

对话联汇科技赵天成:被动智能正走向主动智能,一切都将被颠覆
source link: https://www.geekpark.net/news/329162
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
对话联汇科技赵天成:被动智能正走向主动智能,一切都将被颠覆

智能体将成为全新物种,广泛而深刻地影响人类。
作者 | 北方
编辑 | 靖宇
历史上从来没有哪一个时刻,比 2023 年更紧密地将 AI 与人类未来联系在一起。
仅仅刚刚过去的几个月,AI 行业就上演了 OpenAI 开发者大会、Humane 推出 AI Pin、微软 Ignite 大会、xAI 发布 Grok、OpenAI「宫斗剧」等行业大事件,不仅一次次引发 AI 圈密集讨论,也让更多人开始密切关注 AI 商业化与自身的未来发展。
作为「大模型元年」,AI 大模型的落地也出现不同走向。面向 C 端,以 OpenAI 为代表,将 GPT Store、人人可定制的 GPT 等切入人类生活变成新的主题;而在 B 端,「技术如何落地」「应用的可能性」这类更实际的问题,从没有如此频繁地出现在创业者的话语中。
卡耐基梅隆大学(CMU)「学霸」、联汇科技首席科学家赵天成,现在还记得当年在大学攻读博士时,看到谷歌的 AlphaGO 战胜人类顶尖围棋选手带给自己的震撼。当时已经看清传统「列规则」式的 AI 开发方式的弊端,转而研究「AI 智能体」的他,选择了一条「前 GPT 模式」的 AI 之路,早在几年之前,已经预判大模型才是 AI 快速进化的正确路径。
回国加盟联汇科技后,赵天成和团队就开始打磨基础模型,将重心放在了多模态大模型领域,并在 2021 年就推出了首个自研的多模态大模型,与当下创业者仍在疲于「卷」文字大模型形成鲜明对比。
技术上的创新和务实的产品开发,让联汇科技利用多模态大模型的超强能力,先后获得广电、运营商、国家电网等多个领域的 B 端客户,成为大模型创业者中少见的功落地者。
在商业路径上,赵天成看到当年「AI 四小龙」当下的窘境,认识到「小模型定制死路一条」的真理,坚持联汇科技在大模型领域的不断研发和创新。
对于当下的「百模大战」,赵天成认为单纯的「卷参数」,尝试复现 ChatGPT 的能力,对很多创业公司来说,可能并不是唯一正确的打法。而已经在 B 端积累了相当经验的他,认为大模型并不止 LLM 一种形式,相比而言,多模态大模型能落地的场景更多。
「GPT 只是大模型的一个路径,但 OpenAI 的方法论可以在更多场景中做尝试。」赵天成告诉极客公园。在他看来,在 AI 的 B 端落地上,竞争并非是「百团大战」,而更像「丛林狩猎」,最终能获得猎物的,并非一定是大公司。
以下为联汇科技首席科学家赵天成采访实录,由极客公园整理:
01 传统 AI 研究有上限,要做没人敢做的事情
极客公园:你之前在加州大学攻读计算机专业,为什么后来又去了 CMU 进行语言技术方面的研究?
赵天成:我在 UCLA 电子工程系加计算机双修,差不多三年时间就修完本科专业课程,第四年主要攻读了一系列研究生课程,并且在 UCLA 语音技术实验室做语音处理相关研究,开始接触到人工智能和机器学习等前沿课题,激发了我很大的兴趣。
选择去 CMU 攻读计算机博士学位,是因为 CMU 在 AI 领域全球排名第一,去那里是所有 AI 研究人员的梦想。而去 CMU 计算机学院的 LTI(语言技术研究所)是因为接触到语音处理技术之后,我感觉到这项技术,已经开始慢慢从学术界往工业界转移了,它本身的技术部分相对来说已经比较成熟了,我想去做更前沿的基础人工智能理论研究工业工程化相关的研究。
我当时判断既然语音识别作为语音感知层已经相对成熟,那后续的行业趋势肯定会做更深度的认知智能,比如理解语义,智能对话,甚至具有超出语言本身之外的推理与决策能力。CMU 的 LTI 是这个领域全球最好的研究机构,那里的科学家研发了全球最早的语音识别引擎、机器翻译系统、人机对话系统等等,我相信在那里可以诞生出未来新一代的突破性人工智能技术。
极客公园:2014 年你选择去做语音和语言研究的时候,当时的学术界是什么状态?
赵天成:NLP(自然语言处理)领域那时属于一个交接期。当时有一批人在做偏规则型研究,也有人在做偏机器学习型的研究,或者把机器学习和规则进行结合。
在 2016 年,我发表了业内最早的一篇端到端人机对话论文,讲如何用神经网络解决整个对话系统的问题。当时通常的做法是多个规则模块的拼接,而用一个神经网络来完成全部的对话还是很前沿的想法,和现在的 ChatGPT 很像。这个工作也提名了当年 SIGDIAL 最佳论文奖。
我当时提出的就是,应该用一个神经网络进行端到端的学习来实现智能对话,而不是用很多 AI 规则模块来做人机交互系统。
极客公园:这种灵感来源是什么?
赵天成:当时我分析了传统的对话系统,发现通过人工建立规则或者人工建立专家系统,虽然能在短期内对系统的能力会有一些提升,但这个提升是不可持续的,因为我们不可能穷举所有的对话场景,因此从长远看,要实现大的 AI 飞跃,正确的路线应该是减少人工干预,依靠更强的算力,让机器能更好地进行自学习来达到智能的提升。而不能陷入有多少「人工」,才有多少「智能」的怪圈,那样做只能让「人工智能」变成「人工智障」。
但是要实现机器自我学习,这个过程中有很多挑战,因为一个人机交互系统会有很多复杂模块,需要做自然语言理解,把它解释成实体,在对话层面又要去做很多逻辑以及规划,这些都要通过一个神经网络去解决。
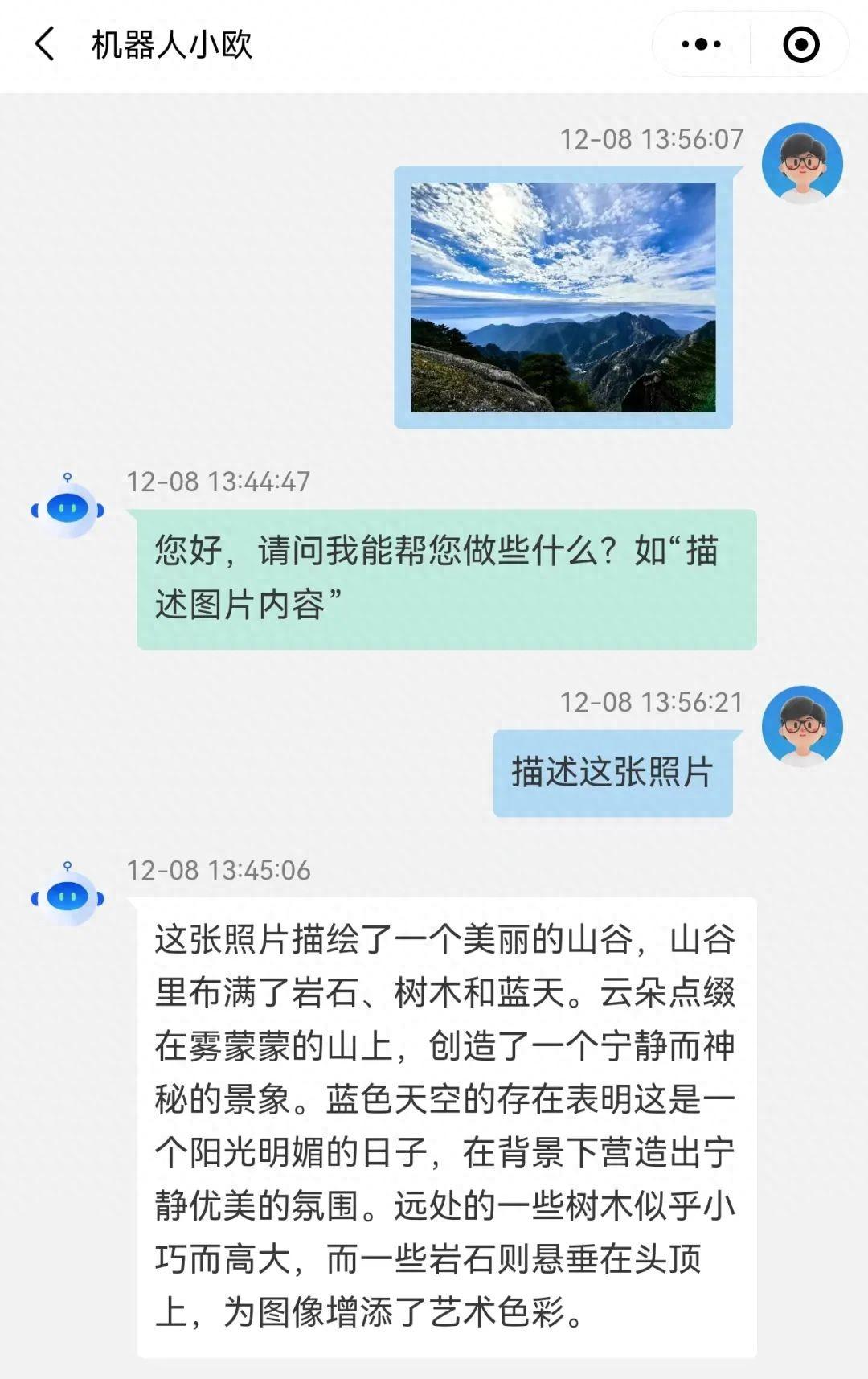
机器人小欧对画面深度理解 | 小程序搜索「机器人小欧」体验
但当时业界没有现在这么多的工具,在做的过程中,我们考虑的是从怎样的点入手,把最基本的闭环走通,然后以它为基础再去做扩展。这是我当时觉得比较容易实现、成为真正智能的 AI 的方向和路径。
极客公园:你在 CMU 读博期间,业内还没有大模型这个概念出现?
赵天成:当时还没有大模型这个概念,甚至连生成式模型都是少见的概念。
在硕博期间,我做了两件事情。我在硕士期间承接了一个美国科研自然基金 NSF 的项目,当时还没有智能音箱,我提出做一个智能体,其智能大脑可以融合各种各样的单任务智能体能力,可能是订餐,也可能是推荐地图,通过一个统一的智能体和用户交流。这在当时还是很前沿的课题,类似于现在 ChatGPT 的插件系统。我和团队在 2014 -2016 年从 0 到 1 把整个平台做出来,作为基础科研平台,支撑了后续超过 100 多篇科研论文的发表。这个成果得到了亚马逊、谷歌等多位人工智能专家的充分肯定。
做这个智能体的过程中,我发现靠传统的方式去做智能体其实能力上限很低。这启发我在博士课题中去做端到端的生成式模型,我认为只有这样才能真正从根本上解决这个问题。所以从 2016 年之后,我基本上所有的论文都是围绕怎样去做更好的生成式模型,把数据「注入」进去之后,它就可以完成更复杂的任务。
极客公园:当时做的就已经是大模型,只是没有像现在这种几百亿参数这么大?
赵天成:对,只是在规模上不一样,在核心算法这一块非常接近,几乎没有差别。比如当时我训练的是 1 亿参数的模型,现在可能是 100 亿参数或者 1000 亿参数的模型。
极客公园: 2016 年 AlphaGo 出现了,当时也引起了非常大的反响,你当时有什么感受?
赵天成:当时触动很大。因为我当时做的就是生成式模型过程中最大的两个技术栈:偏神经网络的设计、训练和强化学习。
当时 AlphaGo 是强化学习一个很好的应用场景和成果。所以我们也考虑怎样让这种能力应用在现实场景中,因为 AlphaGo 本身的规则是固定的。但实际上我们在跟人机交互、自然语言、图像打交道的时候有无限的可能性,难度远远超出下围棋这个任务。所以我们花了很多精力去研究,怎样将 AlphaGo 级别的端到端的机器学习应用在更广领域,在 2018 年我们就提出了通过基于隐变量的强化学习,让智能体学会从人类反馈中获得更好的人机交互策略,大幅度提高任务完成的成功率,达到了当时的 SOTA 性能。
极客公园:在 2019 年和 2020 年左右,国内 AI 行业尚处于波谷期,为什么会选择回国创业做 AI?
赵天成:因为我发现不管什么模型、什么技术,都需要有一些匹配的应用场景,去实现它的迭代和本身价值的体现。当时我们和国内有很多交流,发现其实国内不管是视频还是多媒体,有很多应用场景在美国可能很少见,国内反而机会更多。
一方面,国内做 AI 会有更大的应用空间,有更多的机会。另一方面,回国也是我的个人选择,我个人还是比较有家国情怀的一个人,在美国留学这么多年,我希望能把时间与精力放在建设自己的国家,综合决定之后,我选择回国实现我的理想。
02 做小模型定制,是死路一条
极客公园:当时国内 AI 行业处于什么状态,联汇科技如何选择切入市场的角度?
赵天成:当时国内大模型几乎是未开启状态。很多大厂,包括华为、百度等也训练过一些模型,但当时大家还没有发现什么实际的价值。
我回来后分析了国内 AI 行业的痛点。当时很多行业都在做 AI,比如零售 AI、客服 AI 等,这些基本上都是用传统的小模型方式在做的,定制化程度极高,而对小模型定制来说,他的瓶颈在于每个模型不能泛用,每个场景都要从头做起,无法沉淀积累,使得定制成本很高。这就导致了当时做 AI 商业化落地成为一件很累、很亏钱的事情。
经过研究分析,我们发现虽然市场有很多中长尾应用场景,但功能要求非常分散,这种情况和我们之前做智能体平台差不多。如果用小模型方式去做的话,很难走远。所以我觉得我们既然要做,就要去做有「未来」的东西,摒弃小模型的思路,专心于大模型。而且我们根据学术界的研究成果,判断大模型的行业爆发不会太远。
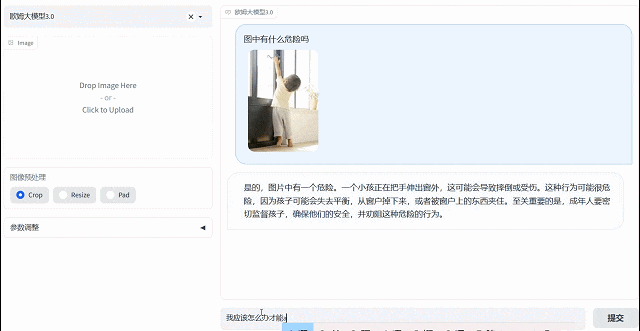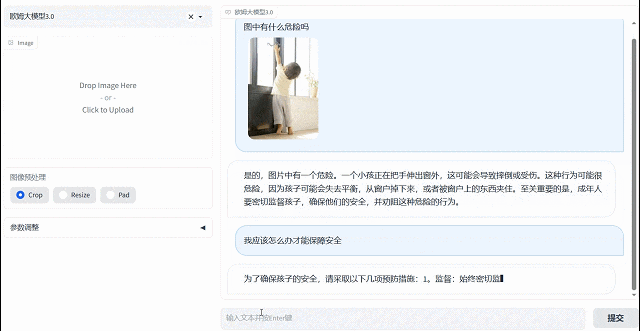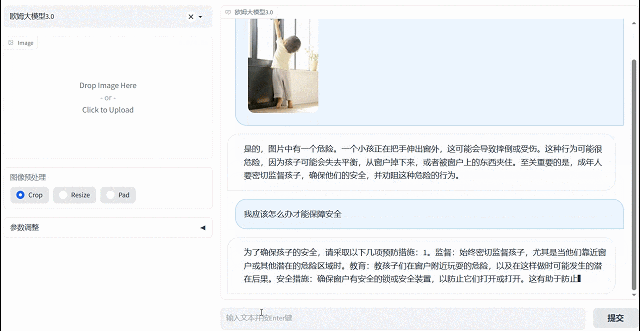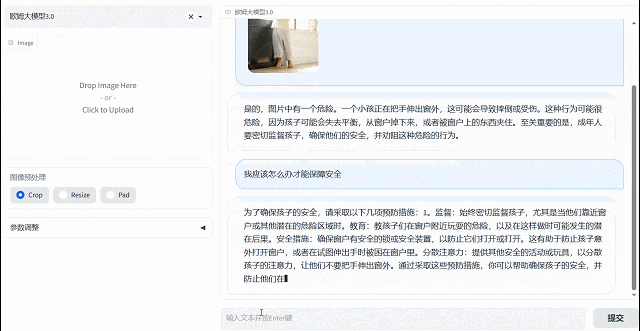
欧姆视觉语言大模型拥有主动思考分析能力
极客公园:当时你怎样让客户认识到这种技术案例的先进性?说服对方在这个方向投入?
赵天成:非常困难。当时还没有大模型的概念,我们尝试了很多方法去做科普,但几乎没人听得懂。我们就尝试通过和其他产品 PK 来说明我们的路线优势,因为大模型和小模型一对比就能看到效果。比如在介绍跨模态搜索能力时,我们就和对方说以前的搜索都是需要打标签的,但我们的搜索只要通过自然语言说一句话,就能把东西搜出来,我们不用标签,或者说我们是「无限标签」。
这种概念其实很多客户也还是不理解,我们只能用更具象的方式去介绍。比如虽然我们是无限标签,但有时候不得不说我们有几万个标签,因为这样能给他们一个具象的概念。这些都是我们在尝试落地时碰到的困难。
极客公园:有没有给你印象很深的客户,你展示前他并不相信这些,展示后他被震惊到了?
赵天成:比如某广电集团,他们也是我们比较大的一个客户。他们有很多视频媒体资料,比如新闻播报类节目等,以前一年要花几百万进行人工编目、打标签,来实现资产管理和检索。当时我们说可以通过机器学习,自动生成无限标签,可以实现任意检索,对方不太相信,我们就给他们做测试系统,让客户自己去验证。然后我们再从技术底层去讲解这个原理。经过几次使用和讲解之后,他们内部一些专业的技术专家也认识到这个技术路线的先进性,后续合作就比较顺畅了。
极客公园:这样的一个商业化方向是团队经过很长时间碰出来的吗?还是说你早就已经想到了场景和方向,只是根据客户不同来去提供支持?
赵天成:虽然我们当时认为大模型一定是一个方向,而且我们也一直在致力于提高大模型的基础能力,但在商业化方向上,还是通过不断的市场探索,慢慢摸出来的。在寻找具体应用场景时,我们当时尝试了很多行业,也碰过很多壁。最终发现,最终我们聚焦在媒体视觉和 IoT 视觉这两大应用场景。
极客公园:从回国到成功落地这样的大客户,大概花了多长时间?
赵天成:差不多一年多时间。虽然在技术方面,我们之前在美国已经有了一些积淀,并不是回来之后从零开始做起。但在真正落地应用时,还是有很多需要改进。实际上要真正做到应用落地,需要大模型能力提升、工具链开发、应用场景确定、应用闭环开发以及商业模式确定等一系列因素结合起来才能实现,并不仅仅是技术问题。
极客公园:你回国的时候,国内「AI 四小龙」很受关注,经过这些年,从这些公司的起伏中能学到什么经验?
赵天成:我认为这些公司都很优秀,他们在小模型应用落地方面,做了很多尝试,在高频领域也有很多成功案例,但在中长尾领域都不太顺利。这也反过来验证了我的判断——如果用小模型方式去服务中长尾场景,貌似是死路一条。
这样的判断,更加坚定了我们做大模型的决心。我们看到只要把大模型的商业道路走通的话,将具有巨大的市场价值。
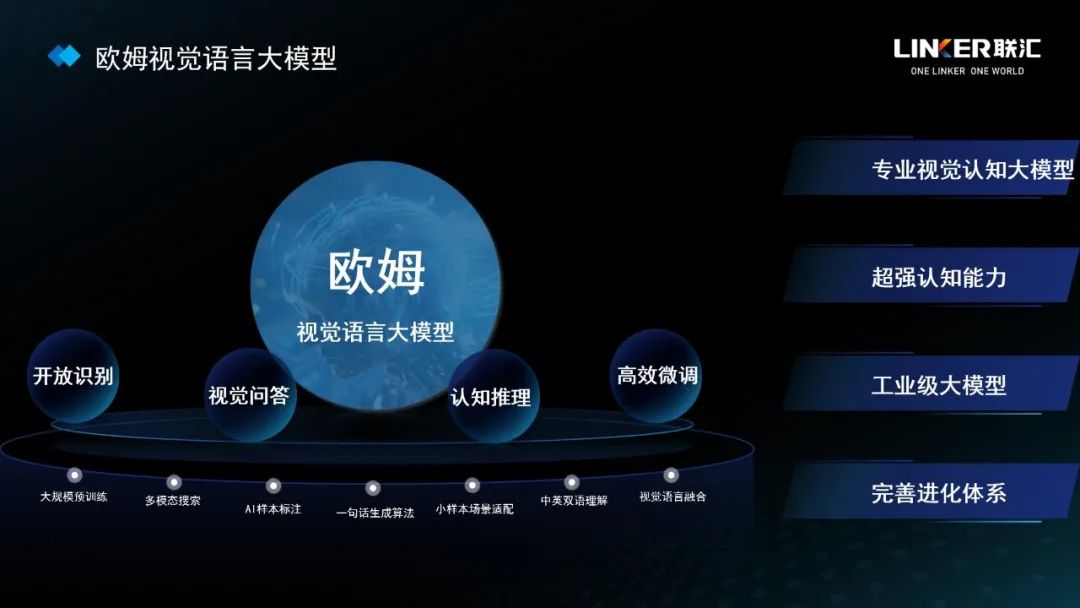
欧姆视觉语言大模型拥有四大核心能力
03 被动智能正走向主动智能,一切都将被颠覆
极客公园:在 ChatGPT 出来之前,你已经预判到大模型技术的行业趋势,在这些年里,你对大模型的理解有什么变化?
赵天成:我是从 2016 年左右开始专注于端到端的生成式模型训练,其核心思想和如今的大模型训练如出一辙,也就是首先构建一个上限极高的神经网络模型,然后通过对大量的无监督数据进行自回归学习,实现原本需要 N 个专家系统模块组合而成的复合能力。在这些年里,对于大模型学习的最大变化在于对于这种学习方式能达到的上限与发展速度一次次地刷新了我的预期,也让我更加坚定这种方法论的正确性。
早年的时候,端到端模型能够实现 AI 对于自然语言的流畅生成,到后面能够根据用户的问题给出流畅的答复就已经是非常了不起的成果了。然而现在 GPT-4 可以不但进行流畅的语言生成与问题回复,还可以主动地选择不同的工具,并且产生思维与推理链条,这个在当时是不太敢想的。当时这个过程只能靠人工去定义,不可能靠 AI 自己做出来。
现在不管多模态大模型还是大语言模型,已经逐步具备自己去产生整个推理链路或者决策链路的能力,我觉得这个是颠覆性的变化,也让现在的 AI Agent 开始具备了主动思考与决策的能力。

联汇科技智能管家机器人看护老人
极客公园:所以这些年的改变,让 AI 有可能实现大范围的商业化?
赵天成:对,这些年最大的变化是从以前的被动智能——用户问一个问题,AI 回答一个问题,到现在的主动智能——用户问一个问题,AI 除了回答他的直接问题,还会主动联想到其他问题。甚至用户不用提问,AI 自己根据它的观察,就能主动发现问题并给出解决问题的建议。
比如在零售场景下面,AI 通过视频分析发现超市里的咖啡打翻了,它会自己联想到需要做清理,或者通知谁去打扫卫生。这样从观察到行动的决策方案,以前只有通过人工设置才可能实现,但现在就可以自动实现,这是一个比较颠覆性的变化,从被动智能进化到主动智能。
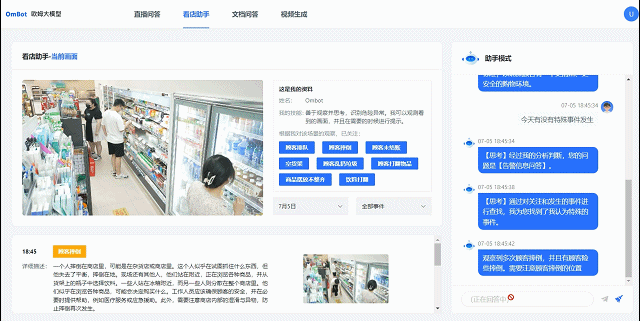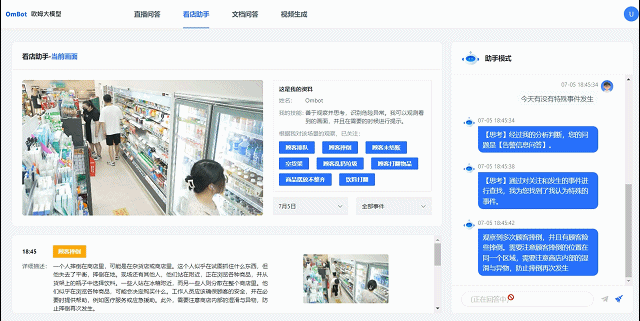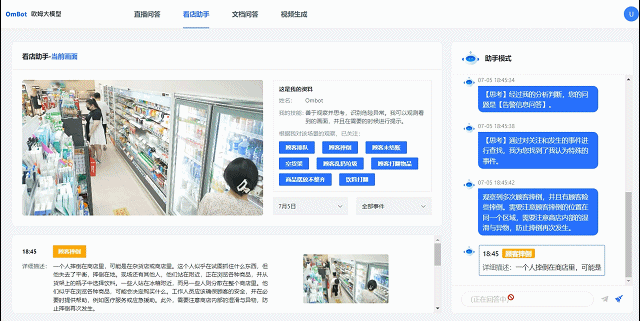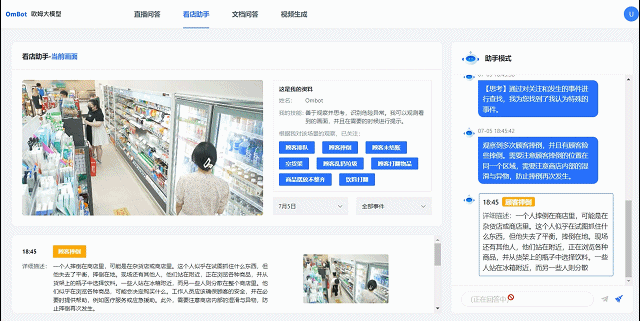
联汇科技巡店机器人进行店面管理
当 AI 从被动智能发展到主动智能后,就有了更多的商业应用价值,就有可能实现大规模的商业化。
极客公园:联汇科技团队在 AI 落地场景很早就开始尝试,现在还有哪些落地场景可以透露?
赵天成:现在很多 AI 应用主要还是基于纯语言模型,我们的特点是专注在多模态大模型上,特别是视觉和语言两个模态。把视觉和语言结合起来的应用场景很多。
比如在媒体领域有很多内容创作需求。我们正在用基于视觉语言大模型的智能体框架做一个产品,实现编导层面的自动化和主动智能,以解决编导们最头痛的内容创意问题,这个产品可以根据内容主题要求,自动分析内容主体是什么、需要什么素材、镜头怎么拆,最后要用怎样的叙事线表达,让 AI 去做一步步推理的过程。
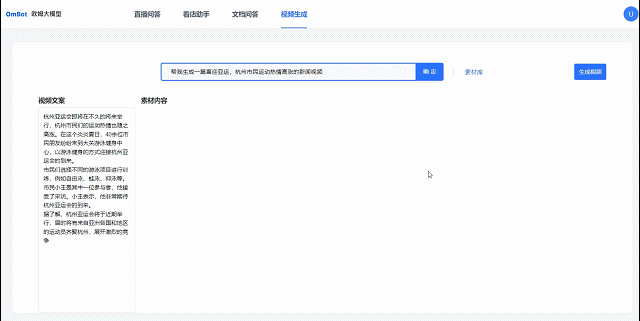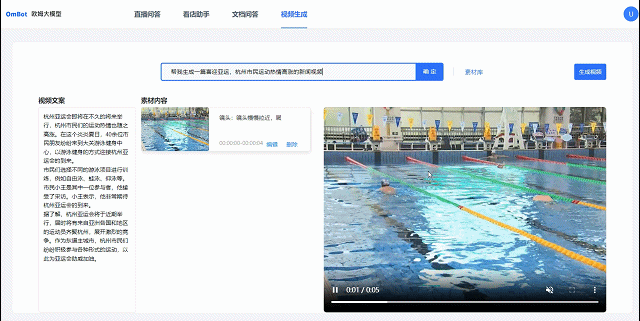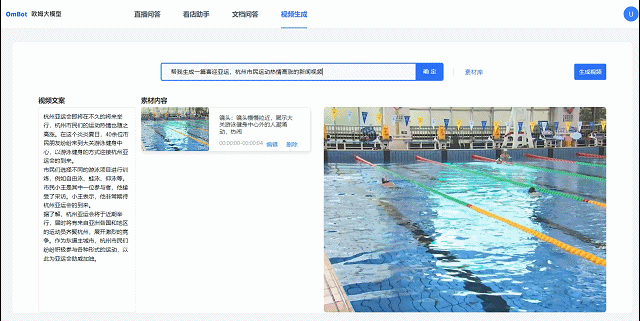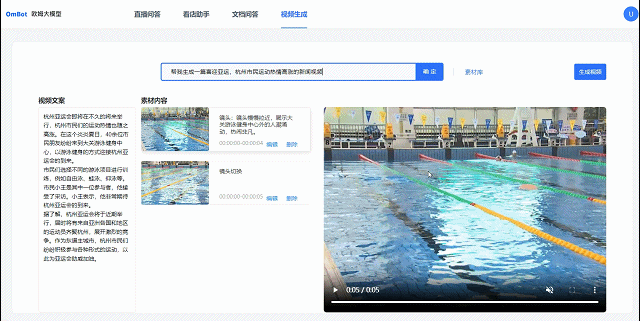
视频小欧文生视频
另外比如国内做的比较多的智慧家居、智慧零售等场景。以前家庭或者小店里安装的摄像头只是一个观察者,只会识别预定目标,比如有人闯入,然后通知你看视频回放,但一旦这些摄像头加上了主动智能后,每个设备都能主动思考,它就成了一个虚拟店长、虚拟保姆,这些都很有想象空间。

OmBot 自主智能体:面向行业的多模态智能体系列
04 大模型 B 端市场是丛林,而不是大决战
极客公园:联汇科技在 AI 商业化,尤其是 B 端是很成功的,这其中有哪些经验值得分享?
赵天成:B 端场景不像 C 端。B 端必然会有个性化的需求。因此怎样用更低成本去满足这些个性化需求是非常重要的。这几年,我们一直致力于加强我们大模型的能力,同时开发相应的微调工具链,在此基础上,用户通过 Prompt(提示词)的方式就可以完成用户的个性化微调训练,这就让定制成本变得很低,创造出一种全新的用户个性化 AI 服务的方法。
我们的经验在做 B 端服务时,一定要考虑取舍,不能走上定制小模型的路,要学会克制,有舍有得。
极客公园:在 AI 大模型商业化落地这件事上,真正难的地方是什么?
赵天成:把 AI 技术产品化,让它满足客户的需求有很多因素需要考虑。国内和国外市场有个很不一样的地方,美国在很多技术方面都有更明晰的分层,生态链中每一个环节,都能发展出很优秀的公司。
比如说有些公司就做一个中间件,也可以活得很好。但是国内并不存在这样成熟的生态体系,只做中间件很难存活。因此在国内市场,一家 AI 公司要实现商业化落地,他产品得有「厚度」才行,意味着你必然要对客户有更深的理解,要做成产品闭环。单纯把某个模块做到极致,是远远不够的。
极客公园:前不久刚刚召开 OpenAI 开发者大会,很多开发者看完觉得自己做的半年甚至一年努力都归零了,怎么看这种趋势?
赵天成:我觉得 OpenAI 做这些商业化尝试和我预期的差不多,他们肯定会做这些事情。Sam Altman 是很有野心的人,他肯定不会放弃这么大的潜在市场。
OpenAI 的商业化模式,对国外的开发者冲击确实很大,但我认为他们很快就会在这样的生态中,找到新的机会。
前面我讲到,国内和国外的 AI 生态有很大的不同,特别是 2B 市场,OpenAI 的模式很难在中国复制。国内用户的私有化部署、数据壁垒、个性化需求等特点,都会影响到商业落地模式。
因此我们还是坚持把自己的模型做好,把我们的工具链做好,提升自己原生的长期竞争力。同时,我们也在根据国内的商业环境,探索更多的应用形态,其中也会借鉴国内外的很多模式,它山之石可以攻玉,总的来看,OpenAI 的发展对我们的成长还是非常有利的。
极客公园:国内目前卷大模型的这个现状,联汇科技是怎样看待或者应对的?
赵天成:我们主要从几个方面来应对,第一,走差异化路线。回头看「百模大战」,其实大部分公司都是在想办法复现 ChatGPT,到现在为止,基本上还停留在 OpenAI 早期的大语言模型阶段,各家的产品很难看出差异化。而我们一开始就是走多模态路线,很多时候客户会说,文本 AI 我见过,但是能看懂图像的好像没见过。图像+文本的场景应用非常丰富。因此,我们通过差异化,能够更好满足客户需求,并提供市场想要的产品。
另外,相较于很多公司,联汇有不同的定位,因为我们主要服务在 B 端,就和目前市面上大部分企业面向 C 端的打法也不一样。

联汇科技拥有丰富完整的产品体系
还有,相较于有些公司一味地卷模型参数的大小。我们更关注的是模型的实际落地能力。大家也都知道微软透露 GPT 3.5-Turbo 用的大模型参数也就在 200 亿左右。因此模型参数多少合适,要有一个综合的判断,不是越大越好。
极客公园:如果现在才回国创业,大模型领域当前的红海状态下,你还会考虑做基础模型吗?
赵天成:假如目前从 0 去做基础模型,相比三年前会难很多。很多团队已经入场。但我并不认为现在大模型领域已经进入红海阶段,因为大模型本身证明了对于海量数据的学习和压缩可以产生智能,但是 ChatGPT 也只是大模型的其中一种形式。
通过大量的预训练,把知识融入到一个模型里面,让它产生通用能力,涌现出一些智能,这件事是不是只能做语言模型?我觉得肯定不是,别的场景下面还可以有,比如图像、3D 或者分子结构等等,因此,切准某一个领域去做,还是有很多机会的。
比如我可以专门做 3D 大模型,或者做物理世界大模型,像 World Model 这种类型。其实三年前,做语言类大模型也是有很多不确定性的,因此我觉得做基础大模型还是有很多机会的,关键是要对大模型的方法论有真正的理解,以及切入点的正确选择。
极客公园:怎样看待和大厂在 AI 领域的关系?是完全的竞争还是说有其他可能?
赵天成:首先,在 AI 领域,任何时候小公司都有机会,就像美国,很多 AI 创新都是谷歌提出的,但是 OpenAI 就比谷歌做得更好。
2017 年的时候我一些朋友也在 OpenAI 实习,那时候这家公司还不到 100 人。所以在 AI 领域,创业公司并不是没有机会,但是竞争肯定不可避免。每家公司要找准自己的定位。
对于 C 端场景,竞争肯定会比较激烈,大厂本身有较强的用户平台,小公司可能要真正有一些比较创新的应用场景,同时又有比较好的市场策略才能胜出。
不过在 B 端,我觉得不管大厂还是小厂,都不存在赢家通吃的局面,因为 B 端的行业逻辑和 C 端是不一样的。有一个比喻说的很好,C 端可能是一种规模战,大家是在比拼火力,我有 100 辆坦克,你有 1 辆坦克,我就能赢你。但是 B 端场景下面,大家都是丛林里的猎人,你可能拿了一个火箭筒,我拿了一把狙击步枪,我的火力没有你强,但这头鹿到底谁能打下来不一定。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK