

AI届的英雄好汉“训练集、验证集、测试集”各显神通!
source link: https://www.woshipm.com/ai/5987712.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
AI届的英雄好汉“训练集、验证集、测试集”各显神通!
充分利用好训练集、验证集和测试集,有助于我们构建出性能优秀的模型,这篇文章里,作者就对三者做了介绍,并结合猫猫识别模型的模拟案例来展示训练集、验证集和测试集各自的能力,一起来看看作者的解读与分析。

各位看官:
欢迎一起揭秘AI的世界。AI的运行离不开数据,若数据就是AI的“大米”,良米炊而成饭,质地上乘。我们喂养给AI多好的“大米”,AI就会输出多好的“饭”。
原本是打算仅用一篇来说清楚AI数据集,但在持续的梳理和撰写过程中,发现字数越码越多,所以就决定分几篇说完吧。
上一篇《带你识别AI数据集的各种面孔 (AI从业万字干货)》中,我主要介绍了AI数据集是什么,这些数据集的常见格式有哪些,分别有哪些适用场景和局限之处,也给大家整理了一些网上的公开数据集,当我们需要数据来做AI项目时,可供君参考。
本篇,我会继续聊聊AI中的数据集。全文8000字左右,预计阅读时间8分钟,若是碎片时间不够,建议先收藏后看,便于找回。
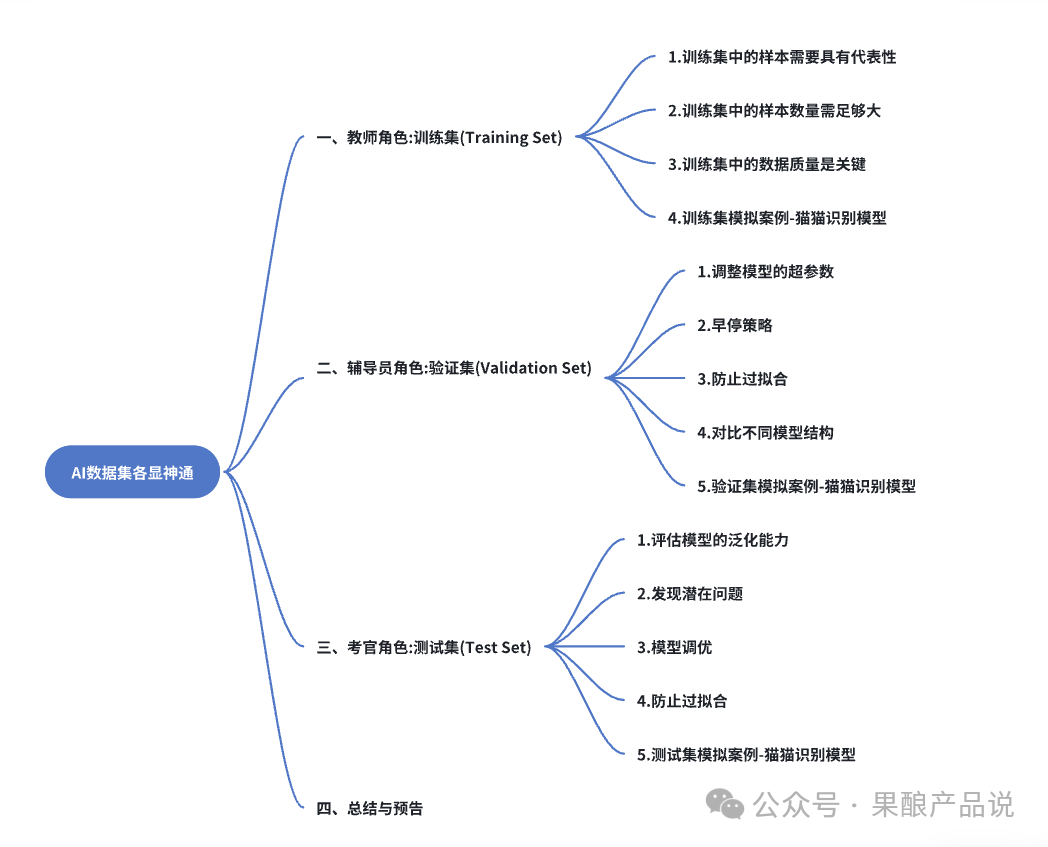
照例,开篇提供文章结构导图,方便大家在阅读前总揽全局,有大致的画面框架。
Now let’s start,在人工智能和机器学习的世界里,数据训练是不可避免的。机器学习的核心任务就是从数据中学习和构建模型(该过程称之为训练),并且能够在未遇见的数据上进行预测。我们通过数据训练,期待模型能够展现出优秀的预测性能。
项目实践中,我们在构建模型的不同阶段时,通常会将数据集划分成三种:训练集、验证集和测试集。这样划分的目的是希望可以更好地评估模型的性能,同时也能避免数据过拟合和欠拟合的问题。
BTW,关于数据拟合的问题,我写过的一篇《(万字干货)如何训练优化“AI神经网络”模型?》中,有详细介绍,本篇不赘述。
接下来,我们将重点围绕训练集、验证集和测试集来展开,进一步揭晓AI数据集背后的故事。

一、教师角色:训练集(Training Set)
顾名思义,训练集是机器学习中用于训练模型的数据集合。训练集通常包含已标记的样本,即每个样本都有对应的输入特征和相应的目标标签或输出。
在训练模型的过程中,模型通过学习分析训练集中的样本数据来调整其参数和权重,以实现对新样本的准确预测或分类。

简单来说,训练集就像是教师,教学生知识,给学生提供教材,学生通过阅读和理解所教授的内容和教材来学习新的知识和技能。
所需的“知识”需具备一定的广度,我们在选取训练集时,要注意“训练集是否具备代表性”,“数据量大小是否足够”,“数据质量是否符合要求”。
1. 训练集中的样本需要具有代表性
这是指被训练的数据需要涵盖模型在实际应用中可能遇到的各种情况。
如果说,我们要构建一个用于图像分类的训练集,任务是将动物图像分为猫和狗两类。为了保证训练集的代表性,我们需要包含各种情境下的动物图像,比如以下因素:
【物种多样性】:确保训练集中涵盖多种不同种类的猫和狗,而不仅仅是某一特定品种。例如,包括短毛猫和长毛猫,各类狗的品种也要有广泛覆盖。
【背景和环境】:图像中的背景和环境对于模型的泛化至关重要。训练集应该包含不同的背景,例如室内、室外、草地、水域等,以确保模型不仅仅是学到了特定背景下的特征。
【姿势和动作】: 动物在图像中的不同姿势和动作也是代表性的一部分。包括站立、躺下、奔跑等动作,以及正面、侧面等不同的拍摄角度所呈现的图像。
【光照条件】: 不同的光照条件会影响图像的外观,因此训练集应该包含,例如阳光明媚、阴天、夜晚等不同光照条件下的样本。
【年龄和大小】:动物的不同年龄和大小也是重要的代表性样本。包含幼年和成年阶段,以及不同体型大小的猫和狗。
所以,为了确保模型在处理真实世界图像时能够实现更加精准的分类,我们最好提供一个涵盖各种情景的样本数据集。

因此,在构建训练集时,我们应当注重数据的代表性,帮助模型学到更全面的特征,提高模型在实际应用中的性能和可靠性,使其更好地适应和处理多样化的真实场景。
2. 训练集中的样本数量需足够大
除了训练集的代表性以外,样本数量也是至关重要的。在实际应用中,我们通常会发现,随着训练集样本数量的增加,模型的性能也会得到相应的提高。
我们发现,当训练集样本数量较小时,模型更容易受到随机变动的影响,导致模型对训练数据过于敏感,难以捕捉真实的数据分布。相反,大规模训练集则有助于降低随机性,使模型更稳健。
假设我们想让AI模型完成一个分类任务,比如训练一个神经网络来识别手写数字。
如果训练集只包含几十个图像,而且这些图像中只有很少的数字样本,那模型可能只能学到非常有限的特征,无法泛化到新的手写数字。也就是说,因为数据量过少,模型将无法成功完成手写数字的识别任务。
相反,如果我们有数万张包含各种手写数字的图像,模型将有更多机会学到数字的共同特征,从而提高其在未见过的数据上的表现。这时候,给它一个新的手写数字图片,它就可以成功识别了。
3. 训练集中的数据质量是关键
高质量的训练数据能帮助模型更准确地把握数据的真实分布,从而提升模型在处理未知数据时的表现。
训练集中的质量关注点会落在标签的准确性,图像质量,数据异常值或噪声,数据采样偏差,数据来源一致性等方面。
如果标签有误,模型将学到错误的关系,影响其泛化能力。
假设需要AI模型完成一个医学图像识别的任务,如果图像标签错误地标注了病变类型,模型可能会对患者的健康状况做出错误的预测。
如果训练集包含错误的数据,模型可能会学到不准确的模式。
例如,在图像分类任务中,如果识别猫狗的图像中,出现了其他动物的图片,模型就会因训练不到位,产生不准确的分类结果。
不只是错误数据,低质量的数据也不行。
如果识别猫狗的图像训练集中,大都是模糊的,分辨率低的,光线暗的,边缘不清晰的图片。那么最后模型的预测性能也不会好到哪里去。
还有哦,数据集中的采样偏差也可能导致模型在某些类别上表现较差。
如果训练集中某个类别的样本数量远远超过其他类别,模型可能会偏向于学习这个类别,而对其他类别的分类效果较差。
在金融欺诈检测中,如果正常交易的数量远远超过欺诈交易,模型可能更难捕捉欺诈交易的模式。
最后一点,如果训练集包含来自不同来源的数据,数据之间的不一致性可能导致模型性能下降。
例如,在自动驾驶领域,如果训练数据来自于不同城市或天气条件下的驾驶场景,模型可能在特定城市场景下的泛化能力较差。

4. 训练集模拟案例-猫猫识别模型
说了这么多,我们不妨来一个模拟案例-猫猫识别模型
此刻,我们脑暴一下,如果我们要训练一个识别猫的图像分类模型,我们该如何准备训练集数据呢?
首先,图片的数量不能少。我们至少要准备上万张图片,确保模型可以更全面地学习到猫的特征差异。
同时,我们在收集图片时,还需要注重图片的代表性。也就是说训练集应该包含各种各样的猫的图片。
这意味着我们不仅需要收集不同品种、年龄和颜色的猫的图片,还要收集正面、侧面、背面以及俯视和仰视角度的猫的图片。
此外,我们还需要收集在不同光照条件下拍摄的猫的图片,如自然光、室内灯光和夜晚等。同时,还应该收集各种背景环境的猫的图片,如草地、沙滩、街道等。
有了一定数量和代表性的图片后,在质量方面也不能忽视。因此,在收集图片时,我们需要确保训练集中的每一张图片都是高清的、无模糊或失真的,并且尽量避免使用过度处理或有滤镜效果的图片。
在图片中,猫的毛发、眼睛、耳朵等特征都是模型学习的重要依据,而高清图片能够为模型提供更丰富的细节信息。
如果图片质量较差,这些特征可能会被模糊或者丢失,导致模型无法准确识别。因此,在收集训练数据时,我们应尽量选择分辨率较高的图片,以便模型能够捕捉到更多的细节。
还有一点,我们可以在收集训练数据时,要尽量拿到无噪声的图片。因为无噪声的图片有助于提高模型的学习效率。
在实际场景中,拍摄环境可能受到光线、设备等因素的影响,导致图片存在一定的噪声。这些噪声会对模型的学习产生干扰,降低训练效果。
为了解决这个问题,要尽量选择光线充足、设备稳定的环境进行拍摄,或者通过后期处理技术去除图片中的噪声。
此外,我们还需要关注图片的色彩平衡和对比度。色彩平衡是指图片中各种颜色的分布是否均匀,对比度是指图片中明暗区域的对比程度。
一个具有良好色彩平衡和对比度的图片,能够更准确地反映猫的颜色和纹理信息,有助于模型进行准确的识别。因此,在进行图片收集时,我们应尽量选择色彩平衡且对比度适中的图片,以提高模型的学习效果。
还有非常关键的一环,当我们准备好了合适的图库后,我们需要关注每张图像是否添加了正确的标签。正确的标签会告诉模型,图像中是否真的包含猫。这是模型能正确训练的前提。
最后,我们将图片库数据进行划分,通常会划分出60%~80%左右的数量比例用于训练集中。剩下的划分到验证集和测试集中。
是不是觉得,机器识别图片和我们人类识别图片,有很大的差异呢?连准备训练数据都有那么多注意事项,这和我们随便拿一张有猫的图片教小孩识别图中的猫,还是很不一样的。
二、辅导员角色:验证集(Validation Set)
在机器学习中,训练集是用来训练模型的数据,而验证集通常是从原始数据集中划分出来的一个子集,用于在训练过程中检查模型的性能,是在过拟合或欠拟合的情况下对模型进行评估和调整的数据。
验证集的主要目的是为了找到一个最佳的模型及参数,使得模型在未知数据上的表现最好。
之前提到,训练集一般会占用60%或80%的比例,对应的验证集则一般会占用20%或10%的比例。划分比例的依据可以根据实际需求和数据集的大小来确定。
通常情况下,我们可以使用随机抽样的方法从原始数据集中划分验证集。
验证集在整个模型训练的过程中起着关键的作用,我们从几个方面出发,聊聊其重要性。

1. 调整模型的超参数
在机器学习模型中,有许多超参数需要我们参与设置,例如学习率、隐藏层神经元数量等。这些超参数的选择对模型的性能有很大影响。
为了找到最优的超参数组合,我们可以将训练过程分为多个阶段,每个阶段使用不同的超参数组合进行训练。然后,我们可以使用验证集来评估每个阶段模型的性能,从而选择出最优的超参数组合。
BTW,补充一个知识点,关于模型参数和模型超参数,是怎么回事。
在机器学习中,模型参数是模型内部的配置变量,它们是在建模过程中通过数据自动学习得到的。例如,在线性回归或逻辑回归模型中,这些参数对应于方程中的系数;在支持向量机中,它们是支持向量;在神经网络中,则是连接不同层之间的权重。这些参数的学习是模型训练的核心,旨在捕捉数据中的模式和关系。
相对地,模型超参数是模型外部的配置变量,它们不是从数据中学习得到的,而是由研究人员或数据科学家根据先验知识和经验预先设定的。超参数包括学习率、迭代次数、网络层数、隐藏单元的数量等,它们对模型的性能和训练过程有显著影响。正确的超参数选择对于获得高效的模型至关重要,通常需要通过实验和调优来确定最佳值。
2. 早停策略
在训练过程中,如果我们发现模型在验证集上的性能不再提高时,可以提前停止训练。
具体来说,我们可以设置一个小的阈值,当模型在连续多个迭代周期内,验证集上的误差没有降低到这个阈值以下时,我们就认为模型已经收敛,可以停止训练。
这样既可以节省训练时间,也可以降低不必要的成本。
3. 防止过拟合
过拟合是机器学习中的一个常见问题,指的是模型在训练集上表现很好,但在测试集上表现较差的现象。这是因为模型过于复杂,学习到了训练集中的一些噪声和异常数据。
为了解决这个问题,我们可以使用验证集来监控模型在训练过程中的性能。
如果发现模型在训练集上的表现越来越好,但在验证集上的表现越来越差,那么我们可以考虑减少模型的复杂度或者增加正则化项,以防止过拟合的发生。
4. 对比不同模型结构
我们可以通过对比不同模型结构在验证集上的性能,选择最适合任务的模型结构。
这有助于避免选择过于简单或过于复杂的模型,从而提高模型的实际效果。
比如,比较卷积神经网络(CNN) 和循环神经网络(RNN) 在情感分析任务上的性能。通过观察它们的表现,选择更适合处理文本数据的模型结构。
5. 验证集模拟案例-猫猫识别模型
了解了验证集后,我们趁热打铁,继续猫猫识别模型的模拟案例。
为了有效完成猫的图像识别任务,我们假设已经选择好了一个合适的图像分类模型:卷积神经网络(CNN)。
在训练CNN模型时,我们需要设置一些超参数,如学习率、批次大小、迭代次数等。
一般来说,我们可以先设置一个较大的学习率,然后逐渐减小,以加快收敛速度。
批次大小和迭代次数的选择则需要根据具体任务和计算资源来确定。
在模型的训练过程中,我们需要周期性地使用验证集来评估模型在未见过的数据上的表现。这有助于检测模型是否过拟合训练,泛化能力如何等等。
评估性能时,我们会用到一些数据指标。最常用的指标是准确率(accuracy),即正确分类的样本数占总样本数的比例。
此外,我们还可以使用其他指标,如精确率(precision)、召回率(recall)和F1分数(F1-score)等,以便更全面地了解模型的性能。这些指标可以反映CNN模型对新的猫图片数据的分类能力。
BTW,关于这些指标的详细解释,我在本篇《产品经理的独门技能—AI监督学习(6000字干货)》中有进一步的介绍,感兴趣的朋友也可以去看看。
通过验证集的指标反馈,我们会观测到一些问题。
如果模型在某一类别上的准确率较低,可能说明该类别的训练样本较少或者特征不够明显。
针对这种情况,我们可以尝试增加该类别的训练样本或者调整模型结构。
此外,我们还需要注意数据的过拟合现象。
如果出现过拟合问题,我们可以采用增加数据量、简化模型、正则化技术等方法来解决。
最后,我们还需要关注验证集的损失函数(loss function)。损失函数用于衡量模型预测结果与真实结果之间的差距。
损失函数的值越小,越意味着模型的预测结果与真实结果更接近。《(万字干货)如何训练优化“AI神经网络”模型?》中有对损失函数的展开介绍。
总体而言,验证集的使用是一个迭代的调优过程,它会辅助我们观测和调整CNN模型,以确保模型能够有效学习和区分猫的特征,提高CNN模型在实际应用中识别猫图像的准确性和可靠性。
至此,我们可以说,算是完成了CNN模型在验证集上的训练调优。
温馨提示,在使用验证集时,我们还需要注意一些问题。
首先,我们不能在验证集上进行多次迭代,否则验证集就变成了一个“小训练集”。就可能会导致信息泄露,使得模型过分适应验证集的数据分布,从而失去了泛化能力。
还需注意的是,为了避免信息泄露。验证集中的数据应该是模型在训练过程中没有见过的,以真实地模拟模型在实际应用中的性能。
三、考官角色:测试集(Test Set)
现在,我们已经知道了验证集主要用于在训练过程中对模型进行评估和调整。
那它能保证模型在未来的未知数据上具有良好的性能吗?
为了找到这个答案,我们在验证集训练完成后,还需要进行测试,以进一步评估模型的泛化能力。
这时候,测试集就要闪亮登场了。
它扮演着模型性能的“考官”角色,它的考核结果将帮助我们衡量模型是否真正学会了我们需要它学习的知识。
测试集也是从原始数据集中分离出来的一部分数据,但它不参与模型的训练过程。它是一个独立的数据集,其中的数据样例是模型在实际应用中首次遇到的数据,之前素未谋面。
测试集在整个模型训练的过程中,无论是评估模型泛化能力,还是发现潜在问题,又或者是帮助模型优化和调参等方面,都起到了重要的作用。
下面我们来展开讨论一下测试集在整个数据集中起到了什么作用?

1. 评估模型的泛化能力
测试集的最大价值之一是用于评估模型的泛化能力,以衡量模型在未知数据上的表现。
在AI模型训练过程中,我们往往会在训练集上看到很好的表现。
然而,这并不意味着模型已经真正掌握了知识,能够在新遇到的数据上同样表现优秀。为了验证这一点,我们需要借助测试集来进行评估。
通过测试集,我们可以得到模型在真实世界中的泛化能力,而不仅仅是在训练数据上的记忆能力。
我们的目标不仅仅是让模型在训练中取得高分,而是要确保它能够灵活应对新的挑战。
2. 发现潜在问题
测试集会帮助我们发现模型的潜在问题,比如,发现模型不稳定。
正常来说,在不同时间或不同环境下,模型在测试集上的性能应该保持相对一致。
又或者,发现数据质量不一致性的问题,测试集中出现了与训练集不同的数据分布或标签分布。
测试集还可以用于评估模型对于异常情况的处理能力。
在真实场景中,模型可能会面对不同于训练数据的情形,如噪声、异常值或极端情况。
测试集的设计可以包含这些异常情况,帮助评估模型的鲁棒性和处理能力。
一个鲁棒性强的模型能够在各种条件下都能稳定地工作,而不会因为某些小的变化或者噪声而导致性能大幅下降。
例如,一个用于自动驾驶汽车的图像识别模型,即使在雨天、雾天或者光照不足的情况下,也能够准确地识别出物体,我们就可以说这个模型的鲁棒性很强。
因此,通过测试集,我们能发现模型的潜在问题和缺陷,也有助于我们及时对模型进行调整和改进。
3. 模型调优
测试集的结果为我们提供了宝贵的反馈,它们是优化模型和调整参数的客观依据。
通过分析测试集的表现,我们可以确定最佳的模型结构和参数设置。
例如,我们可以根据测试集的准确率来调整神经网络的层数、每层的神经元数量以及激活函数等关键参数。
如果测试结果显示,使用卷积神经网络(CNN)和特定参数配置时,模型的表现最为出色,那么我们很可能会选择这个配置作为我们的最终模型。
这样的选择会更靠谱和可信。因为它是基于测试集上实际的数据反馈,而不是仅仅依赖于训练集上的性能来确定模型是否具有良好的泛化能力。
4. 防止过拟合
测试集可以帮助我们检测模型是否过拟合。当模型在训练集和验证集上表现良好,但在测试集上表现不佳时,这可能是一个警示信号。
打个比方,假设我们有一个信贷审批模型,它在训练和验证阶段都展现出了很高的准确率,但在测试阶段准确率却明显降低。
这种情况通常意味着模型对训练数据过于敏感,没有很好地泛化到新数据上。
我们需要采取一些措施,如简化模型结构或引入正则化方法来减少过拟合的风险。
最后,在整个AI项目中,我们也要注意做好数据隔离,保证数据独立性,避免在处理过程中将测试集的信息泄露到训练集中。
我们需要确保AI遇见的测试集中的数据都是新面孔。
5. 测试集模拟案例-猫猫识别模型
我们继续猫猫识别模型的模拟案例,说说测试集的使用。
照例,要先做好数据准备和数据划分。通常,测试集占原始数据集的10%至20%。
数据划分时要确保数据分布的一致性,以便在不同阶段的模型训练和评估中能够准确地反映出模型的性能。
然后,我们将经历过训练集和验证集考验后的模型,引入测试集进行训练并观测,通过数据指标来进行评估。
我们可以重点关注准确率和损失函数这两个值,准确率表示模型在识别猫图像时的正确率,损失函数表示模型在预测猫图像时的误差。
根据测试集反馈的指标结果,我们可以知晓模型是否能够准确地识别图像中的猫。
比如当出现新的猫的姿势、颜色和背景时,当图片的光照和清晰度水准不一时,模型是否都能认出图中有猫。
当模型经过测试集的检验后,我们最后要做的,就是完成模型部署。
我们将表现最好的猫猫图像识别模型部署到实际应用中。例如,我们可以将这个模型应用于智能监控系统,自动识别和追踪摄像头范围内的猫。
四、总结与预告
以上,就是关于训练集,验证集,测试集的独家介绍了。我将三者比喻成了教师、辅导员和考官,通过猫猫识别模型的模拟案例来展示了它们各自的能力。
训练集为模型提供了学习的基础,使得模型能够从数据中学习到规律和特征。
正如,古人云:“授人以鱼不如授人以渔”,训练集就是那个“渔”,它为模型提供了学习的方法和途径。
验证集的作用在于调整模型的超参数,防止过拟合,采用早停策略,以及对比不同模型结构。
通过验证集,我们能够在训练过程中及时发现模型的问题,并采取相应的措施进行调整。
恰似,“他山之石,可以攻玉”,验证集就是那个“他山之石”,它帮助我们发现问题,改进模型。
测试集是对模型最终性能的评估,它能够客观地反映模型的泛化能力。
可谓,“路遥知马力,日久见人心”,测试集就是那个“路遥”探测器,它能够检验模型的真正实力。
“工欲善其事,必先利其器”,训练集、验证集和测试集就是我们构建和评估模型的“利器”。
充分利用好它们,我们可以构建出性能优秀、泛化能力强的模型,在人工智能的发展中,抓住机遇,收获成功。
预告一下,AI数据集的内容我还没说完。
下一篇章我会唠唠“训练集,验证集,测试集”的区别和联系,也会说一些目前国内数据集的现状、挑战和应对之策。
作者:果酿,公众号:果酿产品说
本文由 @果酿 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK