

论文投Nature先问问GPT-4!斯坦福实测5000篇,一半意见跟人类评审没差别
source link: https://www.51cto.com/article/768659.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
论文投Nature先问问GPT-4!斯坦福实测5000篇,一半意见跟人类评审没差别
GPT-4有能力做论文评审吗?
来自斯坦福等大学的研究人员还真测试了一把。
他们丢给GPT-4数千篇来自Nature、ICLR等顶会的文章,让它生成评审意见(包括修改建议啥的),然后与人类给的意见进行比较。
结果发现:
GPT-4提出的超50%观点与至少一名人类评审员一致;
以及超过82.4%的作者都发现GPT-4给的意见很有帮助。
那么,这项研究究竟能给我们带来何种启示?
高质量的人类反馈仍然不可替代;但GPT-4可以帮助作者在正式同行评审前改进初稿。

具体来看。
实测GPT-4论文评审水平
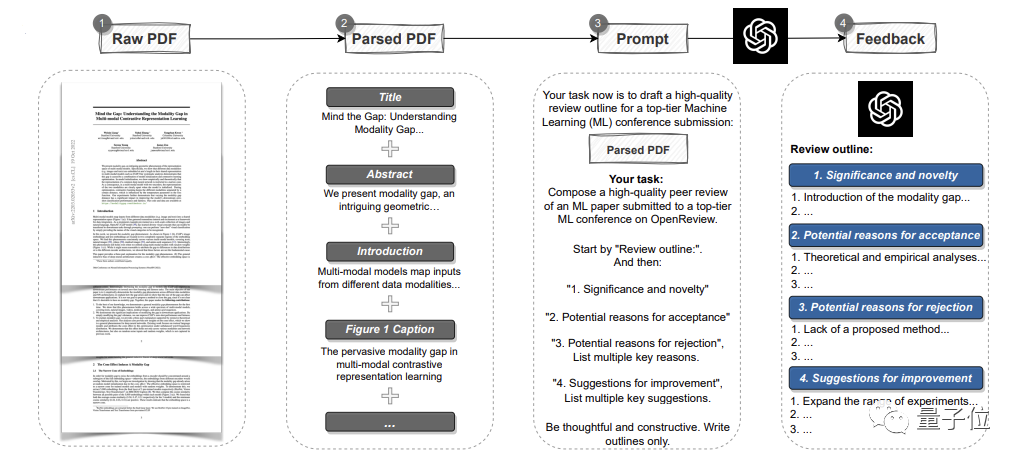
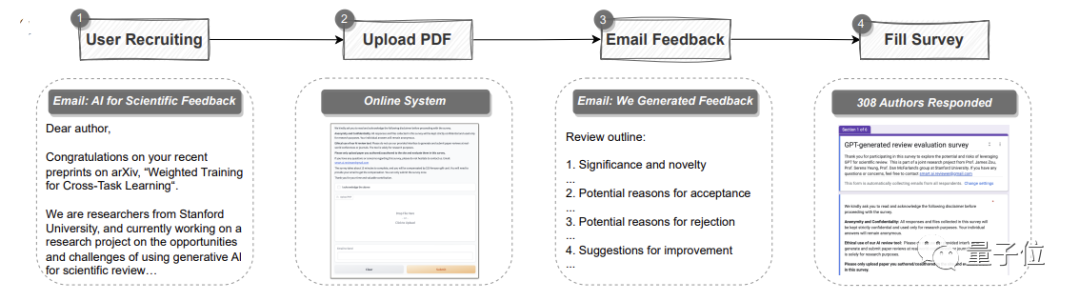
为了证明GPT-4的潜力,研究人员首先用GPT-4创建了一个自动pipeline。
它可以解析一整篇PDF格式的论文,提取标题、摘要、图表、表格标题等内容来构建提示语。
然后让GPT-4提供评审意见。
其中,意见和各顶会的标准一样,共包含四个部分:
研究的重要性和新颖性、可以被接受的潜在原因或被拒绝的理由以及改进建议。
具体实验从两方面展开。
首先是定量实验:
读已有论文,生成反馈,然后与真实人类观点系统地比较出重叠部分。
在此,团队从Nature正刊和各大子刊挑选了3096篇文章,从ICLR机器学习会议(包含去年和今年)挑选了1709篇,共计4805篇。
其中,Nature论文共涉及8745条人类评审意见;ICLR会议涉及6506条。
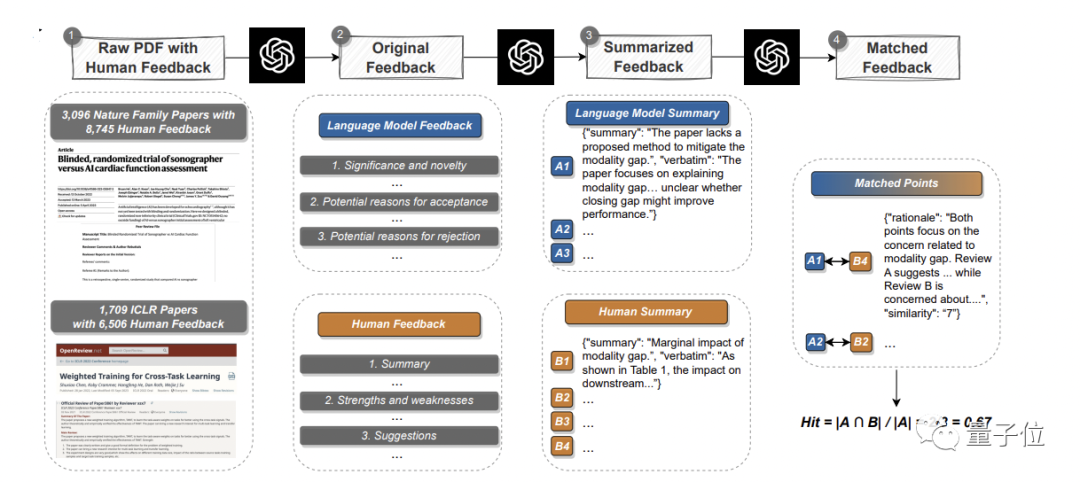
GPT-4给出意见之后,pipeline就在match环节分别提取人类和GPT-4的论点,然后进行语义文本匹配,找到重叠的论点,以此来衡量GPT-4意见的有效性和可靠度。
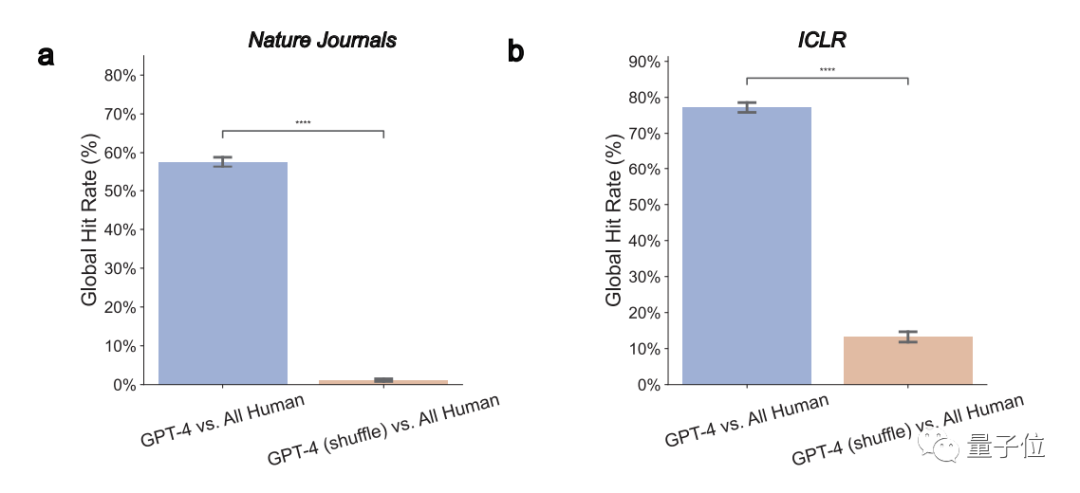
1、GPT-4意见与人类评审员真实意见显著重叠
整体来看,在Nature论文中,GPT-4有57.55%的意见与至少一位人类评审员一致;在ICLR中,这个数字则高达77.18%。
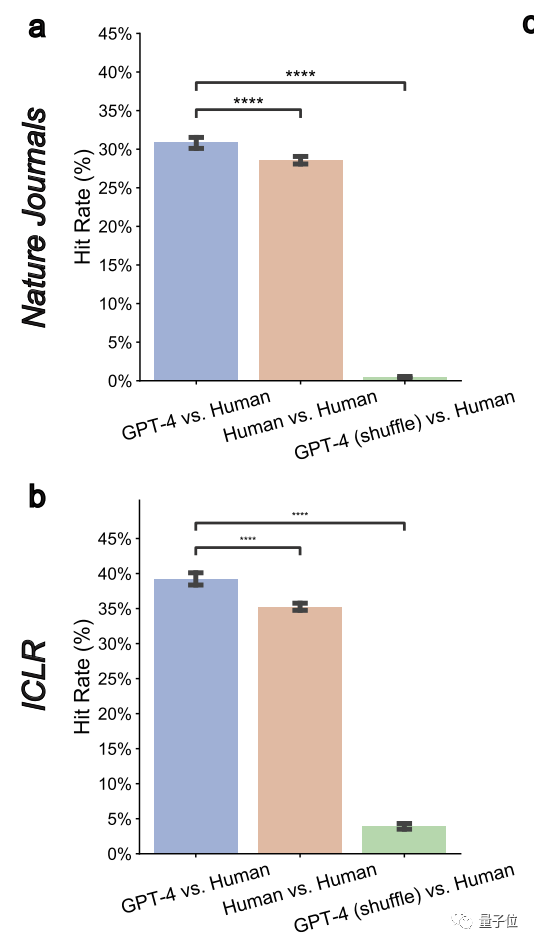
再进一步仔细比较GPT-4与每一位评审员的意见之后,团队又发现:
GPT-4在Nature论文上和人类评审员的重叠率下降为30.85%,在ICLR上降为39.23%。
但这与两位人类审稿人之间的重叠率相当:
人类在Nature论文上的平均重叠率为28.58%;在ICLR上为35.25%。
此外,他们还通过分析论文的等级水平(oral、spotlight、或是直接被拒绝的)发现:
对于水平较弱的论文来说,GPT-4和人类审稿人之间的重叠率更高,可以从上面的30%多升到近50%。
这说明,GPT-4对水平较差的论文的鉴别能力很高。
作者也因此表示,那些需要更实质性修改才能被接收的论文有福了,大伙儿可以在正式提交前多试试GPT-4给出的修改意见。
2、GPT-4可以给出非通用反馈
所谓非通用反馈,即GPT-4不会给出一个适用于多篇论文的通用评审意见。
在此,作者们衡量了一个“成对重叠率”的指标,结果发现它在Nature和ICLR上都显著降低到了0.43%和3.91%。
这说明GPT-4是有针对性的。
3、能够在重大、普遍问题上和人类观点一致
一般来说,人类反馈中较先出现的意见以及多个评审员都提及的意见,最可能代表重要、普遍的问题。
在此,团队也发现,LLM更有可能识别出多个评审员一致认可的常见问题或缺陷。
也就是说,GPT-4在大面上是过得去的。
4、GPT-4给的意见更强调一些与人类不同的方面
研究发现,GPT-4评论研究本身含义的频率是人类的7.27倍,评论研究新颖性的可能性是人类的10.69倍。
以及GPT-4和人类都经常建议进行额外的实验,但人类更关注于消融实验,GPT-4更建议在更多数据集上试试。
作者表示,这些发现表明,GPT-4和人类评审员在各方面的的重视程度各不相同,两者合作可能带来潜在优势。
定量实验之外是用户研究。
在此共包括308名来自不同机构的AI和计算生物学领域的研究员,他们都在本次研究中上传了各自的论文给GPT-4进行评审。
研究团队收集了他们对GPT-4评审意见的真实反馈。
总体而言,超过一半(57.4%)的参与者认为GPT-4生成的反馈很有帮助,包括给到一些人类想不到的点。
以及82.4%的调查者认为它比至少一些人类评审员的反馈更有益。
此外,还有超过一半的人(50.5%)表示,愿意进一步使用GPT-4等大模型来改进论文。
其中一人表示,只需要5分钟GPT-4就给出了结果,这个反馈速度真的非常快,对研究人员改善论文很有帮助。
当然,作者指出:
GPT-4也有它的局限性。
最明显的是它更关注于“整体布局”,缺少特定技术领域(例如模型架构)的深度建议。
所以,如作者最后总结:
人类评审员的高质量反馈还是不可或缺,但大家可以在正式评审前拿它试试水,弥补遗漏实验和构建等方面的细节。
当然,他们也提醒:
正式评审中,审稿人应该还是独立参与,不依赖任何LLM。
一作都是华人
本研究一作共三位,都是华人,都来自斯坦福大学计算机科学学院。

他们分别是:
- 梁伟欣,该校博士生,也是斯坦福AI实验室(SAIL)成员。他硕士毕业于斯坦福电气工程专业,本科毕业于浙江大学计算机科学。
- Yuhui Zhang,同博士生在读,研究方向为多模态AI系统。清华本科毕业,斯坦福硕士毕业。
- 曹瀚成,该校五年级博士在读,辅修管理科学与工程,同时加入了斯坦福大学NLP和HCI小组。此前毕业于清华大学电子工程系本科。
论文地址:https://arxiv.org/abs/2310.01783
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK