

【年度专题】3D AIGC 的 2023:离改变XR 内容的生产关系或许还要一年
source link: https://www.vrtuoluo.cn/539170.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

【年度专题】3D AIGC 的 2023:离改变XR 内容的生产关系或许还要一年_VR陀螺

文/VR陀螺 WiZ
2023 年,AIGC 的风终于还是吹到了 3D 领域。一句话生成虚拟世界的口号从年初喊到了年尾,更别提刚刚结束的 CES 2024,直接将 AI 视作编织行业未来的变革技术。
AIGC 热潮下,单视角生成多视角方案成为技术热门;形态稳定、纹理优化成为新品焦点,重建大模型 LRM 的出现为市场结构带来全新变化……这一年,AIGC为虚拟内容行业带来了什么又改变了什么,VR陀螺对此专门与通义实验室XR算法科学家董子龙进行对话,以下关于3D AIGC模型的盘点及趋势总结或许可以给出一些答案。
2023 年,2D 扩散生成 3D 模型更受青睐
2023 年以 ChatGPT 的火爆全球作为开局,以支持图像输入的多模态大模型 GPT-4 的推出作为契机,大模型的多模态计算潜力开始在内容生成领域发挥技术优势,全球顶尖的科技公司和想要抓住 AIGC 风口的初创企业开始争先恐后地推出 AI 驱动的 3D 模型生成器。
梳理过去一年全球 AI 企业以及其他科研机构推出的模型后,董子龙认为目前的 3D AIGC 方案主要还是包括两种常见的技术路径。
一是从 3D 数据直接回归三维模型的方案。代表模型有 OpenAI 于 2023 年 5 月推出的的 Shap-E。

图源:OpenAI
Shap-E 是一种在 3D 隐式函数空间上的潜扩散模型,能够直接生成隐式函数的参数提取纹理网格模型。
训练 Shap-E 分为两个阶段:首先训练编码器,该编码器将 3D 资产确定性地映射到隐式函数的参数中;其次在编码器的输出上训练条件扩散模型。
该类模型的优势在于生成速度快,且生成效果较为稳定。当在配对的3D 和文本数据大型数据集上进行训练后,Shap-E 能够在几秒钟内生成复杂而多样的 3D 资产。

Shap-E的生成效果展示(图源:Shap-E)
但其缺点同样明显。该技术路径的可行性建立在大量的 3D 数据训练之下,而目前 AIGC 领域的 3D 数据集合仍较为匮乏,仅有几百万量级。同时,该技术在通常情况下无法生成高质量纹理,如果要给三维模型进行纹理贴图,仍旧需要 2D 生成模型的助力。
因此,目前行业内应用更广泛的另一种技术路径,即借助 2D 扩散模型生成 3D 模型。该方法实现从文本到 3D 模型跨越的关键在于两个技术点。
首先是 Loss 的计算,利用预训练的 2D 文生图模型,计算出三维表征渲染出的 2D 图像和文本之间的 Loss,间接判断渲染出的图像是否符合 2D 扩散模型的先验知识。
其次是通过 NeRF、DMTet 等可微分、可渲染的三维表征渲染 2D 图像,然后用2D文生图模型监督蒸馏,将Loss得到的梯度回传到这些表征当中,从而实现几何形状和颜色的优化,得到可用的 3D 模型。
结合这两个技术点,就可以在空间随机采样视点、渲染图像、计算 loss、回传梯度,并最终得到 3D 模型,该技术框架最早由谷歌 DreamFusion 提出。
目前大多数 3D 生成方法都借助2D扩散模型的技术框架形成了各自优化的特点。代表模型有“RichDreamer”、“Make-It-3D”、以及“One-2-3-45++”等。

DreamFusion的生成效果展示(图源:DreamFusion)
2023 年 8 月,来自上海交通大学、HKUST、微软研究院的研究者们提出了 Make-It-3D 方法,通过使用 2D 扩散模型作为 3D-aware 先验,从单个图像中创建高保真度的 3D 物体。该框架不需要多视角图像进行训练,并可应用于任何输入图像。
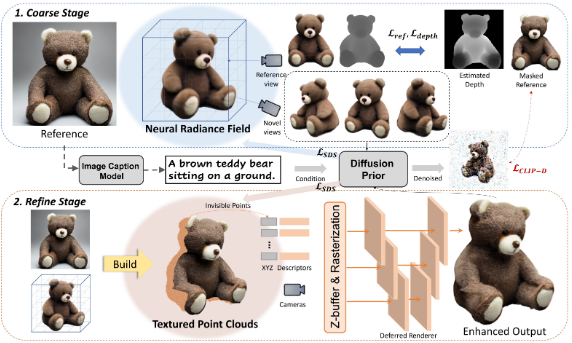
图源:Make-It-3D
2023 年 12 月,加州大学、清华大学、斯坦福大学共同开发了全新模型“One-2-3-45++”并将其开源,该模型仅通过图片,就能在 1 分钟内将一张 RGB 图像转换为高精准 3D 模型。
One-2-3-45++的核心技术原理主要包括三大块:一致的多视角图像生成、基于多视角的 3D 重建以及纹理优化。以单张图像作为输入,One-2-3-45++通过微调 2D 扩散模型生成一致的多视角图像,再将多视角图像通过一对 3D 原生扩散网络提升为 3D 模型,能够在 20 秒内生成初始纹理网格,并在大约一分钟内提供精细网格。
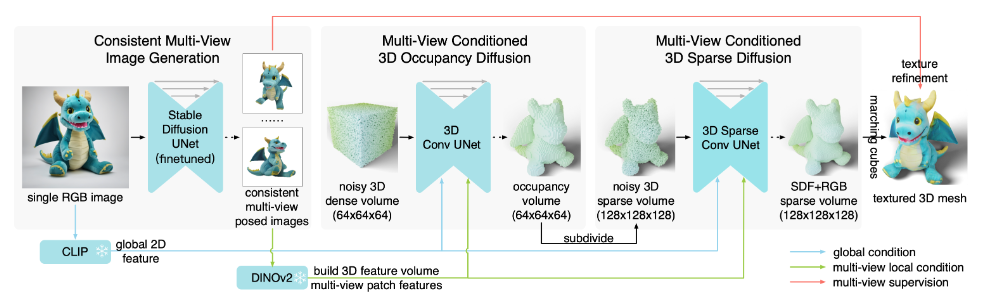
图源:One-2-3-45++
RichDreamer 则出自通义实验室XR,使用 G-buffer Objaverse 来训练多视角法向深度扩散模型(ND-MV) 和深度条件控制的多视角反照率扩散模型(Albedo-MV),通过分数蒸馏采样(SDS)生成 3D 对象。
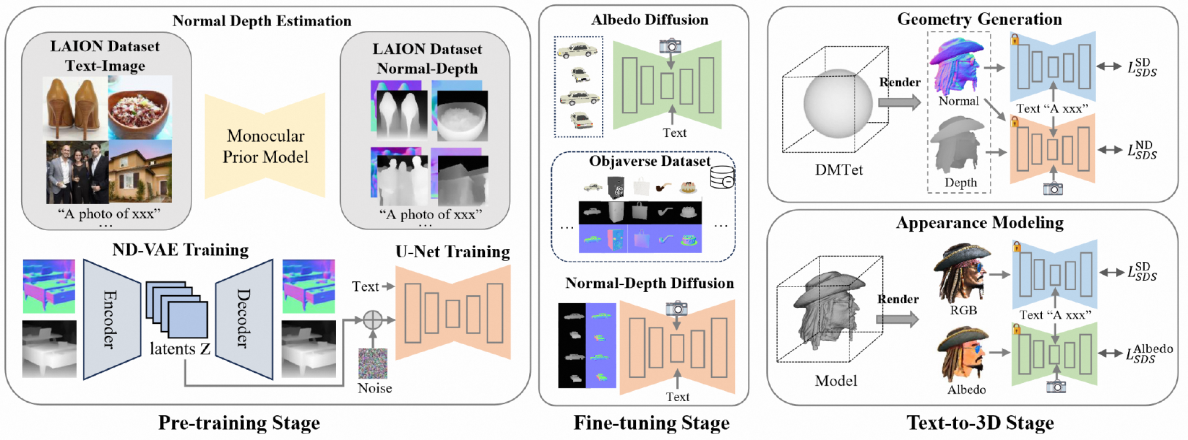
图源:RichDreamer
在 2D 扩散生成 3D 的方案中,2D RGB扩散模型缺乏几何先验,仅依靠 2D RGB 扩散模型来优化表面法线会导致优化不稳定,并且自然图像中材质和照明的解耦是另外一个具有挑战性的问题。
而 RichDreamer 通过在大规模2D数据集LAION-2B 和 3D G-buffer Objaverse 数据集上训练法向深度扩散模型,同时引入反照率扩散模型以减轻生成材料中的混合照明效应,显著增强了细节的丰富性以及建模的稳定性。

图源:RichDreamer
除了以上代表模型外,2023 年值得关注 3D AIGC 模型还有很多,包括 LDM3D-VR、DMV3D、Zero-1-to-3、Neuralangelo、Magic3D、Fantasia 3D、Prolific-Dreamer,以及踩着 2023 的尾巴,成为 2024 年第一个瞩目模型的 Genie 1.0 等。这些 AI 模型侧重点各不相同,但都为刚刚起步的 3D AIGC 行业提供了不同的思路。
来自英伟达和约翰霍普金斯大学的研究人员提出的“Neuralangelo”可以利用神经网络重建 3D 物体,被 TIME 杂志评为“2023 年 200 个最佳发明”之一。
Meta 生成式AI 团队发布了名为 ControlRoom3D 的 3D 室内设计生成系统,只需要给出房间布局和风格描述,AI 算法就能自动渲染出精细的3D 几何结构和材质纹理。
苹果公司正在研究的生成式 AI 技术“HUGS”经过训练后,可以在约 30 分钟内生成数字人类分身,拓宽了 3D AIGC 技术的使用场景。
3D AIGC 的难点——“精准高效”
“一句话生成 3D 模型”、“秒建虚拟世界”的口号已经喊了一年,但 2023 年人们眼中真正做到能够商用的“又快又好”的 3D AIGC 模型似乎仍未出现。
3D AIGC 模型的难点之一是如何在有限的 prompt 条件下尽可能准确还原。在尝试使用多个 3D AIGC 模型后我们可以发现,2023 年市面上大多数模型对于基础的指令理解能力其实已经十分优秀,但对于日常生活中不太常见的关键词很难做到准确识别建模,而当描述语句中出现多个角色时,甚至还会出现元素杂糅现象。
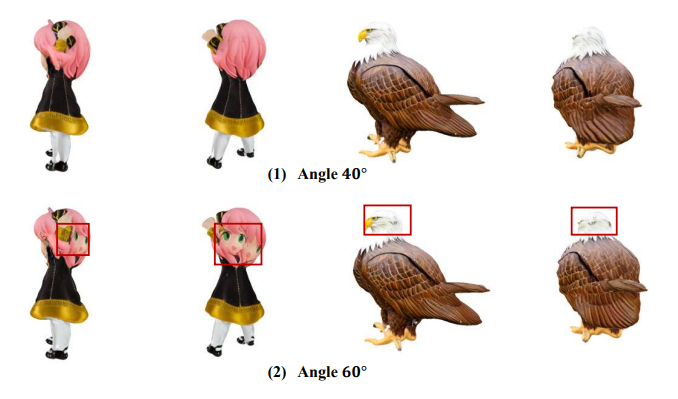
可能出现的多视角不一致问题(图源:Repaint123)
在董子龙看来,3D 生成中的多对象杂糅问题主要有两个原因:
首先是文生图模型的底层逻辑。由于文生图模型本质是对图像信息的学习整合,在融合数据库中数十亿级别图像的过程中,不可避免会出现元素杂糅现象。这就要求图像数据集要更加干净,更有物体针对性。
其次是训练数据的文本问题。前文提到,目前主流的文本生成 3D 方法大多使用预训练的 2D 扩散模型,通过 SDS 优化神经辐射场(NeRF)生成 3D 模型。但这种预训练扩散模型提供的监督仅限于输入的文本本身,并未约束多视角间的一致性,导致生成模型几何结构差。
当我们用中文 prompt 去命令一个由英文数据训练的模型时,模型需要通过将中文 prompt 翻译成英文后再进行处理,这会带来更多的未知的命令偏差。这一问题要求模型厂商对用户输入的 prompt 进行优化微调,还需要对用户进行 prompt 提示,给予没有经验的使用者一些帮助。
针对多视角不一致的雅努斯问题(Janus Problem),业内公认的关键解决方案在于“文本/图像+相机视角”的组合约束,比如说“Zero-1-to-3”方案,其出发点就在于利用大规模 3D 物体数据集以及固定相机视角的渲染图像,以保证生成 3D 物体的几何结构一致性。
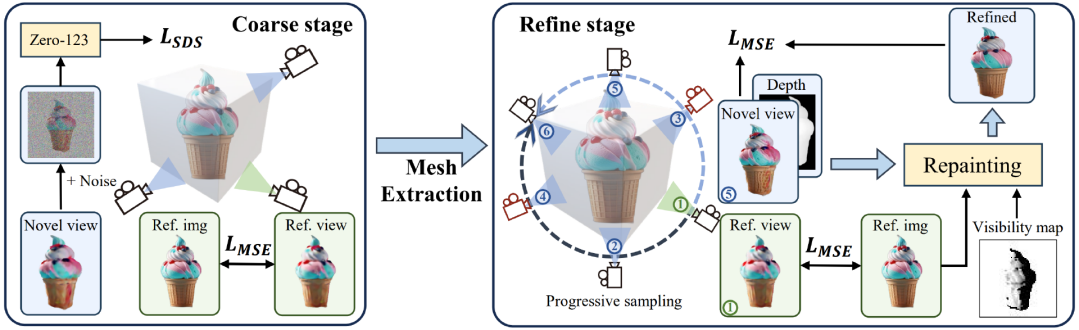
相机视角采样(图源:Repaint123)
该技术路线目前已经广泛应用在3D生成的框架中,例如字节的MVDream 、港大的Wonder3D、腾讯的 SweetDreamer和SyncDreamer。
其中,MVDream 主要是从视频扩散模型中得到灵感,能同时生成多个视角(4 个)的图像,并在在 4 个视角间建立交叉注意力,以保持较好效果的一致性。
此外,RichDreamer 也在训练深度法向扩散模型之外部分延续了 MVDream 的思路,通过多视角深度法向扩散模型解决雅努斯问题。
国内类似的工作还有很多。
2023 年 12 月,清华大学刘永进教授课题组提出了一种基于扩散模型的文生 3D 新模型“TICD”(Text-Image Conditioned Diffusion),在 T3Bench 数据集上达到了 SOTA 水平,无论是不同视角间的一致性,还是与提示词的匹配度,都比此前大幅提升。
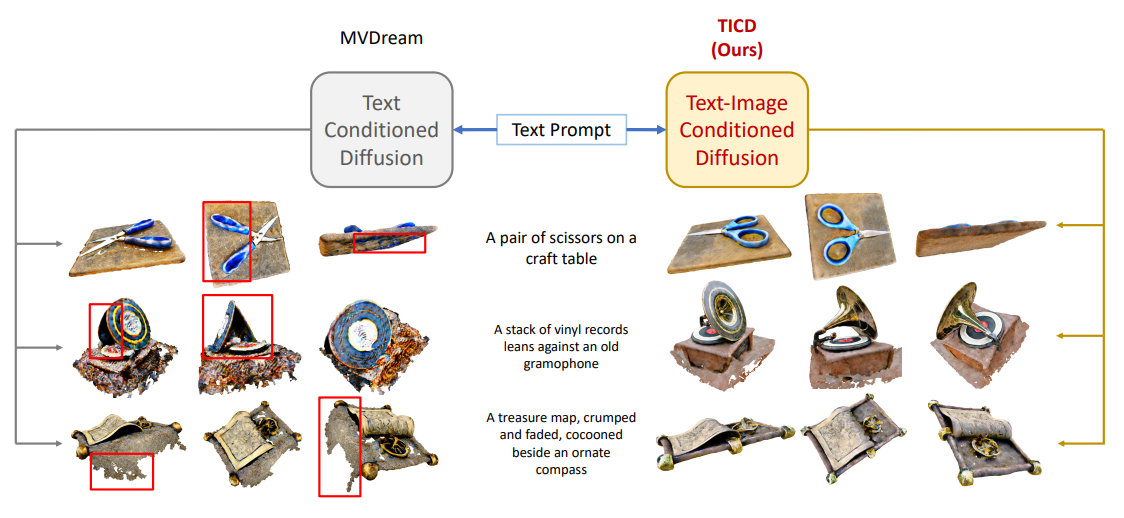
图源:TICD
根据论文信息,TICD 首先采样若干组正交的参考相机视角,使用 NeRF 渲染出对应的参考视图,然后对这些参考视图运用基于文本的条件扩散模型,约束内容与文本的整体一致性。
在此基础上选取若干组参考相机视角,并对于每个视角渲染一个额外新视角下的视图。接着以这两个视图与视角间的位姿关系作为新条件,使用基于图像的条件扩散模型约束不同视角间的细节一致性。
结合两种扩散模型的监督信号,TICD 可对 NeRF 网络的参数进行更新并循环迭代优化,直到获得最终的 NeRF 模型,并渲染出高质量、几何清晰且与文本一致的 3D 内容。
TICD 方法将以文本为条件的和图像为条件的多视角图像纳入 NeRF 优化的监督信号中,分别保证了 3D 信息与提示词的对齐和 3D 物体不同视角间的强一致性,有效提升了生成 3D 模型的质量。
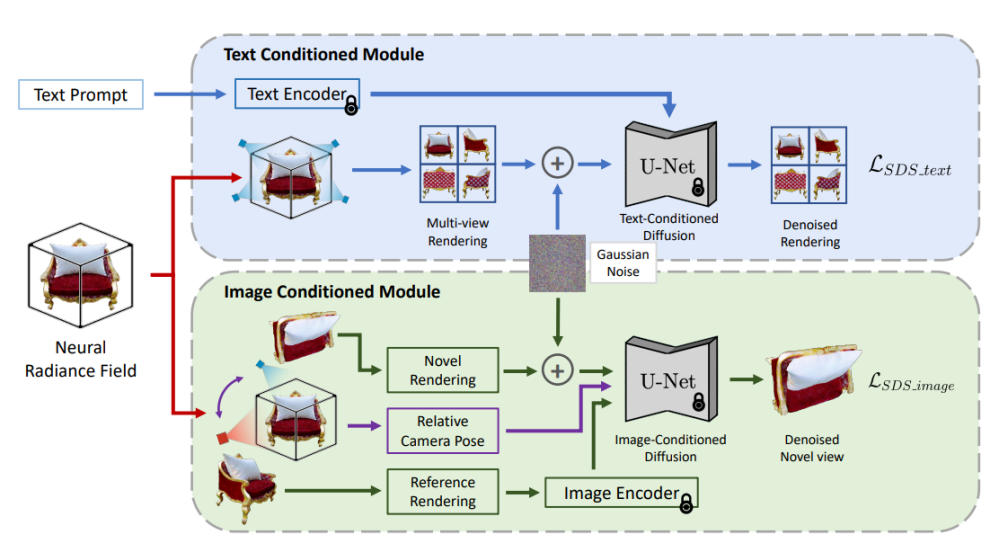
图源:TICD
在能够准确还原文本信息之后,3D AIGC 模型的另一难点则是如何尽可能快速生成模型。毕竟越能根据输入 prompt 快速生成结果,就越能更快地对模型的错误理解做出更正,提高建模效率。
以 RichDreamer 为例。在董子龙的介绍中,该模型采用了优化的框架,生成过程中需要进行数千次的迭代,其中的耗时主要出现在两个阶段。一是 NeRF 的图像渲染,二是 SDS Loss 的计算。
其一的优化方向在于采用更高效的 NeRF 方案,例如 3D 高斯泼溅算法,可以将生成时间降低为分钟级。
另一个优化方向则是放弃对 SDS Loss 的优化,重新回到网络前向推理的框架,该方法可以从图片或文本直接推理出 NeRF 场,3D 生成时间可以直接降到秒级。但这两种方法在生成效果上都会出现损失,且生成的结果也较为单一。
在商用模型上,则出现了 Tripo 以及 Genie 1.0 等为代表的主流两阶段生成方式。

图源:Luma AI
其中,Genie 1.0 号称只需要输入一句文字提示就能在 10 秒内生成四个高保真的 3D 模型,用户还可以从中选择,并在三维网格界面内对模型的纹理进行编辑。
但实际使用下来可以发现,Genie 1.0 的 10 秒生成仅限第一阶段的草图模型阶段,在二阶段将“半成品”生成高分辨精细模型的过程仍需要花费数十分钟时间。

使用 Genie 1.0 生成的模型
虽然并没能真正做到秒生模型,但从生成结果上方看,Genie 1.0 生成的最终结果在立体度和真实感方面表现不俗。同时,Genie 1.0 不仅内置编辑功能,生成的模型还能导出到 Blender、Unity 等软件中进一步完善,无缝衔接游戏、VR 等 3D 内容项目。因此,这种两阶段生成方式目前看来还是更加实用也更加成熟,很大概率将在 2024 年继续出彩。
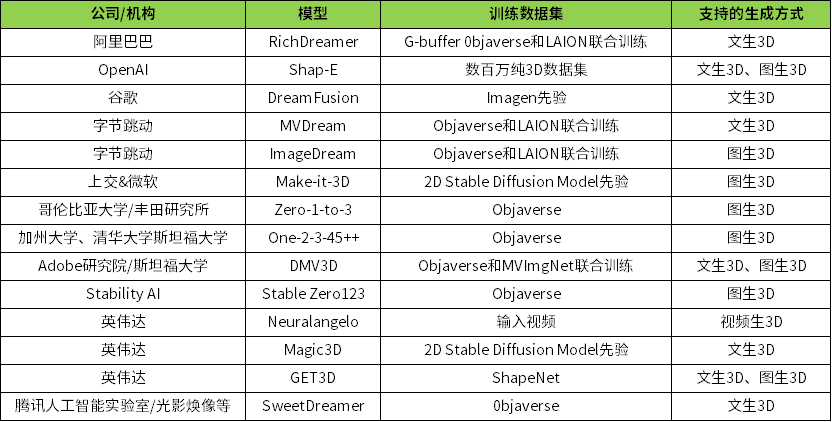
2023年值得关注的 3D-AIGC 开源模型
AIGC 赋能 XR 内容产业,但前提是成为合格的生产力工具
3D AIGC 的火热之下,最先被抬上“崛起队列”的是游戏、动画影视,以及以 XR 为代表的的虚拟内容领域,其核心都在于提高创建3D资产的效率。
3D AIGC 在游戏领域的一大应用是复杂场景生成。相对于人物、动物等游戏可活动角色,3D 场景对建模质量要求不高,且可以容忍一定程度的模型重复,但由于涉及大空间布局,3D 场景并不适合单物体建模流程。

3D AIGC 模型生成场景(图源:3D-GPT)
从结构上看,可交互的 3D 场景基本都是由空间和物体构成的,如果直接将文生 3D 的框架直接应用于场景生成的话,模型渐进式贴片方式生成的场景质量并不可控,且最终生成的场景实际上只是一个大型的一体式模型,并没有分开表达,这在商业应用场景中的价值并不高。
因此,对于文生 3D 场景的较好思路在于先用输入文本生成空间,再在空间中生成物体布局。每个布局都使用包围盒表示,再在每个包围盒中解析对应的文本信息,并用文生 3D 模型生成该位置的 3D 对象,最终集合成一个强结构性的 3D 场景。此类对输入文本的结构化理解也是现在大语言模型更擅长的。
2023 年 2 月,Blockade Labs 上线 AI 工具“Skybox AI”,使用者无需代码基础和高性能硬件即可快速构建一个超高清 6K 分辨率的 360 度全景图像。Skybox AI 能够将生成的 2D 图像自动升维为 3D 自由探索版,用户可以根据鼠标所指的视点在图片中自由漫游,实现动态光线变化。

图源:Skybox AI
这些 3D 场景的 AI 化生产流程一定程度上是也对游戏引擎极佳的技术补充。像 Unity 这样的 3D 游戏引擎目前更多的是充当资产管理工具和应用平台的角色,本身并不负责生成 3D 资产,3D AIGC 技术的出现将使更多的游戏开发者将能够在 AI 加持下以更低的成本去开发 3D、VR 内容。此前,Unity 也一直在支持集成第三方的 AI 生成能力,并在人物、物体的是 AI 生成方向已有部分动作。而诸如树、河流等环境矢量场景元素的 AI 生成应用更为广泛。
只是由于多维参数化生成,物体多样性方面受限较多,因此,董子龙认为 3D AIGC 技术会成为游戏生产环节的一个比较重要的工具,但其在游戏领域更多起到的还是辅助作用,难以在目前阶段带来突破性的变化。

图源:Unity
主要原因在于目前整个游戏的生产链路已经非常成熟,并不会马上因为 AI 的介入而颠覆整个生产过程,这一点哪怕是文本生成、图像生成模型也还没到完全可替代人工的程度。
不过可以肯定的是,随着 3D AIGC 技术成熟到在生产效率、成品质量都足以媲美传统游戏 3D 内容生产模式的时候,AI 在游戏领域势必发挥更大的作用。
毕竟,智能时代下,无论是在个人场景下的各类消费电子产品 APP,还是公共场景下的各类教育、医疗、文旅产品的视觉展示,对于 3D 技术的使用率都有增无减。建立在虚拟世界基础上的 XR 行业更是如此,3D AIGC 技术的出现大概率会对尚在发展初期的 XR 内容行业带来颠覆性的变革。

图源:索尼
设想一下,在之前我们戴上 XR 设备之后往往会变得无所适从,应用场景的缺失导致我们最多只是在体验游戏、影音之后就草草结束。而当 AI 生成技术足够成熟之后,我们一戴上眼镜便可以通过语言手势创造出一个属于自己的完整三维世界,所有的角色物体场景都可以“一句话生成”,动态且可交互。
此外,大语言模型还可以将 3D 空间中的每一个元素“智能化”,电影《黑镜》中的一些科幻场景将变为现实。如果这些设想成真的话,XR 的吸引力将很难抵挡得住。
而这一切的前提是 3D AIGC 技术能成熟到足以作为合格的生产力工具。
目前 Tripo AI、Meshy AI、LUMA AI 等都推出自己的平台,也逐渐的走向应用场景。董子龙乐观估计,3D 生成模型真正成为生产力工具的时刻将出现在 2024 年,但如果要实现《黑镜》中秒生物体的程度或许还需要两三年。毕竟此前文生图模型从原型到真正投入应用也用了近两年时间,而文生 3D 相比文生图难度更高、挑战更多,因此其最终成熟落地所需的准备时间并不会比文生图模型更短。

图源:Tripo AI
这一过程目前还在加速。从技术上看,3D AIGC 技术目前已经出现了一些技术突破的路径。
其中既包括3D高斯泼溅等三维表征上的技术突破,也包括针对物体图像三维数据的数据集的突破,比如MVImgNet数据集。
MVImgNet 是由港中大(深圳)韩晓光团队推出的图像数据集,包含了超过 21 万个视频的 650 万帧图像,涵盖了 238 个类别的真实世界物体。MVImgNet 包含了 238 个日常生活中常见的物体类别(以人为中心),其中有 65 个类别与 ImageNet (以植物、动物等自然物体为中心)重叠。得益于数据的多视角特性,MVImgNet 在图像分类、自监督对比学习以及显著性物体检测等任务上表现优秀,生成模型获得了很好的视角一致性。

图源:MVImgNet
在以上技术难题实现突破后,3D AIGC 才有可能作为一项生产力工具,以适配 XR 内容的生产模式。
小结
总的来看,以 2022 年末的 DreamFusion 为开端,3D AIGC 技术基本已经实现了从无到有的跨越。从 0 到 1 是最难的,3D AIGC 技术已经跨过了这一个坎,剩下的就是从 1 开始的不断细化。
从技术上来看,2023 年 3D AIGC 领域出现了热门的单视角生成多视角的技术方案,图生 3D 成为比文生 3D 更为贴近应用场景的生成模式。
而从应用场景上看,所有与 3D 资产密不可分的行业未来都会成为 3D AIGC 技术的潜在客户,在这方面游戏市场抢先入局,但以 XR 为代表的虚拟产业将成为更大赢家。
如果将视野拉得更长点,3D视频生成正在路上;国家广播电视总局批复同意在华为技术有限公司设立“超高清技术创新与应用国家广播电视总局重点实验室”,鼓励 4K/8K 电视机、虚拟现实终端、裸眼 3D 显示终端等产品入户,AIGC+XR 迎来新应用场景。可以预见,在世界尝试和了解 AIGC 的 2023 年之后,AI 大爆发的 2024 年将带给我们更多新变化,AI 驱动内容生产的时代已经到来。

元宇宙数字产业服务平台
下载「陀螺科技」APP,获取前沿深度元宇宙讯息
</div
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK