

Does sinusoid Positional Embeddings actually work well?
source link: https://donghao.org/2024/03/13/does-positional-embeddings-actually-work-well/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Does sinusoid Positional Embeddings actually work well?
The GPT part of my Multimodal trials mainly comes from nanoGPT. In the nanoGPT, the Positional Encoding is just a learnable tensor (“wpe” means “weights of positional embedding”):
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
drop = nn.Dropout(config.dropout),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = LayerNorm(config.n_embd, bias=config.bias),
))self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
drop = nn.Dropout(config.dropout),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = LayerNorm(config.n_embd, bias=config.bias),
))
It’s different from the implementation of the original paper. The original paper mentioned:
We also experimented with using learned positional embeddings instead, and found that the two versions produced nearly identical results.
The “vanilla” Positional Embeddings for the transformer are two functions:
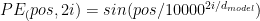
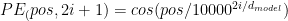
Which ones work better in the model training? Let me try running “python train.py config/train_shakespeare_char.py” in nanoGPT and get the best validation loss as metrics.
I wrote my own sinusoid Positional Embeddings for testing:
class GPT(nn.Module):
def __init__(self, config):
...
# Position Embedding from original Transformer paper
divisor = torch.pow(
10000, 2 * torch.arange(1, config.n_embd + 1) / config.n_embd
)
pe = []
for pos in range(1, config.block_size + 1):
if pos % 2 == 0:
pe.append(torch.sin(pos / divisor).unsqueeze(0))
else:
pe.append(torch.cos(pos / divisor).unsqueeze(0))
self.register_buffer("pos_emb", torch.cat(pe, 0))class GPT(nn.Module):
def __init__(self, config):
...
# Position Embedding from original Transformer paper
divisor = torch.pow(
10000, 2 * torch.arange(1, config.n_embd + 1) / config.n_embd
)
pe = []
for pos in range(1, config.block_size + 1):
if pos % 2 == 0:
pe.append(torch.sin(pos / divisor).unsqueeze(0))
else:
pe.append(torch.cos(pos / divisor).unsqueeze(0))
self.register_buffer("pos_emb", torch.cat(pe, 0))The “10000” (let’s call it “base number” for convenience) looks too big for a shorter sequence length, so I do experiments by changing it to “block_size” “2*block_size” etc.
The testing result:
| validation loss | |
| Original nanoGPT | 1.4754 |
| Base number: 10000 | 1.4959 |
| Base number: 4 * block_size | 1.4916 |
| Base number: 2 * block_size | 1.4995 |
| Base number: 3.14/2 * block_size | 1.4870 |
| Base number: block_size | 1.4947 |
From my simple tests, the learnable Positional Embeddings has the best effort. nanoGPT wins this round.
I have a guess about why the author of Transformer chose “10000”. The smallest “pos” is 1 and the biggest
is 2. Therefore the smallest value in sin() is
, which is very close to the minimal value of FLOAT16
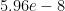
Related Posts
- Run docker on centos6
Docker use thin-provision of device mapper as its default storage, therefore if we wan't run…
March 13, 2024 - 0:52
RobinDong
machine learning
nanoGPT, PyTorch
Leave a comment
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Comment *
Name *
Email *
Website
Save my name, email, and website in this browser for the next time I comment.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK