

一日一技:HTML里面提取的JSON怎么解析不了?
source link: https://www.kingname.info/2023/10/28/json-in-html/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一日一技:HTML里面提取的JSON怎么解析不了?
2023-10-28
73
722
2 分钟
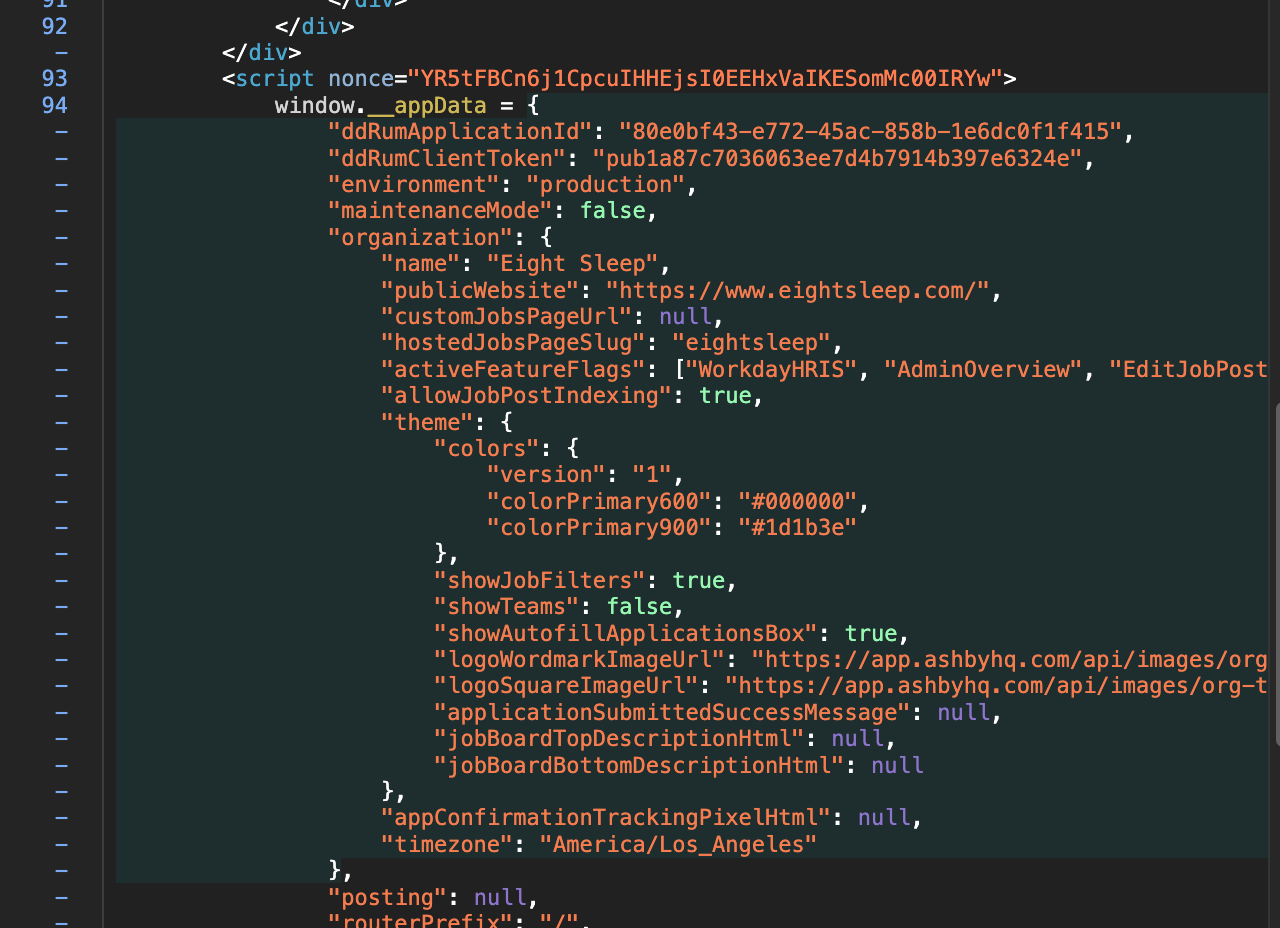
我们在开发爬虫的过程中,经常发现有一些网站,会直接把数据以JSON的形式,通过<script>标签放到页面源代码中。如下图所示:
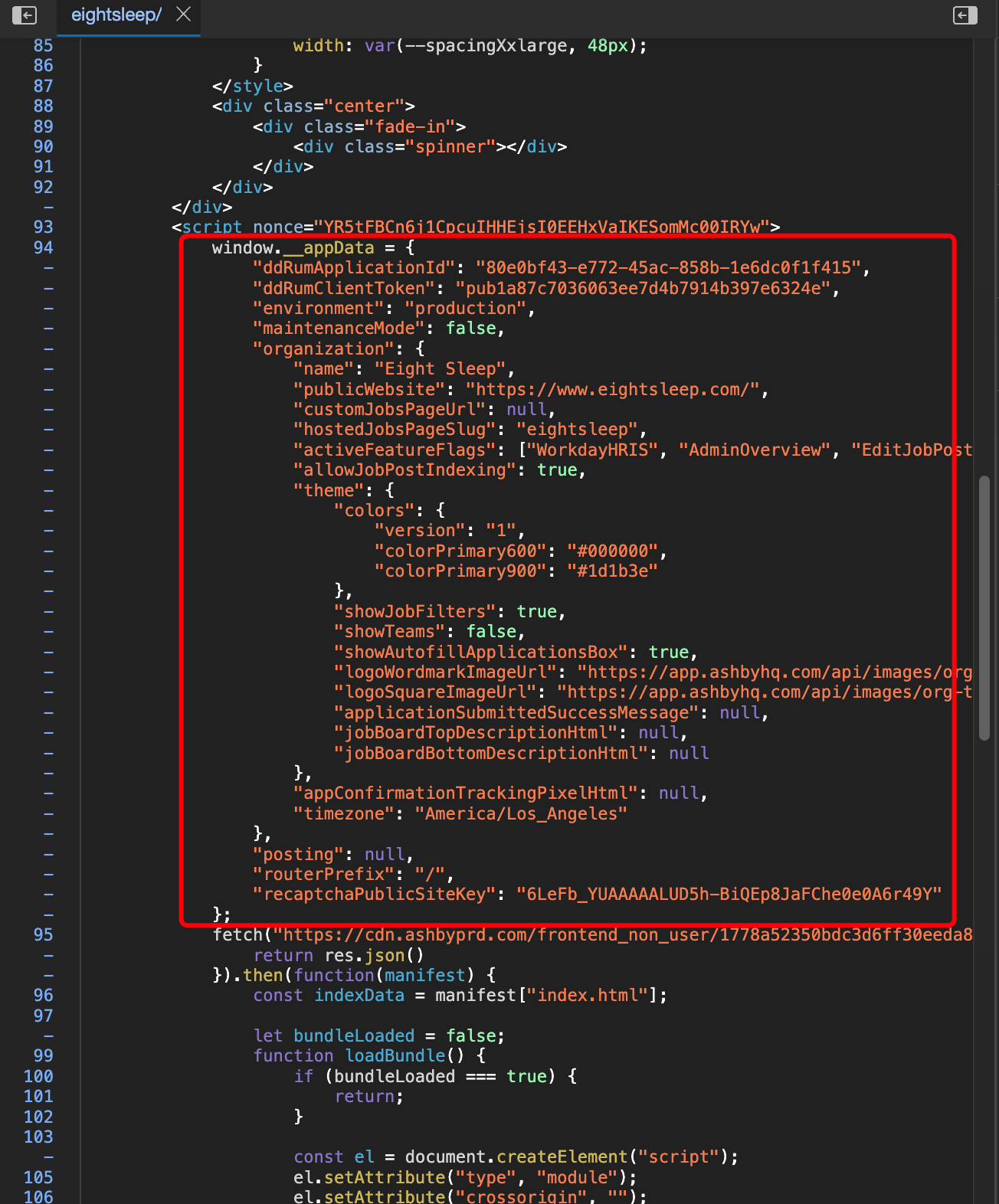
有时候请求URL拿到HTML的过程比较麻烦,有些同学习惯先把HTML复制到代码里面,先把解析的逻辑写好,然后再去开发请求HTML的代码。
这个思路本身是没有什么问题的,于是他们就写了如下的代码:
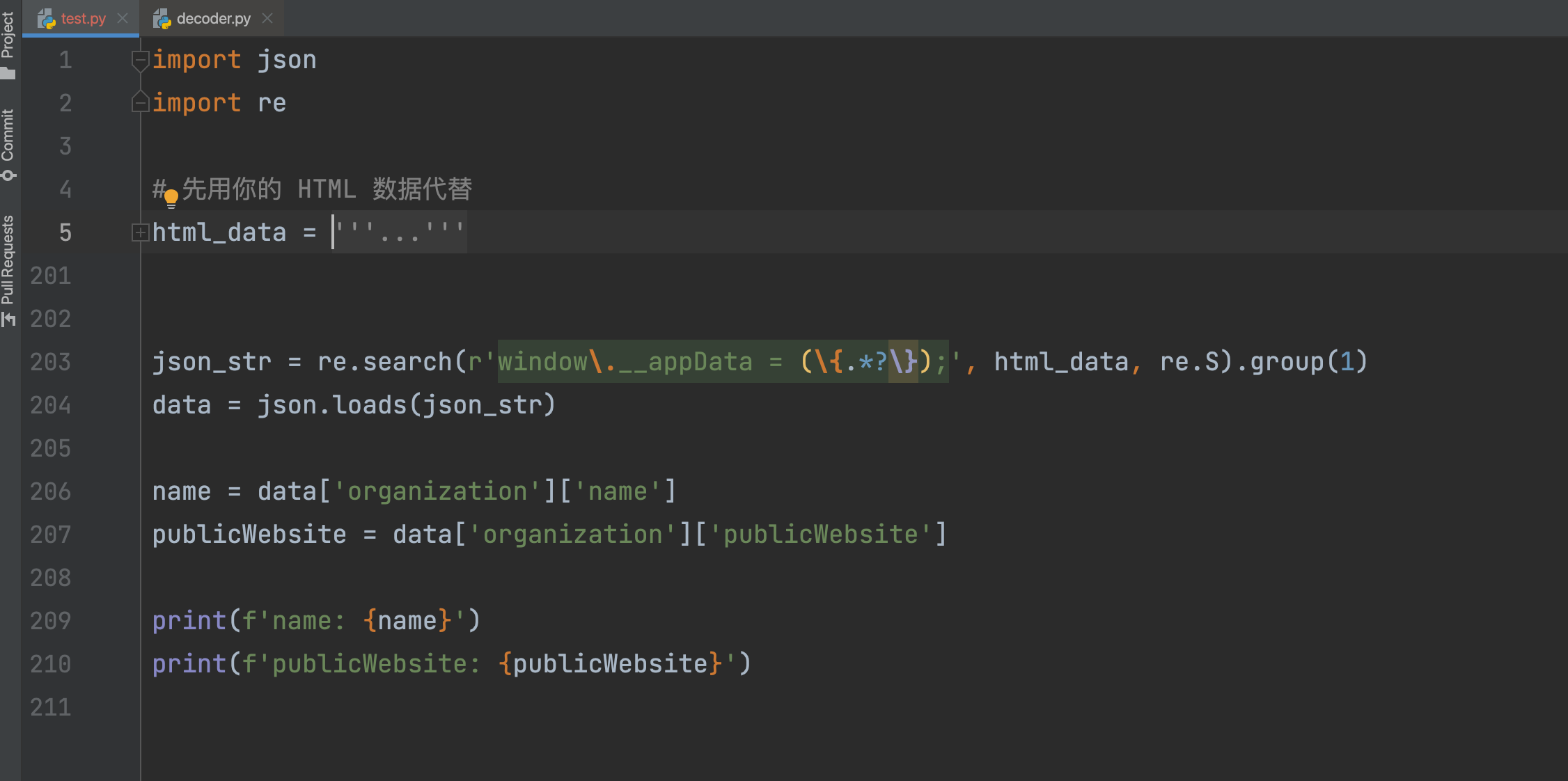
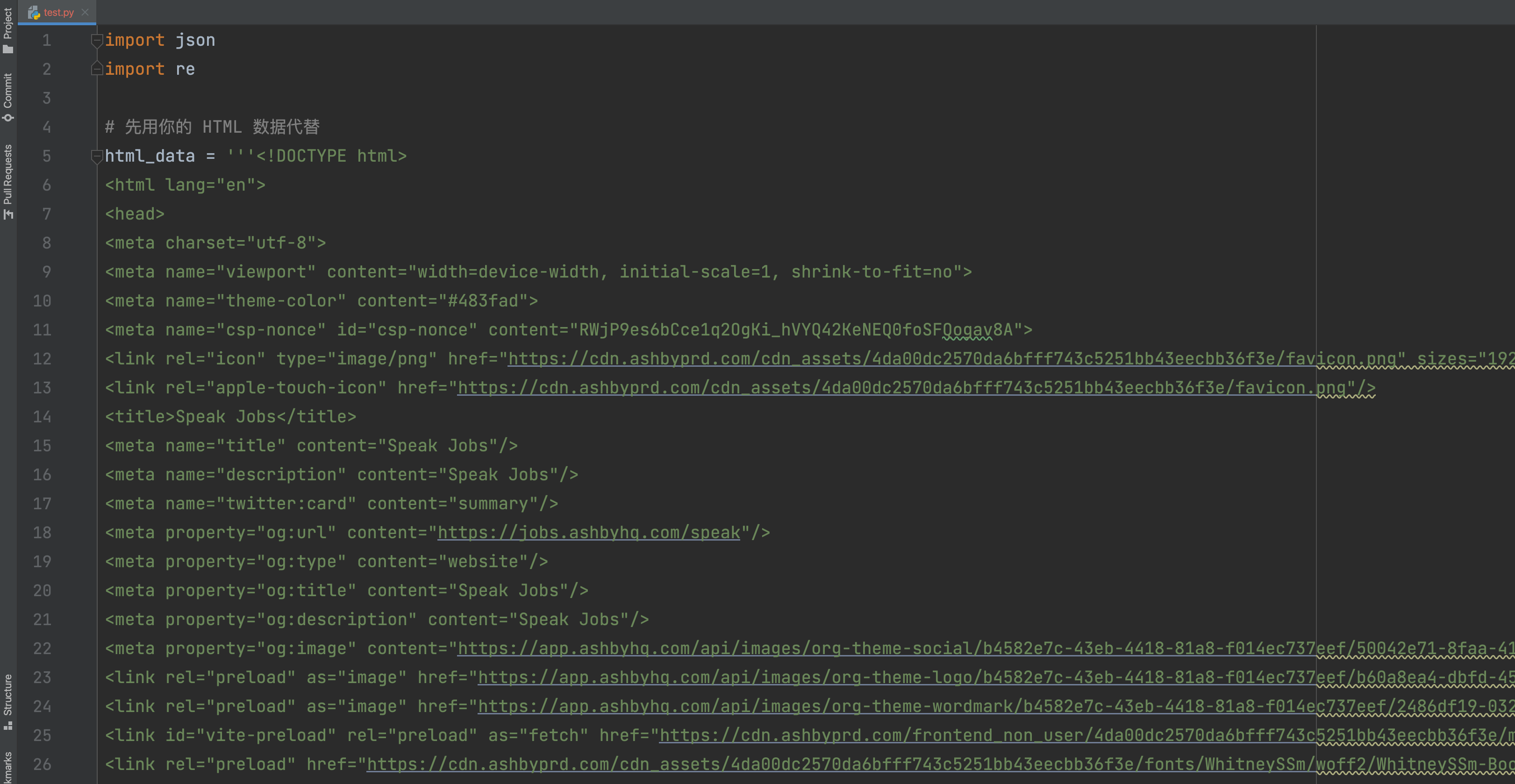
代码中的html_data = '''里面就是原样复制的网页HTML,没有做任何修改,因为太长了,我这里做了折叠。展开以后如下图所示:
但当运行这段代码的时候,发现代码报错了,如下图所示:
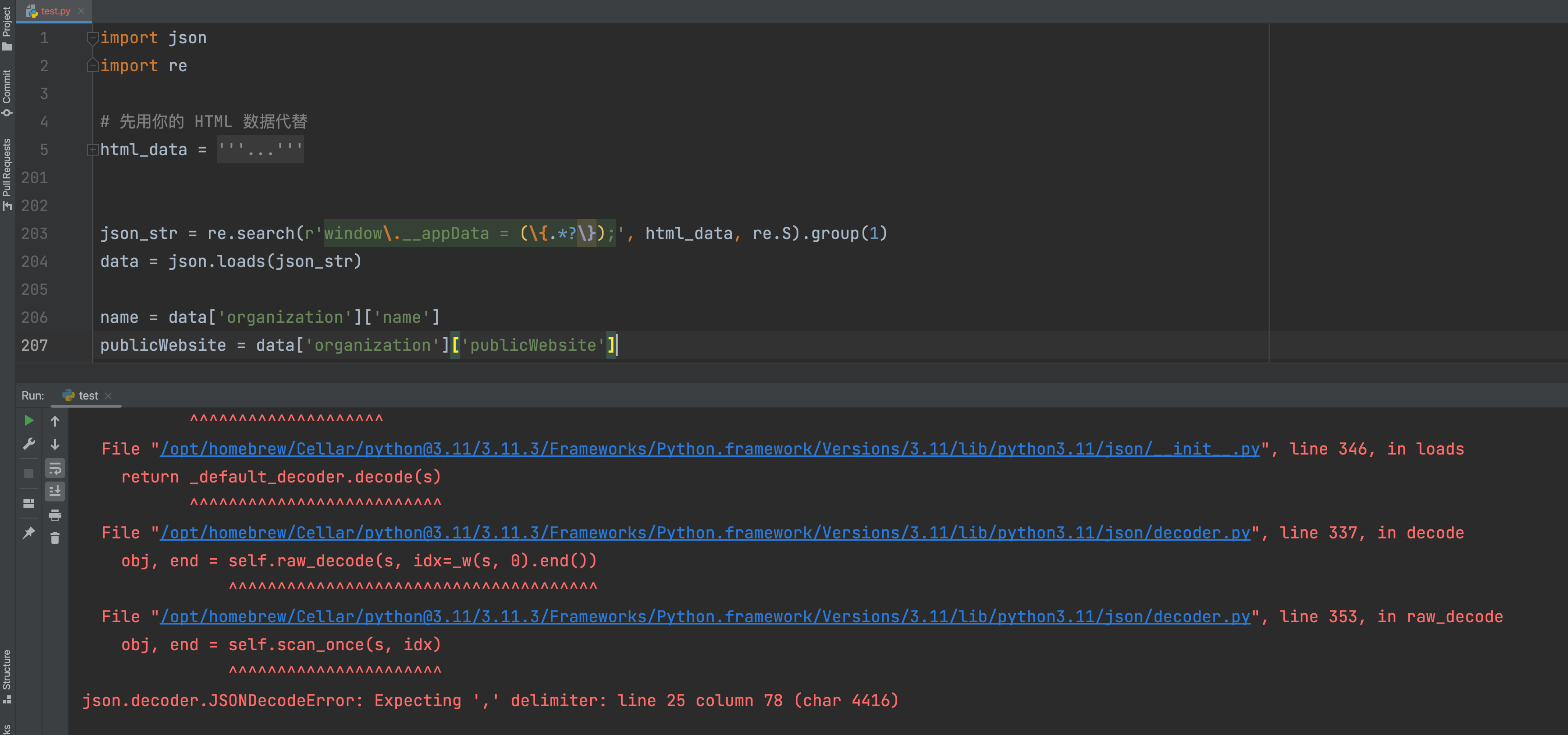
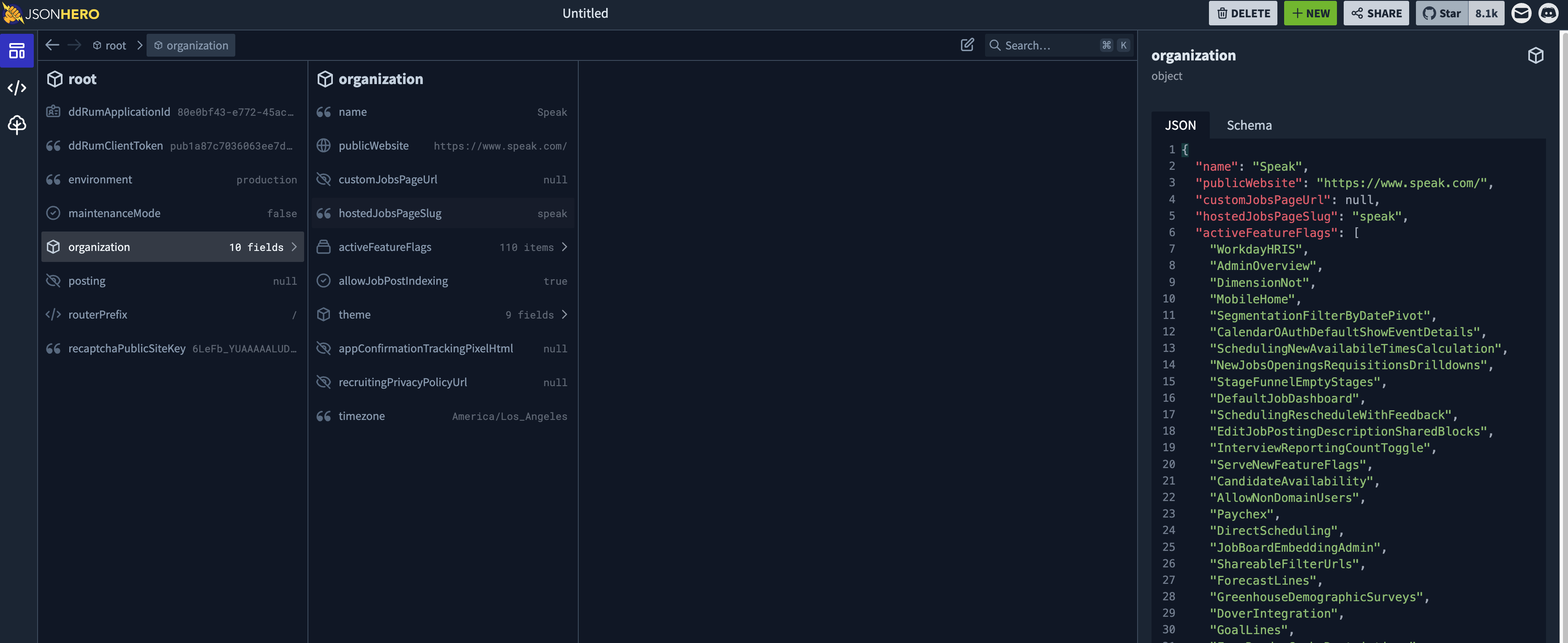
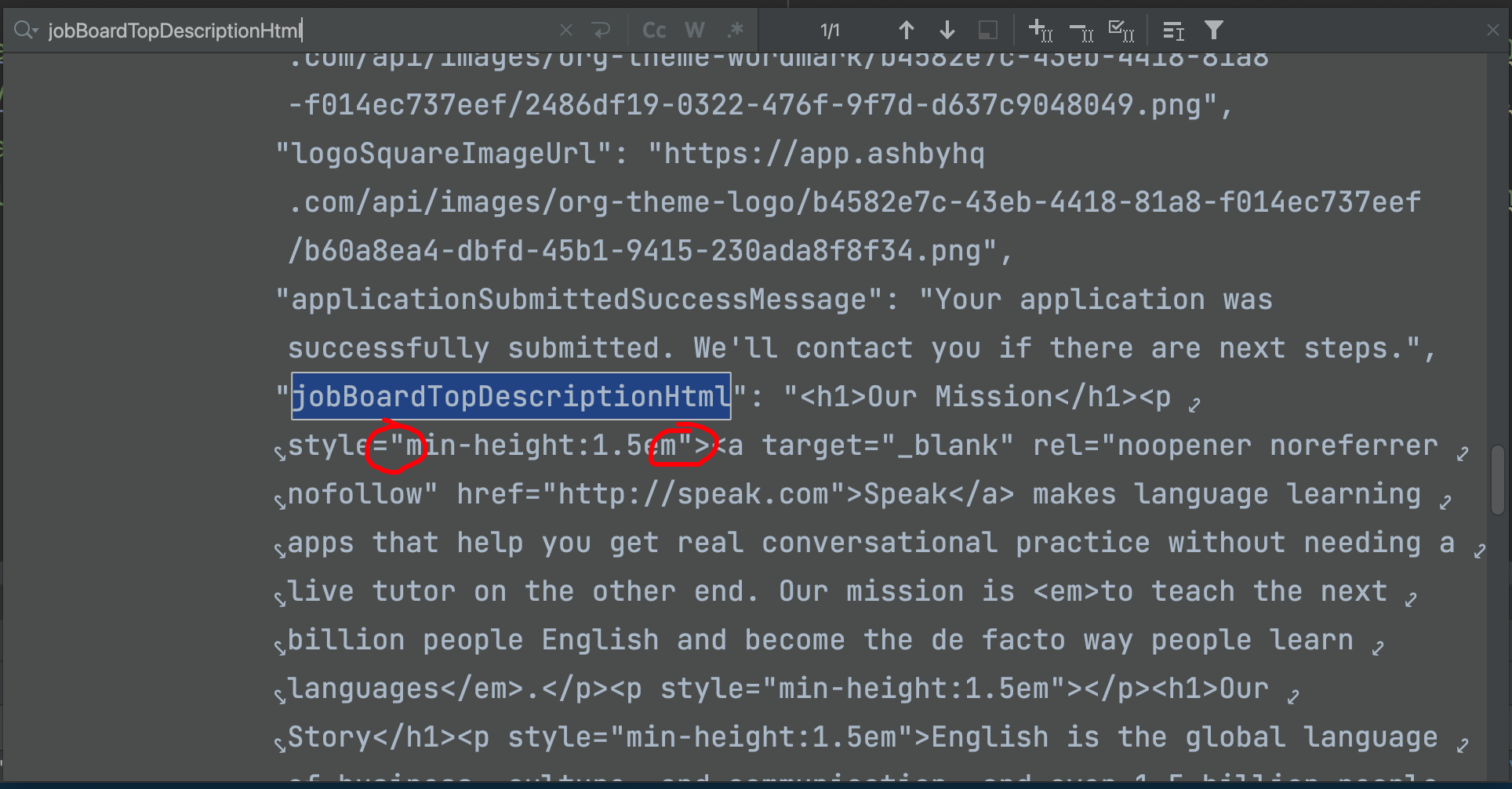
看这个报错信息,难道说是JSON本身有问题?于是,你到网页上,把这个JSON复制下来:
使用JSONHero这种验证网站,进行验证,结果发现一切正常:
这就见鬼了,为什么正则表达式提取的JSON就不对呢?你开启PyCharm的调试模式,看看正则表达式提取出来的JSON:
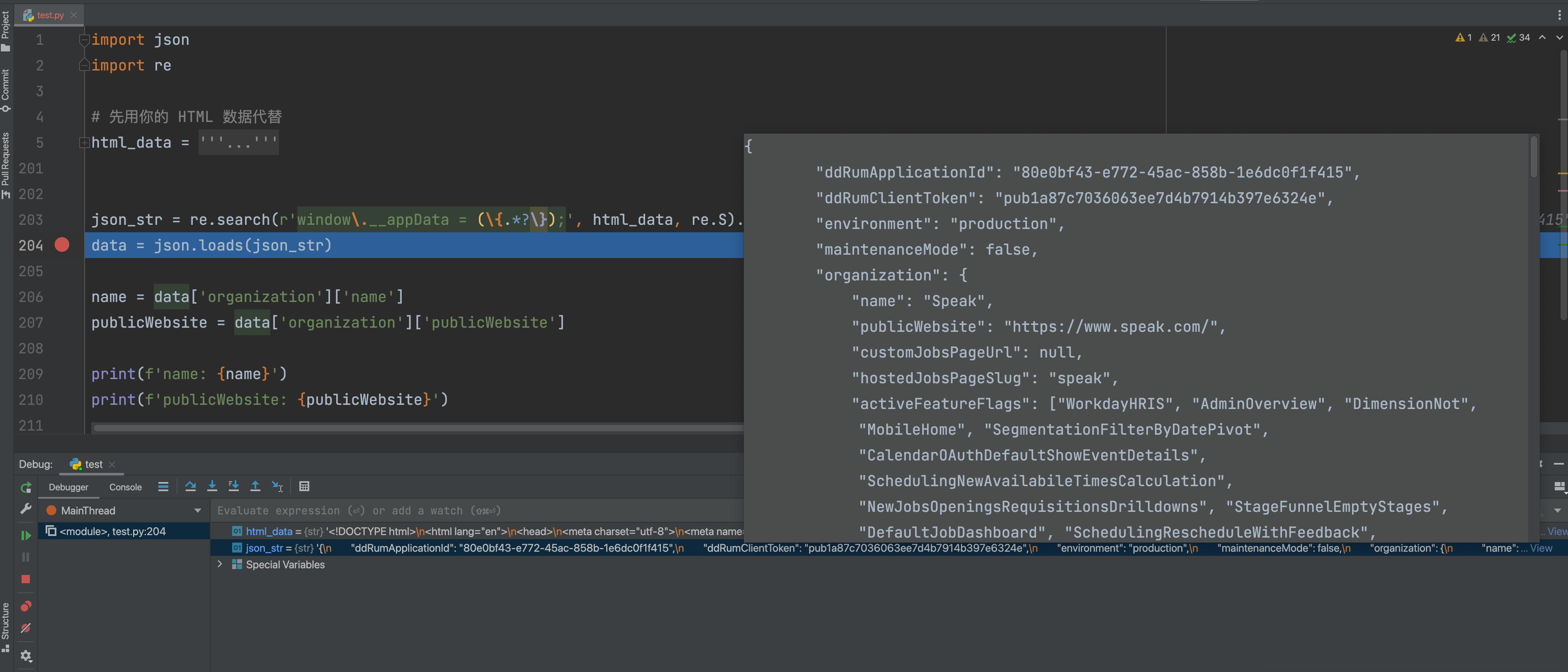
你把提取出来的JSON复制粘贴到JSONHero网站上,竟然报错了:
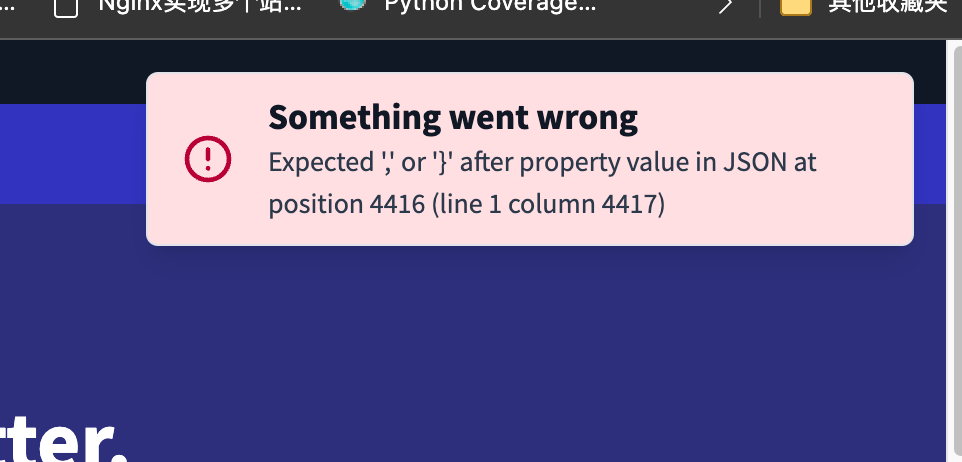
到底是哪里有问题呢?为什么直接从网页上复制JSON就没有问题,而使用正则表达式提取的JSON就有问题呢?
其实原因非常简单,问题就出现在HTML中的JSON里面的反斜杠:
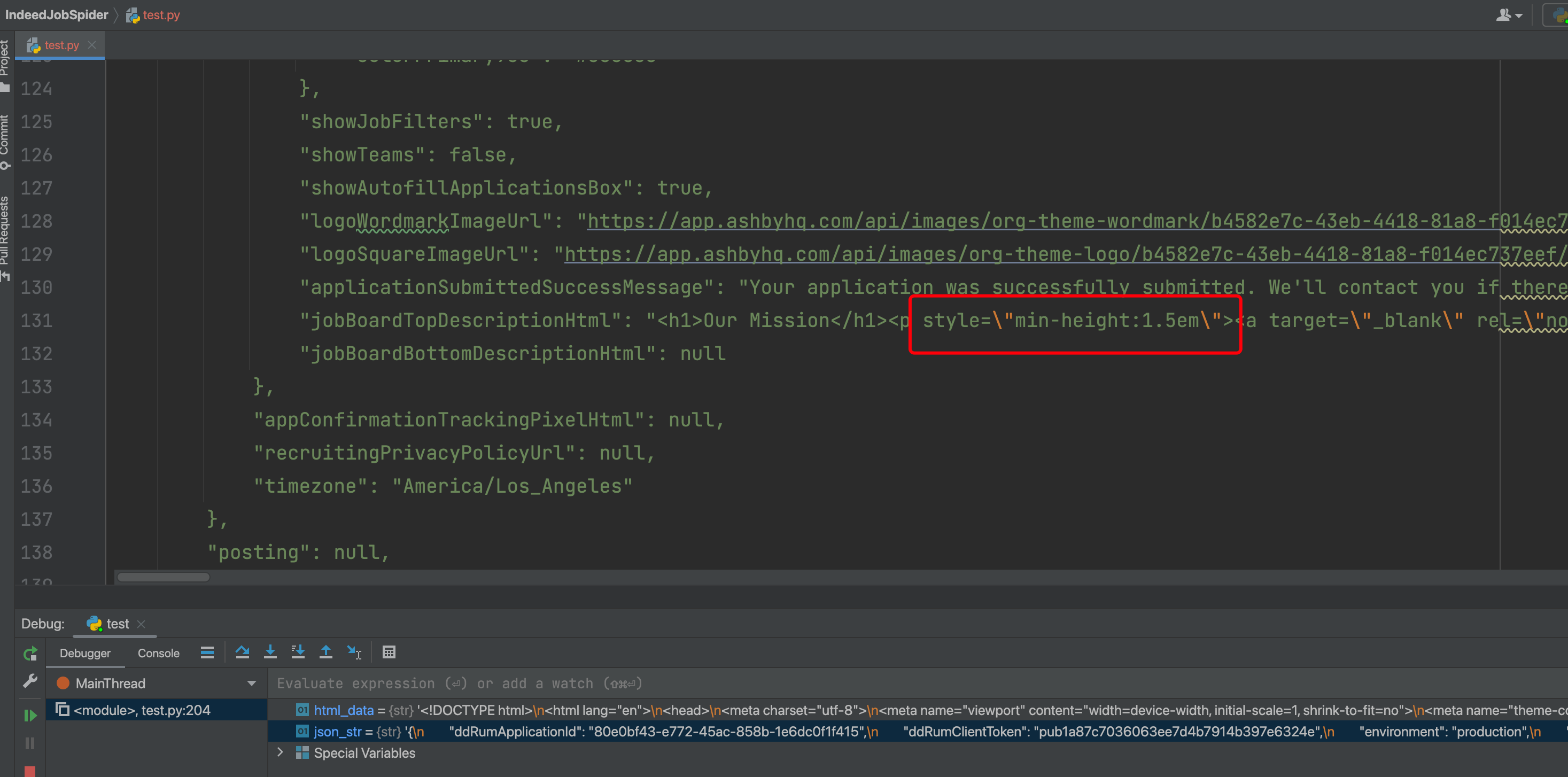
我们知道,反斜杠是不能单独存在的,它有自己独特的意义。在代码里面,我使用了'''三个引号来抱住整个网页的HTML,这个时候,Python发现这里的\"这种写法,会自动把反斜杠去掉。于是,正则表达式提取出来的JSON,引号就会出现冲突,如下图所示:
这样的JSON就会变成不合法的JSON。因为在JSON中,字符串内部作为普通字符的双引号,应该使用反斜杠转义,而这里的反斜杠被自动删除了。
要解决这个问题,有三种方法:
- 手动修改JSON里面的所有反斜杠,把每一根反斜杠变成两根反斜杠:
\"->\\"。(太麻烦了,就不演示了) - 在三引号前加上
r,此时Python会自动把所有的反斜杠转换为普通的字符串: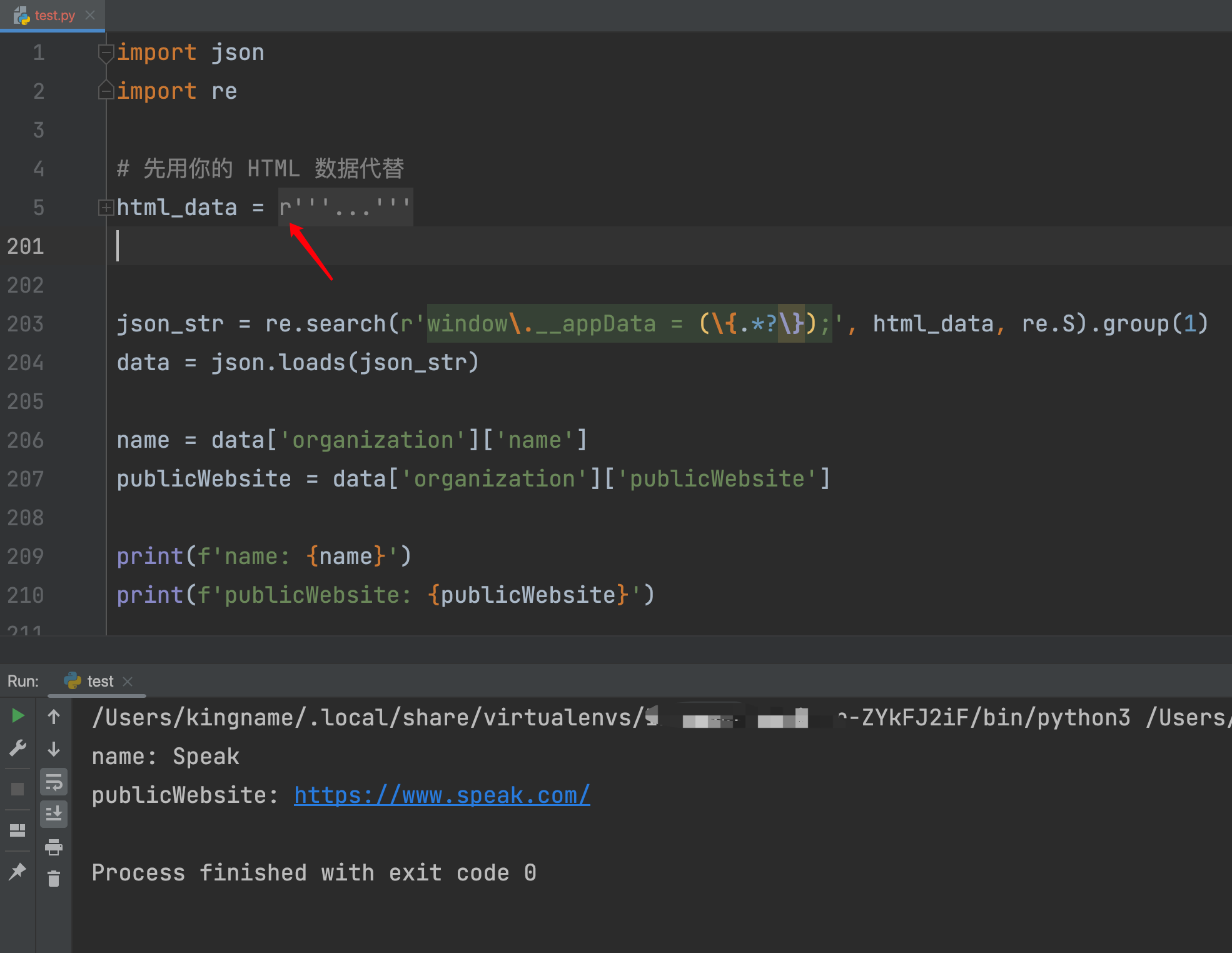
- 把HTML写到文件里面,通过读文件的形式来读源代码。Python自动就会处理反斜杠。
总结,这个问题只有在你直接把HTML粘贴到Python代码里面的时候会出现。如果你是直接使用Requests请求网页,或者你把HTML存到文件里面,通过读文件的形式来读HTML,那么Python都能自动处理好这个反斜杠的问题。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK