

自然语言处理之 BERT
source link: https://www.biaodianfu.com/bert.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
BERT简介
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言表示的方法,由Google的研究者在2018年提出。它在自然语言处理(NLP)领域取得了革命性的进展,尤其是在理解上下文含义方面。BERT的出现标志着从单向语言模型到基于Transformer的双向预训练语言模型的重大转变。

核心特点
- 双向上下文理解: BERT的关键创新之一是它的双向特性。它通过同时考虑文本中每个词的左右两侧上下文来理解词义,这与之前的模型(如ELMo或GPT)不同,后者只能从一个方向(左到右或右到左)考虑上下文。
- 基于Transformer: BERT使用的是Transformer架构,特别是它的编码器部分。Transformer是一种注意力机制(Attention Mechanism),它允许模型在处理每个单词时关注输入序列中的所有其他单词,从而更有效地捕捉上下文。
- 大规模预训练和微调: BERT模型首先在大量文本上进行预训练,学习通用的语言模式和知识。然后,可以针对特定任务(如情感分析、问题回答等)对模型进行微调。
预训练任务
BERT在预训练阶段使用了两种主要任务:
- 掩码语言模型(Masked Language Model, MLM): 在这个任务中,输入文本的一部分单词被随机掩盖(例如,用”[MASK]”标记代替),模型需要预测这些掩盖的单词。这种方法使模型能够学习双向上下文。
- 下一句预测(Next Sentence Prediction, NSP): 在这个任务中,模型接收一对句子作为输入,并学习预测第二个句子是否是文本中紧随第一个句子的下一句。
应用和性能
BERT在多个NLP任务上展示了卓越的性能,包括但不限于文本分类、情感分析、问题回答、实体识别等。它在许多标准NLP基准测试中设置了新的记录,改变了人们对自然语言理解的方法。
BERT优势
- 深度语境理解:由于其双向结构,BERT能够更深入地理解词语在不同上下文中的含义。
- 高效的迁移学习:通过预训练和微调的流程,BERT能够将在大规模数据集上学到的知识迁移到特定任务上,减少了对大量标记数据的依赖。
- 突破性的性能:在多种NLP基准测试中,BERT展现出了卓越的性能。
BERT挑战
- 计算资源密集:由于模型的规模和预训练过程的复杂性,BERT需要大量的计算资源。
- 处理长文本的局限性:由于Transformer的自注意力机制,BERT在处理非常长的文本时可能会遇到性能瓶颈。
变体和进化
自BERT问世以来,已经出现了许多基于BERT的变体和改进模型,例如RoBERTa(Facebook的一个改进版BERT)、ALBERT(一个更轻量级的版本)、BERT-large(一个更大更复杂的版本)等。这些变体通常在某些方面对原始BERT模型进行了优化或调整。
总之,BERT是NLP领域的一个重要里程碑,它通过有效地利用双向上下文和Transformer架构,为各种文本处理任务提供了强大的基础。
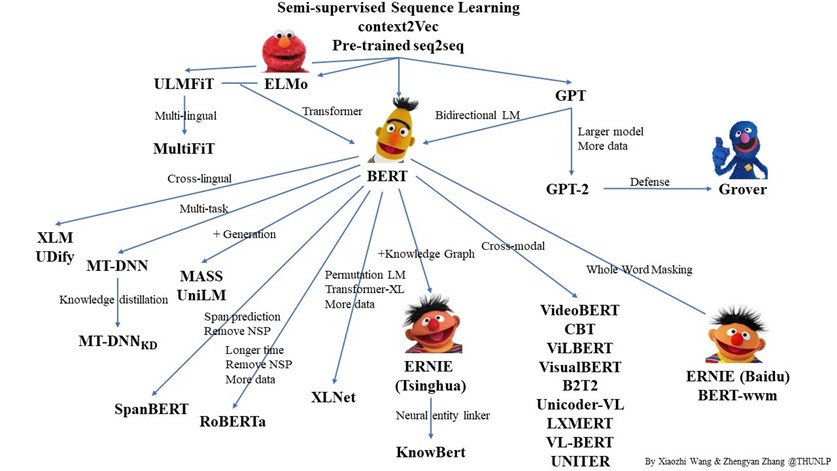
BERT的产生背景
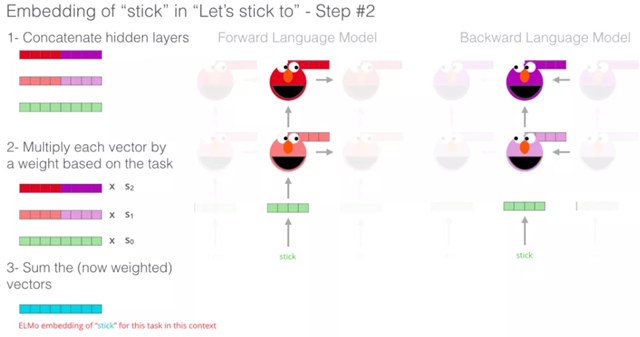
如果我们使用 Glove 的词嵌入表示方法,那么不管上下文是什么,单词 “stick” 都只表示为一个向量。一些研究人员指出,像 “stick” 这样的词有多种含义。为什么不能根据它使用的上下文来学习对应的词嵌入呢?这样既能捕捉单词的语义信息,又能捕捉上下文的语义信息。于是,语境化的词嵌入模型应运而生:ELMo。
语境化的词嵌入,可以根据单词在句子语境中的含义,赋予不同的词嵌入。ELMo没有对每个单词使用固定的词嵌入,而是在为每个词分配词嵌入之前,查看整个句子,融合上下文信息。它使用在特定任务上经过训练的双向LSTM来创建这些词嵌入。
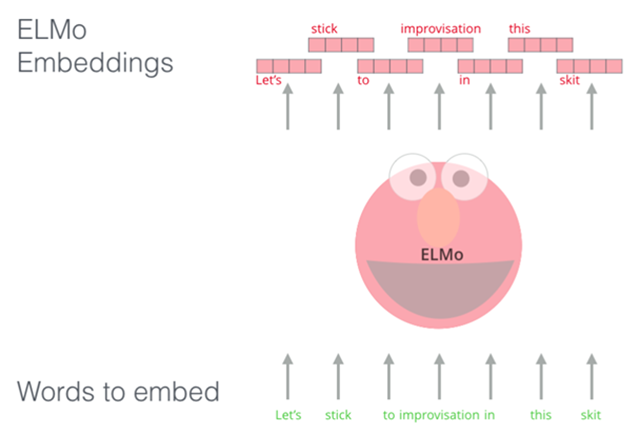
ELMo LSTM 会在一个大规模的数据集上进行训练,然后我们可以将它作为其他语言处理模型的一个部分,来处理自然语言任务。
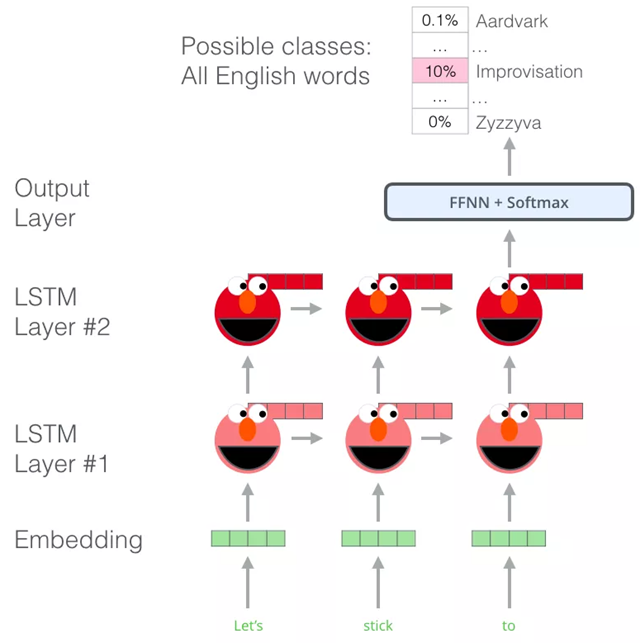
ELMo预训练过程是一个典型的语言模型:以 “Let’s stick to” 作为输入,预测下一个最有可能的单词。当我们在大规模数据集上训练时,模型开始学习语言的模式。例如,在 “hang” 这样的词之后,模型将会赋予 “out” 更高的概率(因为 “hang out” 是一个词组),而不是输出 “camera”。
在上图中,我们可以看到 ELMo 头部上方展示了 LSTM 的每一步的隐藏层状态向量。在这个预训练过程完成后,这些隐藏层状态在词嵌入过程中派上用场。
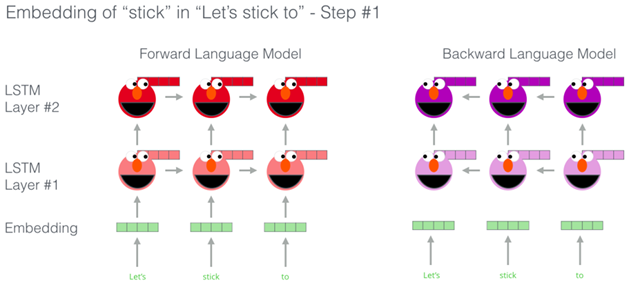
ELMo是NLP社区对一词多义问题的回应——相同的词在不同的语境中有不同的含义。从训练浅层前馈网络(Word2vec),逐步过渡到使用复杂的双向LSTM体系结构的层来训练Word Embedding。这意味着同一个单词可以根据它所在的上下文有多个ELMO Embedding。
ELMo 通过将LSTM模型的隐藏层表示向量(以及初始化的词嵌入)以某种方式(向量拼接之后加权求和)结合在一起,实现了带有语境化的词嵌入。
BERT被设计成一个深度双向模型。网络有效地从第一层本身一直到最后一层捕获来自目标词的左右上下文的信息。传统上,我们要么训练语言模型预测句子中的下一个单词(GPT中使用的从右到左的上下文),要么训练语言模型预测从左到右的上下文。这使得我们的模型容易由于信息丢失而产生错误。
ELMo试图通过在左到右和从右到左的上下文中训练两个LSTM语言模型并对其进行浅级连接来解决此问题。即使它在现有技术上有了很大的改进,但这还不够。
“凭直觉,我们有理由相信,深层双向模型比左向右模型或从左至右和从右至左模型的浅级连接严格更强大。” – BERT
这就是BERT在GPT和ELMo上都大大改进的地方。
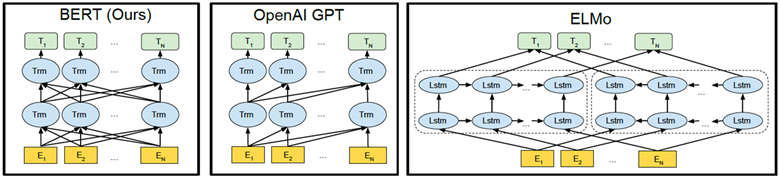
如上图所示,图中的Trm代表的是Transformer层,E代表的是Token Embedding,即每一个输入的单词映射成的向量,T代表的是模型输出的每个Token的特征向量表示。
BERT使用的是双向的Transformer,OpenAI GPT使用的是从左到右的Transformer。ELMo使用的是单独的从左到右和从右到左的LSTM拼接而成的特征。其中只有BERT在所有的层考虑了左右上下文。除此之外,BERT和OpenAI GPT是微调(fine-tuning)的方法,而ELMo是一个基于特征的方法。
从网络结构以及最后的实验效果来看,BERT 比 ELMo 效果好主要集中在以下几点原因:
- LSTM 抽取特征的能力远弱于 Transformer
- 拼接方式双向融合的特征融合能力偏弱
- BERT 的训练数据以及模型参数均多于 ELMo
BERT的原理
BERT,全称是 Pre-training of Deep Bidirectional Transformers for Language Understanding。注意其中的每一个词都说明了 BERT 的一个特征。
- Pre-training 说明 BERT 是一个预训练模型,通过前期的大量语料的无监督训练,为下游任务学习大量的先验的语言、句法、词义等信息。
- Bidirectional 说明 BERT 采用的是双向语言模型的方式,能够更好的融合前后文的知识。
- Transformers 说明 BERT 采用 Transformers 作为特征抽取器。
- Deep 说明模型很深,base 版本有 12 层,large 版本有 24 层。
总的来说,BERT 是一个用 Transformers 作为特征抽取器的深度双向预训练语言理解模型。
BERT的体系结构
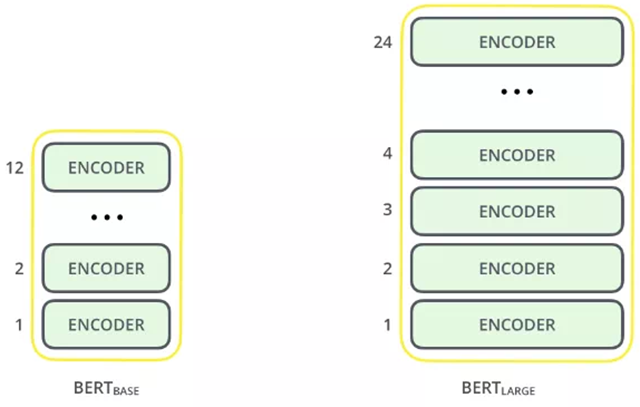
BERT架构建立在Transformer之上。我们目前有两个可用的版本:
- BERT Base:12层transformer,12个attention heads和1亿个参数
- BERT Large:24层transformer,16个attention heads和4亿个参数
BERT的模型输入
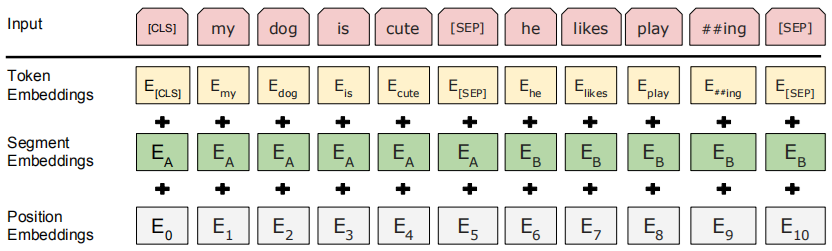
BERT背后的开发人员已经添加了一组特定规则来表示模型的输入文本。其中许多是创造性的设计选择,目的是使模型更好。
对于初学者,每个输入的Embedding是3个嵌入的组合:
- 位置嵌入(Position Embeddings):BERT学习并使用位置嵌入来表达句子中单词的位置。这些是为了克服Transformer的限制而添加的,Transformer与RNN不同,它不能捕获“序列”或“顺序”信息
- 段嵌入(Segment Embeddings):BERT还可以将句子对作为任务的输入(可用于问答)。这就是为什么它学习第一和第二句话的独特嵌入,以帮助模型区分它们。在上面的例子中,所有标记为EA的标记都属于句子A(对于EB也是一样)
- 目标词嵌入(Token Embeddings):这些是从WordPiece词汇表中对特定词汇学习到的嵌入。每次输入总以符号[CLS]的 embedding 开始,如果是两个句子,则句之间用[SEP]隔开。
对于给定的目标词,其输入表示是通过对相应的目标词、段和位置的Embedding进行求和来构造的。
这样一个综合的Embedding方案包含了很多对模型有用的信息。
这些预处理步骤的组合使BERT如此多才多艺。这意味着,不需要对模型的体系结构进行任何重大更改,我们就可以轻松地对它进行多种NLP任务的训练。
BERT的模型输出
BERT模型的输出依赖于它被应用于的特定任务。通常,BERT的输出可以分为两类:特征表示和特定任务的输出。让我们详细探讨这两类输出。
- 上下文相关的嵌入:BERT的主要输出是输入序列中每个词的高维向量表示,这些表示捕捉了词语在其上下文中的意义。这种向量表示是深层次的,因为它们是由BERT网络的多层生成的。
- 序列表示:BERT还提供整个输入序列的表示,通常是特殊的[CLS]标记的输出,这在某些任务(如句子分类)中特别有用。
特定任务的输出
- 分类任务(如情感分析):对于分类任务,BERT的输出通常是一个固定长度的向量(通常是[CLS]标记的输出),然后通过一个或多个额外的全连接层来预测类别标签。
- 问答任务:在问答系统中,BERT的输出是用于确定答案在文本中位置的起始和结束标记的概率分布。
- 命名实体识别(NER):对于NER任务,BERT输出输入序列中每个词的表示,然后这些表示被用于预测每个词的实体类型(如人名、地点等)。
- 文本生成任务:尽管BERT主要用于分类和回答问题,它也可以通过特定的架构调整(如添加解码器)来进行文本生成。
输出的灵活性
- 微调:根据特定任务的需要,BERT的输出可以通过微调过程进行调整。在微调时,可以在BERT的顶部添加特定的层(如全连接层、LSTM层等),以便它能够生成适合特定任务的输出。
BERT输入的所有token经过BERT编码后,会在每个位置输出一个大小为 hidden_size(在 BERT-base中是 768)的向量。
BERT的预训练任务
BERT(Bidirectional Encoder Representations from Transformers)的预训练包括两个主要任务:掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)。这两个任务共同使得BERT能够有效地学习语言表示。下面是对这两个预训练任务的详细介绍:
掩码语言模型(MLM)
- 目标:MLM的目的是使模型能够理解和预测文本中的词语,即使它们被掩盖了。
- 操作:在预训练过程中,BERT随机地选择输入文本中的一些词语并将其替换为特殊的[MASK]标记。然后,模型被训练来预测这些被掩盖的词语,基于它们的上下文。
- 重要性:这种方法迫使BERT在预测词语时考虑双向上下文,即它必须使用左侧和右侧的词语信息。这使得模型能够更全面地理解语言结构和词语间的关系。
下一句预测(NSP)
- 目标:NSP的目标是使模型能够理解句子间的关系。
- 操作:在这个任务中,BERT被给予一对句子作为输入,并需要判断第二个句子是否是第一个句子的逻辑后继。在训练样本中,50%的时间里,第二个句子是紧接着第一个句子的下一句;另外50%的时间里,第二个句子是从语料库中随机选择的,与第一个句子无逻辑关系。
- 重要性:通过NSP任务,BERT学习了如何理解和推断句子间的关系,这对于理解段落和文章的整体结构非常重要。
这两个预训练任务共同为BERT提供了全面的语言理解能力。MLM使得模型能够深入理解单词在不同上下文中的含义,而NSP赋予模型理解句子间关系的能力。这种预训练使得BERT在后续的特定任务上,如文本分类、问答系统、命名实体识别等,能够通过微调快速有效地适应并展现出色的性能。
掩码语言模型(Masked Language Model)
MLM是BERT能够不受单向语言模型所限制的原因。简单来说就是以15%的概率用mask token ([MASK])随机地对每一个训练序列中的token进行替换,然后预测出[MASK]位置原有的单词。然而,由于[MASK]并不会出现在下游任务的微调(fine-tuning)阶段,因此预训练阶段和微调阶段之间产生了不匹配(这里很好解释,就是预训练的目标会令产生的语言表征对[MASK]敏感,但是却对其他token不敏感)。
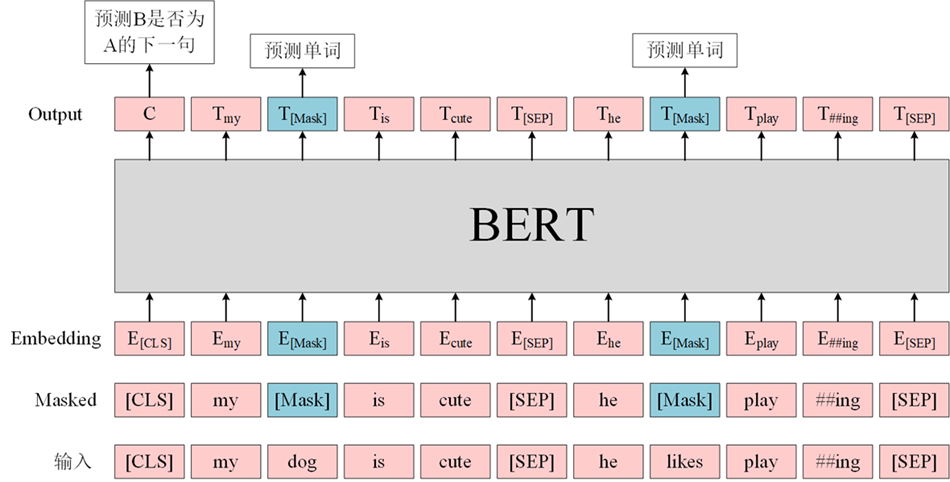
因此BERT采用了以下策略来解决这个问题:
首先在每一个训练序列中以15%的概率随机地选中某个token位置用于预测,假如是第i个token被选中,则会被替换成以下三个token之一
- 80%的时候是[MASK]。如,my dog ishairy——>my dog is [MASK]
- 10%的时候是随机的其他token。如,my dog ishairy——>my dog is apple
- 10%的时候是原来的token(保持不变,个人认为是作为2)所对应的负类)。如,my dog ishairy——>my dog is hairy
再用该位置对应的 $T_i $去预测出原来的token(输入到全连接,然后用softmax输出每个token的概率,最后用交叉熵计算loss)。
该策略令到BERT不再只对[MASK]敏感,而是对所有的token都敏感,以致能抽取出任何token的表征信息。

该怎么理解 Masked Language Model 呢?我们不妨回想一下高中阶段都做过的英语完形填空,我们在做完形填空题目的时候,为了填上空格中的词,常常需要不断的看空格词的上下文,甚至要了解整个段落的信息。有时候,有些空甚至要通过一些英语常识才能得到答案。通过做完形填空,我们能够学习到英语中很多的词义、句法和语义信息。BERT 的训练过程也类似,Masked Language Model 通过预测[MASK]代替的词,不断的“对比”上下文的语义,句法和词义信息,从而学到了大量相关的知识。
- 被随机选择15%的词当中以10%的概率用任意词替换去预测正确的词,相当于文本纠错任务,为BERT模型赋予了一定的文本纠错能力;
- 被随机选择15%的词当中以10%的概率保持不变,缓解了finetune时候与预训练时候输入不匹配的问题(预训练时候输入句子当中有mask,而finetune时候输入是完整无缺的句子,即为输入不匹配问题)。
- 针对有两个及两个以上连续字组成的词,随机mask字割裂了连续字之间的相关性,使模型不太容易学习到词的语义信息。主要针对这一短板,因此google此后发表了BERT-WWM,国内的哈工大联合讯飞发表了中文版的BERT-WWM。
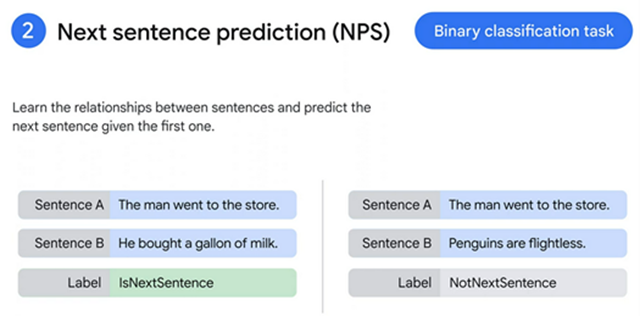
下一句预测(Next Sentence Prediction)
BERT 的预训练过程,还有一个预测下一句的任务。就是输入两个句子,判断第二个句子是不是第一个句子的下一句的任务。
通过这个任务,BERT 获得了句子级表征的能力。通常,BERT 的第一个输出,即[CLS]对应的输出,就可以用来当作输入句子的句向量来使用。
此类任务的一个很好的例子是问题回答系统。
任务很简单。给定两个句子——A和B, B是语料库中A后面的下一个句子,还是一个随机的句子?
由于它是一个二分类任务,因此可以通过将任何语料库分成句子对来轻松生成数据。就像MLM一样,作者在这里也添加了一些注意事项。让我们举个例子:
假设我们有一个包含100,000个句子的文本数据集。因此,将有50,000个训练例子或句子对作为训练数据。
- 对于50%的对来说,第二个句子实际上是第一个句子的下一个句子
- 对于剩下的50%,第二句是语料库中的一个随机句子
- 第一种情况的标签是“IsNext”,而第二种情况的标签是“NotNext”
这就是为什么BERT能够成为一个真正的任务不可知的模型。它结合了掩蔽语言模型(MLM)和下一个句子预测(NSP)的预训练任务。
BERT的微调
BERT整体框架包含pre-train和fine-tune两个阶段。pre-train阶段模型是在无标注的标签数据上进行训练,fine-tune阶段,BERT模型首先是被pre-train模型参数初始化,然后所有的参数会用下游的有标注的数据进行训练。
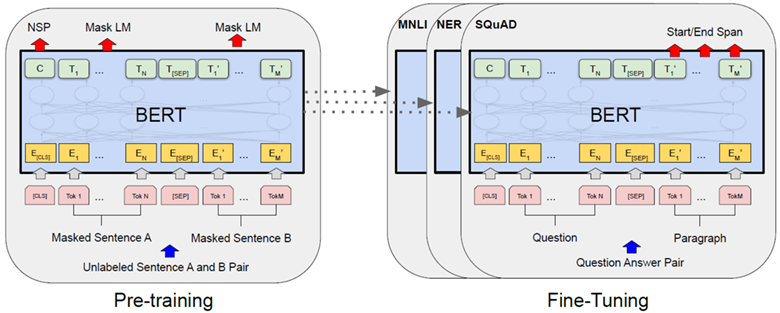
在海量的语料上训练完BERT之后,便可以将其应用到NLP的各个任务中了。微调(Fine-Tuning)的任务包括:基于句子对的分类任务,基于单个句子的分类任务,问答任务,命名实体识别等。
- 基于句子对的分类任务:
- MNLI:给定一个前提 (Premise) ,根据这个前提去推断假设 (Hypothesis) 与前提的关系。该任务的关系分为三种,蕴含关系 (Entailment)、矛盾关系 (Contradiction) 以及中立关系 (Neutral)。所以这个问题本质上是一个分类问题,我们需要做的是去发掘前提和假设这两个句子对之间的交互信息。
- QQP:基于Quora,判断 Quora 上的两个问题句是否表示的是一样的意思。
- QNLI:用于判断文本是否包含问题的答案,类似于我们做阅读理解定位问题所在的段落。
- STS-B:预测两个句子的相似性,包括5个级别。
- MRPC:也是判断两个句子是否是等价的。
- RTE:类似于MNLI,但是只是对蕴含关系的二分类判断,而且数据集更小。
- SWAG:从四个句子中选择为可能为前句下文的那个。
- 基于单个句子的分类任务
- SST-2:电影评价的情感分析。
- CoLA:句子语义判断,是否是可接受的(Acceptable)。
- 问答任务
- SQuAD v1.1:给定一个句子(通常是一个问题)和一段描述文本,输出这个问题的答案,类似于做阅读理解的简答题。
- 命名实体识别
- CoNLL-2003 NER:判断一个句子中的单词是不是Person,Organization,Location,Miscellaneous或者other(无命名实体)。
参考链接:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK