

Modernizing Granite’s mesh rendering
source link: https://themaister.net/blog/2024/01/17/modernizing-granites-mesh-rendering/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Modernizing Granite’s mesh rendering
Granite’s renderer is currently quite old school. It was written with 2017 mobile hardware in mind after all. Little to no indirect drawing, a bindful material system, etc. We’ve all seen that a hundred times before. Granite’s niche ended up exploring esoteric use cases, not high-end rendering, so it was never a big priority for me to fix that.
Now that mesh shading has starting shipping and is somewhat proven in the wild with several games shipping UE5 Nanite, and Alan Wake II – which all rely on mesh shaders to not run horribly slow – it was time to make a more serious push towards rewriting the entire renderer in Granite. This has been a slow burn project that’s been haunting me for almost half a year at this point. I haven’t really had the energy to rewrite a ton of code like this in my spare time, but as always, holidays tend to give me some energy for these things. Video shenanigans have also kept me distracted this fall.
I’m still not done with this rewrite, but enough things have fallen into place, that I think it’s time to write down my findings so far.
Design requirements
Reasonable fallbacks
I had some goals for this new method. Unlike UE5 Nanite and Alan Wake II, I don’t want to hard-require actual VK_EXT_mesh_shader support to run acceptably. Just thinking in terms of meshlets should benefit us in plain multi-draw-indirect (MDI) as well. For various mobile hardware that doesn’t support MDI well (or at all …), I’d also like a fallback path that ends up using regular direct draws. That fallback path is necessary to evaluate performance uplift as well.
What Nanite does to fallback
This is something to avoid. Nanite relies heavily on rendering primitive IDs to a visibility buffer, where attributes are resolved later. In the primary compute software rasterizer, this becomes a 64-bit atomic, and in the mesh shader fallback, a single primitive ID is exported to fragment stage as a per-primitive varying, where fragment shader just does the atomic (no render targets, super fun to debug …). The problem here is that per-primitive varyings don’t exist in the classic vertex -> fragment pipeline. There are two obvious alternatives to work around this:
- Geometry shaders. Pass-through mode can potentially be used if all the stars align on supported hardware, but using geometry shaders should revoke your graphics programmer’s license.
- Unroll a meshlet into a non-indexed draw. Duplicate primitive ID into 3 vertices. Use flat shading to pull in the primitive ID.
From my spelunking in various shipped titles, Nanite does the latter, and fallback rendering performance is halved as a result (!). Depending on the game, meshlet fallbacks are either very common or very rare, so real world impact is scene and resolution dependent, but Immortals of Aveum lost 5-15% FPS when I tested it.
The Visibility Buffer: A Cache-Friendly Approach to Deferred Shading suggests rendering out a visibility G-Buffer using InstanceID (fed through some mechanism) and SV_PrimitiveID, which might be worth exploring at some point. I’m not sure why Nanite did not go that route. It seems like it would have avoided the duplicated vertices.
Alan Wake II?
Mesh shaders are basically a hard requirement for this game. It will technically boot without mesh shader support, but the game gives you a stern warning about performance, and they are not kidding. I haven’t dug into what the fallback is doing, but I’ve seen people posting videos demonstrating sub-10 FPS on a 1080 Ti. Given the abysmal performance, I wouldn’t be surprised if they just disabled all culling and draw everything in the fallback.
A compressed runtime meshlet format
While studying https://github.com/zeux/meshoptimizer I found support for compressed meshes, a format that was turned into a glTF EXT. It seems to be designed for decompressing on CPU (completely serial algorithm), which was not all that exciting for me, but this sparked an idea. What if I could decompress meshlets on the GPU instead? There are two ways this can be useful:
- Would it be fast enough to decompress inline inside the mesh shader? This can potentially save a lot of read bandwidth during rendering and save precious VRAM.
- Bandwidth amplifier on asset loading time. Only the compressed meshlet format needs to go over PCI-e wire, and we decompress directly into VRAM. Similar idea to GDeflate and other compression formats, except I should be able to come up with something that is way faster than a general purpose algorithm and also give decent compression ratios.
I haven’t seen any ready-to-go implementation of this yet, so I figured this would be my starting point for the renderer. Always nice to have an excuse to write some cursed compute shaders.
Adapting to implementations
One annoying problem with mesh shading is that different vendors have very different fast paths through their hardware. There is no single implementation that fits all. I’ve spent some time testing various parameters and observe what makes NV and AMD go fast w.r.t. mesh shaders, with questionable results. I believe this is the number 1 reason mesh shaders are still considered a niche feature.
Since we’re baking meshlets offline, the format itself must be able to adapt to implementations that prefer 32/64/128/256 primitive meshlets. It must also adapt nicely to MultiDrawIndirect-style rendering.
Random-access
It should be efficient to decode meshlets in parallel, and in complete isolation.
The format
I went through some (read: way too many) design iterations before landing on this design.
256 vert/prim meshlets
Going wide means we get lower culling overhead and emitting larger MDI calls avoids us getting completely bottlenecked on command stream frontend churn. I tried going lower than 256, but performance suffered greatly. 256 seemed like a good compromise. With 256 prim/verts, we can use 8-bit index buffers as well, which saves quite a lot of memory.
Sublets – 8×32 grouping
To consider various hardware implementations, very few will be happy with full, fat 256 primitive meshlets. To remedy this, the encoding is grouped in units of 32 – a “sublet” – where we can shade the 8 groups independently, or have larger workgroups that shade multiple sublets together. Some consideration is key to be performance portable. At runtime we can specialize our shaders to fit whatever hardware we’re targeting.
Using grouping of 32 is core to the format as well, since we can exploit NV warps being 32-wide and force Wave32 on RDNA hardware to get subgroup accelerated mesh shading.
Format header
// Can point to mmap-ed file.
struct MeshView
{
const FormatHeader *format_header;
const Bound *bounds;
const Bound *bounds_256; // Used to cull in units of 256 prims
const Stream *streams;
const uint32_t *payload;
uint32_t total_primitives;
uint32_t total_vertices;
uint32_t num_bounds;
uint32_t num_bounds_256;
};
struct FormatHeader
{
MeshStyle style;
uint32_t stream_count;
uint32_t meshlet_count;
uint32_t payload_size_words;
};
The style signals type of mesh. This is naturally engine specific.
- Wireframe: A pure position + index buffer
- Textured: Adds UV + Normal + Tangent
- Skinned: Adds bone indices and weights on top
A stream is 32 values encoded in some way.
enum class StreamType
{
Primitive = 0,
Position,
NormalTangentOct8,
UV,
BoneIndices,
BoneWeights,
};
Each meshlet has stream_count number of Stream headers. The indexing is trivial:
streams[RuntimeHeader::stream_offset + int(StreamType)]
// 16 bytes
struct Stream
{
union
{
uint32_t base_value[2];
struct { uint32_t prim_count; uint32_t vert_count; } counts;
} u;
uint32_t bits;
uint32_t offset_in_words;
};
This is where things get a bit more interesting. I ended up supporting some encoding styles that are tailored for the various attribute formats.
Encoding attributes
There’s two parts to this problem. First is to decide on some N-bit fixed point values, and then find the most efficient way to pull those bits from a buffer. I went through several iterations on the actual bit-stuffing.
Base value + DELTA encoding
A base value is encoded in Stream::base_value, and the decoded bits are an offset from the base. To start approaching speed-of-light decoding, this is about as fancy as we can do it.
I went through various iterations of this model. The first idea had a predictive encoding between neighbor values, where subgroup scan operations were used to complete the decode, but it was too slow in practice, and didn’t really improve bit rates at all.
Index buffer
Since the sublet is just 32-wide, we can encode with 5-bit indices. 15 bit / primitive. There is no real reason to use delta encode here, so instead of storing base values in the stream header, I opted to use those bits to encode vertex/index counts.
Position
This is decoded to 3×16-bit SINT. The shared exponent is stored in top 16 bits of Stream::bits.
vec3 position = ldexp(vec3(i16vec3(decoded)), exponent);
This facilitates arbitrary quantization as well.
Similar idea as position, but 2×16-bit SINT. After decoding similar to position, a simple fixup is made to cater to typical UVs which lie in range of [0, +1], not [-1, +1].
vec2 uv = 0.5 * ldexp(vec2(i16vec2(decoded)), exponent) + 0.5;
Normal/Tangent
Encoded as 4×8-bit SNORM. Normal (XY) and Tangent (ZW) are encoded with Octahedral encoding from meshoptimizer library.
To encode the sign of tangent, Stream::bits stores 2 bits, which signals one of three modes:
- Uniform W = -1
- Uniform W = +1
- LSB of decoded W encodes tangent W. Tangent’s second component loses 1 bit of precision.
Bone index / weight
Basically same as Normal/Tangent, but ignore tangent sign handling.
First (failed?) idea – bitplane encoding
For a long time, I was pursuing bitplane encoding, which is one of the simplest ways to encode variable bitrates. We can encode 1 bit for 32 values by packing them in one u32. To speed up decoding further, I aimed to pack everything into 128-bit aligned loads. This avoids having to wait for tiny, dependent 32-bit loads.
For example, for index buffers:
uint meshlet_decode_index_buffer(
uint stream_index, uint chunk_index,
int lane_index)
{
uint offset_in_b128 =
meshlet_streams.data[stream_index].offset_in_b128;
// Fixed 5-bit encoding.
offset_in_b128 += 4 * chunk_index;
// Scalar load. 64 bytes in one go.
uvec4 p0 = payload.data[offset_in_b128 + 0];
uvec4 p1 = payload.data[offset_in_b128 + 1];
uvec4 p2 = payload.data[offset_in_b128 + 2];
uvec4 p3 = payload.data[offset_in_b128 + 3];
uint indices = 0;
indices |= bitfieldExtract(p0.x, lane_index, 1) << 0u;
indices |= bitfieldExtract(p0.y, lane_index, 1) << 1u;
indices |= bitfieldExtract(p0.z, lane_index, 1) << 2u;
indices |= bitfieldExtract(p0.w, lane_index, 1) << 3u;
indices |= bitfieldExtract(p1.x, lane_index, 1) << 8u;
indices |= bitfieldExtract(p1.y, lane_index, 1) << 9u;
indices |= bitfieldExtract(p1.z, lane_index, 1) << 10u;
indices |= bitfieldExtract(p1.w, lane_index, 1) << 11u;
indices |= bitfieldExtract(p2.x, lane_index, 1) << 16u;
indices |= bitfieldExtract(p2.y, lane_index, 1) << 17u;
indices |= bitfieldExtract(p2.z, lane_index, 1) << 18u;
indices |= bitfieldExtract(p2.w, lane_index, 1) << 19u;
indices |= bitfieldExtract(p3.x, lane_index, 1) << 4u;
indices |= bitfieldExtract(p3.y, lane_index, 1) << 12u;
indices |= bitfieldExtract(p3.z, lane_index, 1) << 20u;
return indices;
}
On Deck, this ends up looking like
s_buffer_load_dwordx4 x 4 v_bfe_u32 x 15 v_lshl_or_b32 x 15
Thinking about ALU and loads in terms of scalar and vectors can greatly help AMD performance when done right, so this approach felt natural.
For variable bit rates, I’d have code like:
if (bits & 4) { unroll_4_bits_bit_plane(); }
if (bits & 2) { unroll_2_bits_bit_plane(); }
if (bits & 1) { unroll_1_bit_bit_plane(); }
However, I abandoned this idea, since while favoring SMEM so heavily, the VALU with all the bitfield ops wasn’t exactly amazing for perf. I’m still just clocking out one bit per operation here. AMD performance was quite alright compared to what I ended up with in the end, but NVIDIA performance was abysmal, so I went back to the drawing board, and ended up with the absolute simplest solution that would work.
Tightly packed bits
This idea is to just literally pack bits together, clearly a revolutionary idea that noone has ever done before. A VMEM load or two per thread, then some shifts should be all that is needed to move the components into place.
E.g. for index buffers:
uvec3 meshlet_decode_index_buffer(uint stream_index,
uint chunk_index,
int lane_index)
{
uint offset_in_words =
meshlet_streams.data[stream_index].offset_in_words;
return meshlet_decode3(offset_in_words, lane_index, 5);
}
For the actual decode I figured it would be pretty fast if all the shifts could be done in 64-bit. At least AMD has native instructions for that.
uvec3 meshlet_decode3(uint offset_in_words,
uint index,
uint bit_count)
{
const uint num_components = 3;
uint start_bit = index * bit_count * num_components;
uint start_word = offset_in_words + start_bit / 32u;
start_bit &= 31u;
uint word0 = payload.data[start_word];
uint word1 = payload.data[start_word + 1u];
uvec3 v;
uint64_t word = packUint2x32(uvec2(word0, word1));
v.x = uint(word >> start_bit);
start_bit += bit_count;
v.y = uint(word >> start_bit);
start_bit += bit_count;
v.z = uint(word >> start_bit);
return bitfieldExtract(v, 0, int(bit_count));
}
There is one detail here. For 13, 14 and 15 bit components with uvec3 decode, more than two u32 words may be needed, so in this case, encoder must choose 16 bit. (16-bit works due to alignment.) This only comes up in position encode, and encoder can easily just ensure 12 bit deltas is enough to encode, quantizing a bit more as necessary.
Mapping to MDI
Every 256-wide meshlet can turn into an indexed draw call with VK_INDEX_TYPE_UINT8_EXT, which is nice for saving VRAM. The “task shader” becomes a compute shader that dumps out a big multi-draw indirect buffer. The DrawIndex builtin in Vulkan ends up replacing WorkGroupID in mesh shader for pulling in per-meshlet data.
Performance sanity check
Before going further with mesh shading fun, it’s important to validate performance. I needed at least a ballpark idea of how many primitives could be pumped through the GPU with a good old vkCmdDrawIndexed and the MDI method where one draw call is one meshlet. This was then to be compared against a straight forward mesh shader.
Zeux’s Niagara renderer helpfully has a simple OBJ for us to play with.

When exported to the new meshlet format it looks like:
[INFO]: Stream 0: 54332 bytes. (Index) 15 bits / primitive [INFO]: Stream 1: 75060 bytes. (Position) ~25 bits / pos [INFO]: Stream 2: 70668 bytes. (Normal/Tangent) ~23.8 bits / N + T + sign [INFO]: Total encoded vertices: 23738 // Vertex duplication :( [INFO]: Average radius 0.037 (908 bounds) // 32-wide meshlet [INFO]: Average cutoff 0.253 (908 bounds) [INFO]: Average radius 0.114 (114 bounds) // 256-wide meshlet [INFO]: Average cutoff 0.697 (114 bounds) // Backface cone culling isn't amazing for larger meshlets. [INFO]: Exported meshlet: [INFO]: 908 meshlets [INFO]: 200060 payload bytes [INFO]: 86832 total indices [INFO]: 14856 total attributes [INFO]: 703872 uncompressed bytes
One annoying thing about meshlets is attribute duplication when one vertex is reused across meshlets, and using tiny 32-wide meshlets makes this way worse. Add padding on top for encode and the compression ratio isn’t that amazing anymore. The primitive to vertex ratio is ~1.95 here which is really solid, but turning things into meshlets tends to converge to ~1.0.
I tried different sublet sizes, but NVIDIA performance collapsed when I didn’t use 32-wide sublets, and going to 64 primitive / 32 vertex only marginally helped P/V ratios. AMD runtime performance did not like that in my testing (~30% throughput loss), so 32/32 it is!
After writing this section, AMD released a blog post suggesting that the 2N/N structure is actually good, but I couldn’t replicate that in my testing at least and I don’t have the energy anymore to rewrite everything (again) to test that.
Test scene
The classic “instance the same mesh a million times” strategy. This was tested on RTX 3070 (AMD numbers to follow, there are way more permutations to test there …). The mesh is instanced in a 13x13x13 grid. Here we’re throwing 63.59 million triangles at the GPU in one go.
Spam vkCmdDrawIndexed with no culling
5.5 ms

layout(location = 0) in vec3 POS;
layout(location = 1) in mediump vec3 NORMAL;
layout(location = 2) in mediump vec4 TANGENT;
layout(location = 3) in vec2 UV;
layout(location = 0) out mediump vec3 vNormal;
layout(location = 1) out mediump vec4 vTangent;
layout(location = 2) out vec2 vUV;
// The most basic vertex shader.
void main()
{
vec3 world_pos = (M * vec4(POS, 1.0)).xyz;
vNormal = mat3(M) * NORMAL;
vTangent = vec4(mat3(M) * TANGENT.xyz, TANGENT.w);
vUV = UV;
gl_Position = VP * vec4(world_pos, 1.0);
}
With per-object frustum culling
This is the most basic thing to do, so for reference.
4.3 ms

One massive MDI
Here we’re just doing basic frustum culling of meshlets as well as back-face cone culling and emitting one draw call per meshlet that passes test.
3.9 ms

Significantly more geometry is rejected now due to back-face cull and tighter frustum cull, but performance isn’t that much better. Once we start considering occlusion culling, this should turn into a major win over normal draw calls. In this path, we have a bit more indirection in the vertex shader, so that probably accounts for some loss as well.
void main()
{
// Need to index now, but shouldn't be a problem on desktop hardware.
mat4 M = transforms.data[draw_info.data[gl_DrawIDARB].node_offset];
vec3 world_pos = (M * vec4(POS, 1.0)).xyz;
vNormal = mat3(M) * NORMAL;
vTangent = vec4(mat3(M) * TANGENT.xyz, TANGENT.w);
vUV = UV;
// Need to pass down extra data to sample materials, etc.
// Fragment shader cannot read gl_DrawIDARB.
vMaterialID = draw_info.data[gl_DrawIDARB].material_index;
gl_Position = VP * vec4(world_pos, 1.0);
}
Meshlet – Encoded payload
Here, the meshlet will read directly from the encoded payload, and decode inline in the shader. No per-primitive culling is performed.
4.1 ms

Meshlet – Decoded payload
4.0 ms

We’re at the point where we are bound on fixed function throughput. Encoded and Decoded paths are basically both hitting the limit of how much data we can pump to the rasterizer.
Per-primitive culling
To actually make good use of mesh shading, we need to consider per-primitive culling. For this section, I’ll be assuming a subgroup size of 32, and a meshlet size of 32. There are other code paths for larger workgroups, which require some use of groupshared memory, but that’s not very exciting for this discussion.
The gist of this idea was implemented in https://gpuopen.com/geometryfx/. Various AMD drivers adopted the idea as well to perform magic driver culling, but the code here isn’t based on any other code in particular.
Doing back-face culling correctly
This is tricky, but we only need to be conservative, not exact. We can only reject when we know for sure the primitive is not visible.
Perspective divide and clip codes
The first step is to do W divide per vertex and study how that vertex clips against the X, Y, and W planes. We don’t really care about Z. Near-plane clip is covered by negative W tests, and far plane should be covered by simple frustum test, assuming we have a far plane at all.
vec2 c = clip_pos.xy / clip_pos.w;
uint clip_code = clip_pos.w <= 0.0 ? CLIP_CODE_NEGATIVE_W : 0;
if (any(greaterThan(abs(c), vec2(4.0))))
clip_code |= CLIP_CODE_INACCURATE;
if (c.x <= -1.0)
clip_code |= CLIP_CODE_NEGATIVE_X;
if (c.y <= -1.0)
clip_code |= CLIP_CODE_NEGATIVE_Y;
if (c.x >= 1.0)
clip_code |= CLIP_CODE_POSITIVE_X;
if (c.y >= 1.0)
clip_code |= CLIP_CODE_POSITIVE_Y;
vec2 window = roundEven(c * viewport.zw + viewport.xy);
There are things to unpack here. The INACCURATE clip code is used to denote a problem where we might start to run into accuracy issues when converting to fixed point, or GPUs might start doing clipping due to guard band exhaustion. I picked the value arbitrarily.
The window coordinate is then computed by simulating the fixed point window coordinate snapping done by real GPUs. Any GPU supporting DirectX will have a very precise way of doing this, so this should be okay in practice. Vulkan also exposes the number of sub-pixel bits in the viewport transform. On all GPUs I know of, this is 8. DirectX mandates exactly 8.
vec4 viewport =
float(1 << 8 /* shader assumes 8 */) *
vec4(cmd->get_viewport().x +
0.5f * cmd->get_viewport().width - 0.5f,
cmd->get_viewport().y +
0.5f * cmd->get_viewport().height - 0.5f,
0.5f * cmd->get_viewport().width,
0.5f * cmd->get_viewport().height) -
vec4(1.0f, 1.0f, 0.0f, 0.0f);
This particular way of doing it comes into play later when discussing micro-poly rejection. One thing to note here is that Vulkan clip-to-window coordinate transform does not flip Y-sign. D3D does however, so beware.
Shuffle clip codes and window coordinates
void meshlet_emit_primitive(uvec3 prim, vec4 clip_pos, vec4 viewport)
{
// ...
vec2 window = roundEven(c * viewport.zw + viewport.xy);
// vertex ID maps to gl_SubgroupInvocationID
// Fall back to groupshared as necessary
vec2 window_a = subgroupShuffle(window, prim.x);
vec2 window_b = subgroupShuffle(window, prim.y);
vec2 window_c = subgroupShuffle(window, prim.z);
uint code_a = subgroupShuffle(clip_code, prim.x);
uint code_b = subgroupShuffle(clip_code, prim.y);
uint code_c = subgroupShuffle(clip_code, prim.z);
}
Early reject or accept
Based on clip codes we can immediately accept or reject primitives.
uint or_code = code_a | code_b | code_c;
uint and_code = code_a & code_b & code_c;
bool culled_planes = (and_code & CLIP_CODE_PLANES) != 0;
bool is_active_prim = false;
if (!culled_planes)
{
is_active_prim =
(or_code & (CLIP_CODE_INACCURATE |
CLIP_CODE_NEGATIVE_W)) != 0;
if (!is_active_prim)
is_active_prim = cull_triangle(window_a,
window_b,
window_c);
}
- If all three vertices are outside one of the clip planes, reject immediately
- If any vertex is considered inaccurate, accept immediately
- If one or two of the vertices have negative W, we have clipping. Our math won’t work, so accept immediately. (If all three vertices have negative W, the first test rejects).
- Perform actual back-face cull.
Actual back-face cull
bool cull_triangle(vec2 a, vec2 b, vec2 c)
{
precise vec2 ab = b - a;
precise vec2 ac = c - a;
// This is 100% accurate as long as the primitive
// is no larger than ~4k subpixels, i.e. 16x16 pixels.
// Normally, we'd be able to do GEQ test, but GE test is conservative,
// even with FP error in play.
// Depending on your engine and API conventions, swap these two.
precise float pos_area = ab.y * ac.x;
precise float neg_area = ab.x * ac.y;
// If the pos value is (-2^24, +2^24),
// the FP math is exact,
// if not, we have to be conservative.
// Less-than check is there to ensure that 1.0 delta
// in neg_area *will* resolve to a different value.
bool active_primitive;
if (abs(pos_area) < 16777216.0)
active_primitive = pos_area > neg_area;
else
active_primitive = pos_area >= neg_area;
return active_primitive;
}
To compute winding, we need a 2D cross product. While noodling with this code, I noticed that we can still do it in FP32 instead of full 64-bit integer math. We’re working with integer-rounded values here, so based on the magnitudes involved we can pick the exact GEQ test. If we risk FP rounding error, we can use GE test. If the results don’t test equal, we know for sure area must be negative, otherwise, it’s possible it could have been positive, but the intermediate values rounded to same value in the end.
3.3 ms

Culling primitives helped as expected. Less pressure on the fixed function units.
Micro-poly rejection
Given how pathologically geometry dense this scene is, we expect that most primitives never trigger the rasterizer at all.
If we can prove that the bounding box of the primitive lands between two pixel grids, we can reject it since it will never have coverage.
if (active_primitive)
{
// Micropoly test.
const int SUBPIXEL_BITS = 8;
vec2 lo = floor(ldexp(min(min(a, b), c), ivec2(-SUBPIXEL_BITS)));
vec2 hi = floor(ldexp(max(max(a, b), c), ivec2(-SUBPIXEL_BITS)));
active_primitive = all(notEqual(lo, hi));
}
There is a lot to unpack in this code. If we re-examine the viewport transform:
vec4 viewport = float(1 << 8 /* shader assumes 8 */) *
vec4(cmd->get_viewport().x +
0.5f * cmd->get_viewport().width - 0.5f,
cmd->get_viewport().y +
0.5f * cmd->get_viewport().height - 0.5f,
0.5f * cmd->get_viewport().width,
0.5f * cmd->get_viewport().height) -
vec4(1.0f, 1.0f, 0.0f, 0.0f);
First, we need to shift by 0.5 pixels. The rasterization test happens at the center of a pixel, and it’s more convenient to sample at integer points. Then, due to top-left rasterization rules on all desktop GPUs (a DirectX requirement), we shift the result by one sub-pixel. This ensures that should a primitive have a bounding box of [1.0, 2.0], we will consider it for rasterization, but [1.0 + 1.0 / 256.0, 2.0] will not. Top-left rules are not technically guaranteed in Vulkan however (it just has to have some rule), so if you’re paranoid, increase the upper bound by one sub-pixel.
1.9 ms

Now we’re only submitting 1.2 M primitives to the rasterizer, which is pretty cool, given that we started with 31 M potential primitives. Of course, this is a contrived example with ridiculous micro-poly issues.
We’re actually at the point here where reporting the invocation stats (one atomic per workgroup) becomes a performance problem, so turning that off:
1.65 ms

With inline decoding there’s some extra overhead, but we’re still well ahead:
2.5 ms

Build active vertex / primitive masks
This is quite straight forward. Once we have the counts, SetMeshOutputCounts is called and we can compute the packed output indices with a mask and popcount.
uint vert_mask = 0u;
if (is_active_prim)
vert_mask = (1u << prim.x) | (1u << prim.y) | (1u << prim.z);
uvec4 prim_ballot = subgroupBallot(is_active_prim);
shared_active_prim_offset = subgroupBallotExclusiveBitCount(prim_ballot);
shared_active_vert_mask = subgroupOr(vert_mask);
shared_active_prim_count_total = subgroupBallotBitCount(prim_ballot);
shared_active_vert_count_total = bitCount(shared_active_vert_mask);
Special magic NVIDIA optimization
Can we improve things from here? On NVIDIA, yes. NVIDIA seems to under-dimension the shader export buffers in their hardware compared to peak triangle throughput, and their developer documentation on the topic suggests:
- Replace attributes with barycentrics and allowing the Pixel Shader to fetch and interpolate the attributes
Using VK_KHR_fragment_shader_barycentrics we can write code like:
// Mesh output
layout(location = 0) flat out uint vVertexID[];
layout(location = 1) perprimitiveEXT out uint vTransformIndex[];
// Fragment
layout(location = 0) pervertexEXT in uint vVertexID[];
layout(location = 1) perprimitiveEXT flat in uint vTransformIndex;
// Fetch vertex IDs
uint va = vVertexID[0];
uint vb = vVertexID[1];
uint vc = vVertexID[2];
// Load attributes from memory directly
uint na = attr.data[va].n;
uint nb = attr.data[vb].n;
uint nc = attr.data[vc].n;
// Interpolate by hand
mediump vec3 normal = gl_BaryCoordEXT.x * decode_rgb10a2(na) +
gl_BaryCoordEXT.y * decode_rgb10a2(nb) +
gl_BaryCoordEXT.z * decode_rgb10a2(nc);
// Have to transform normals and tangents as necessary.
// Need to pass down some way to load transforms.
normal = mat3(transforms.data[vTransformIndex]) * normal;
normal = normalize(normal);
1.0 ms

Quite the dramatic gain! Nsight Graphics suggests we’re finally SM bound at this point (> 80% utilization), where we used to be ISBE bound (primitive / varying allocation). An alternative that I assume would work just as well is to pass down a primitive ID to a G-buffer similar to Nanite.
There are a lot of caveats with this approach however, and I don’t think I will pursue it:
- Moves a ton of extra work to fragment stage
- I’m not aiming for Nanite-style micro-poly hell here, so doing work per-vertex seems better than per-fragment
- This result isn’t representative of a real scene where fragment shader load would be far more significant
- Incompatible with encoded meshlet scheme
- It is possible to decode individual values, but it sure is a lot of dependent memory loads to extract a single value
- Very awkward to write shader code like this at scale
- Probably need some kind of meta compiler that can generate code, but that’s a rabbit hole I’m not going down
- Need fallbacks, barycentrics is a very modern feature
- Makes skinning even more annoying
- Loading multiple matrices with fully dynamic index in fragment shader does not scream performance, then combine that with having to compute motion vectors on top …
- Only seems to help throughput on NVIDIA
- We’re already way ahead of MDI anyway
Either way, this result was useful to observe.
Steam Deck
Before running the numbers, we have to consider that the RADV driver already does some mesh shader optimizations for us automatically. The NGG geometry pipeline automatically converts vertex shading workloads into pseudo-meshlets, and RADV also does primitive culling in the driver-generated shader.
To get the raw baseline, we’ll first consider the tests without that path, so we can see how well RADV’s own culling is doing. The legacy vertex path is completely gone on RDNA3 as far as I know, so these tests have to be done on RDNA2.
No culling, plain vkCmdDrawIndexed, RADV_DEBUG=nongg
Even locked to 1600 MHz (peak), GPU is still just consuming 5.5 W. We’re 100% bound on fixed function logic here, the shader cores are sleeping.
44.3 ms

Basic frustum culling
As expected, performance scales as we cull. Still 5.5 W. 27.9 ms
NGG path, no primitive culling, RADV_DEBUG=nonggc
Not too much changed in performance here. We’re still bound on the same fixed function units pumping invisible primitives through. 28.4 ms
Actual RADV path
When we don’t cripple RADV, we get a lot of benefit from driver culling. GPU hits 12.1 W now. 9.6 ms
Slight win. 8.9 ms
Forcing Wave32 in mesh shaders
Using Vulkan 1.3’s subgroup size control feature, we can force RDNA2 to execute in Wave32 mode. This requires support in
VkShaderStageFlags requiredSubgroupSizeStages;
The Deck drivers and upstream Mesa ship support for requiredSize task/mesh shaders now which is very handy. AMD’s Windows drivers or AMDVLK/amdgpu-pro do not, however  It’s possible Wave32 isn’t the best idea for AMD mesh shaders in the first place, it’s just that the format favors Wave32, so I enable it if I can.
It’s possible Wave32 isn’t the best idea for AMD mesh shaders in the first place, it’s just that the format favors Wave32, so I enable it if I can.
Testing various parameters
While NVIDIA really likes 32/32 (anything else I tried fell off the perf cliff), AMD should in theory favor larger workgroups. However, it’s not that easy in practice, as I found.
Decoded meshlet – Wave32 – N/N prim/vert
- 32/32: 9.3 ms
- 64/64: 10.5 ms
- 128/128: 11.2 ms
- 256/256: 12.8 ms
These results are … surprising.
Encoded meshlet – Wave32 N/N prim/vert
- 32/32: 10.7 ms
- 64/64: 11.8 ms
- 128/128: 12.7 ms
- 256/256: 14.7 ms
Apparently Deck (or RDNA2 in general) likes small meshlets?
Wave64?
No meaningful difference in performance on Deck.
VertexID passthrough?
No meaningful difference either. This is a very NVIDIA-centric optimization I think.
A note on LocalInvocation output
In Vulkan, there are some properties that AMD sets for mesh shaders.
VkBool32 prefersLocalInvocationVertexOutput; VkBool32 prefersLocalInvocationPrimitiveOutput;
This means that we should write outputs using LocalInvocationIndex, which corresponds to how RDNA hardware works. Each thread can export one primitive and one vertex and the thread index corresponds to primitive index / vertex index. Due to culling and compaction, we will have to roundtrip through groupshared memory somehow to satisfy this.
For the encoded representation, I found that it’s actually faster to ignore this suggestion, but for the decoded representation, we can just send the vertex IDs through groupshared, and do split vertex / attribute shading. E.g.:
if (meshlet_lane_has_active_vert())
{
uint out_vert_index = meshlet_compacted_vertex_output();
uint vert_id = meshlet.vertex_offset + linear_index;
shared_clip_pos[out_vert_index] = clip_pos;
shared_attr_index[out_vert_index] = vert_id;
}
barrier();
if (gl_LocalInvocationIndex < shared_active_vert_count_total)
{
TexturedAttr a =
attr.data[shared_attr_index[gl_LocalInvocationIndex]];
mediump vec3 n = unpack_bgr10a2(a.n).xyz;
mediump vec4 t = unpack_bgr10a2(a.t);
gl_MeshVerticesEXT[gl_LocalInvocationIndex].gl_Position =
shared_clip_pos[gl_LocalInvocationIndex];
vUV[gl_LocalInvocationIndex] = a.uv;
vNormal[gl_LocalInvocationIndex] = mat3(M) * n;
vTangent[gl_LocalInvocationIndex] = vec4(mat3(M) * t.xyz, t.w);
}
Only computing visible attributes is a very common optimization in GPUs in general and RADV’s NGG implementation does it roughly like this.
Either way, we’re not actually beating the driver-based meshlet culling on Deck. It’s more or less already doing this work for us. Given how close the results are, it’s possible we’re still bound on something that’s not raw compute. On the positive side, the cost of using encoded representation is very small here, and saving RAM for meshes is always nice.
Already, the permutation hell is starting to become a problem. It’s getting quite obvious why mesh shaders haven’t taken off yet 
RX 7600 numbers
Data dump section incoming …
NGG culling seems obsolete now?
By default RADV disables NGG culling on RDNA3, because apparently it has a much stronger fixed function culling in hardware now. I tried forcing it on with RADV_DEBUG=nggc, but found no uplift in performance for normal vertex shaders. Curious. Here’s with no culling, where the shader is completely export bound.

But, force NGG on, and it still doesn’t help much. Culling path takes as much time as the other, the instruction latencies are just spread around more.

- vkCmdDrawIndexed, no frustum culling: 5.9 ms
- With frustum cull: 3.7 ms
- MDI: 5.0 ms
Wave32 – Meshlet
- Encoded – 32/32: 3.3 ms
- Encoded – 64/64 : 2.5 ms
- Encoded – 128/128: 2.7 ms
- Encoded – 256/256: 2.9 ms
- Decoded – 32/32: 3.3 ms
- Decoded – 64/64: 2.4 ms
- Decoded – 128/128: 2.6 ms
- Decoded – 256/256: 2.7 ms
Wave64 – Meshlet
- Encoded – 64/64: 2.4 ms
- Encoded – 128/128: 2.6 ms
- Encoded – 256/256: 2.7 ms
- Decoded – 64/64: 2.2 ms
- Decoded – 128/128: 2.5 ms
- Decoded – 256/256: 2.7 ms
Wave64 mode is doing quite well here. From what I understand, RADV hasn’t fully taken advantage of the dual-issue instructions in RDNA3 specifically yet, which is important for Wave32 performance, so that might be a plausible explanation.
There was also no meaningful difference in doing VertexID passthrough.
It’s not exactly easy to deduce anything meaningful out of these numbers, other than 32/32 being bad on RDNA3, while good on RDNA2 (Deck)?
AMD doesn’t seem to like the smaller 256 primitive draws on the larger desktop GPUs. I tried 512 and 1024 as a quick test and that improved throughput considerably, still, with finer grained culling in place, it should be a significant win.
amdgpu-pro / proprietary (Linux)
Since we cannot request specific subgroup size, the driver is free to pick Wave32 or Wave64 as it pleases, so I cannot test the difference. It won’t hit the subgroup optimized paths however.
- vkCmdDrawIndexed, no culling : 6.2 ms
- With frustum cull: 4.0 ms
- MDI: 5.3 ms
- Meshlet – Encoded – 32/32: 2.5 ms
- Meshlet – Encoded – 64/64 : 2.6 ms
- Meshlet – Encoded – 128/128: 2.7 ms
- Meshlet – Encoded – 256/256: 2.6 ms
- Meshlet – Decoded – 32/32: 2.1 ms
- Meshlet – Decoded – 64/64: 2.1 ms
- Meshlet – Decoded – 128/128: 2.1 ms
- Meshlet – Decoded – 256/256: 2.1 ms
I also did some quick spot checks on AMDVLK, and the numbers are very similar.
The proprietary driver is doing quite well here in mesh shaders. On desktop, we can get significant wins on both RADV and proprietary with mesh shaders, which is nice to see.
It seems like the AMD Windows driver skipped NGG culling on RDNA3 as well. Performance is basically the same.

Task shader woes
The job of task shaders is to generate mesh shader work on the fly. In principle this is nicer than indirect rendering with mesh shaders for two reasons:
- No need to allocate temporary memory to hold for indirect draw
- No need to add extra compute passes with barriers
However, it turns out that this shader stage is even more vendor specific when it comes to tuning for performance. So far, no game I know of has actually shipped with task shaders (or the D3D12 equivalent amplification shader), and I think I now understand why.
The basic task unit I settled on was:
struct TaskInfo
{
uint32_t aabb_instance; // AABB, for top-level culling
uint32_t node_instance; // Affine transform
uint32_t material_index; // To be eventually forwarded to fragment
uint32_t mesh_index_count;
// Encodes count [1, 32] in lower bits.
// Mesh index is aligned to 32.
uint32_t occluder_state_offset;
// For two-phase occlusion state (for later)
};
An array of these is prepared on CPU. Each scene entity translates to one or more TaskInfos. Those are batched up into one big buffer, and off we go.
The logical task shader for me was to have N = 32 threads which tests AABB of N tasks in parallel. For the tasks that pass the test, test 32 meshlets in parallel. This makes it so the task workgroup can emit up to 1024 meshlets.
When I tried this on NVIDIA however …
18.8 ms

10x slowdown … The NVIDIA docs do mention that large outputs are bad, but I didn’t expect it to be this bad:
Avoid large outputs from the amplification shader, as this can incur a significant performance penalty. Generally, we encourage a flexible implementation that allows for fine-tuning. With that in mind, there are a number of generic factors that impact performance:
-
Size of the payloads. The AS payload should preferably stay below 108 bytes, but if that is not possible, then keep it at least under 236 bytes.
If we remove all support for hierarchical culling, the task shader runs alright again. 1 thread emits 0 or 1 meshlet. However, this means a lot of threads dedicated to culling, but it’s similar in performance to plain indirect mesh shading.

AMD however, is a completely different story. Task shaders are implemented by essentially emitting a bunch of tiny indirect mesh shader dispatches anyway, so the usefulness of task shaders on AMD is questionable from a performance point of view. While writing this blog, AMD released a new blog on the topic, how convenient!
When I tried NV-style task shader on AMD, performance suffered quite a lot.
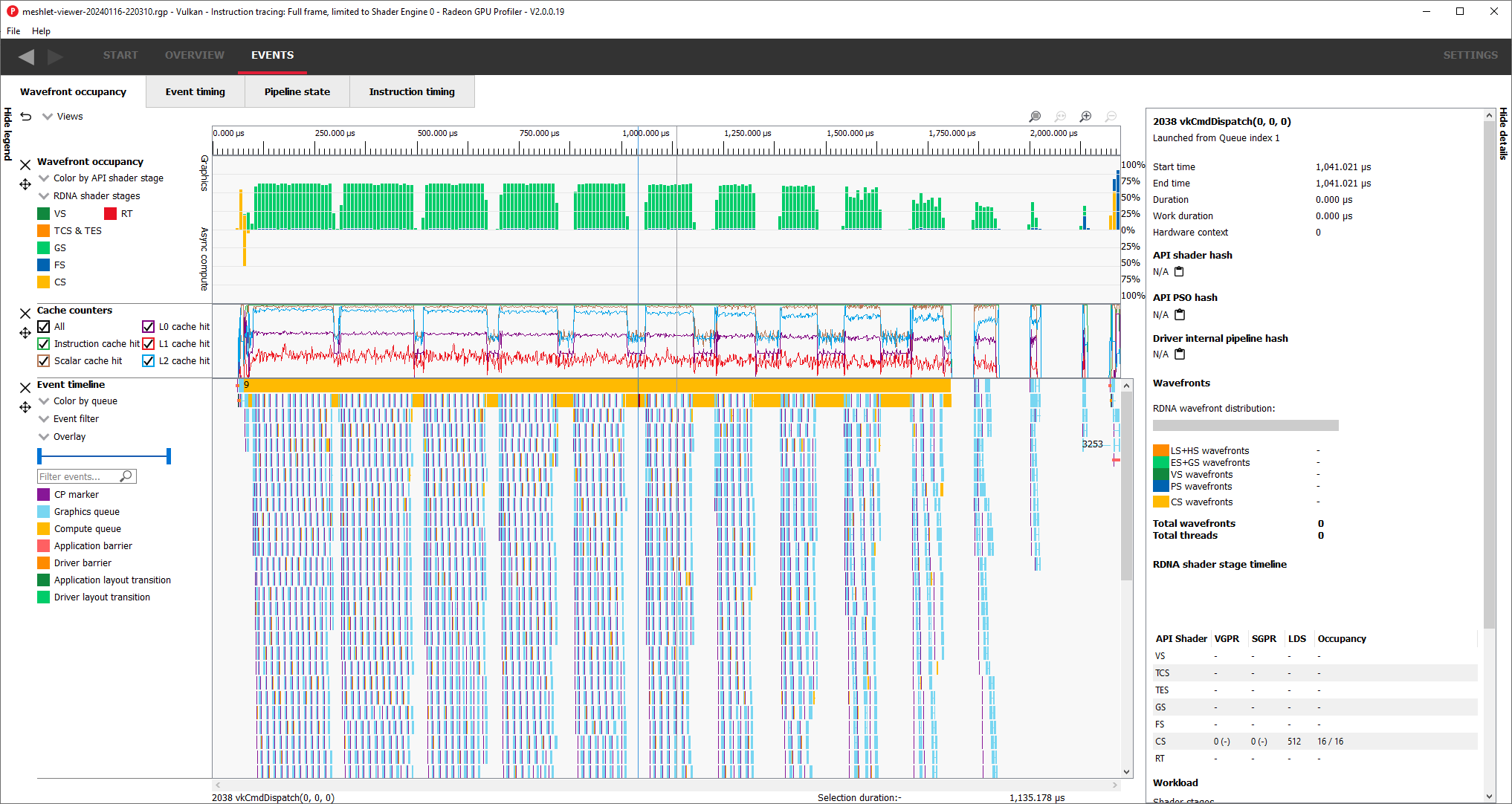
However, the only thing that gets us to max perf on both AMD and NV is to forget about task shaders and go with vkCmdDrawMeshTasksIndirectCountEXT instead. While the optimal task shader path for each vendor gets close to indirect mesh shading, having a universal fast path is good for my sanity. The task shader loss was about 10% for me even in ideal situations on both vendors, which isn’t great. As rejection ratios increase, this loss grows even more. This kind of occupancy looks way better

The reason for using multi-indirect-count is to deal with the limitation that we can only submit about 64k workgroups in any dimension, similar to compute. This makes 1D atomic increments awkward, since we’ll easily blow past the 64k limit. One alternative is to take another tiny compute pass that prepares a multi-indirect draw, but that’s not really needed. Compute shader code like this works too:
// global_offset = atomicAdd() in thread 0
if (gl_LocalInvocationIndex == 0 && draw_count != 0)
{
uint max_global_offset = global_offset + draw_count - 1;
// Meshlet style.
// Only guaranteed to get 0xffff meshlets,
// so use 32k as cutoff for easy math.
// Allocate the 2D draws in-place, avoiding an extra barrier.
uint multi_draw_index = max_global_offset / 0x8000u;
uint local_draw_index = max_global_offset & 0x7fffu;
const int INC_OFFSET = NUM_CHUNK_WORKGROUPS == 1 ? 0 : 1;
atomicMax(output_draws.count[1], multi_draw_index + 1);
atomicMax(output_draws.count[
2 + 3 * multi_draw_index + INC_OFFSET],
local_draw_index + 1);
if (local_draw_index <= draw_count)
{
// This is the thread that takes us over the threshold.
output_draws.count[
2 + 3 * multi_draw_index + 1 - INC_OFFSET] =
NUM_CHUNK_WORKGROUPS;
output_draws.count[2 + 3 * multi_draw_index + 2] = 1;
}
// Wrapped around, make sure last bucket sees 32k meshlets.
if (multi_draw_index != 0 && local_draw_index < draw_count)
{
atomicMax(output_draws.count[
2 + 3 * (multi_draw_index - 1) +
INC_OFFSET], 0x8000u);
}
}
This prepares a bunch of (8, 32k, 1) dispatches that are processed in one go. No chance to observe a bunch of dead dispatches back-to-back like task shaders can cause. In the mesh shader, we can use DrawIndex to offset the WorkGroupID by the appropriate amount (yay, Vulkan). A dispatchX count of 8 is to shade the full 256-wide meshlet through 8x 32-wide workgroups. As the workgroup size increases to handle more sublets per group, dispatchX count decreases similarly.
Occlusion culling
To complete the meshlet renderer, we need to consider occlusion culling. The go-to technique for this these days is two-phase occlusion culling with HiZ depth buffer. Some references:
Basic gist is to keep track of which meshlets are considered visible. This requires persistent storage of 1 bit per unit of visibility. Each pass in the renderer needs to keep track of its own bit-array. E.g. shadow passes have different visibility compared to main scene rendering.
For Granite, I went with an approach where 1 TaskInfo points to one uint32_t bitmask. Each of the 32 meshlets within the TaskInfo gets 1 bit. This makes the hierarchical culling nice too, since we can just test for visibility != 0 on the entire word. Nifty!
First phase
Here we render all objects which were considered visible last frame. It’s extremely likely that whatever was visible last frame is visible this frame, unless there was a full camera cut or similar. It’s important that we’re actually rendering to the framebuffer now. In theory, we’d be done rendering now if there were no changes to camera or objects in the scene.
HiZ pass
Based on the objects we drew in phase 1, build a HiZ depth map. This topic is actually kinda tricky. Building the mip-chain in one pass is great for performance, but causes some problems. With NPOT textures and single pass, there is no obvious way to create a functional HiZ, and the go-to shader for this, FidelityFX SPD, doesn’t support that use case.
The problem is that the size of mip-maps round down, so if we have a 7×7 texture, LOD 1 is 3×3 and LOD 2 is 1×1. In LOD2, we will be able to query a 4×4 depth region, but the edge pixels are forgotten.
The “obvious” workaround is to pad the texture to POT, but that is a horrible waste of VRAM. The solution I went with instead was to fold in the neighbors as the mips are reduced. This makes it so that the edge pixels in each LOD also remembers depth information for pixels which were truncated away due to NPOT rounding.
I rolled a custom HiZ shader similar to SPD with some extra subgroup shenanigans because why not (SubgroupShuffleXor with 4 and 8).
Second phase
In this pass we submit for rendering any object which became visible this frame, i.e. the visibility bit was not set, but it passed occlusion test now. Again, if camera did not change, and objects did not move, then nothing should be rendered here.
However, we still have to test every object, in order to update the visibility buffer for next frame. We don’t want visibility to remain sticky, unless we have dedicated proxy geometry to serve as occluders (might still be a thing if game needs to handle camera cuts without large jumps in rendering time).
In this pass we can cull meshlet bounds against the HiZ.
Because I cannot be arsed to make a fancy SVG for this, the math to compute a tight AABB bound for a sphere is straight forward once the geometry is understood.

The gist is to figure out the angle, then rotate the (X, W) vector with positive and negative angles. X / W becomes the projected lower or upper bound. Y bounds are computed separately.
vec2 project_sphere_flat(float view_xy, float view_z, float radius)
{
float len = length(vec2(view_xy, view_z));
float sin_xy = radius / len;
float cos_xy = sqrt(1.0 - sin_xy * sin_xy);
vec2 rot_lo = mat2(cos_xy, sin_xy, -sin_xy, cos_xy) *
vec2(view_xy, view_z);
vec2 rot_hi = mat2(cos_xy, -sin_xy, +sin_xy, cos_xy) *
vec2(view_xy, view_z);
return vec2(rot_lo.x / rot_lo.y, rot_hi.x / rot_hi.y);
}
The math is done in view space where the sphere is still a sphere, which is then scaled to window coordinates afterwards. To make the math easier to work with, I use a modified view space in this code where +Y is down and +Z is in view direction.
bool hiz_cull(vec2 view_range_x, vec2 view_range_y, float closest_z) // view_range_x: .x -> lower bound, .y -> upper bound // view_range_y: same // closest_z: linear depth. ViewZ - Radius for a sphere
First, convert to integer coordinates.
// Viewport scale first applies any projection scale in X/Y // (without Y flip). // The scale also does viewport size / 2 and then // offsets into integer window coordinates. vec2 range_x = view_range_x * frustum.viewport_scale_bias.x + frustum.viewport_scale_bias.z; vec2 range_y = view_range_y * frustum.viewport_scale_bias.y + frustum.viewport_scale_bias.w; ivec2 ix = ivec2(range_x); ivec2 iy = ivec2(range_y); ix.x = clamp(ix.x, 0, frustum.hiz_resolution.x - 1); ix.y = clamp(ix.y, ix.x, frustum.hiz_resolution.x - 1); iy.x = clamp(iy.x, 0, frustum.hiz_resolution.y - 1); iy.y = clamp(iy.y, iy.x, frustum.hiz_resolution.y - 1);
Figure out a LOD where we only have to sample a 2×2 footprint. findMSB to the rescue.
int max_delta = max(ix.y - ix.x, iy.y - iy.x); int lod = min(findMSB(max_delta - 1) + 1, frustum.hiz_max_lod); ivec2 lod_max_coord = max(frustum.hiz_resolution >> lod, ivec2(1)) - 1; // Clamp to size of the actual LOD. ix = min(ix >> lod, lod_max_coord.xx); iy = min(iy >> lod, lod_max_coord.yy);
And finally, sample:
ivec2 hiz_coord = ivec2(ix.x, iy.x);
float d = texelFetch(uHiZDepth, hiz_coord, lod).x;
bool nx = ix.y != ix.x;
bool ny = iy.y != iy.x;
if (nx)
d = max(d, texelFetchOffset(uHiZDepth,
hiz_coord, lod,
ivec2(1, 0)).x);
if (ny)
d = max(d, texelFetchOffset(uHiZDepth,
hiz_coord, lod,
ivec2(0, 1)).x);
if (nx && ny)
d = max(d, texelFetchOffset(uHiZDepth,
hiz_coord, lod,
ivec2(1, 1)).x);
return closest_z < d;
Trying to get up-close, it’s quite effective.
Without culling:

With two-phase:

As the culling becomes more extreme, GPU go brrrrr. Mostly just bound on HiZ pass and culling passes now which can probably be tuned a lot more.

Conclusion
I’ve spent way too much time on this now, and I just need to stop endlessly tuning various parameters. This is the true curse of mesh shaders, there’s always something to tweak. Given the performance I’m getting, I can call this a success, even if there might be some wins left on the table by tweaking some more. Now I just need to take a long break from mesh shaders before I actually rewrite the renderer to use this new code … And maybe one day I can even think about how to deal with LODs, then I would truly have Nanite at home!
The “compression” format ended up being something that can barely be called a compression format. To chase decode performance of tens of billions of primitives per second through, I suppose that’s just how it is.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK