

一款Python高性能数据处理工具
source link: https://xugaoxiang.com/2023/10/02/python-polars/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Polars 是一个开源的 Python 库,是一个高性能数据处理库,提供了类似于 Pandas 的 API 接口。它在处理大规模数据时表现出色,能够快速执行各种数据操作,如筛选、转换、连接等。
要安装 Polars 库,可以使用 pip 命令
pip install polars pyarrow
下面我们来看看 Polars 库的基本使用方法及示例
创建和加载数据
在 Polars 中,可以使用 polars.DataFrame 对象来表示数据。可以通过多种方式创建和加载数据,如手动创建、从 CSV 文件加载、从 Pandas DataFrame 转换等。以下是一些常用的示例代码
import polars as plimport pandas as pd# 创建DataFramedf = pl.DataFrame({'name': ['Alice', 'Bob', 'Charlie'],'age': [25, 30, 35]})# 从CSV文件加载数据# df = pl.read_csv('data.csv')# 从Pandas DataFrame转换pandas_df = pd.DataFrame({'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 30, 35]})df = pl.from_pandas(pandas_df)print(df)
代码执行的结果为
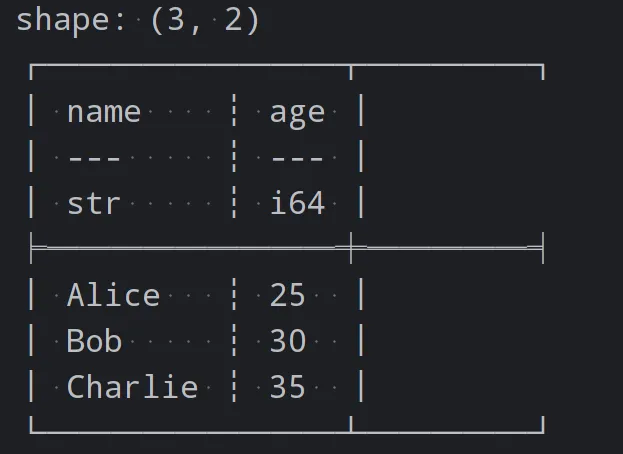
数据筛选和过滤
Polars 提供了灵活的筛选和过滤功能,可以根据条件选择特定的行或列。以下是一些示例代码
# 根据条件筛选行filtered_df = df.filter(pl.col("age") > 30)# 根据条件筛选列selected_df = df[['name', 'age']]print(selected_df)# 使用多个条件筛选filtered_df = df.filter((pl.col("age") > 30) & (pl.col("name") == "Bob"))print(filtered_df)
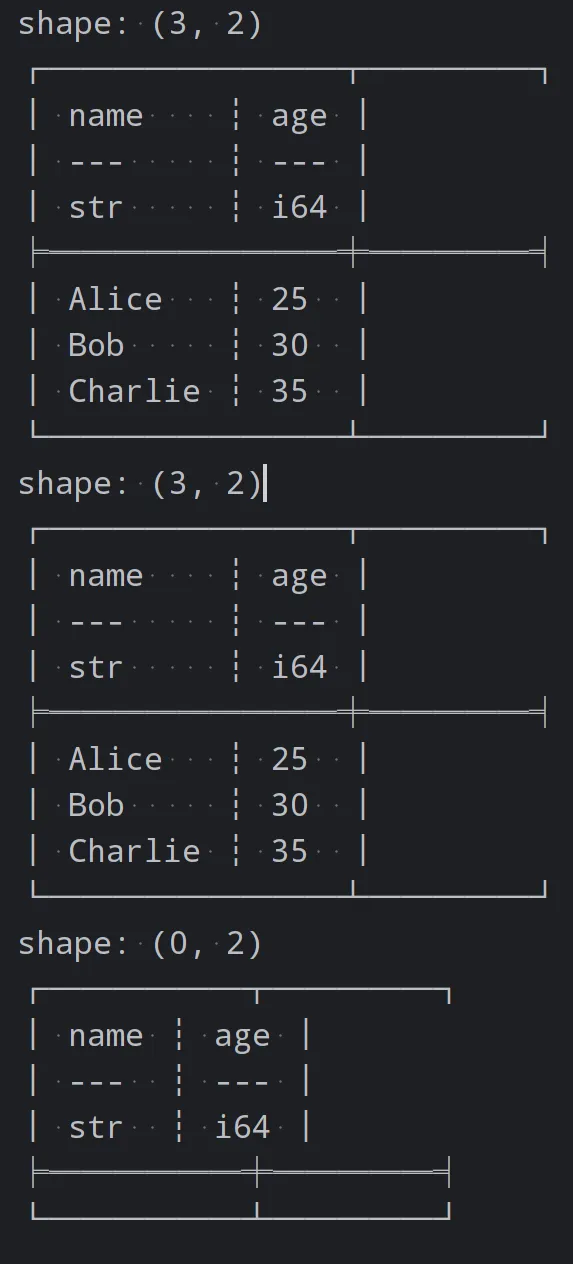
Polars 提供了丰富的数据转换和操作功能,如添加新列、重命名列、排序等。以下是一些示例代码
# 添加新列heightdf = df.with_columns(pl.Series('height', [160, 170, 180]))# 重命名age列df = df.with_columns(pl.col('age').alias('years'))# 按列进行排序sorted_df = df.sort('age')print(sorted_df)
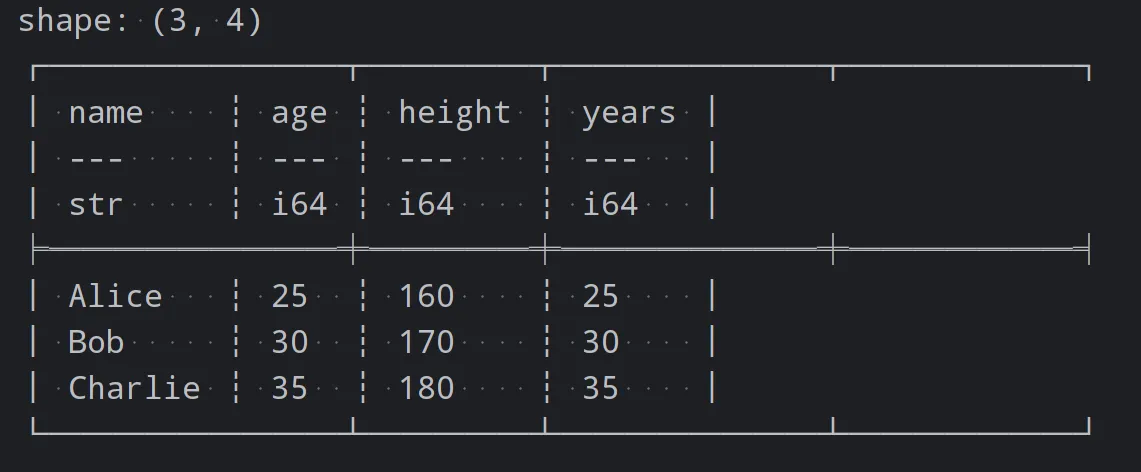
数据聚合和分组
Polars 支持灵活的数据聚合和分组操作,可以根据指定的列对数据进行分组,并进行各种聚合操作,如求和、计数、平均值等。以下是一些示例代码
import polars as pl# 创建DataFramedf = pl.DataFrame({'name': ['fish', 'meat', 'fish', 'meat'],'price': [25, 30, 35, 40]})# 按name列分组,并计算每个类别的平均售价grouped_df = df.group_by('name').agg(pl.col('price').mean())print(grouped_df)
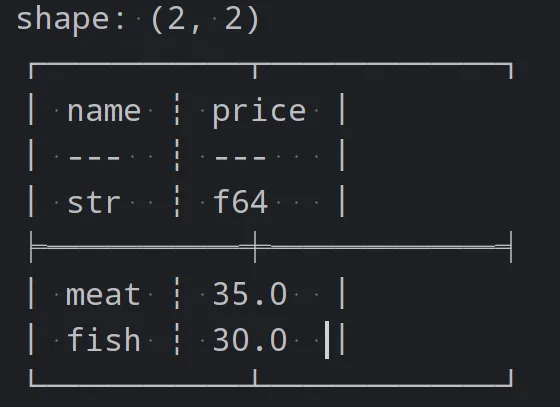
Polars 提供了多种数据连接的方法,如合并两个 DataFrame、连接两个 DataFrame 等。以下是一个示例代码
import polars as pl# 创建DataFramedf = pl.DataFrame({'name': ['fish', 'meat'],'price': [25, 30]})df1 = pl.DataFrame({'name': ['beef', 'vegetable'],'price': [65, 10]})# 连接两个DataFramejoined_df = df.join(df1, on='name', how="outer")print(joined_df)
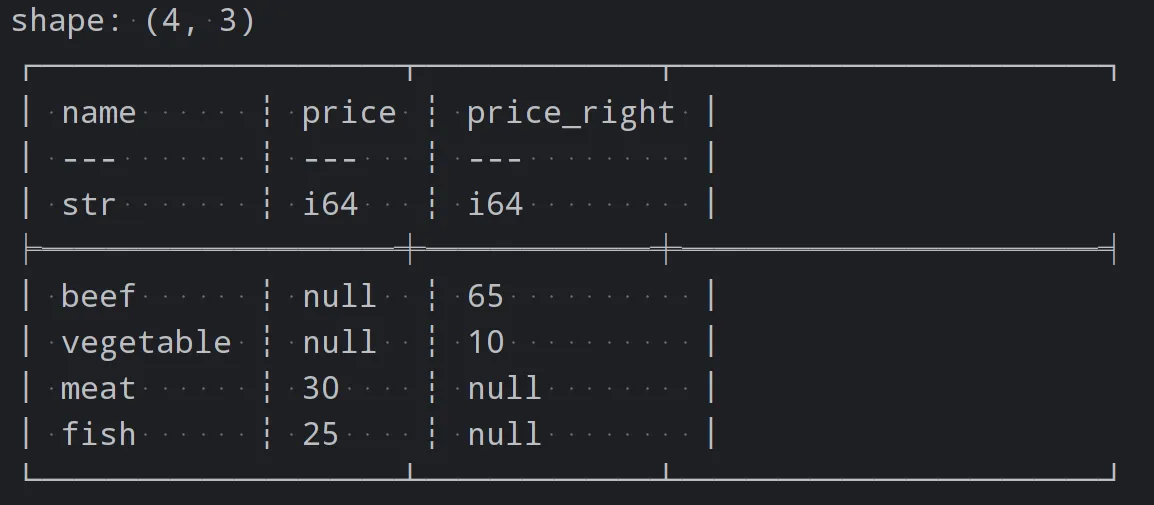
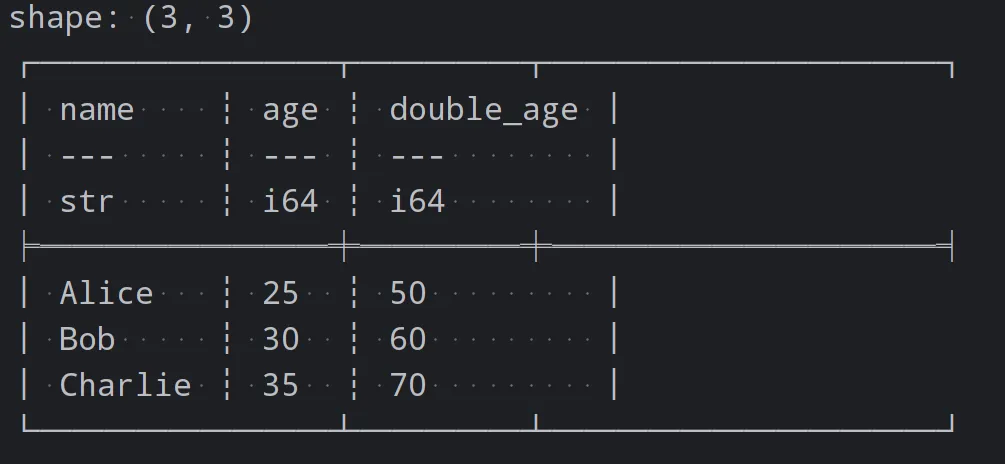
自定义函数和映射
在 Polars 中,可以使用自定义函数和映射来对数据进行复杂的转换和操作。以下是一个示例代码
import polars as pl# 创建DataFramedf = pl.DataFrame({'name': ['Alice', 'Bob', 'Charlie'],'age': [25, 30, 35]})# 定义自定义函数def double_age(age):return age * 2# 应用自定义函数df = df.with_columns(pl.col('age').map_batches(double_age).alias("double_age"))print(df)
在本文中,我们深入介绍了 Polars 库的基本原理和使用方法,并提供了相应的代码示例。通过学习 Polars 库,你将能够高效地处理和分析大规模数据,提高工作效率。更多详细信息可参考官方文档: https://github.com/pola-rs/polars。
</article
Recommend
-
172
Python数据处理库pandas入门教程, AI, Python,MachineLearning,pandas, pandas是一个Python语言的软件包,在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础编程库。本文是对它的一个入门教程。
-
113
Python数据处理库pandas进阶教程, AI, Python,MachineLearning,pandas, 在前面一篇文章中,我们对pandas做了一些入门介绍。本文是它的进阶篇。在这篇文章中,我们会讲解一些更深入的知识。
-
126
参考资料: medium.com Python是一门非常适合处理数据和自动化完成重复性工作的编程语...
-
41
阿里妹导读:
-
34
1. 前言本篇文章继续继续另外一种比较常用的数据存储方式:Memcached Memcached:一款高性能分布式内存对象缓存系统,通过 内存缓存,以减少数据库的读取,从而分担数据库的压力,进而提高网站的加载速度 Memcached,实际上是一...
-
7
SeaTable 开发者版可以运行 Python 了,开发自定义数据处理流程更方便发布于 3 月 23 日又填新功能了!从 1.8.0 版开始,SeaTable 开发者版加入了运行 Python 的能力(具体配...
-
23
V2EX › 程序员 [C#外包] 用 C#写一个 GUI 数据处理工具, 限深圳(需求之前发帖讨论过的) wzw
-
4
数据处理开源工具-Volbx – 开源派 Volbx是一款可用于数据处理的开源图形工具,拥有数据加载、过滤、选择筛选、可视化、xlsx 与 CSV 格式导出等功能。基于
-
10
合集 - 前沿技术(1)1.向量数据库:新一代的数据处理工具07-05 在我们的日常生活中,数据无处不在。从社交媒体的帖子...
-
7
我在业余时间开发维护了一款免费开源的升讯威在线客服系统,也收获了许多用户。对我来说,只要能获得用户的认可,就是我最大的动力。 最近客服系统成功经受住了客户现场组织的压力测试,获得了客户的认可。 客户组织多名...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK