

TabR:检索增强能否让深度学习在表格数据上超过梯度增强模型?
source link: https://www.51cto.com/article/763306.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

TabR:检索增强能否让深度学习在表格数据上超过梯度增强模型?
这是一篇7月新发布的论文,他提出了使用自然语言处理的检索增强Retrieval Augmented技术,目的是让深度学习在表格数据上超过梯度增强模型。
这是一篇7月新发布的论文,他提出了使用自然语言处理的检索增强Retrieval Augmented技术,目的是让深度学习在表格数据上超过梯度增强模型。
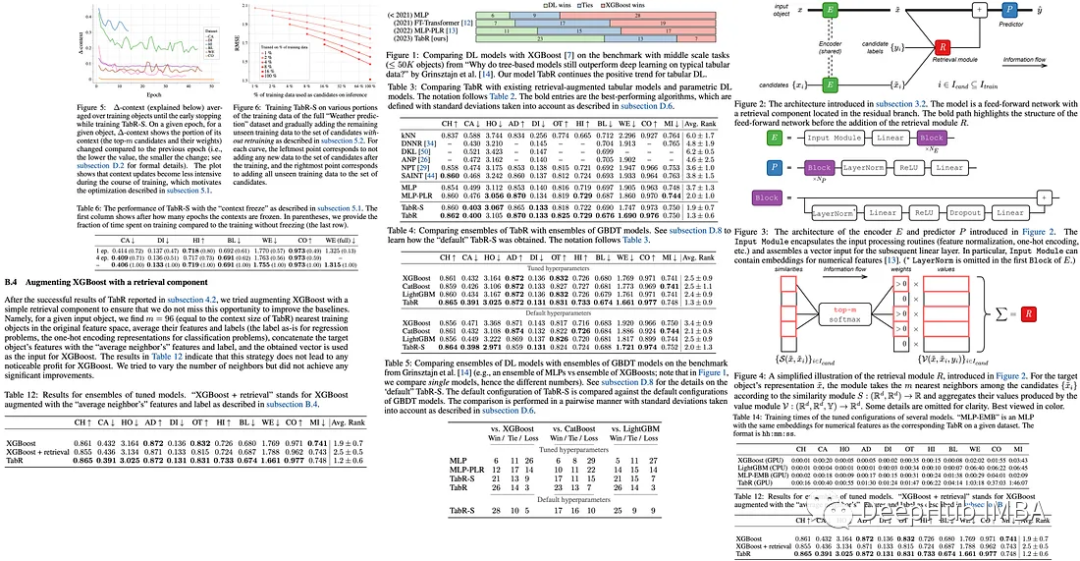
检索增强一直是NLP中研究的一个方向,但是引入了检索增强的表格深度学习模型在当前实现与非基于检索的模型相比几乎没有改进。所以论文作者提出了一个新的TabR模型,模型通过增加一个类似注意力的检索组件来改进现有模型。据说,这种注意力机制的细节可以显著提高表格数据任务的性能。TabR模型在表格数据上的平均性能优于其他DL模型,在几个数据集上设置了新的标准,在某些情况下甚至超过了GBDT模型,特别是在通常被视为GBDT友好的数据集上。
表格数据集通常被表示为特征和标签对{(xi, yi)},其中xi和yi分别是第i个对象的特征和标签。一般有三种类型的主要任务:二元分类、多类分类和回归。
对于表格数据我们会将数据集分为训练部分、验证部分和测试部分,模型对“输入”或“目标”对象进行预测。当使用检索技术时,检索是在一组“上下文候选”或“候选”中完成的,被检索的对象称为“上下文对象”或简称为“上下文”。同一组候选对象用于所有输入对象。
论文的实验设置涉及调优和评估协议,其中需要超参数调优和基于验证集性能的早期停止。然后在15个随机种子的平均测试集上测试最佳超参数,并在算法比较中考虑标准偏差。
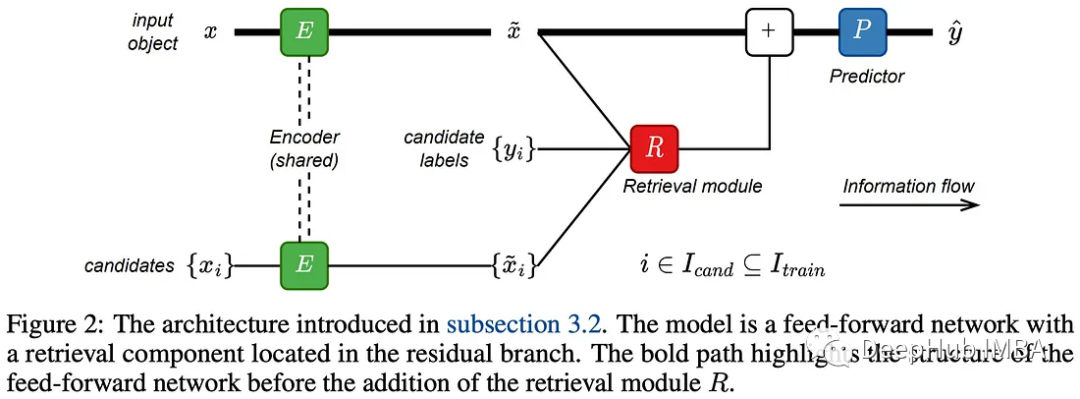
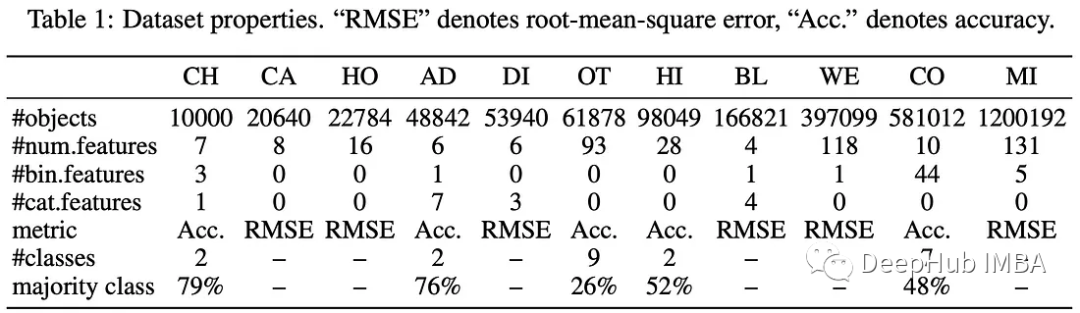
论文作者的目标是将检索功能集成到传统的前馈网络中。该过程包括通过编码器传递目标对象及其上下文候选者,然后检索组件会对目标对象进行的表示,最后预测器进行预测。
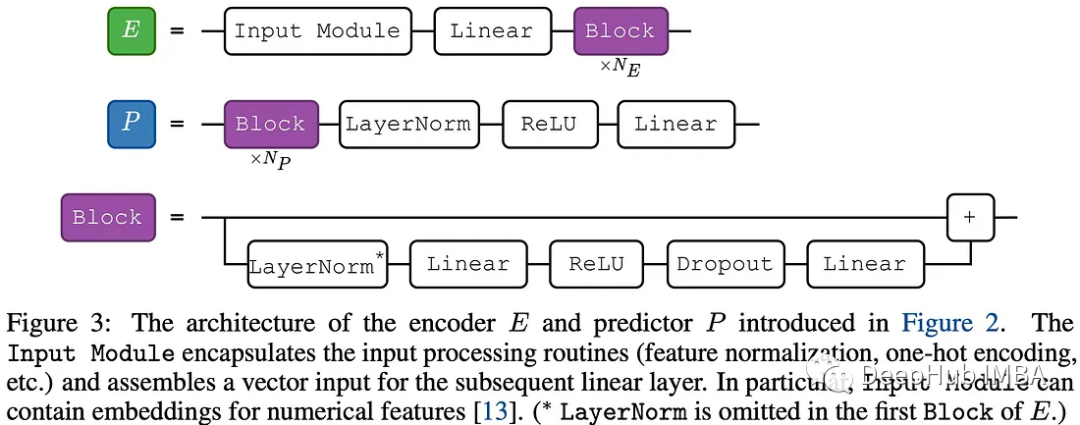
编码器和预测器模块很简单简单,因为它们不是工作的重点。检索模块对目标对象的表示以及候选对象的表示和标签进行操作。这个模块可以看作是注意力机制的一般化版本。
这个过程包括几个步骤:
- 如果编码器包含至少一个块,则将表示进行规范化;
- 根据与目标对象的相似性定义上下文对象;
- 基于softmax函数对上下文对象的相似性分配权重;
- 定义上下文对象的值;
- 使用值和权重输出加权聚合。
上下文大小设置为一个较大的值96,softmax函数会自动选择有效的上下文大小。
检索模块是最重要的部分
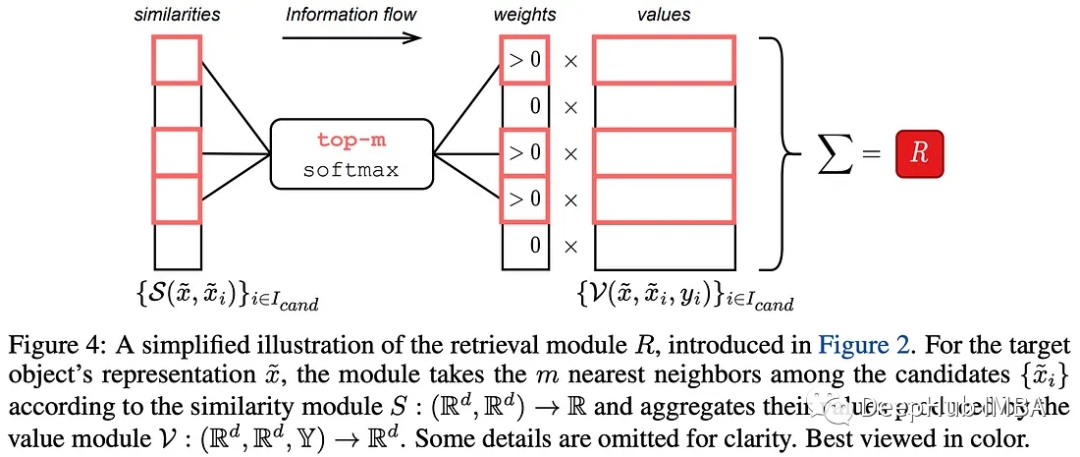
作者探讨了检索模块的不同实现,特别是相似度模块和值模块。并且说明了是通过一下几个步骤得到最终的模型。
1、作者评估了传统注意力的相似性和值模块,发现该配置与多层感知器(MLP)相似,因此不能证明使用检索组件是合理的。
2、然后他们将上下文标签添加到值模块中,但发现这并没有改进,这表明传统注意力的相似性模块可能是瓶颈。
3、为了改进相似度模块,作者删除了查询的概念,并用L2距离替换点积。这种调整使得几个数据集上性能的显著跃升。
4、值模块也进行改进,灵感来自最近提出的DNNR(用于回归问题的kNN算法的广义版本)。新的值模块带来了进一步的性能改进。
5、最后,作者创建模型TabR。在相似性模块中省略缩放项,不包括目标对象在其自身的上下文中(使用交叉注意),平均而言会得到更好的结果。
生成的TabR模型为基于检索的表格深度学习问题提供了一种健壮的方法。
作者也强调了TabR模型的两个主要局限性:
与所有检索增强模型一样,从应用程序的角度来看,使用真实的训练对象进行预测可能会带来一些问题,例如隐私和道德问题。
TabR的检索组件虽然比以前的工作更有效,但会产生明显的开销。所以它可能无法有效地扩展以处理真正的大型数据集。
作者将TabR与现有的检索增强解决方案和最先进的参数模型进行比较。除了完全配置的TabR,他们还使用了一个简化版本,TabR- s,它不使用特征嵌入,只有一个线性编码器和一个块预测器。
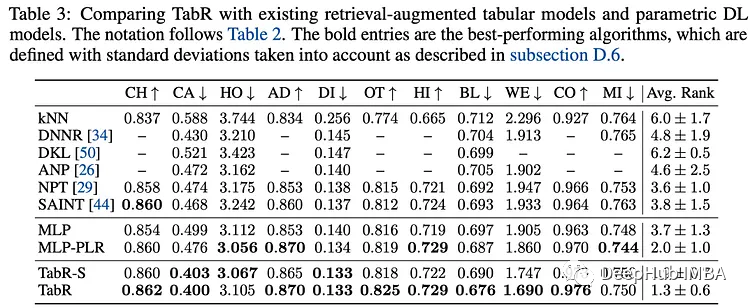
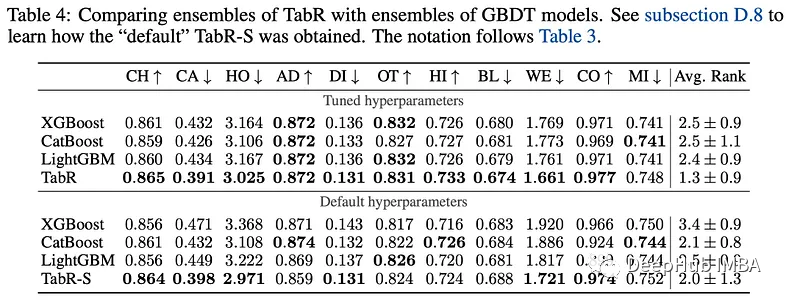
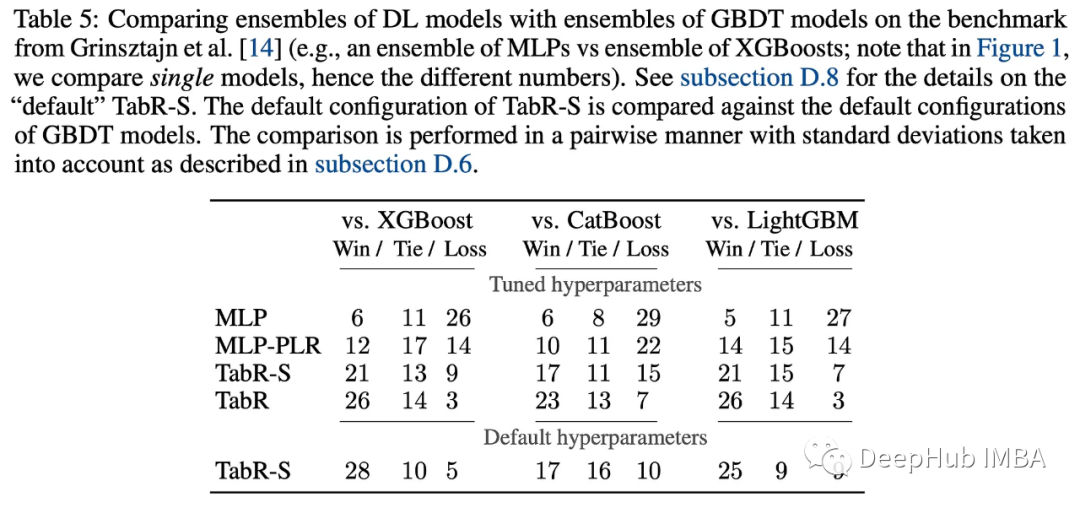
与全参数深度学习模型的比较表明,TabR在几个数据集上优于大多数模型,除了MI数据集,在其他数据集也很有竞争力。在许多数据集上,它比多层感知器(MLP)提供了显著的提升。
与GBDT模型相比,调整后的TabR在几个数据集上也有明显的改进,并且在其他数据集上保持竞争力(除了MI数据集),并且TabR的平均表现也优于GBDT模型。
总之,TabR将自己确立为表格数据问题的强大深度学习解决方案,展示了强大的平均性能,并在几个数据集上设置了新的基准。它的基于检索的方法具有良好的潜力,并且在某些数据集上可以明显优于梯度增强的决策树。
1、冻结上下文以更快地训练TabR
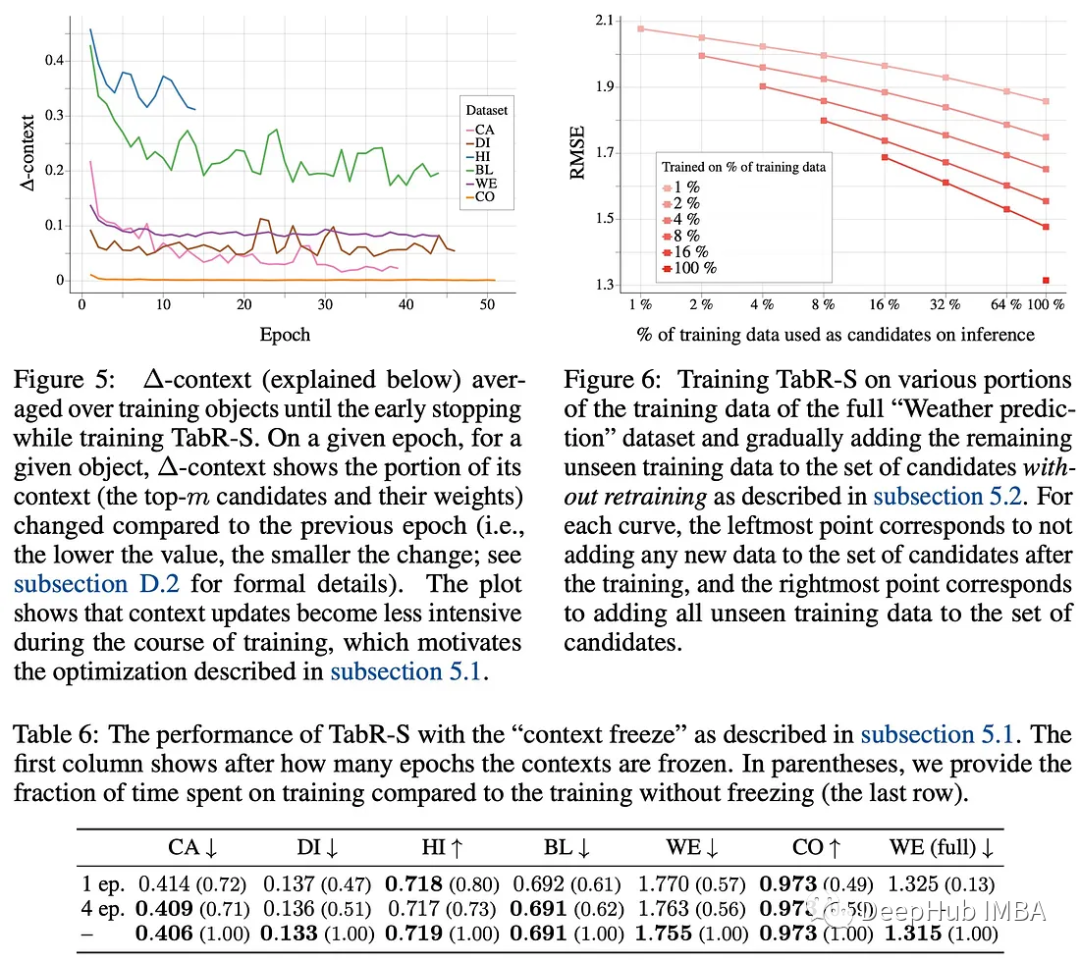
在TabR的原始实现中,由于需要对所有候选对象进行编码并计算每个训练批次的相似度,因此在大型数据集上的训练可能很慢。作者提到在完整的“Weather prediction”数据集上训练一个TabR需要18个多小时,该数据集有300多万个对象。
作者注意到在训练过程中,平均训练对象的上下文(即,根据相似度模块S,前m个候选对象及其分布)趋于稳定,这为优化提供了机会。在一定数量的epoch之后,他们提出了一个“上下文冻结”,即最后一次计算所有训练对象的最新上下文,然后在其余的训练中重用。
这种简单的技术可以加速TabR的训练,并且不会在指标上造成重大损失。在上面提到的完整的“Weather prediction”数据集上,它使速度提高了近7倍(将训练时间从18小时9分钟减少到3小时15分钟),同时仍然保持有竞争力的均方根误差(RMSE)值。
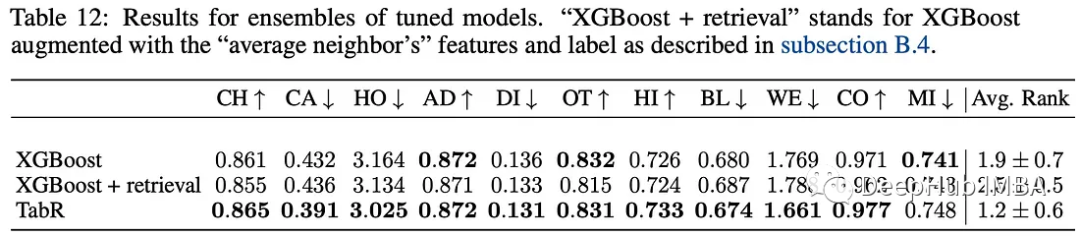
2、用新的训练数据更新TabR不需要再训练(初步探索)
在现实世界的场景中,在机器学习模型已经训练完之后,通常会收到新的、看不见的训练数据。作者测试了TabR在不需要再训练的情况下合并新数据的能力,方法是将新数据添加到候选检索集中。
他们使用完整的“Weather prediction”数据集进行了这个测试。结果表明在线更新可以有效地将新数据整合到训练好的TabR模型中。这种方法可以通过在数据子集上训练模型并从完整数据集中检索模型来将TabR扩展到更大的数据集。
3、使用检索组件增强XGBoost
作者试图通过结合类似于TabR中的检索组件来提高XGBoost的性能。这种方法涉及在原始特征空间中找到与给定输入对象最接近的96个训练对象(匹配TabR的上下文大小)。然后对这些最近邻的特征和标签进行平均,将标签按原样用于回归任务,并将其转换为用于分类任务的单一编码。
将这些平均数据与目标对象的特征和标签连接起来,形成XGBoost的新输入向量。但是该策略并没有显著提高XGBoost的性能。试图改变邻居的数量也没有产生任何显著的改善。
深度学习模型在表格类数据上一直没有超越梯度增强模型,TabR还在这个方向继续努力。
Recommend
-
94
-
20
↑ 点击 蓝字 关注极市平台 作 者...
-
7
随着不同形式的数据(例如图像)可用性的增加,理解和提取图像中的信息变得至关重要,尤其是包含某种表格形式的文本数据的图像。我们可以在发票、税务和银行对账单、医疗记录、设备和设施相关日志中找到它们。 表格是文档图像中信息丰富的结构化对象。
-
4
深度信息检索 Information Retrieval是用户进行信息查询和获取的主要方式,是查找信息的方法和手段。狭义的信息检索仅指信息查询(Information Search)。即用户根据需要,采用一定的方法,借助检索工具,从信息集合中找出所需要信息的查找过程。广义...
-
4
行人重识别 行人重识别(Person re-identification)也称行人再识别,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题。给定一个监控行人图像,检索跨设备下的该行人图像。旨在弥补目前固定的...
-
8
Ultra Deep Network FractalNet 《FractalNet: Ultra-Deep Neural Networks without Residuals》 Resnet in Resnet 《Resnet in Resnet: Generalizing Residual Architectures》 Highway 《Trai...
-
7
摘要:本章节介绍基于IR的方法(包括基础的信息检索技术IRar以及自动适配技术RAadapt)和结合的方法。 本文分享自华为云社区《
-
5
完爆GPT3、谷歌PaLM!检索增强模型Atlas刷新知识类小样本任务SOTA 作者:小戏 2022-08-25 15:05:23 今天介绍的这篇由 Meta AI 推出的论文,便另辟蹊径的将检索增强的方法应用于小样本学习领域。
-
4
深度学习炼丹-数据预处理和增强 一般机器学习任...
-
3
alg via Mac OS 本助手集算力、智能于一...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK