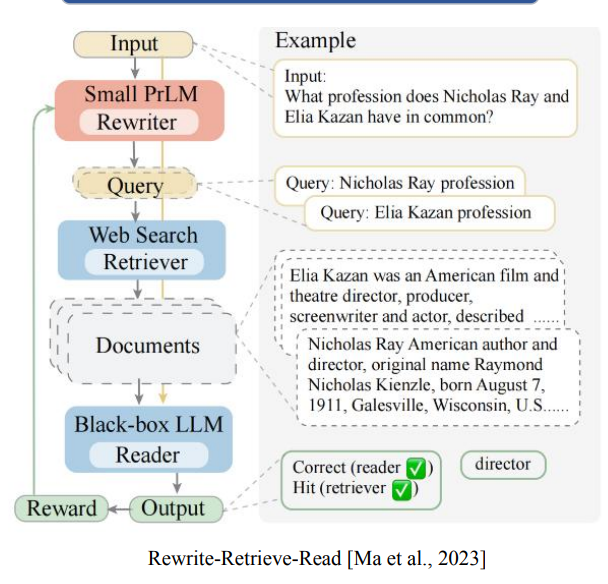
问题和答案并不总是具有很高的语义相似性,所以我们可以适当的调整query,以便获得更佳的检索效果,可以通过Query Rewriting改写技术和Query Clarification 澄清技术。
- Query 改写: 将query改写成一个或者多个search query,分别查询,这样可以得到更佳的召回效果,比如下面例子中,问两个人的共同
profession职业,那么可以先分别查询各自的,然后让大模型去解决。
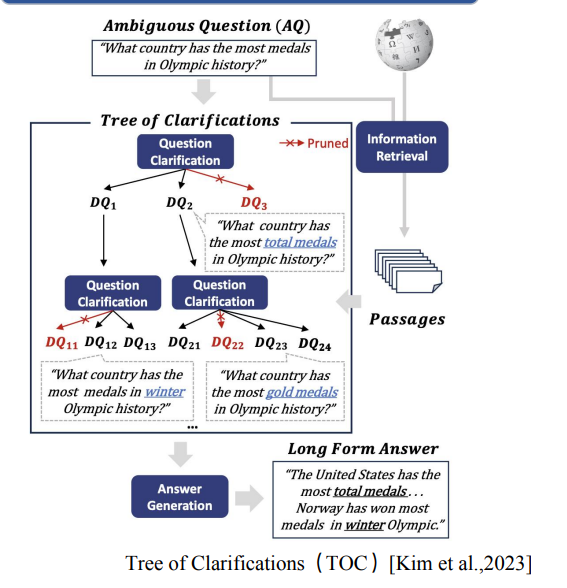
- Query Clarification
Embedding 嵌入模型优化
- 一方面,可以选择一个合适的商用embedding 供应商,比如:

- 另外一方面,可以自己微调embedding模型,现在业界有很多还不错的embedding模型,比如BAAI的BGE模型
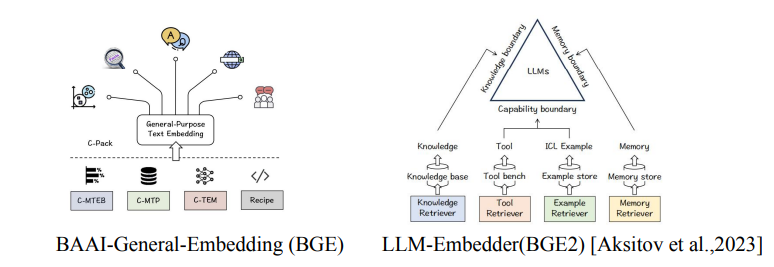
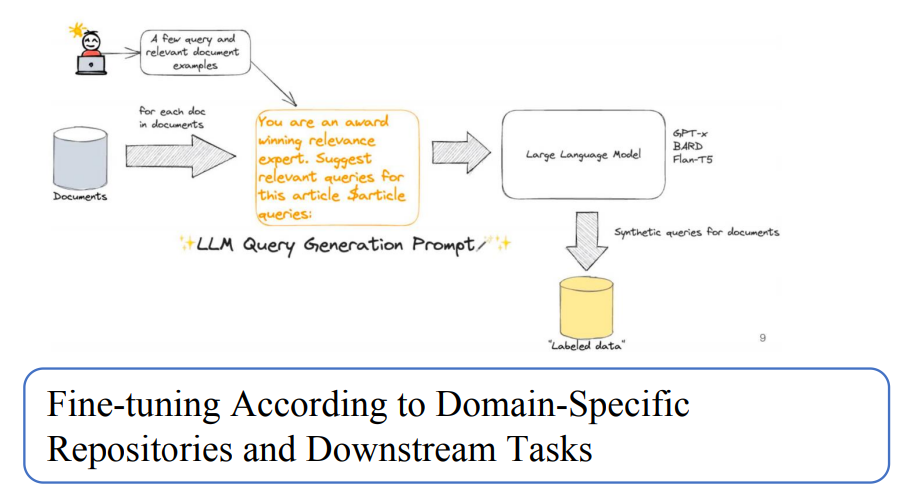
- 微调的方法,可以通过领域数据和下游任务需要去微调
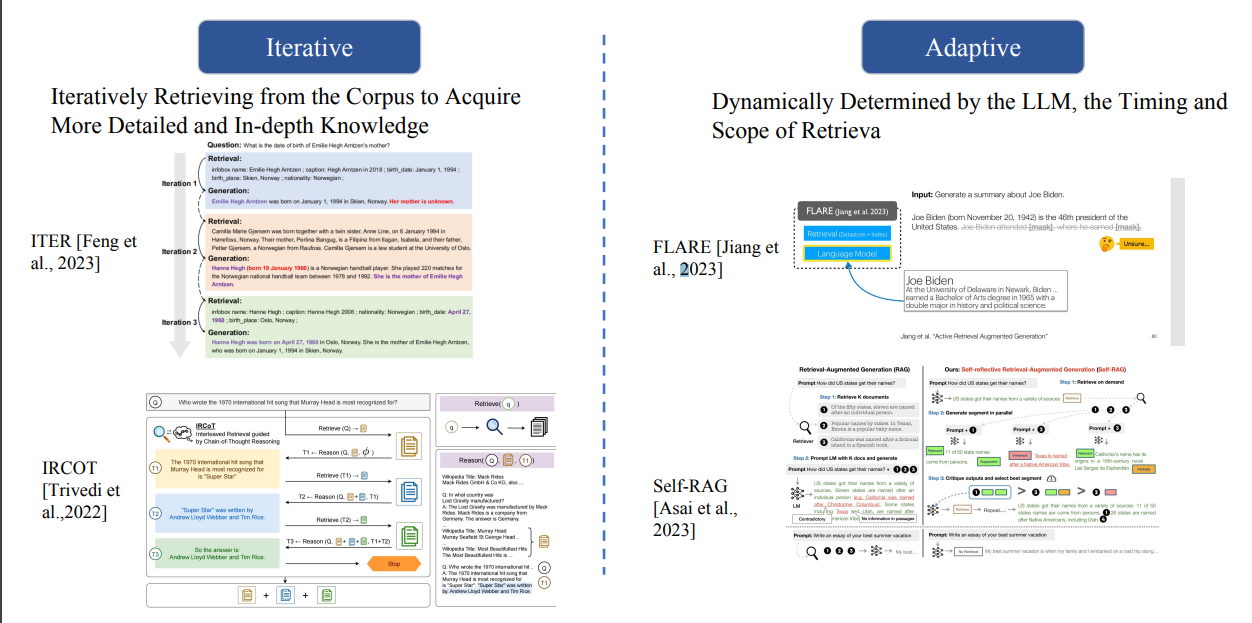
检索流程优化
在检索流程方面,可以有Iterative迭代式检索,也可以Adaptive自适应检索
Hybrid (RAG+Fine-tuning) 融合RAG和FT
既可以检索FT,也可以生成FT,还可以进行检索,生成联合FT
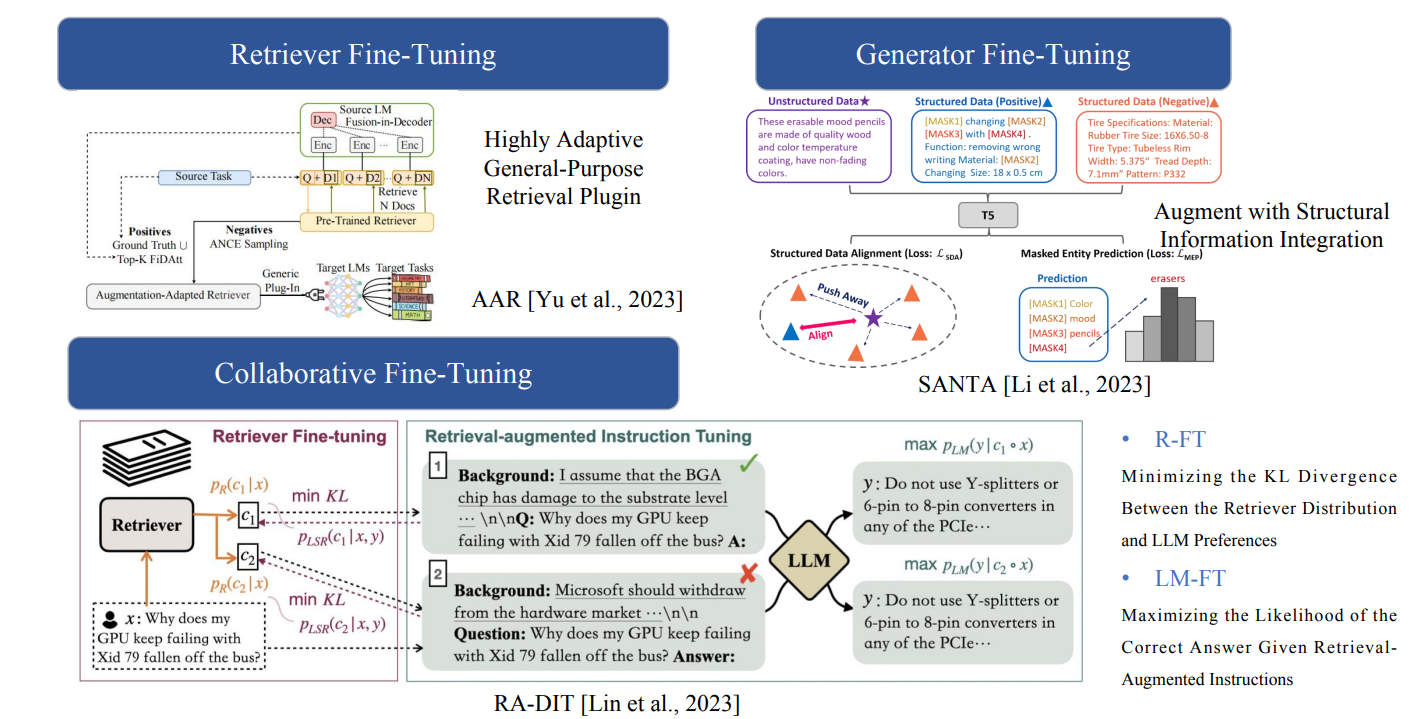
相关研究总结
RAG 评估
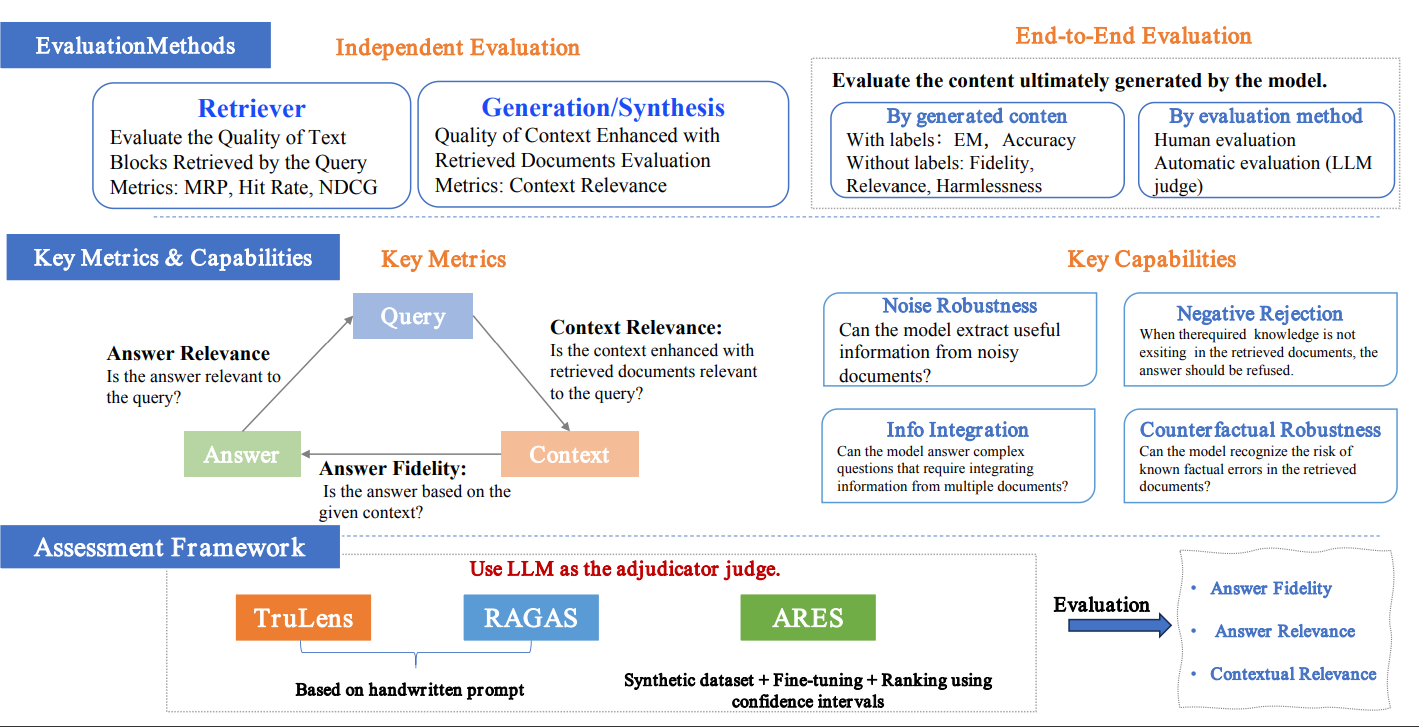
- 评测方法层面,可以检索和生成独立评测,也可以端到端进行评测
- RAG 的评估办法很丰富,主要包括三个质量分数:上下文相关度、答案忠实度、答案相关度
- 评估涉及四项核心能力:鲁棒性、拒识能力、信息整合能力和反事实解释
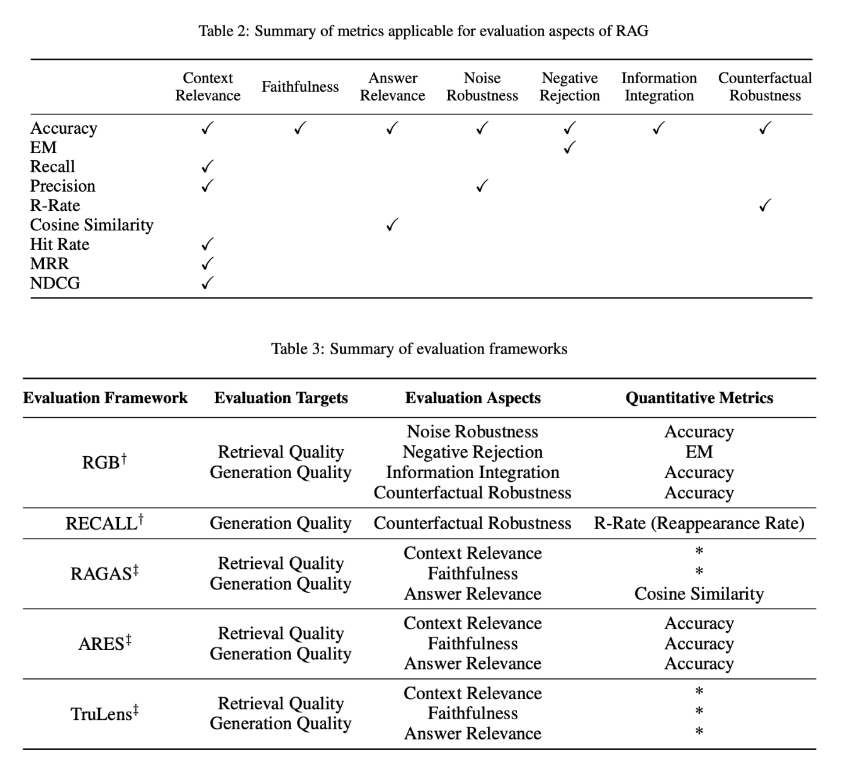
- 评估框架方面,有 RGB、RECALL 等基准指标,以及 RAGAS、ARES、TruLens 等自动化评估工具,可以较全面地衡量 RAG 模型的性能。
下面补充一些信息:
具体来说,评估方法主要围绕其两个关键组件:检索(Retrieval)和生成(Generation)。评估这些组件的性能涉及到多个质量分数和能力,这些分数和能力共同反映了 RAG 模型在信息检索和生成过程中的效率。
检索质量评估指标:
- Hit Rate (HR):命中率,衡量检索结果中相关文档的比例。高命中率意味着检索系统能够更准确地找到用户查询相关的信息。
- Mean Reciprocal Rank (MRR):平均倒数排名,衡量检索结果中相关文档的平均排名的倒数。MRR 越高,表示检索系统的性能越好。
- Normalized Discounted Cumulative Gain (NDCG):归一化折扣累积增益,用于衡量检索结果列表中相关文档的排名质量。NDCG 考虑了文档的相关性和排名位置。
- Precision:精确率,衡量检索结果中被正确识别为相关的文档的比例。
- Recall:召回率,衡量检索系统找到的相关文档占所有相关文档的比例。
- R-Rate (Reappearance Rate):再次出现率,衡量检索结果中信息在后续生成文本中的出现频率。
生成质量评估指标:
- Context Relevance:上下文相关性,评估生成的文本与检索到的上下文之间的相关性。
- Answer Faithfulness:答案忠实度,确保生成的答案忠实于检索到的上下文,保持一致性。
- Answer Relevance:答案相关性,要求生成的答案直接相关于提出的问题,有效解决问题。
- Accuracy:准确性,衡量生成的信息的准确性。
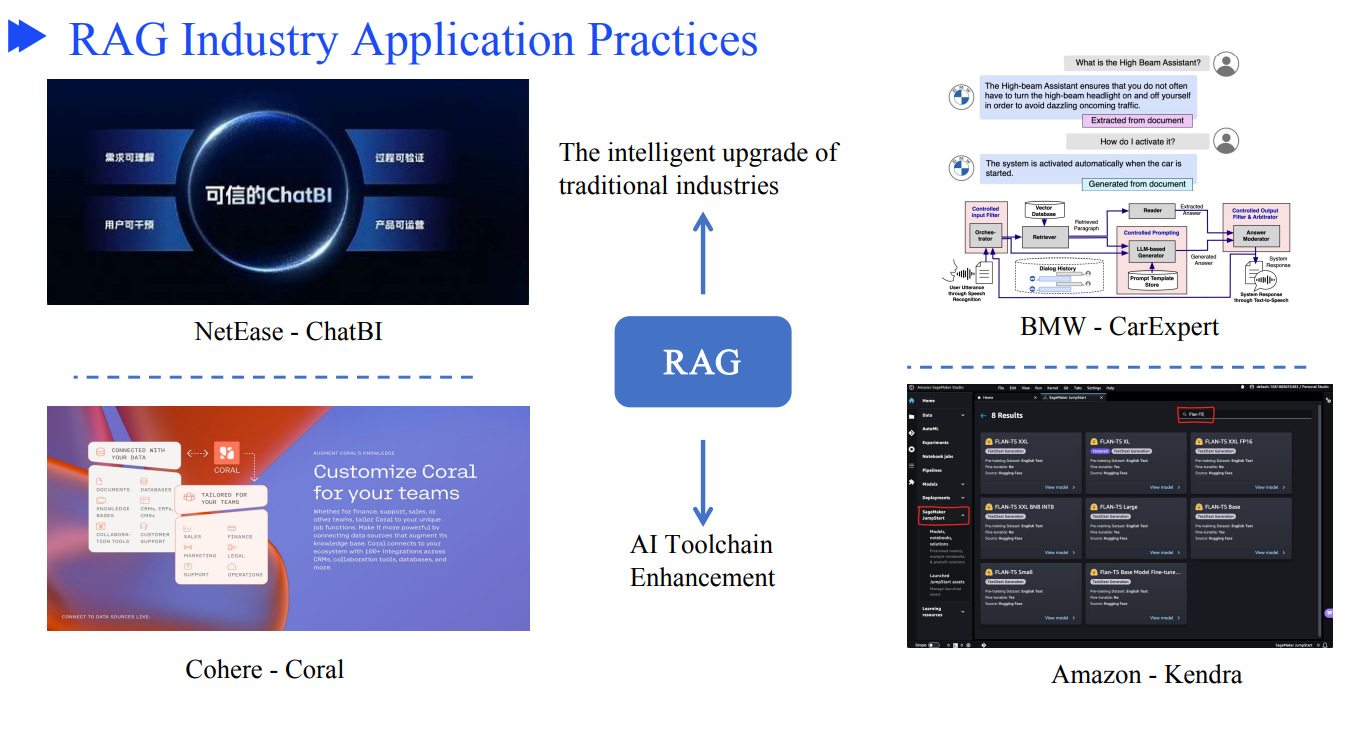
RAG 技术栈与工业界实践
当前有LangChain、LlamaIndex、AutoGen等流行的开发框架,可以方便开发RAG应用。
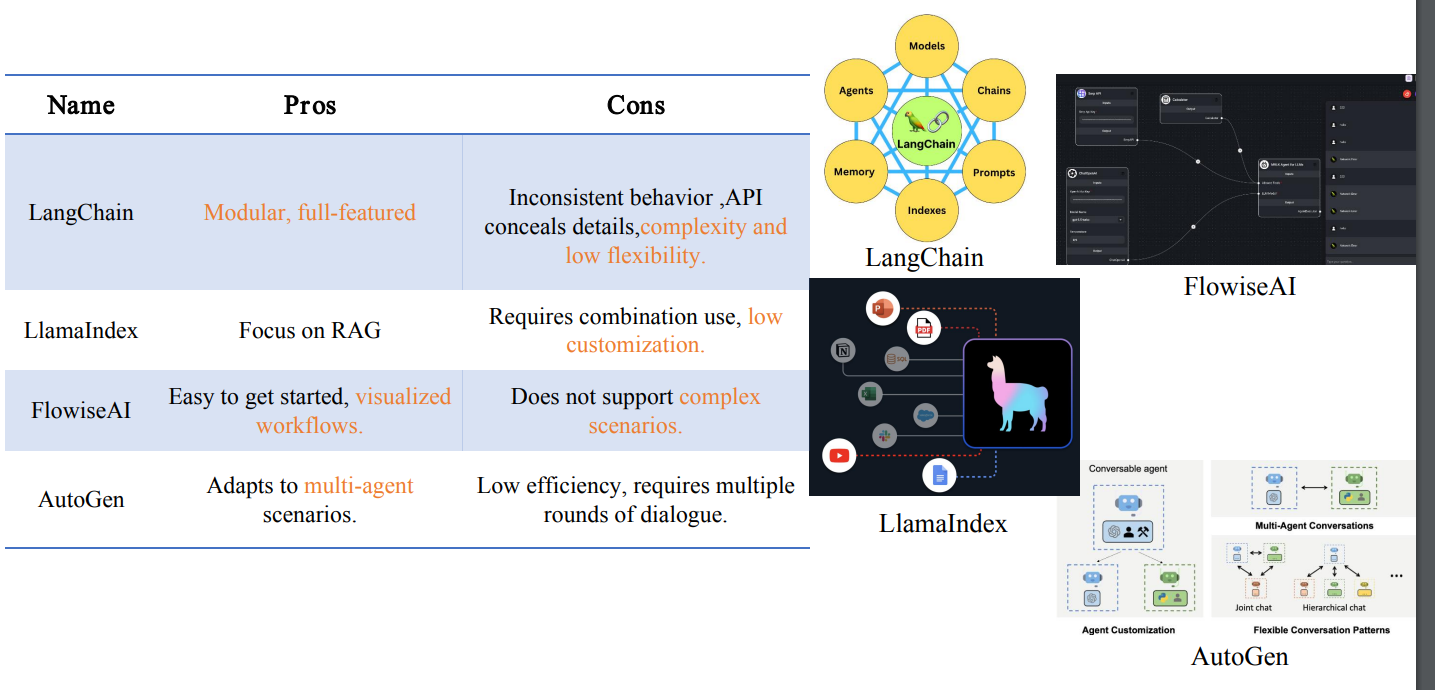
工业界也有很多RAG应用。
总结与展望
RAG 技术框架
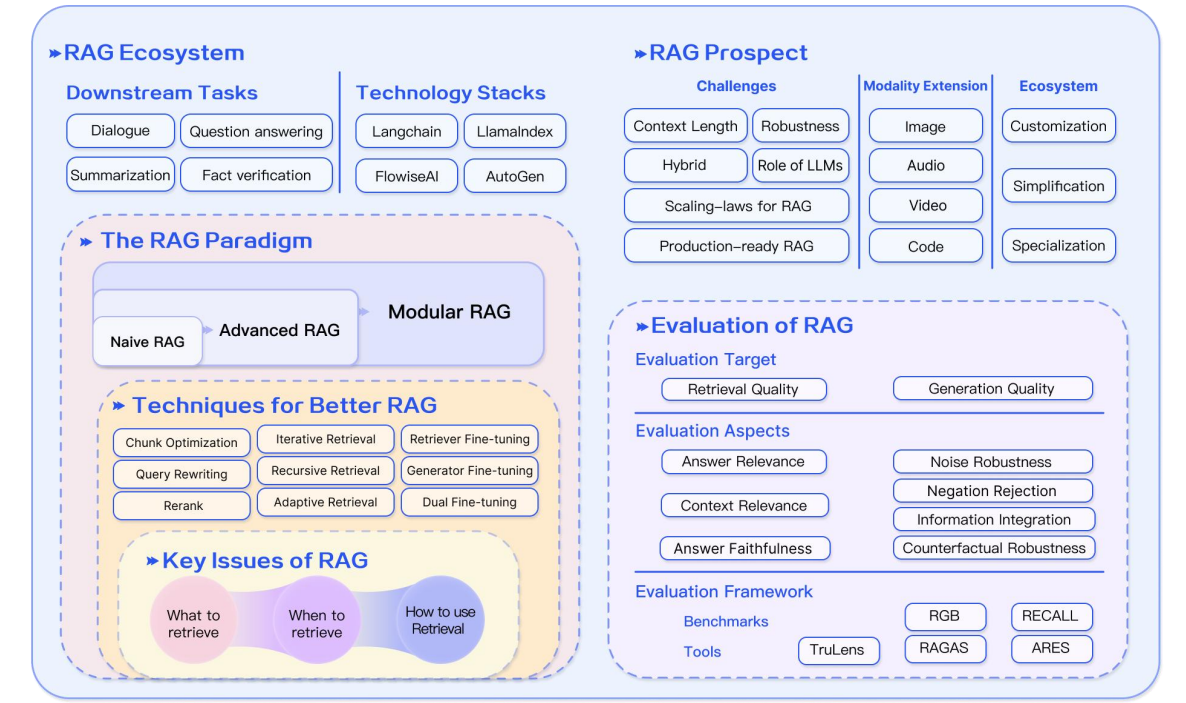
RAG 的三个研究热点
RAG 的挑战
- 与FT的协同
- 如何应用好LLM,充分挖掘利用LLM
- 提升鲁棒性,比如如何处理错误的召回内容,如何过滤和验证召回内容
- RAG 是否也遵循Scaling Law
- 最佳工程实践,比如提升在大数据量下的检索延迟,如何保障隐私的检索内容不被LLM泄露
多模态扩展
将RAG从文本扩展到多模态
RAG 开发生态建设
扩展RAG下游任务,改善生态建设
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK