

不用LLM,遗传编程可控Python代码!谷歌DeepMind等提出全新ARZ框架
source link: https://www.51cto.com/article/763343.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

不用LLM,遗传编程可控Python代码!谷歌DeepMind等提出全新ARZ框架
谷歌等团队发布了遗传编程最新成果——AutoRobotics-Zero(ARZ)。最新论文已被IROS 2023接收。

论文地址:https://arxiv.org/pdf/2307.16890.pdf
这是一种使用AutoML-Zero的搜索方法,能够构建紧凑、可解释的机器人策略,可以快速适应环境的剧烈变化。
即使在随机选择的一条腿折断后,ARZ策略能够控制步态,让其继续行走。

而这一挑战任务,在2个流行的神经网络基线MLP+LSTM中,取得了失败结果。
甚至,ARZ使用的参数和FLOPS比基线少得多。

英伟达高级研究科学家Jim Fan表示,令人耳目一新的机器人技术!无需LLM,甚至无需神经网络:只需使用进化搜索控制机器人的Python代码。可解释,并且自适应。

全新ARZ框架
现实世界中的机器人,面临着不同类型的挑战,比如物理磨损、地形障碍等等。
如果仅是依靠将相同状态映射到,相同动作的静态控制器,只能暂且逃过这一劫。
但不能将万事万物都映射出来,而需要机器人能够根据不同变化的环境,来持续调整控制策略。
要实现这种能力,它们必须在没有外部提示的情况下,通过观察行动如何随时间改变系统状态,来识别环境变化,并更新其控制以做出响应。
当前,递归深度神经网络是支持快速适应的常用策略表示法。然而,它的问题在于,单一,参数过高,难以解释。
由此,谷歌等研究人员提出了基于AMLZ的AutoRobotics-Zero (ARZ)方法,以支持四足机器人适应任务中动态、自我修正的控制策略进化。
研究人员将这些策略表示为程序,而非神经网络。
他们演示了如何从零开始,仅使用基本数学运算作为构建模块,进化出适应性策略及其初始参数。

自动发现Python代码,代表四足机器人模拟器的可适应策略
演化可以发现控制程序,这些程序在与环境交互的过程中,利用其感官-运动经验来微调其策略参数或即时改变其控制逻辑。
这就实现了在不断变化的环境条件下,保持接近最佳性能所需的自适应行为。
与AMLZ不同,研究人员为Laikago机器人设计了模拟器,在倒立摆任务(Cataclysmic Cartpole)中取得良好性能。为此,团队还放弃了AMLZ的监督学习范式。
研究表明,进化程序可以在其生命周期内进行自适应,而无需明确接收任何监督输入,比如奖励信号。
此外,AMLZ依靠的是人为应用三个已发现的函数,而ARZ允许进化程序中使用的函数数量,由进化过程本身决定。
为此,研究人员使用了条件自动定义函数(CADF),并展示了其影响。
通过这种方法,发现进化的适应性策略比先进解决方案要简单得多,因为进化搜索从最小的程序开始,并通过与任务领域的交互逐步增加复杂性。
因此,它们的行为具有很高的可解释性。
在四足机器人中,即使随机选择的一条腿上的所有电机都无法产生任何扭矩,ARZ也能进化出适应性策略,保持向前运动并避免摔倒。
相比之下,尽管进行了全面的超参数调整,并采用了最先进的强化学习方法进行训练,但MLP和LSTM基线仍无法在这种具有挑战性的条件下学习到稳健的行为。
由于模拟真实机器人却非常耗时,自适应控制缺乏高效且具有挑战性的基准,研究人员还创建了一个简易自适应任务,名为「倒立摆」。
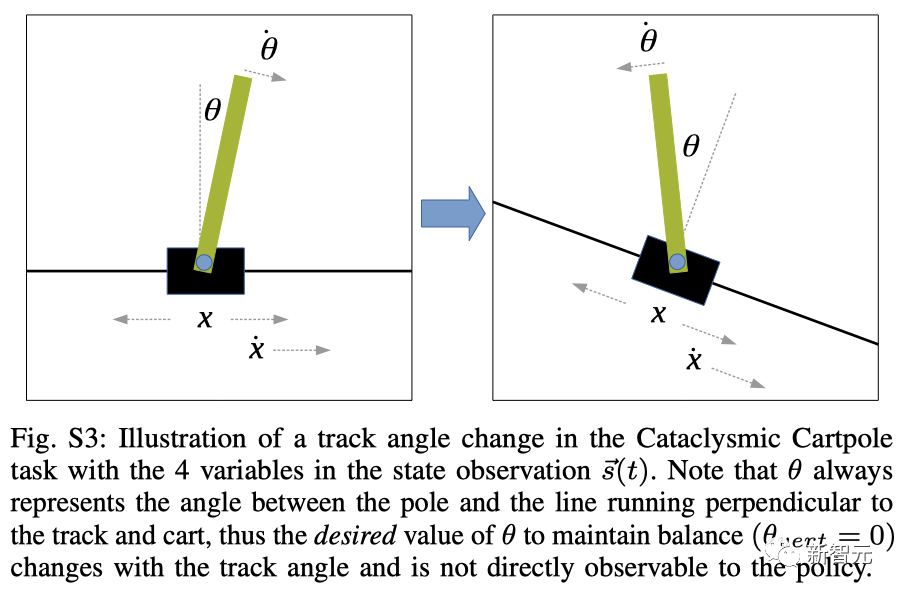
倒立摆任务中轨道角度变化的示意图
总而言之,本论文开发了一种进化方法,用于从零开始自动发现适应性机器人策略。在每个任务中,得到的策略具有以下特点:
• 超越经过精心训练的MLP和LSTM基线;
• 表示为可解释的、符号化的程序;
• 使用的参数和操作比基线更少。
2种搜索算法:自然选择第一性原理
算法由两个核心函数组成:StartEpisode() 和 GetAction()。
StartEpisode() 会在与环境交互的每episode开始时运行一次。它的唯一目的是用进化常量初始化虚拟内存的内容。
这些内存在任何时间的内容,都可以被描述为控制程序的状态。研究人员的目标是发现,能够在与环境交互的同时,通过调整内存状态,或改变控制代码来适应环境的算法。
而这种适应性以及算法的决策策略,由 GetAction() 函数实现,其中每条指令都执行一个操作,比如「0=s7*s1 or s3=v1[i2]」。
同时,研究人员定义了一个更大的操作库,对程序的复杂度不设限制。
进化搜索被用来发现 GetAction() 函数中出现的操作序列和相关内存地址。
论文中,采用了2种进化算法:(a) 多目标搜索采用NSGA-II,(b) 单目标搜索采用RegEvo.
这两种搜索算法都,采用了达尔文自然选择原理的算法模型,对候选控制程序群体进行迭代更新。
进化搜索的一般步骤如下:
1. 初始化一组随机控制程序
2. 评估任务中的每个程序

进化控制算法的评估过程:单目标进化搜索采用均值episode奖励作为算法的适应度,而多目标搜索优化了两个适应度指标:均值奖励(第一个返回值),每个episode的均值步长(第二个返回值)
3. 使用特定任务的适应度指标选择有前途的程序
4. 通过交叉和变异改变选定的个体

算法群的简化示例,通过交叉和变异产生新的算法群体
5. 在群(population)中加入新的项目,取代一定比例的现有个体
6. 返回第二步
就本研究而言,NSGA-II和RegEvo之间的最大区别在于它们的选择方法。
NSGA-II使用多种适应性指标,比如前向运动和稳定性,来识别有潜力的个体。
而RegEvo则根据单一指标(前向运动)进行选择。
两种搜索方法同时演化:(1) 初始算法参数(即浮点存储器中的初始值sX、vX、mX),由 StartEpisode() 设置;(2) GetAction() 函数和CADF的程序内容。
测试环境
研究人员考虑在两种不同的环境中来测试ARZ:一个是四足机器人真实模拟器,另一个是全新倒立摆。
在这两种情况下,ARZ策略必须处理过渡函数的变化,这通常会阻碍它们的正常功能。
这些变化可能是突然的,也可能是渐进的,而且没有传感器输入来指示何时发生变化或环境如何变化。
断腿
与ARS+MLP和ARS+LSTM基线相比,ARZ(包括CADF)是唯一一个在四足机器人腿部折断的任务中,生成了可行控制策略的方法。
实际上,这个问题非常困难,因为找到一种能够保持平稳运动且对腿部折断具有鲁棒性的策略,需要重复20次进化实验。
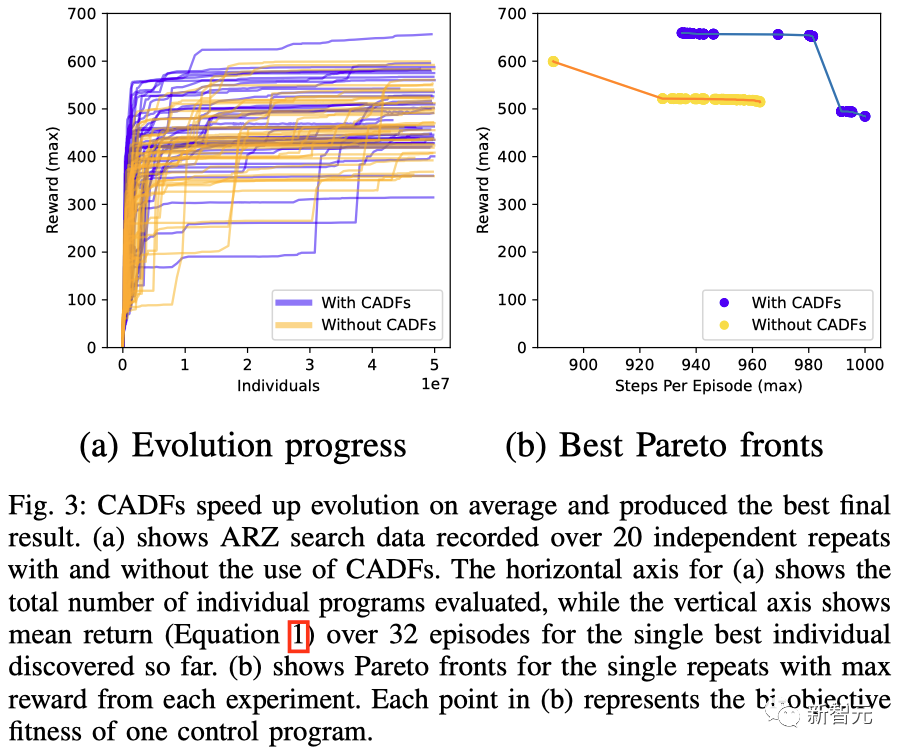
CADF 加快了进化速度,并产生了最佳的结果
从5个测试场景的轨迹可视化中可以发现,ARZ策略是唯一一个能够在所有情况下避免摔倒的控制器,尽管在前左腿折断的情况下,维持前行会有些困难。

ARZ发现了唯一能够适应任何断腿情况的策略
相比之下,MLP策略在右后腿折断的情况下可以继续前行,但在其他动态任务中都会摔倒。而LSTM策略只能在所有腿都完好的静止任务中避免摔倒。
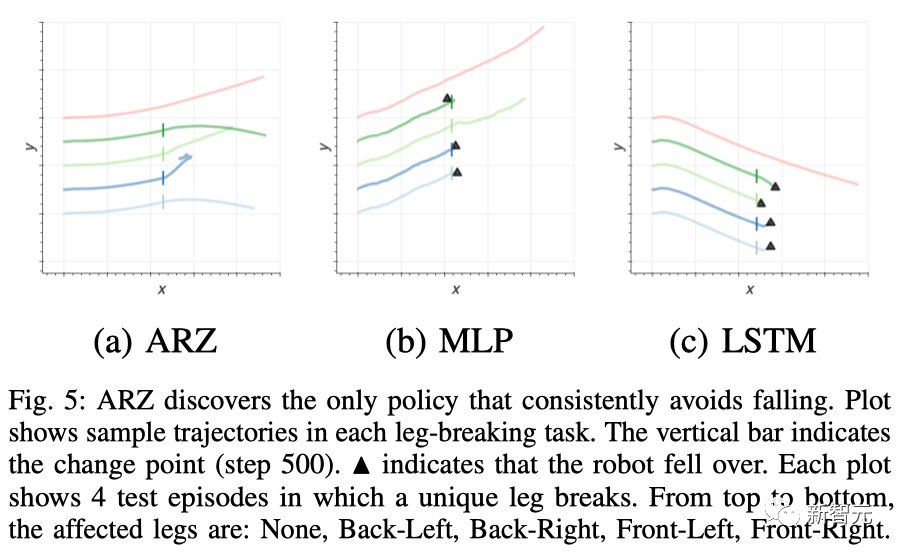
ARZ发现了唯一能持续避免摔倒的策略
简洁性和可解释性
研究人员提出的进化算法只用了608个参数和40行代码,每步最多执行2080个浮点运算(FLOPs)。
这与基线MLP/LSTM模型在每一步中使用的超过2.5k/9k个参数和5k/18k个FLOPs相比显得更为简洁。
从下图中可以看到,ARZ策略能够快速识别和适应多种独特的故障条件。
比如,当一条腿折断时,控制器的行为会瞬时发生改变,而该策略能够在发生变化时迅速做出调整。

当左前腿在途中折断时,ARZ策略发生的变化
倒立摆
在倒立摆中,研究人员证实ARZ与ARS+LSTM基线相比,在突然、剧烈变化的任务中能产生更好的控制效果。
如下,ARZ和LSTM都解决了适应任务,并且没有观察到从静态任务到动态任务的直接转移。
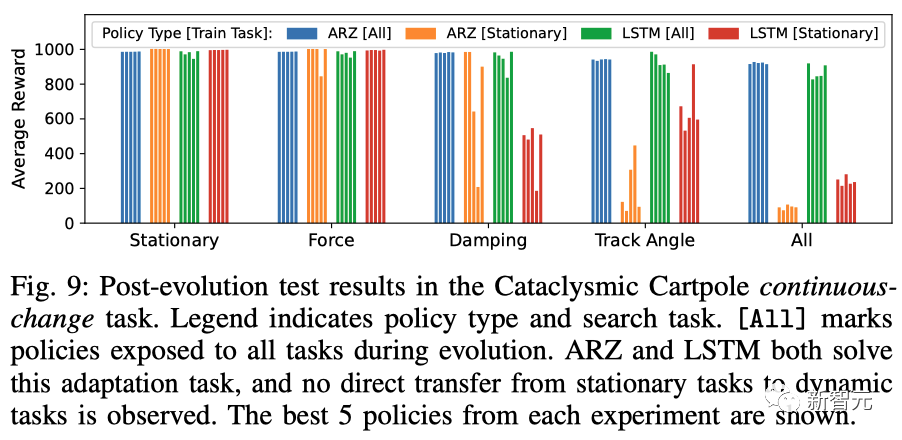
倒立摆连续变化任务的进化后测试结果
另外,在突变任务中,ARZ发现了唯一适用于所有突变的倒立摆任务的策略。
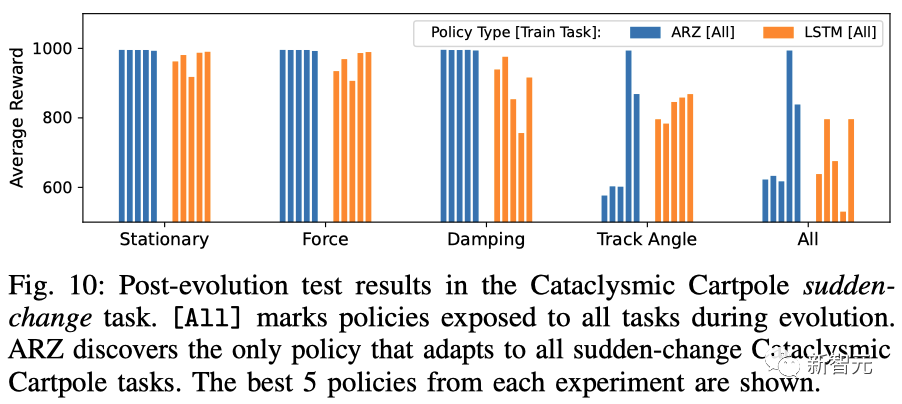
倒立摆突变任务的进化后测试结果
简单性和可解释性
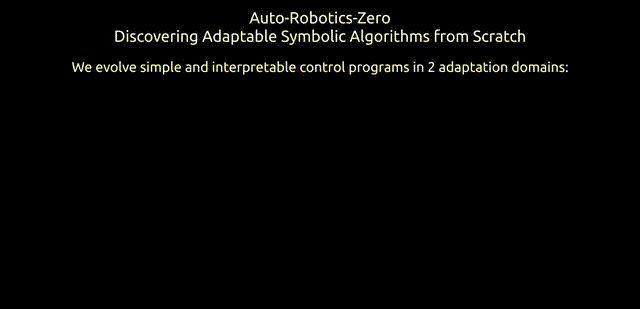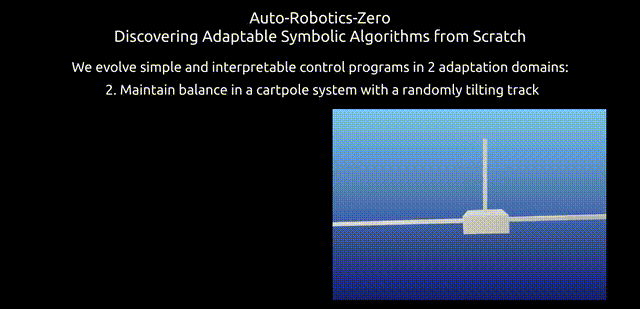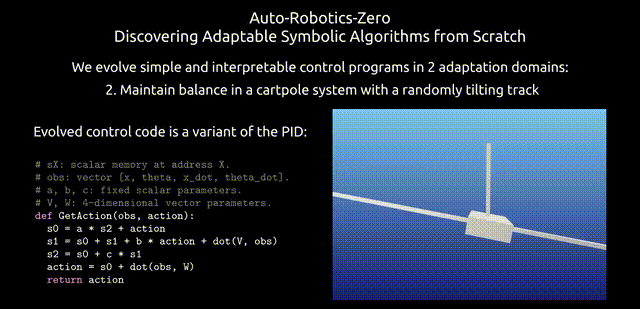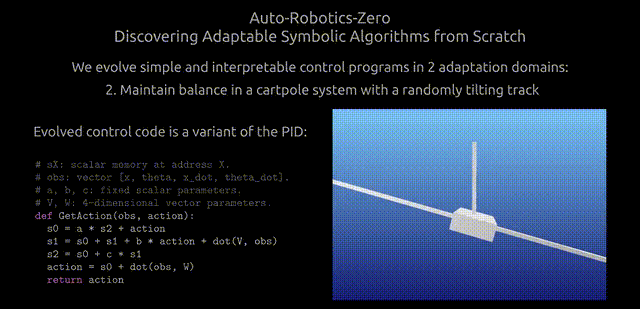
在这里,研究人员对ARZ策略进行分解,以详细解释它是如何在不断变化的环境中,整合状态观测结果来计算最优行动的。
下图,展示了ARZ设置中发现的算法示例。
值得注意的是,解决这项任务并不需要CADF,因此为了简化程序分析,搜索空间中省略了CADF。
研究人员发现的是三个累加器,它们收集了观察值和行动值的历史记录,从中可以推断出当前的行动。

在所有参数都不断变化的任务上,演化出有状态动作函数示例
该算法使用11个变量,每步执行25 FLOPs。
与此同时,MLP和LSTM算法分别使用了超过1k和 4.5k参数,每步分别耗费超过2k和9k FLOPs
使用ARZ在程序空间和参数空间中同时搜索,可以产生熟练、简单和可解释的控制算法。
这些算法可以进行零样本适应,也就是在环境发生根本性变化时迅速改变其行为,从而保持接近最优的控制能力。
· CADF和分心困境
在四足机器人领域,在搜索空间中包括有条件地调用自动定义函数(CADF)可以提高进化控制算法的表现能力。
在单个最佳策略中,CADF被用于将观测空间分成四个状态。然后,行动完全由系统的内部状态和这个离散化的观测决定。其中,离散化有助于策略去定义一种切换行为,从而克服分心困境。
相比之下,仅在人工设计的MLP或LSTM网络的参数空间中进行搜索,并不能产生能够适应多个变化事件的策略(例如,单条腿折断)。
· 适应未见任务动态
那么问题来了,在不知道未来可能会发生什么样的环境变化时,应该如何构建自适应控制策略?
在倒立摆任务中,ARZ的初步结果表明,在进化(训练)过程中注入部分可观测性和动态执行器噪声,可以作为非稳态任务动态的一般替代。
如果这个结论得到进一步证明,也就意味着我们能够在完全不了解任务环境动态的情况下,进化出熟练的控制策略,从而减轻对准确物理模拟器的需求。
</article
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK