
0

AI 共筆 - 台灣本土版語言模型 - Taiwan LLM 是怎麼煉成的?
source link: https://blog.darkthread.net/blog/how-taiwan-llm-trained/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Taiwan LLM 是怎麼煉成的?-黑暗執行緒
2024 新年第一天,拜年文就由 AI 打頭陣吧! 跟風附上 AI 生成圖,祝大家在新的一年神采飛揚,龍光煥發!

在訓練大型語言模型有多燒錢?一文學到:標榜最有台灣味的 Taiwan-LLM 語言模型,是以 Meta LLaMA 2 為基礎的全參數微調模型,大幅提升繁體中文能力並融入台灣文化。Taiwan LLM 採用的訓練方式包含 8 x A100 兩週 Continuous Pretraining (接續預訓練,讓 LLaMA 2 學中文) 及 8 x H100 12 小時的 Instruction Fine-Tuning。我對它的訓練方式格外好奇,意外找到 Taiwan LLM 計劃主要參與者,台大博士生林彥廷同學的第一現場報導影片 - Taiwan LLM 解析台灣第一個大型對話式語言模型,內容還算淺顯,只稍具機器學習基本概念如我,即便看不懂門道,也能有點收獲,特記錄重點備忘。
- LLaMA 2 不是原本就會講中文?為什麼還要學中文?
LLM 的訓練資料繁體中文佔比很低,在全世界的文本可能佔不到 0.1% (英文 54%、西班牙文 30%,中文僅 1%;其中簡體中文 90%,繁體中文 10%)。語言不只是翻譯就好,在文化、價值觀、常識(例如:發票載具)方面也要對齊才算在地化,使用者多聊兩句便能感受這是會講中文的外國機器人,還是真的具有台灣魂?要融入本地語精神,需要用大量台灣文本進行預訓練才能實現。 - Taiwan LLM 的訓練程序為何?
分為三階段:Continuous-Pretraining (使用台灣語料 Corpus 進行接續預訓練, cPT) -> Supervised Fine Tuning (SFT) -> Real User Interaction and Reinforcement (上網公測,蒐集回饋) - Taiwan LLM 用了哪些台灣語料進行 cPT?
V1 用維基百科跟網路資料(CommonCrawl),但發現網路資料品質不佳(包含太多詐騙、色情、政治性),需要大量事後調校修正。V2 改用社群媒體、法律文件、新聞時事取代網路資料,共 35B。(相較國外文本 1 ~ 2T 起跳,其實還是很少)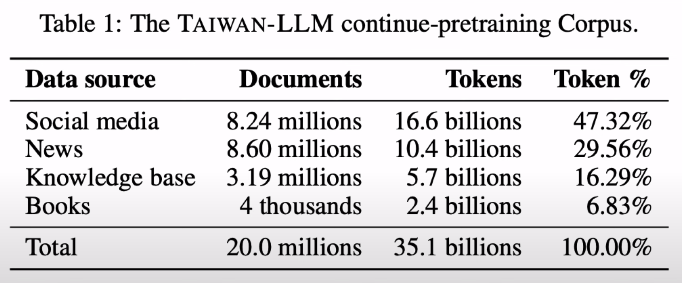
V2 拿掉網路資料後,cPT 完的結果價值觀回答方式已經很接近台灣人,偏差小很多,大幅減少微調工程。結論:從源頭控管可以省很多工夫。
cPT Context 長度上限 4000 (相當於短期記憶)、每個文本只看一次 (1 Epoch)、加速技巧:Fully Sharded Data Parallel(FSDP、DeepSpeed)、Flash Attention v2 (利用 GPU 結構減少 Memory 搬運次數,A100/H100 支援)、bfloat16 (源自 Meta RD 的血淚心得,bfloat 16 (Range 大,精準度低) + 更多資料 = 效果較好,目前較流行 fp16、bfloat16,開始有人用 fp8) - 為什麼用 cPT 而非重新訓練?
Google DeepMind 研究,Chinchilla Scaling Laws 一個參數至少要訓練在 20 個 Token 以上,35B / 20 < 2B,這個資料量只能從頭訓練不到 2B 的模型。故以 LLaMA 2 7B、13B 模型為基礎接續訓練,成本效益較好。 - cPT 過程有遇到什麼困難?
下圖紫線是 Taiwan LLM 的 Loss 曲線,隨 global step 步數增加 Loss 會下降,但會有上下波動的細線叫 Loss Spike,這類不穩定常來自於 Memory 之類的錯誤,解法是 Rollback 忽略會出錯的資料。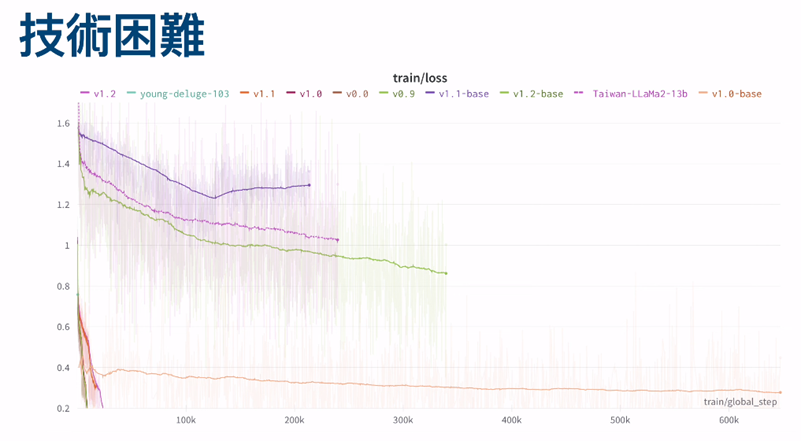
- SFT 如何進行?
蒐集 Instruction Tuning 資料集(人工蒐集 + ChatGPT 翻譯產生 50 萬條、用史丹佛 Alpaca 手法生成),共 100 萬條(事後覺得太多,浪費過多算力)。範圍包含:數學題、程式題、知識問答、推理題、文章摘要、創意寫作、翻譯題、角色扮演、閒聊...
初版模型不夠「台」,解法是手寫 100 條 QA,再請 ChatGPT 換句話說衍生資料。 - Taiwan LLM 有進行公開測試,大家都怎麼跟機器人聊天?
事後分析 Log,互動幾乎都傾向知識問答,幾把機器人考倒為樂。如要商業應用,這是個值得思考的問題,所有聊天服務都被拿來跟 ChatGPT 4 比較,7B/13B 的模型可能會遠低於對方期望。建議明確聲明定位及能力範圍,降低使用者期待。 - 如何客觀評測 Taiwan LLM 表現?
有個資料集叫 Taiwan Trivia QA (MediaTek Research 聯發創新提供,題例:濁水溪、孫越、櫻花勾吻鮭),Taiwan LLM 小勝 ChatGPT,不如 ChatGPT 4。(註:評測結果未必與體感一致,數字很好看,但使用者感受未必是好的)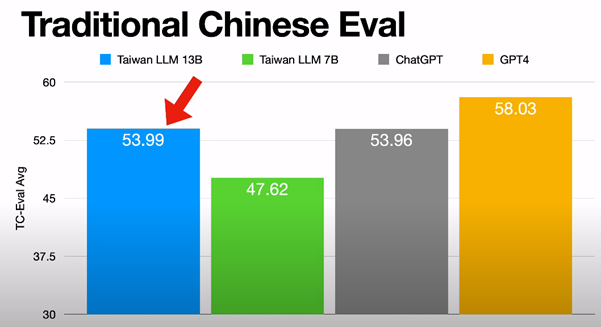
案例:NTU 是什麼的縮寫、22K 是什麼、發票載具是什麼意思 - Taiwan LLM 的適用場合?
- 要落地在自家伺服器執行(資料不允許外流) 2) 口袋不夠深玩不起 ChatGPT 微調,改微調 Taiwan LLaMA
- Mixture of Experts (MoE) 是什麼?
由 Mistral AI 引領風潮,MoE 8x7B 逼近 GPT 4。多個小的 FFN Layer,將任務拆成不同子任務,由 Router 交給不同專長的 FFN 處理。Taiwan LLM MoE 已開始 Pilot Run。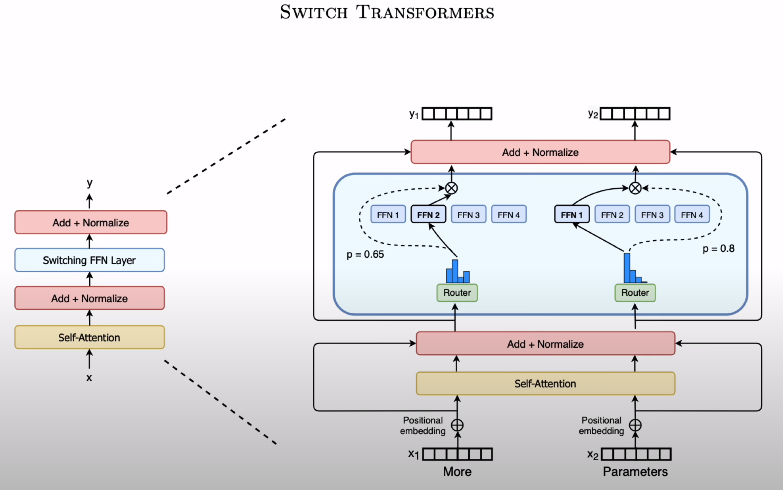
硬體支援問題:MoE 不宜跨節點,是現行數量不超過 8 的原因(八卡機),未來應會有突破。 - 有無可能蒐集更多台灣語料 (Corpus)?
電子書是個好來源,但因著作權問題,在現行法律下難以引用,或許可從法令解釋面解套。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK