

微软开源的大模型太强了,数学推理超ChatGPT,论文、模型权重全部公开
source link: https://www.51cto.com/article/763881.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

微软开源的大模型太强了,数学推理超ChatGPT,论文、模型权重全部公开
上周,微软与中国科学院联合发布的 WizardMath 大模型火了。
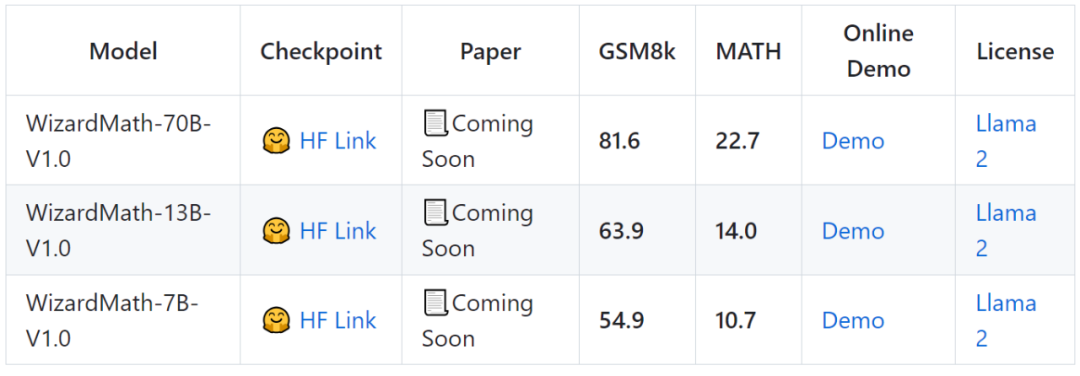
该模型有 70B、13B、7B 三个参数规模,研究者在两个数学推理基准 GSM8k 和 MATH 上的测试表明,WizardMath 优于所有其他开源 LLM,达到 SOTA。
在 GSM8K 上,WizardMath-70B-V1.0 模型的性能略优于一些闭源 LLM,包括 ChatGPT 3.5、Claude Instant 1 和 PaLM 2 540B。
WizardMath-70B-V1.0 模型在 GSM8k 基准测试中达到 81.6 pass@1,比 SOTA 开源 LLM 高出 24.8 分。
WizardMath-70B-V1.0 模型在 MATH 基准测试中达到 22.7 pass@1,比 SOTA 开源 LLM 高出 9.2 分。
其中,GSM8k 数据集包含大约 7500 个训练数据和 1319 个测试数据,主要是小学水平的数学问题,每个数据集都包含基本算术运算(加、减、乘、除),一般需要 2 到 8 步来解决。MATH 数据集来自 AMC 10、AMC 12 和 AIME 等著名数学竞赛当中的数学问题,包含 7500 个训练数据和 5000 个具有挑战性的测试数据:初等代数、代数、数论、几何、微积分等。
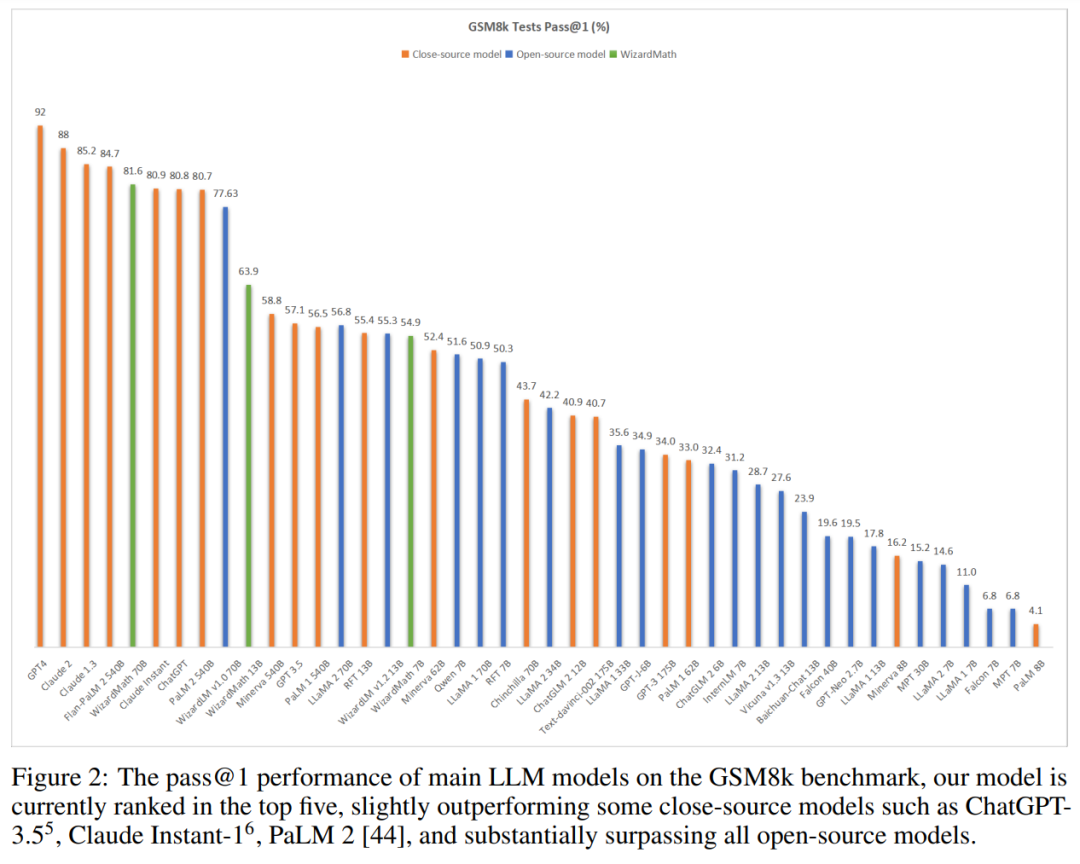
下图显示,WizardMath 在 GSM8k 基准测试中获得第五名,超过了 Claude Instant 1(81.6 vs. 80.9)、ChatGPT(81.6 vs. 80.8)和 PaLM 2 540B(81.6 vs. 80.7)。值得注意的是,与这些模型相比,WizardMath 模型的尺寸要小得多。
HuggingFace 已上线 3 个版本(分别为 7B、13B 和 70B 参数)。现在,相关论文已经公布了。

- 论文地址:https://github.com/nlpxucan/WizardLM
- 项目地址:https://github.com/victorsungo/WizardLM/tree/main/WizardMath
- 模型权重:https://huggingface.co/WizardLM/WizardMath-70B-V1.0
该研究提出了一种名为 Reinforced Evol-Instruct 方法,如图 1 所示,其包含 3 个步骤:1、监督微调。2、训练指令奖励模型以及过程监督奖励模型。3、Active Evol-Instruct 和 PPO 训练。
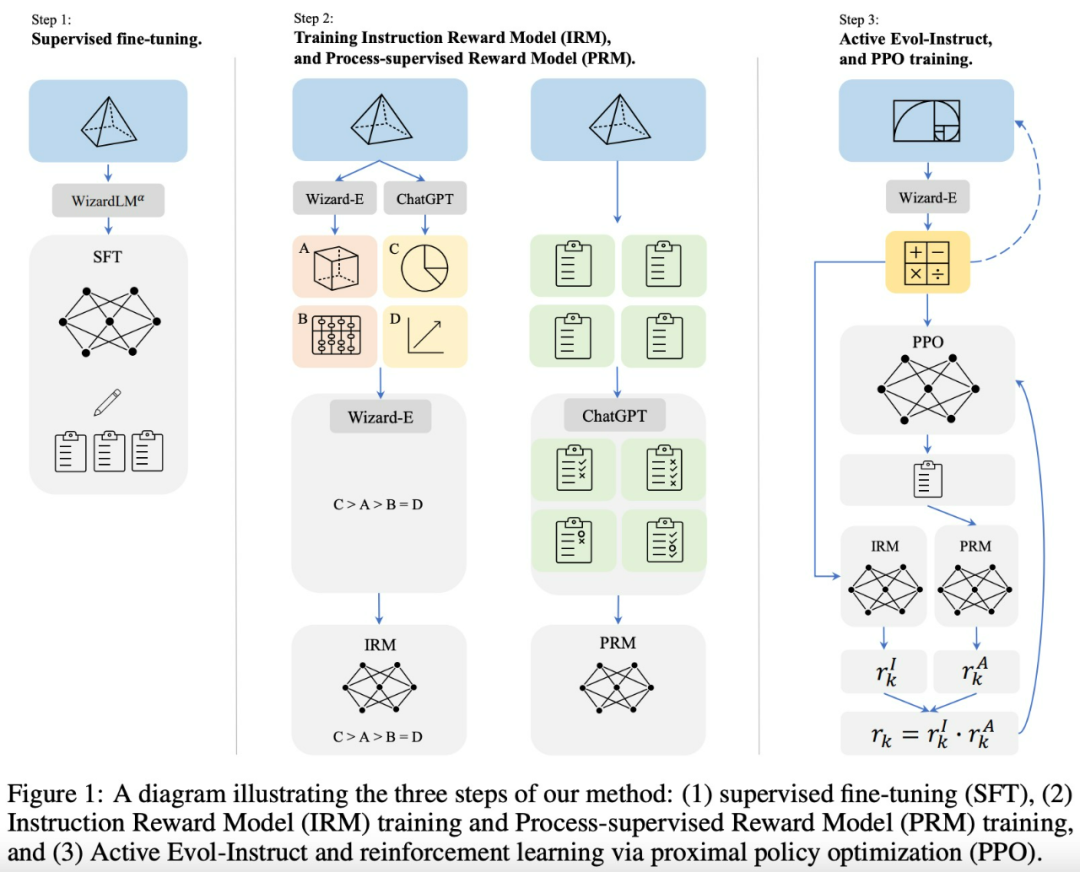
监督微调:继 InstructGPT 之后,该研究还使用了监督指令 - 响应对进行微调,其中包含:
- 为了使每个步骤的解析都更加容易,该研究使用 Alpha 版本的 WizardLM 70B(微调的 LLaMA 模型)模型对 GSM8k 和 MATH 重新生成了 15k 个答案,以 step-by-step 方式生成解决方案,然后找出正确答案,并使用这些数据对基础 Llama 模型进行微调。
- 该研究还从 WizardLM 的训练数据中采样了 1.5k 个开放域对话,然后将其与上述数学语料库合并作为最终的 SFT ( supervised fine-tuning )训练数据。
Evol-Instruct 原则:受 WiazrdLM 提出的 Evol-Instruct 方法及其在 WizardCoder 上有效应用的启发,该研究试图制作具有各种复杂性和多样性的数学指令,以增强预训练 LLM。具体来说:
- 向下进化:首先是增强指令,通过使问题变得更加容易来实现。例如,i):将高难度问题转化为较低难度,或 ii) 用另一个不同主题制作一个新的更简单的问题。
- 向上进化:源自原始的 Evol-Instruct 方法,通过 i)添加更多约束,ii)具体化,iii)增加推理来深化并产生新的更难的问题。
Reinforced Evol-Instruct :受 InstructGPT 和 PRMs 的启发,该研究训练了两个奖励模型,分别用来预测指令的质量和答案中每一步的正确性。
实验及结果
该研究主要在 GSM8k 和 MATH 这两个常见的数学基准上测试了模型的性能,并使用大量基线模型,包括闭源模型:OpenAI 的 GPT-3、GPT-3.5、ChatGPT、GPT-4,谷歌的 PaLM 2、PaLM、 Minerva,Anthropic 的 Claude Instant、Claude 1.3、Claude 2, DeepMind 的 Chinchilla;开源模型:Llama 1、Llama 2、GAL、GPT-J、GPT-Neo、Vicuna、MPT、Falcon、Baichuan、ChatGLM、Qwen 和 RFT。
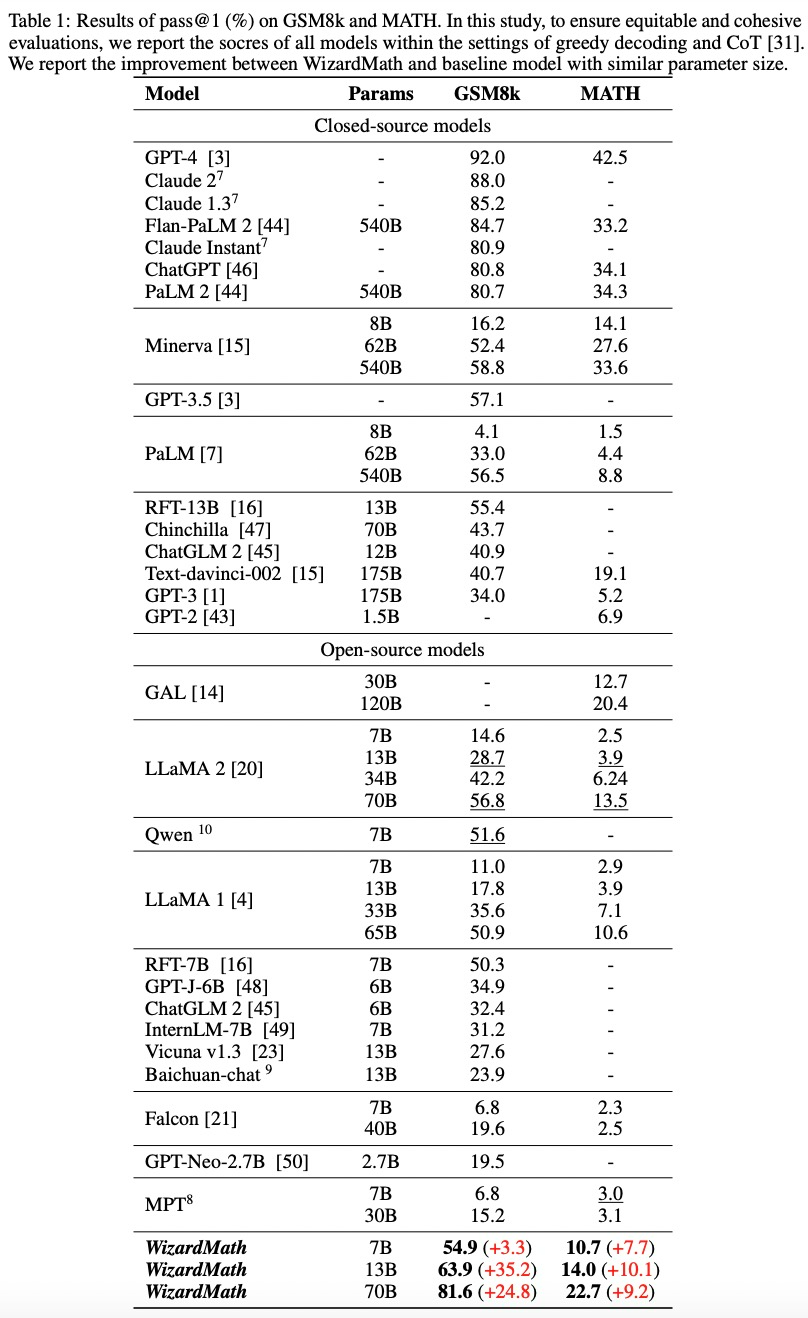
与闭源模型的比较。在表 1 中,WizardMath 70B 稍微优于 GSM8k 上的一些闭源 LLM,包括 ChatGPT、Claude Instant 和 PaLM 2 540B。
如图 2 所示(见上文),WizardMath 目前在所有模型上排名前五。同时,WizardMath 70B 在 MATH 上也超越了 Text-davinci-002。详细结果如下:
WizardMath 13B 在 GSM8k 上优于 PaLM 1 540B(63.9 vs 56.5)、Minerva 540B(63.9 vs 58.8)和 GPT-3.5(63.9 vs 57.1)。同时,它在 MATH 上超越了 PaLM 1 540B(14.0 vs. 8.8)、GPT-3 175B(14.0 vs. 5.2)。
WizardMath 70B 在 GSM8k 上实现了与 Claude Instant(81.6 vs 80.9)、ChatGPT(81.6 vs 80.8)和 PaLM 2(81.6 vs 80.7)更好或相当的性能。同时,WizardMath 70B 在 MATH 基准测试中也超过了 Text-davinci-002(22.7 比 19.1)。
与开源模型的比较。表 1 中所示的结果表明,WizardMath 70B 在 GSM8k 和 MATH 基准测试中明显优于所有开源模型。详细结果如下:
WizardMath 7B 超越了大多数开源模型,这些模型的参数数量约为 7B 到 40B 不等,包括 MPT、Falcon、Baichuan-chat、Vicuna v1.3、ChatGLM 2、Qwen、Llama 1 和 Llama 2 。尽管它的参数数量要少得多。
WizardMath 13B 在 GSM8k 上明显优于 Llama 1 65B(63.9 vs. 50.9)和 Llama 2 70B(63.9 vs. 56.8)。此外,它在 MATH 上的表现远远优于 Llama 1 65B(14.0 vs. 10.6)和 Llama 2 70B(14.0 vs. 13.5)。
WizardMath 70B 在 GSM8k 上超越了 Llama 2 70B(81.6 比 56.8),提升达到 24.8%。同时,它在数学方面也比 Llama 2 70B(22.7 比 13.5)高出 9.2%。
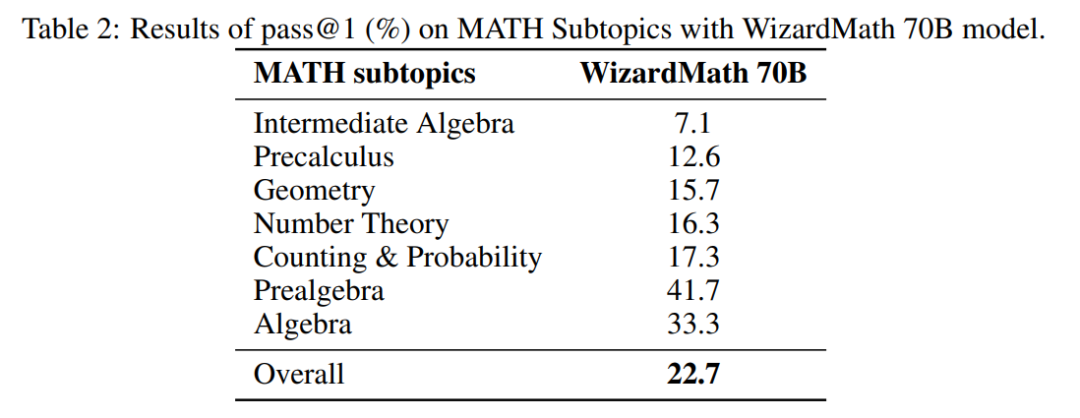
表 2 显示了 WizardMath 70B 模型在 MATH Subtopics上的结果。
Recommend
-
11
推理加速GPT-3超越英伟达方案50%!最新大模型推理系统Energon-AI开源,来自Colossal-AI团队
-
3
微软发声警告:美元太强了 这个季度的财报指引得砍掉一些
-
3
谷歌科学家亲讲:具身推理如何实现?让大模型「说」机器人的语言 作者:夏斐 2022-09-23 09:53:41 机器人领域已经发展了三四十年,但应用方面的进展较慢。这是因为,机器人建立在这样一个假设上:工作环境是简单...
-
4
用BT下载的方式在家跑千亿大模型,推理/微调速度10倍提升
-
3
GPT-4发布!ChatGPT大升级!太太太太强了! 量子位 2023-03-15 1 评论...
-
8
2023-05-24 10:18 科大讯飞:讯飞星火认知大模型数学能力方面结果优于 ChatGPT 据财联社 5 月 24 日报道,科大讯飞在互动平台表示,认知智能全国重点实验室牵头设计了通用认知大模型评测体系,并与中科院人工智能产学研创新联...
-
4
OpenAI出手解决GPT-4数学推理:做对一步立刻奖励!论文数据集全开放,直接拿下SOTA
-
17
华为盘古Chat将发布、OpenAI提升GPT4数学推理能力、NVIDIA发布生成式AI平台 | 36氪ChatGPT周报36氪To B产业报道·2023-06-05 09:05ChatGPT新闻速递
-
3
提升大模型数学推理能力: 过程监督 思维链采用逐步推理的方式得到最终结果,如果模型在某一步出现幻想 (Hallucination),则差之毫厘,谬以千里,后面的错误...
-
2
神秘大模型一夜刷屏,能力太强被疑GPT4.5,奥特曼避而不答打哑谜
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK