

不分割成token,直接从字节中高效学习,Mamba原来还能这样用
source link: https://www.51cto.com/article/781081.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
不分割成token,直接从字节中高效学习,Mamba原来还能这样用
在定义语言模型时,通常会使用一种基本分词方法,把句子分为词(word)、子词(subword)或字符(character)。其中,子词分词法一直是最受欢迎的选择,因为它在训练效率和处理词汇表外单词的能力之间实现了自然的折中。然而,一些研究指出了子词分词法的问题,如对错别字、拼写和大小写变化以及形态变化缺乏稳健性。
因此,有些研究人员另辟蹊径,采用了一种使用字节序列的方法,即从原始数据到预测的端到端映射,中间不进行任何分词。与子词模型相比,基于字节级的语言模型能够更容易地在不同的书写形式和形态变化之间进行泛化。当然,将文本建模为字节意味着生成的序列要比对应的子词长得多。如此一来,效率的提升就要依靠架构的改进来实现了。
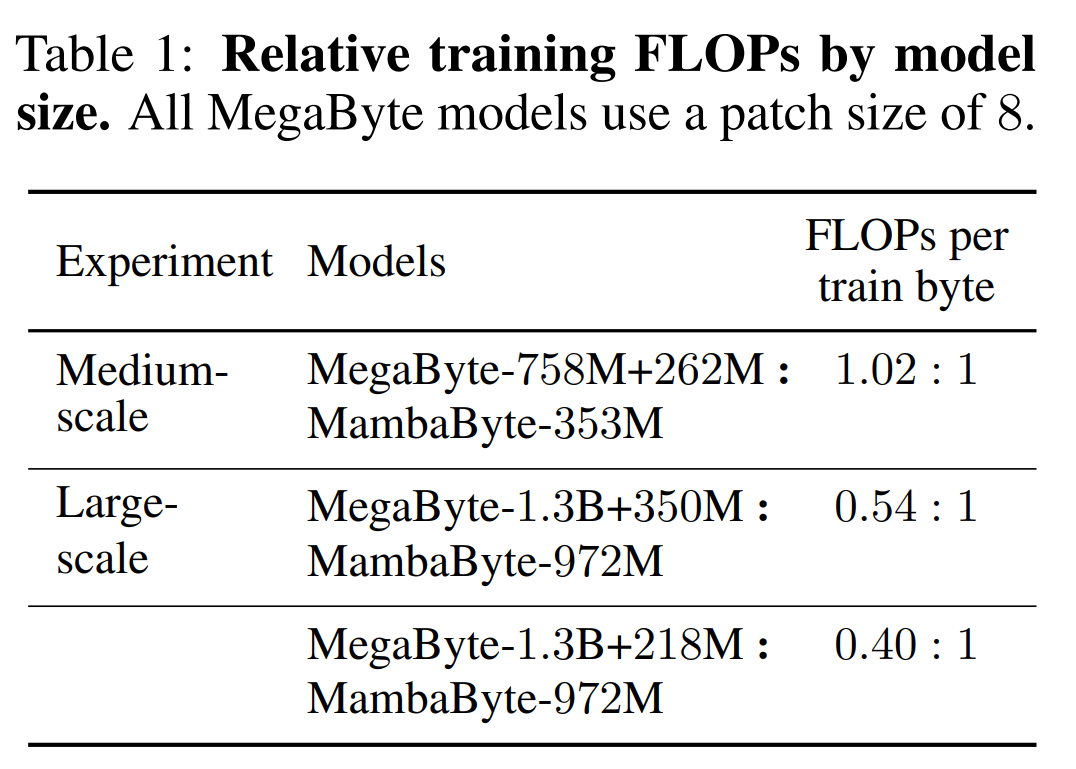
自回归 Transformer 在语言建模中占主导地位,但效率问题尤为突出:计算成本随序列长度呈二次方增长,因此对长(字节)序列的扩展能力很差。研究人员压缩了 Transformer 的内部表示,以便处理长序列,例如开发了长度感知建模方法,在这种方法中,token 组在中间层内合并。最近,Yu 等人 [2023] 提出了 MegaByte Transformer,它使用固定大小的字节片段作为子词的模拟压缩形式。因此,MegaByte 可以降低计算成本。不过,这可能还不是最好的方法。
在一份新论文中,来自康奈尔大学的研究者介绍了一种高效、简单的字节级语言模型 MambaByte。该模型对最近推出的 Mamba 架构进行了直接改造。Mamba 建立在状态空间模型(SSM)开创的方法基础上,引入了对文本等离散数据更有效的选择机制,并提供了高效的 GPU 实现。作者的简单观察结果是,使用 Mamba(不做修改)可以缓解语言建模中的主要计算瓶颈,从而消除 patching 并有效利用可用的计算资源。

- 论文标题:MambaByte: Token-free Selective State Space Model
- 论文链接:https://arxiv.org/pdf/2401.13660.pdf
他们在实验中将 MambaByte 与 Transformers、SSM 和 MegaByte(patching)架构进行了比较,这些架构都是在固定参数和固定计算设置下,并在多个长篇文本数据集上进行比较的。图 1 总结了他们的主要发现。
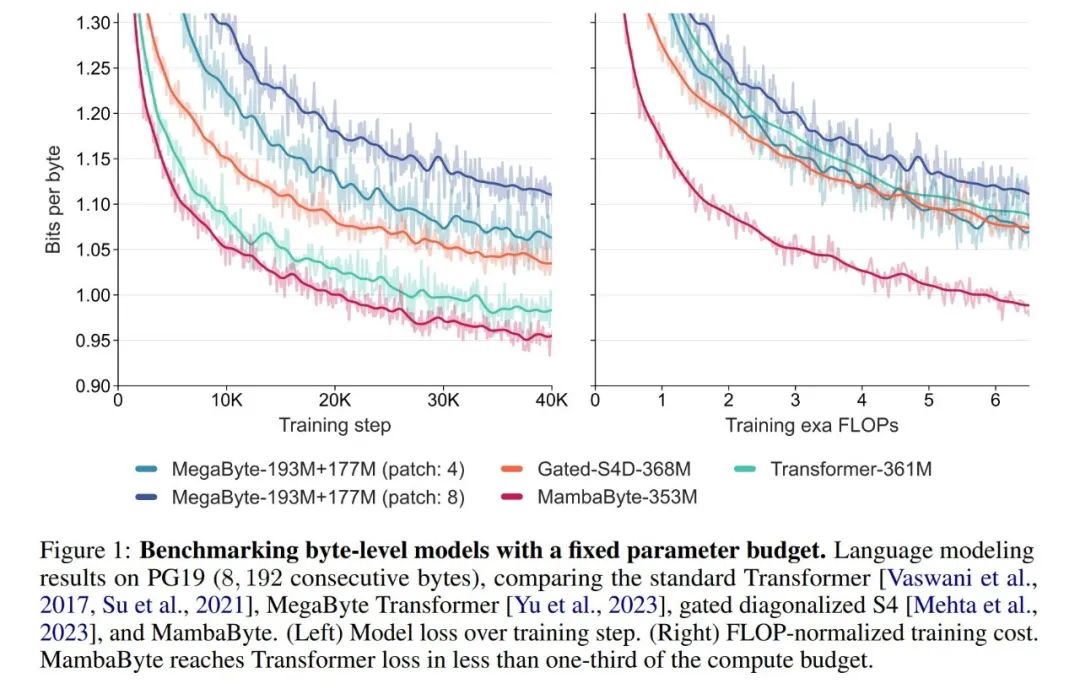
与字节级 Transformers 相比,MambaByte 能更快地实现更好的性能,计算效率也明显更高。作者还考虑了无 token 语言模型与现有最先进的子词模型相比的可行性。在这方面,他们发现 MambaByte 与各种子词基线模型相比具有竞争力,但它能处理更长的序列。研究结果表明,MambaByte 是现有依赖分词器( tokenizer)的模型的有力替代品,有望用来促进端到端学习。
背景:选择性状态空间序列模型
SSM 通过一阶微分方程对隐藏状态的跨时间演变进行建模。线性时不变(time-invariant) SSM 在几种模态的深度学习中显示出了良好的效果。然而,Mamba 作者 Gu 和 Dao 最近认为,这些方法的恒定动态缺乏隐藏状态中依赖输入的上下文选择,而这可能是语言建模等任务所必需的。为此,他们提出了 Mamba,该方法将给定输入 x (t) ∈ R、隐藏状态 h (t) ∈ R^n 和输出 y (t) ∈ R 在时间 t 的时变连续状态动态定义为:
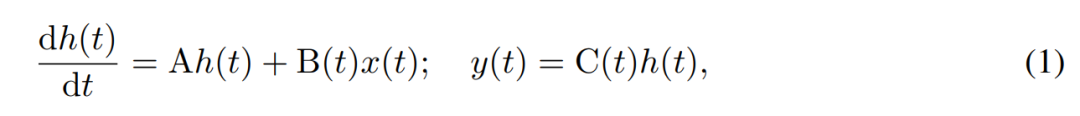
其参数为对角时不变系统矩阵 A∈R^(n×n),以及随时间变化的输入和输出矩阵 B (t)∈R^(n×1) 和 C (t)∈R^(1×n)。
要对字节等离散时间序列建模,必须通过离散化来逼近 (1) 中的连续时间动态。这就产生了离散时间隐态 recurrence,每个时间步都有新矩阵 A、B 和 C,即
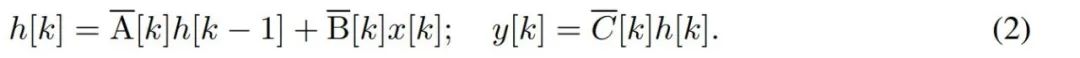
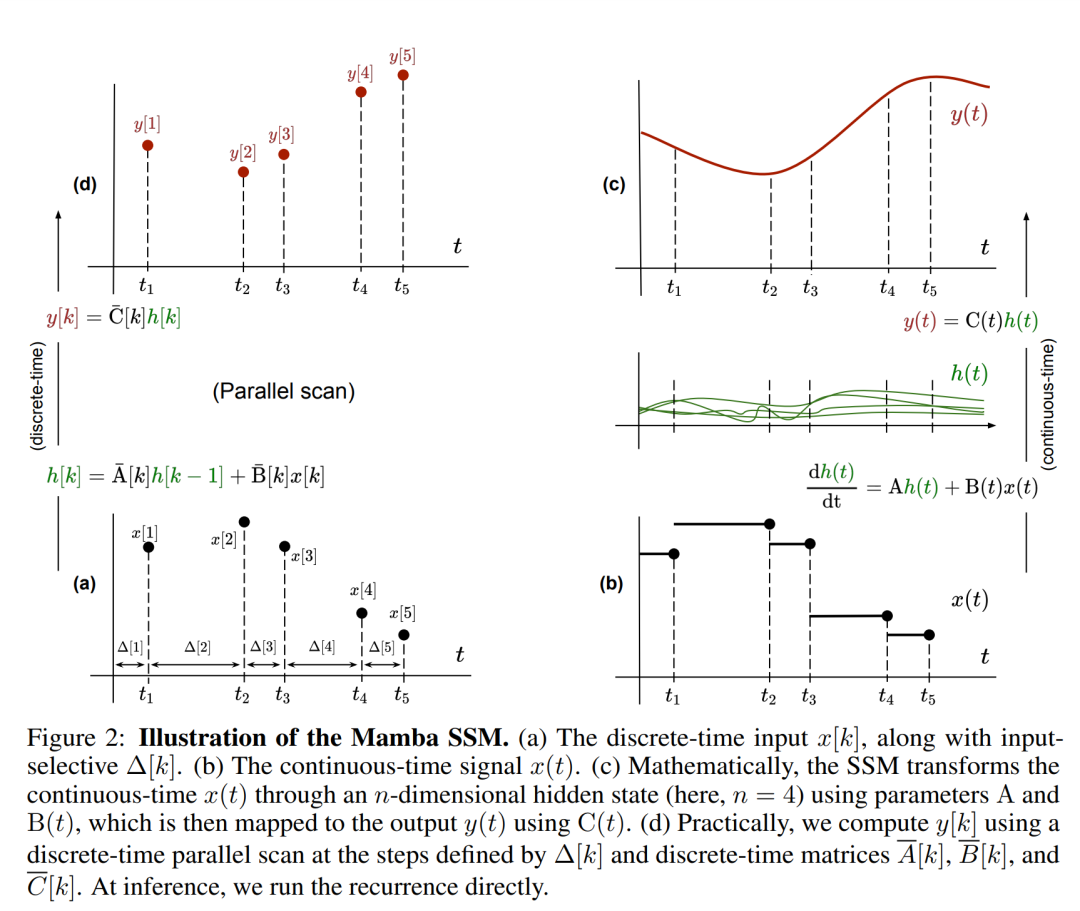
请注意,(2) 类似于循环神经网络的线性版本,可以在语言模型生成过程中以这种循环形式应用。离散化要求每个输入位置都有一个时间步,即 ∆[k],对应于 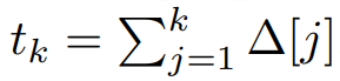 的 x [k] = x (t_k)。然后就可以根据 ∆[k] 计算出离散时间矩阵 A、B 和 C。图 2 展示了 Mamba 如何为离散序列建模。
的 x [k] = x (t_k)。然后就可以根据 ∆[k] 计算出离散时间矩阵 A、B 和 C。图 2 展示了 Mamba 如何为离散序列建模。
在 Mamba 中,SSM 项是输入选择性的,即 B、C 和 ∆ 被定义为输入 x [k]∈R^d 的函数:
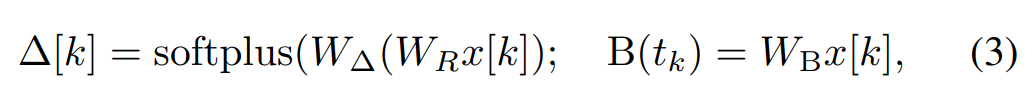
其中 W_B ∈ R^(n×d)(C 的定义类似),W_∆ ∈ R^(d×r) 和 W_R ∈ R^(r×d)(对于某个 r ≪d)是可学习的权重,而 softplus 则确保正向性。请注意,对于每个输入维度 d,SSM 参数 A、B 和 C 都是相同的,但时间步数 ∆ 是不同的;这导致每个时间步数 k 的隐藏状态大小为 n × d。
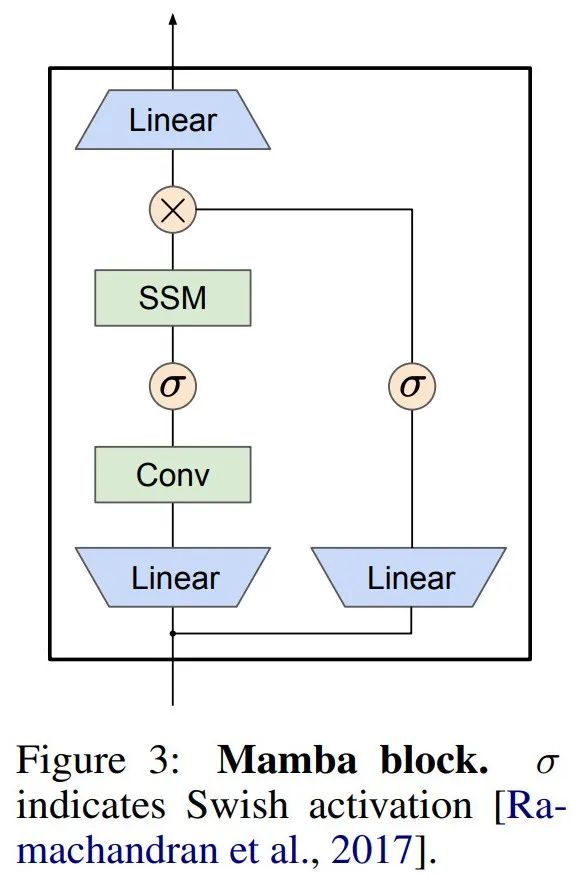
Mamba 将这个 SSM 层嵌入到一个完整的神经网络语言模型中。具体来说,该模型采用了一系列门控层,其灵感来源于之前的门控 SSM。图 3 显示了将 SSM 层与门控神经网络相结合的 Mamba 架构。
线性 recurrence 的并行扫描。在训练时,作者可以访问整个序列 x,从而更高效地计算线性 recurrence。Smith et al. [2023] 的研究证明,使用工作效率高的并行扫描可以高效计算线性 SSM 中的顺序 recurrence。对于 Mamba,作者首先将 recurrence 映射到 L 个元组序列,其中 e_k =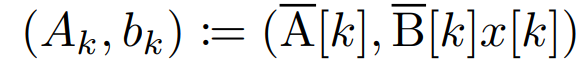 ,然后定义一个关联算子
,然后定义一个关联算子  使得
使得 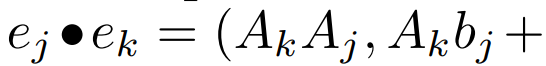
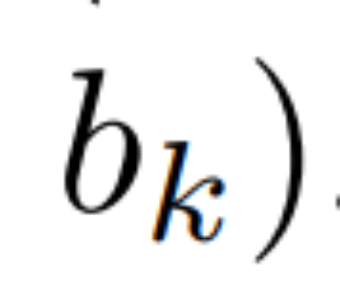 。最后,他们应用并行扫描计算序列
。最后,他们应用并行扫描计算序列 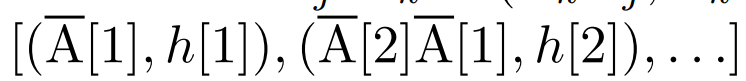 。一般来说,这需要
。一般来说,这需要 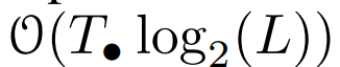 时间,使用 L/2 个处理器,其中
时间,使用 L/2 个处理器,其中 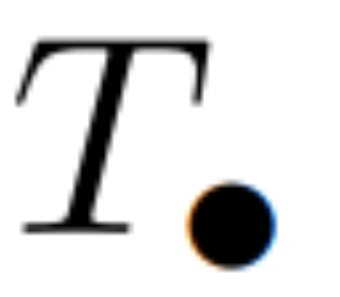 是矩阵乘法的成本。注意,A 是一个对角矩阵,线性 recurrence 可在
是矩阵乘法的成本。注意,A 是一个对角矩阵,线性 recurrence 可在 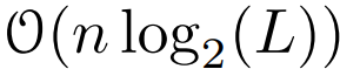 时间和 O (nL) 空间内并行计算。使用对角矩阵进行并行扫描的运行效率也很高,只需 O (nL) FLOPs。
时间和 O (nL) 空间内并行计算。使用对角矩阵进行并行扫描的运行效率也很高,只需 O (nL) FLOPs。
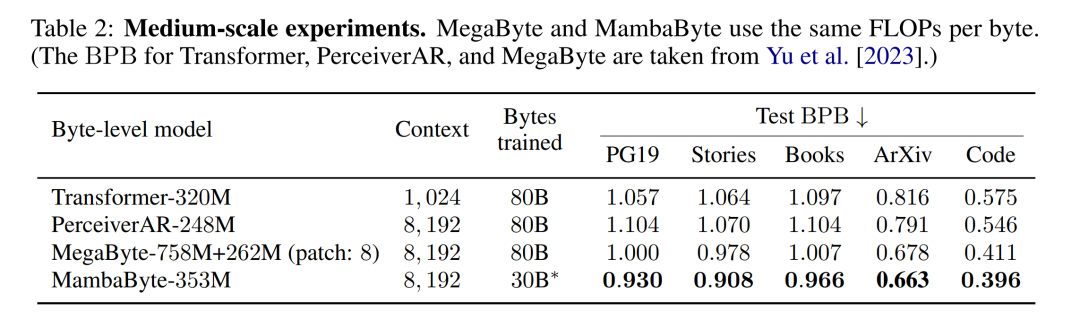
表 2 显示了每个数据集的每字节比特数(BPB)。在本实验中,MegaByte758M+262M 和 MambaByte 模型使用相同的每字节 FLOP 数(见表 1)。作者发现,在所有数据集上,MambaByte 的性能始终优于 MegaByte。此外,作者注意到,由于资金限制,他们无法对 MambaByte 进行完整的 80B 字节训练,但 MambaByte 在计算量和训练数据减少 63% 的情况下仍优于 MegaByte。此外,MambaByte-353M 还优于字节级 Transformer 和 PerceiverAR。
在如此少的训练步骤中,MambaByte 为什么比一个大得多的模型表现得更好?图 1 通过观察参数数量相同的模型进一步探讨了这种关系。图中显示,对于参数大小相同的 MegaByte 模型,输入 patching 较少的模型表现更好,但在计算归一化后,它们的表现类似。事实上,全长的 Transformer 虽然在绝对意义上速度较慢,但在计算归一化后,其性能也与 MegaByte 相似。相比之下,改用 Mamba 架构可以显著提高计算使用率和模型性能。
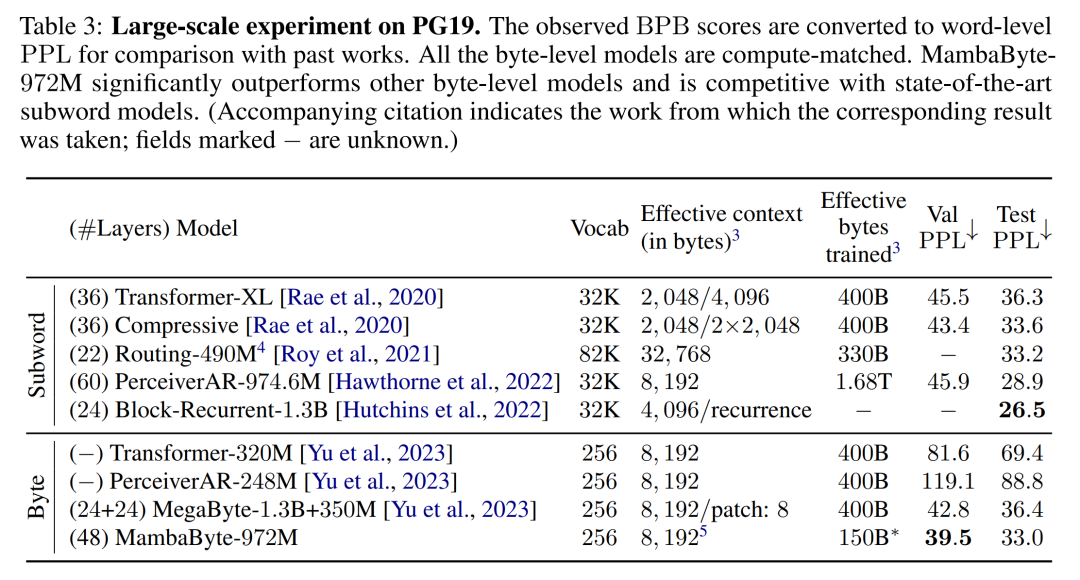
根据这些发现,表 3 比较了这些模型在 PG19 数据集上的较大版本。在这个实验中,作者将 MambaByte-972M 与 MegaByte-1.3B+350M 和其他字节级模型以及几个 SOTA 子词模型进行了比较。他们发现,MambaByte-972M 即使只训练了 150B 字节,其性能也优于所有字节级模型,并与子词模型相比具有竞争力。
文本生成。Transformer 模型中的自回归推理需要缓存整个上下文,这会大大影响生成速度。MambaByte 不存在这一瓶颈,因为它每层只保留一个随时间变化的隐藏状态,因此每生成一步的时间是恒定的。表 4 比较了 MambaByte-972M 和 MambaByte-1.6B 与 MegaByte-1.3B+350M 在 A100 80GB PCIe GPU 上的文本生成速度。虽然 MegaByte 通过 patching 大大降低了生成成本,但他们观察到 MambaByte 由于使用了循环生成,在参数相似设置下速度达到了前者的 2.6 倍。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK